Command Palette
Search for a command to run...
MDPBench:面向真实场景的多语言文档解析基准测试
MDPBench:面向真实场景的多语言文档解析基准测试
Zhang Li Zhibo Lin Qiang Liu Ziyang Zhang Shuo Zhang Zidun Guo Jiajun Song Jiarui Zhang Xiang Bai Yuliang Liu
摘要
我们推出了 Multilingual Document Parsing Benchmark(多语言文档解析基准测试),这是首个针对多语言数字文档及照片文档解析的基准测试。尽管文档解析技术已取得显著进展,但其研究几乎完全集中在少数几种主流语言的清洁、数字格式化且排版良好的页面上。目前尚缺乏系统性的基准测试来评估模型在涵盖多种文字系统和低资源语言的数字及照片文档上的表现。MDPBench 包含 3,400 张文档图像,横跨 17 种语言,涵盖了多种文字系统及不同的拍摄条件。这些图像通过由专家模型标注、人工修正和人工校验构成的严格 pipeline 产生了高质量的标注。为了确保公平比较并防止数据泄露,我们设置了独立的公开(public)和私有(private)评估集。通过对开源和闭源模型进行全面的评估,我们发现了一个惊人的现象:虽然闭源模型(尤其是 Gemini3-Pro)表现出相对较强的鲁棒性,但开源替代方案则遭遇了剧烈的性能崩塌,尤其是在非拉丁文字系统和真实的拍摄文档上——在拍摄文档上的平均性能下降了 17.8%,在非拉丁文字系统上的平均下降了 14.0%。这些结果揭示了模型在不同语言和不同条件下的显著性能失衡,并为构建更具包容性、具备实际部署能力的解析系统指明了具体的研究方向。
一句话总结
研究人员推出了 MDPBench,这是首个用于多语言数字及照片文档解析的基准测试。该基准利用包含 17 种语言、共 3,400 张图像的数据集揭示了:虽然像 Gemini3-Pro 这样的闭源模型仍然保持相对稳健,但开源模型在非拉丁文字和照片文档上表现出显著的性能崩溃。
核心贡献
- 本文引入了 MDPBench,这是首个旨在评估跨数字和照片文档的多语言文档解析基准。
- 该工作提供了一个包含 17 种语言和多种文字、共 3,400 张高质量图像的数据集,这些图像通过涉及专家模型标注、人工修正和人工验证的严格流程进行标注。
- 对开源和闭源模型的广泛评估揭示了显著的性能差距,具体表现为:开源模型在照片文档上的平均性能下降了 17.8%,在非拉丁文字上的性能下降了 14.0%。
引言
高效的文档解析对于信息数字化至关重要,然而目前的研究几乎完全集中在少数主流语言的干净、原生数字文档上。现有的基准测试未能考虑到现实场景的复杂性,例如多样化的文字、低资源语言以及照片文档中存在的视觉失真。为了填补这些空白,作者推出了 MDPBench,这是首个针对多语言数字及照片文档解析的全面基准。该数据集由 3,400 张涵盖 17 种语言和各种拍摄条件的高质量图像组成,为评估模型如何处理非拉丁文字和不完美的现实世界拍摄图像提供了一个严格的框架。
数据集
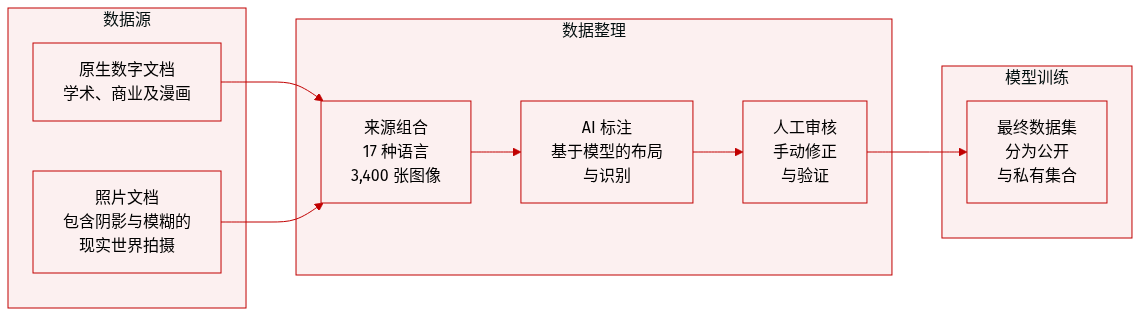
-
数据集组成与来源:作者推出了 MDPBench,这是一个包含 17 种语言、共 3,400 张文档图像的基准。数据集包括源自学术论文、商业报告、教育材料、手写笔记、历史档案、报纸以及像漫画这样复杂的图文文档的原生数字文档。它还整合了来自 OmniDocBench 的具有挑战性的中英文文档。
-
子集详情:
- 原生数字子集:包含 850 张精心挑选的、涵盖 17 种语言的图像。这些图像在布局复杂度和视觉元素(如公式、表格和图表)方面具有多样性,并通过人工审核过滤掉了低质量或琐碎的样本。
- 照片子集:通过打印或屏幕截取将数字文档转换为现实世界的图像而创建。该子集包括具有各种退化情况的室内和室外拍摄图像,例如物理变形(弯曲和皱褶)、多样的相机角度(倾斜和倒置)、摩尔纹、反射、阴影以及光照不均。
- 公开与私有划分:为了防止基准测试过拟合,作者将数据分为用于社区下载的公开子集,以及通过官方网站进行安全评估的私有子集。
-
数据处理与标注:
- 多阶段标注流程:作者采用严格的“标注-修正-验证”工作流。
- 专家模型标注:使用 dots.ocr 和 PaddleOCR-VL 进行布局检测。根据边界框裁剪文本、表格和公式块。随后由三个模型(PaddleOCR-VL、dots.ocr 和 Qwen3VL)进行识别。最终的初始标注根据模型间最高的平均相似度(文本/公式使用 NED,表格使用 TEDS)进行选择。如果相似度低于 0.7,则使用 Gemini-3-pro 以确保可靠性。
- 人工修正与验证:标注人员手动修正布局坐标、元素类型和阅读顺序。随后由一名独立的审核员验证修正后的文档,并将任何错误退回给原始标注人员进行迭代修订。
-
评估策略:作者使用页面级聚合策略,以防止元素分布不均(如公式或表格)不成比例地影响多语言评分。指标按页面计算然后取平均值。评估忽略了页眉、页脚和页码等页面组件。具体指标包括文本的归一化编辑距离 (NED)、公式的 CDM 以及基于树编辑距离的相似度 (TEDS) 用于表格。
实验
MDPBench 在 17 种语言和各种文档格式下,评估了包括通用视觉语言模型和专门的流水线系统在内的多种文档解析模型。实验验证了模型针对现实世界挑战(如照片文档、复杂布局和非拉丁文字)的稳健性。研究结果显示,虽然闭源模型通常优于开源替代方案,但在处理照片图像或低资源语言时,所有方法都面临显著的性能下降。此外,模型经常在特定语言的细微差别上遇到困难,包括从右至左文字的阅读顺序错误、西里尔字母的视觉混淆以及无空格文本中的幻觉。
作者在多语言基准上评估了多个文档解析模型,比较了它们在不同语言和文档类型下的性能。结果显示,闭源模型与开源模型之间存在显著差异,在解析照片文档和非拉丁文字方面面临重大挑战。在所有评估指标上,闭源模型均优于开源模型。与原生数字文档相比,模型在照片文档上的性能显著下降。模型在非拉丁文字语言上的准确率较低,并且难以处理特定语言的阅读顺序。

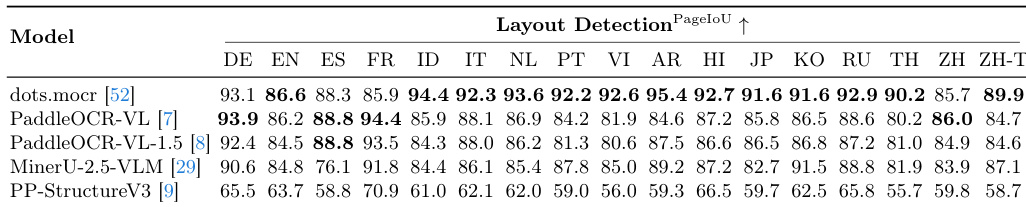
作者使用 MDPBench 评估了多个模型在布局检测方面的表现,重点关注其在各种语言下的性能。结果显示,dots.mocr 实现了最高的整体准确率,在许多语言中表现强劲,而其他模型则根据语言和图像类型的不同表现出不同程度的有效性。dots.mocr 在多种语言中实现了最高的整体布局检测准确率。性能在不同语言之间差异显著,某些模型在特定文字中表现出色,而在其他文字中表现较弱。模型在处理不同语言时表现出差异,表明训练数据中存在特定语言的偏差。
该表比较了几个文档解析基准,突出了在语言覆盖范围、图像类型和照片条件方面的差异。MDPBench 以更广泛的语言支持以及对多样化现实条件下照片文档的关注而脱颖而出。与其它基准相比,MDPBench 包含更多的语言和更广泛的照片条件。大多数现有基准侧重于原生数字文档,而 MDPBench 则强调照片和现实世界场景。MDPBench 具有更大数量的文档图像,并包含了多样化的拍摄挑战,如背景变化和相机方向。

作者在包含数字和照片文档的多语言基准上评估了各种文档解析模型。结果显示,闭源模型与开源模型之间存在显著的性能差距,在照片文档和非拉丁文字语言上下降尤为明显。闭源模型优于开源模型,特别是在照片文档场景下。在所有模型中,照片文档和非拉丁文字语言的性能均大幅下降。模型表现出特定语言的错误,包括阅读顺序问题、幻觉和错误的分割。
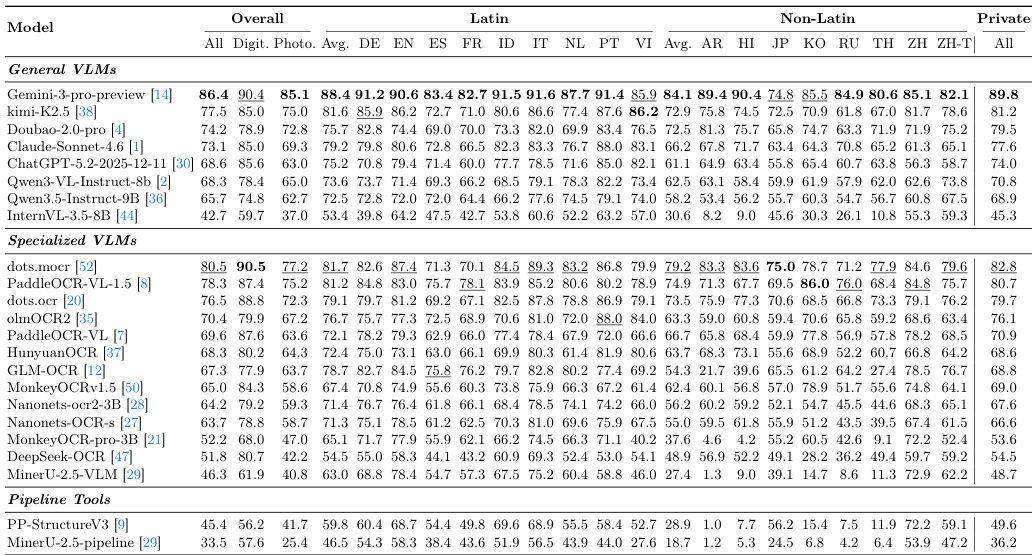
作者使用 MDPBench 评估了各种文档解析模型,这是一个旨在测试多种图像类型和现实拍摄条件下性能的多语言基准。实验表明,闭源模型通常优于开源替代方案,尽管与原生数字文档相比,所有模型在处理非拉丁文字和照片文档时都表现挣扎。最终,结果强调了在处理特定语言阅读顺序和复杂拍摄环境方面面临的重大挑战。