HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

ASGuard:通过 Activation-Scaling 机制缓解针对性 Jailbreaking Attack 的防护方法

GlobalSplat: 通过 Global Scene Tokens 实现高效的 Feed-Forward 3D Gaussian Splatting


























ASGuard:通过 Activation-Scaling 机制缓解针对性 Jailbreaking Attack 的防护方法
GlobalSplat: 通过 Global Scene Tokens 实现高效的 Feed-Forward 3D Gaussian Splatting
如何 Fine-Tune 推理模型?一种用于合成 Student-Consistent SFT 数据的高师生协作框架
RAD-2:在生成器-判别器框架下扩展 Reinforcement Learning
DR3-Eval:迈向真实且可复现的深度研究评估
HY-World 2.0:一种用于重建、生成与模拟 3D 世界的多模态 World Model
pi0.7:一种具有涌现能力的、可控的通用机器人 Foundation Model
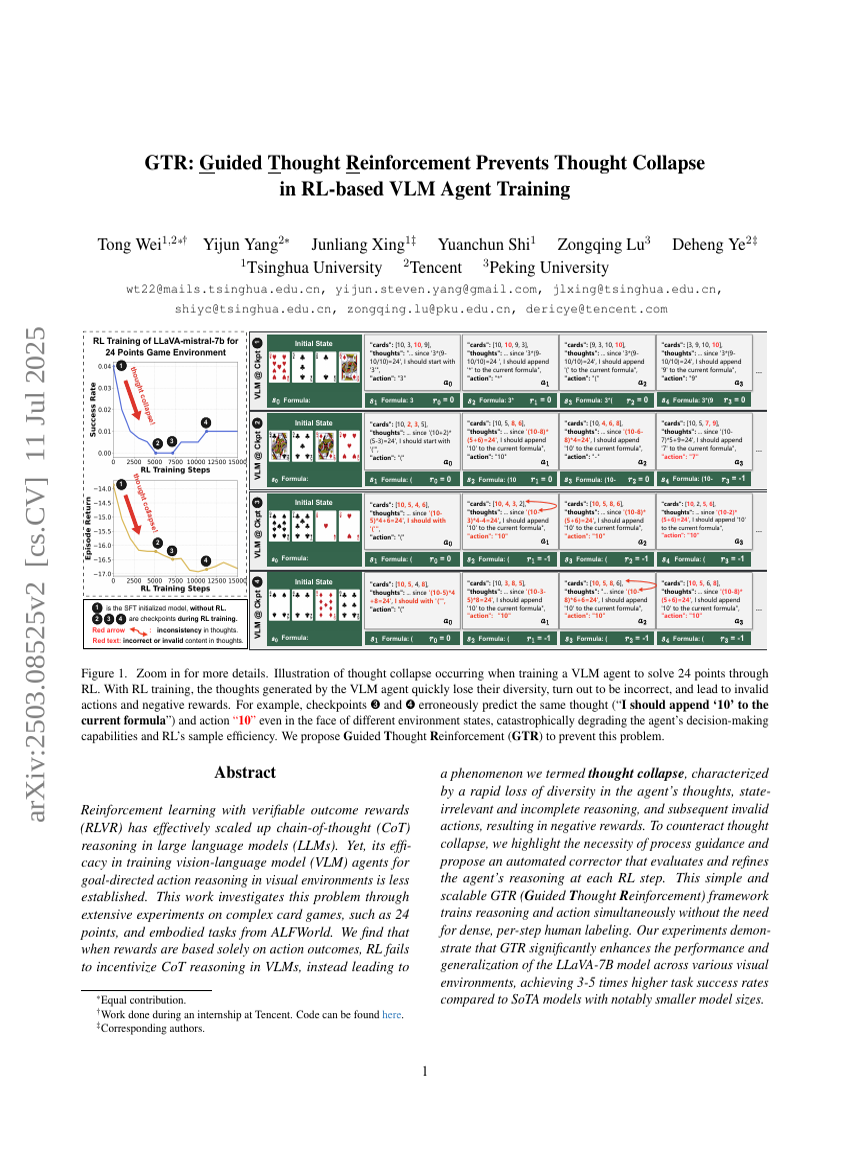
GTR:引导式思维强化通过防止 RL 基础的 VLM Agent 训练中的思维崩溃(Thought Collapse)来提升性能
Large Language Models 的 Agent Skills:架构、获取、安全与未来路径
空间理论:Foundation Models 能否通过主动探索构建空间信念?
记忆迁移学习:Memory 在 Coding Agents 中是如何跨领域迁移的
OccuBench: 通过 Language World Models 在真实世界专业任务上评估 AI Agents
SpatialEvo:通过确定性几何环境实现自我演化的空间智能
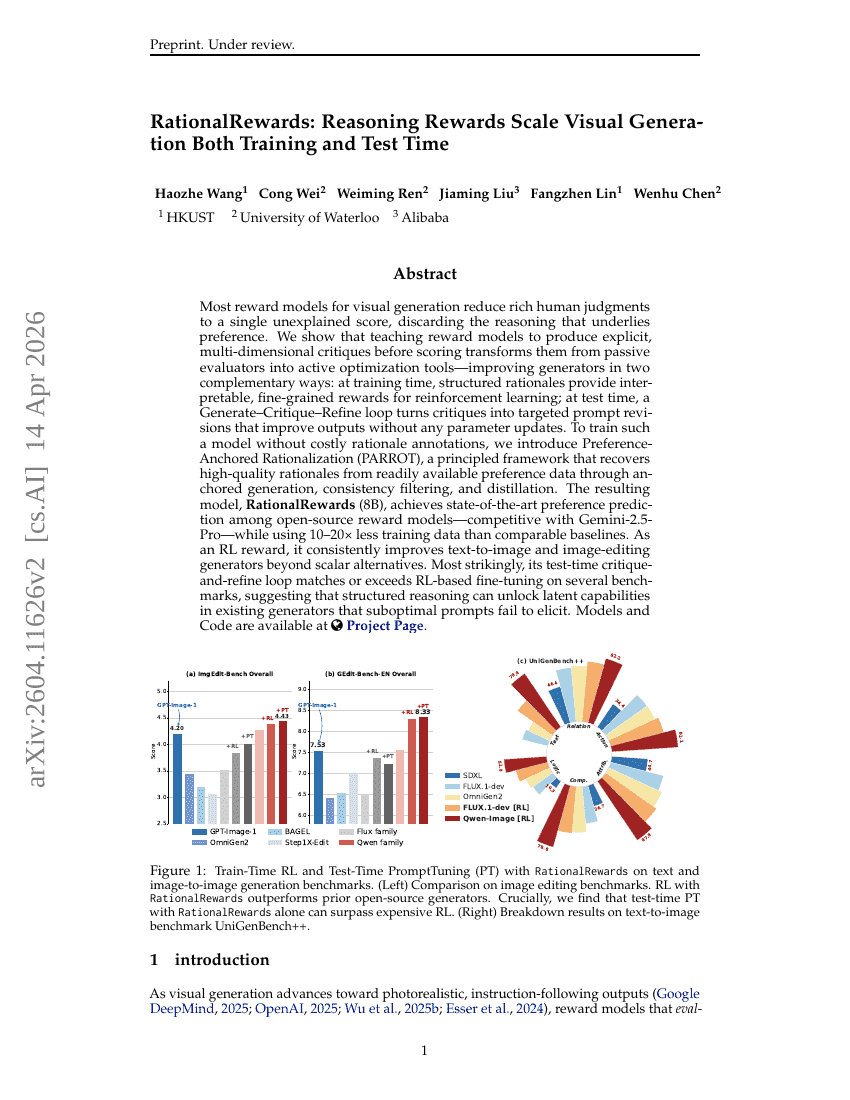
RationalRewards:通过推理 Rewards 在训练与测试阶段共同提升视觉生成的 Scale
Seedance 2.0:提升应对世界复杂性的 Video Generation 能力
GameWorld:迈向多模态 Game Agents 标准化与可验证性的评估研究
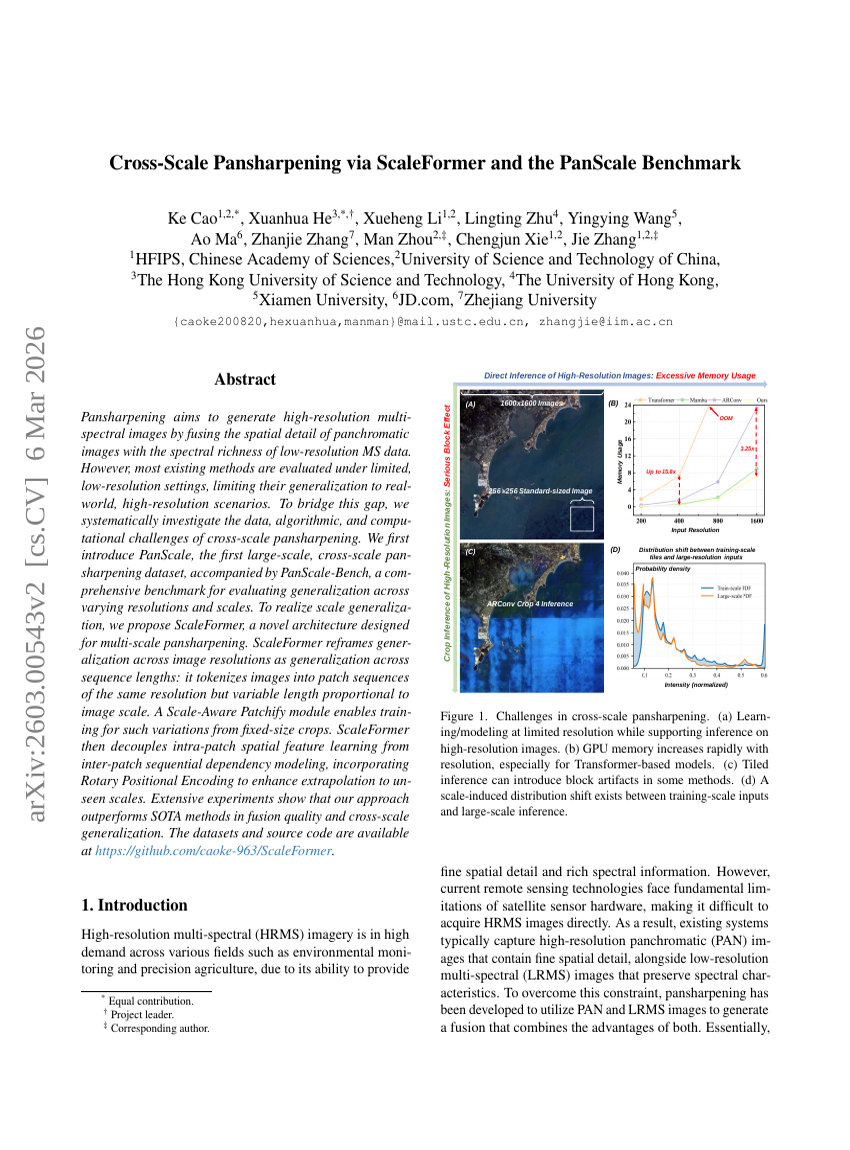
通过 ScaleFormer 实现跨尺度 Pansharpening 以及 PanScale 基准测试
ParseBench:面向 AI Agents 的文档解析基准测试
存储智能 Agent
PROPELLA-1:面向大规模 LLM 数据策展的多属性文档标注
长上下文视觉文档理解中的内化推理机制
TurboQuant:具有近乎最优失真率的在线 Vector Quantization 方法
BERT-as-a-Judge:一种高效、稳健的参考式大语言模型评估方法,可替代传统词汇法
SPPO:用于长程推理任务的序列级PPO方法
屏幕上的图灵测试:移动端GUI智能体人性化评测基准
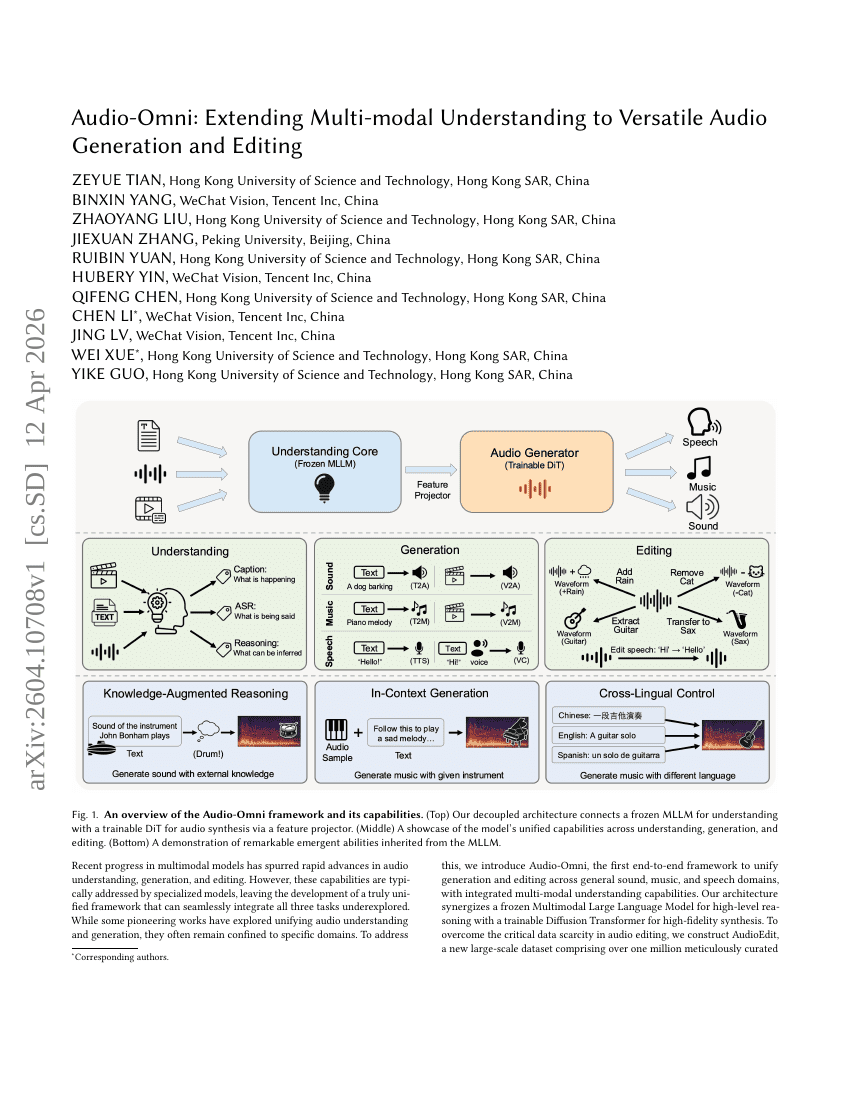
Audio-Omni: 将多模态理解扩展至多功能的 Audio 生成与编辑
重新思考大语言模型的在线策略蒸馏:现象、机制与方法配方
KnowRL: 通过最小充分知识引导的强化学习提升大语言模型推理能力
Uni-ViGU:基于扩散式视频生成器的统一视频生成与理解方法
ClawGUI:用于训练、评测与部署GUI智能体的统一框架
Transformers 中的 Attention Sink:关于其利用、解释与缓解的研究综述
OmniShow: 统一用于 Human-Object Interaction 视频生成的 Multimodal Conditions
如何 Fine-Tune 推理模型?一种用于合成 Student-Consistent SFT 数据的高师生协作框架
RAD-2:在生成器-判别器框架下扩展 Reinforcement Learning
DR3-Eval:迈向真实且可复现的深度研究评估
HY-World 2.0:一种用于重建、生成与模拟 3D 世界的多模态 World Model
pi0.7:一种具有涌现能力的、可控的通用机器人 Foundation Model
GTR:引导式思维强化通过防止 RL 基础的 VLM Agent 训练中的思维崩溃(Thought Collapse)来提升性能
Large Language Models 的 Agent Skills:架构、获取、安全与未来路径
空间理论:Foundation Models 能否通过主动探索构建空间信念?
记忆迁移学习:Memory 在 Coding Agents 中是如何跨领域迁移的
OccuBench: 通过 Language World Models 在真实世界专业任务上评估 AI Agents
SpatialEvo:通过确定性几何环境实现自我演化的空间智能
RationalRewards:通过推理 Rewards 在训练与测试阶段共同提升视觉生成的 Scale
Seedance 2.0:提升应对世界复杂性的 Video Generation 能力
GameWorld:迈向多模态 Game Agents 标准化与可验证性的评估研究
通过 ScaleFormer 实现跨尺度 Pansharpening 以及 PanScale 基准测试
ParseBench:面向 AI Agents 的文档解析基准测试
存储智能 Agent
PROPELLA-1:面向大规模 LLM 数据策展的多属性文档标注
长上下文视觉文档理解中的内化推理机制
TurboQuant:具有近乎最优失真率的在线 Vector Quantization 方法
BERT-as-a-Judge:一种高效、稳健的参考式大语言模型评估方法,可替代传统词汇法
SPPO:用于长程推理任务的序列级PPO方法
屏幕上的图灵测试:移动端GUI智能体人性化评测基准
Audio-Omni: 将多模态理解扩展至多功能的 Audio 生成与编辑
重新思考大语言模型的在线策略蒸馏:现象、机制与方法配方
KnowRL: 通过最小充分知识引导的强化学习提升大语言模型推理能力
Uni-ViGU:基于扩散式视频生成器的统一视频生成与理解方法
ClawGUI:用于训练、评测与部署GUI智能体的统一框架
Transformers 中的 Attention Sink:关于其利用、解释与缓解的研究综述
OmniShow: 统一用于 Human-Object Interaction 视频生成的 Multimodal Conditions