Command Palette
Search for a command to run...
RefineAnything: 用于完美局部细节的多模态区域特定 Refinement
RefineAnything: 用于完美局部细节的多模态区域特定 Refinement
Dewei Zhou You Li Zongxin Yang Yi Yang
摘要
我们提出将“特定区域图像细化”(region-specific image refinement)作为一个专门的问题设定:给定一张输入图像和一个用户指定的区域(例如涂鸦掩码 scribble mask 或边界框 bounding box),其目标是在恢复细粒度细节的同时,确保所有非编辑像素严格保持不变。尽管图像生成技术取得了飞速进展,但现代模型仍频繁遭遇局部细节坍缩(local detail collapse)问题(例如:扭曲的文本、Logo 以及细长结构)。现有的指令驱动型编辑模型多侧重于粗粒度的语义编辑,往往会忽略细微的局部缺陷,或者在编辑过程中无意中改变了背景,尤其是在感兴趣区域(ROI)仅占固定分辨率输入图像一小部分的情况下。我们提出了 RefineAnything,这是一种基于 multimodal diffusion 的细化模型,同时支持基于参考(reference-based)和无参考(reference-free)的细化。基于一个违反直觉的观察——即在固定的 VAE 输入分辨率下,“裁剪并缩放”(crop-and-resize)可以显著提升局部重建质量——我们提出了 Focus-and-Refine 策略。这是一种聚焦于区域的“细化并贴回”(refinement-and-paste-back)策略,通过将分辨率预算重新分配给目标区域,提升了细化的有效性与效率;同时,利用混合掩码(blended-mask)贴回技术来保证背景的严格一致性。此外,我们还引入了一种边界感知(boundary-aware)的边界一致性损失(Boundary Consistency Loss),以减少接缝伪影并提高贴回过程的自然度。为了支持这一新的问题设定,我们构建了 Refine-30K 数据集(包含 20K 个基于参考的样本和 10K 个无参考样本),并推出了 RefineEval——一个用于评估编辑区域保真度(fidelity)与背景一致性(consistency)的 benchmark。在 RefineEval 上,RefineAnything 相比于具有竞争力的基准模型取得了显著提升,并实现了近乎完美的背景保持,为高精度局部细化提供了一种切实可行的解决方案。项目主页:https://limuloo.github.io/RefineAnything/。
一句话总结
作者提出了 RefineAnything,这是一种基于多模态 diffusion 的模型,用于高精度、特定区域的图像细化。该模型利用 Focus-and-Refine 策略和 Boundary Consistency Loss 来恢复局部细节,同时确保严格的背景保留,在 새로引入的 RefineEval 基准测试中表现优于具有竞争力的基准模型。
核心贡献
- 本文提出了 RefineAnything,这是一种基于多模态 diffusion 的细化模型,设计用于基于参考(reference-based)和无参考(reference-free)任务,以恢复细粒度的局部细节。
- 作者引入了 Focus-and-Refine 策略,通过裁剪并缩放(crop-and-resize)的方法将分辨率重新分配到目标区域,并使用混合掩码粘贴回(blended-mask paste-back)方法来确保严格的背景保留。
- 这项工作贡献了一种边界感知的 Boundary Consistency Loss,以最大限度地减少接缝伪影,并提供了 Refine-30K 和 RefineEval,这是一个用于评估编辑区域保真度和背景一致性的新基准。
引言
虽然现代 diffusion 模型在高保真图像生成方面取得了显著进展,但它们经常面临局部细节塌陷的问题,导致文本、logo 和细微结构出现扭曲。现有的指令驱动编辑模型通常侧重于粗粒度的语义变化,并且在编辑小区域时,往往无法解决细微的局部缺陷,或者会无意中改变背景。为了解决这些问题,作者引入了 RefineAnything,这是一个专为特定区域细化设计的多模态 diffusion 框架。作者利用 Focus-and-Refine 策略,将模型能力集中在用户指定的区域,以恢复细粒度细节,同时通过专门的边界感知损失确保严格的背景保留。
数据集
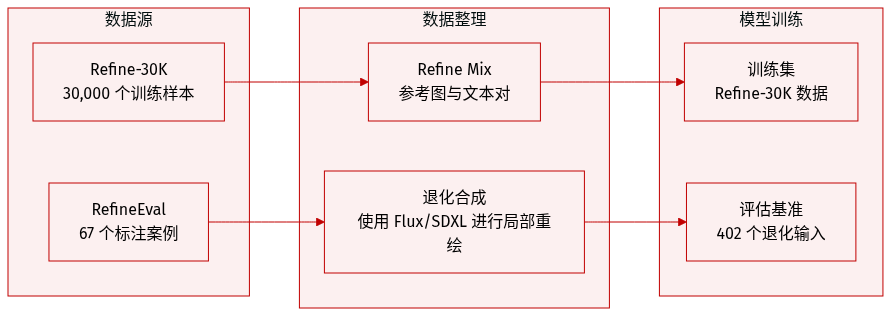
作者引入了两个不同的数据集来支持 RefineAnything 模型的训练和评估:
-
Refine-30K (训练数据集): 该数据集包含 30,000 个样本,分为两个特定的子集:
- 基于参考的细化对 (20,000 个样本): 这些样本为模型提供细化指令和一张参考图像,用于引导视觉风格和外观。
- 无参考的细化样本 (10,000 个样本): 这些仅包含指令的样本要求模型仅根据文本规范进行细化。
-
RefineEval (评估基准): 一个精心策划的基准,由源自 67 个人工标注案例的 402 个退化输入组成。该基准结构如下:
- 组成: 包括 31 个侧重于身份敏感内容(如 logo 和人物 ID)的基于参考的案例,以及 36 个涵盖通用物体、面部和人体结构的无参考案例。
- 数据合成: 对于每个案例,作者使用 Flux-fill、SDXL 和 Qwen-Edit 进行 inpainting,在局部编辑区域内创建退化输入。
- 处理流程: 为了确保多样性,作者针对每种 inpainting 方法,在三个不同的种子下使用五个随机涂鸦掩码生成候选样本。然后,他们手动为每种方法选择两个具有代表性的退化图像,以形成最终的评估集。
方法
作者利用基于 Qwen-Image 架构的多模态 diffusion 框架进行局部图像细化。如框架图所示,整个系统由三个主要部分组成:一个冻结的多模态编码器、一个变分自编码器 (VAE) 和一个可训练的 diffusion backbone。该框架接受输入图像 I、可选的参考图像 Iref、指示编辑区域的用户提供的涂鸦掩码 M 以及文本指令 y。第一个组件是冻结的 Qwen2.5-VL 编码器,它处理输入图像、参考图像(如果提供)、涂鸦掩码和文本指令,以生成高层级多模态调节 token c。这些 token 由方程 c=Eϕ(I,Iref,M,y) 定义,捕捉了任务的语义和指令意图,并通过联合注意力机制引导去噪过程。
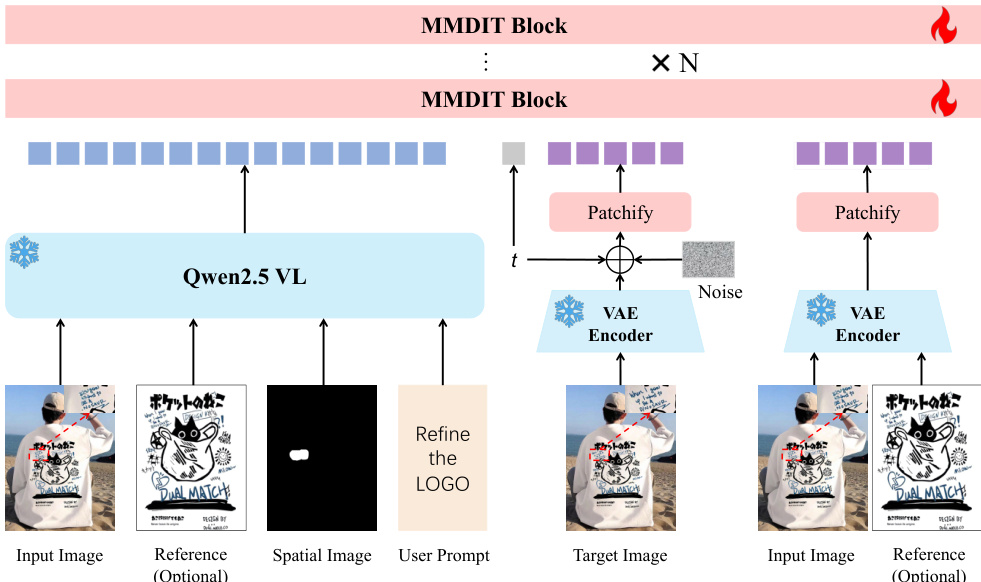
第二个组件是 VAE,它将输入图像和可选的参考图像编码为潜在表示 zI 和 zref。这些 VAE 潜在表示提供了低层级、细粒度的视觉上下文,这对于保留图像的结构细节至关重要。在训练期间,这些潜在表示与带噪声的目标潜在表示 zt 一起打包成 patch token 序列,并在输入 diffusion backbone 之前沿序列维度进行拼接。
第三个组件是去噪 backbone,如框架图所示,它由 MMDiT 块构建。该 backbone 在多模态 token c 和 VAE 潜在分支的共同调节下,迭代地从目标潜在表示 zt 中去除噪声。在推理时,过程始于噪声潜在表示 zT,在调度器(scheduler)的作用下逐步去噪以生成 z0。最终输出图像 I 通过使用 VAE 解码器对 z0 进行解码获得。对涂鸦掩码 M 的调节确保了细化被限制在指定区域内,同时保留了图像的其他部分。
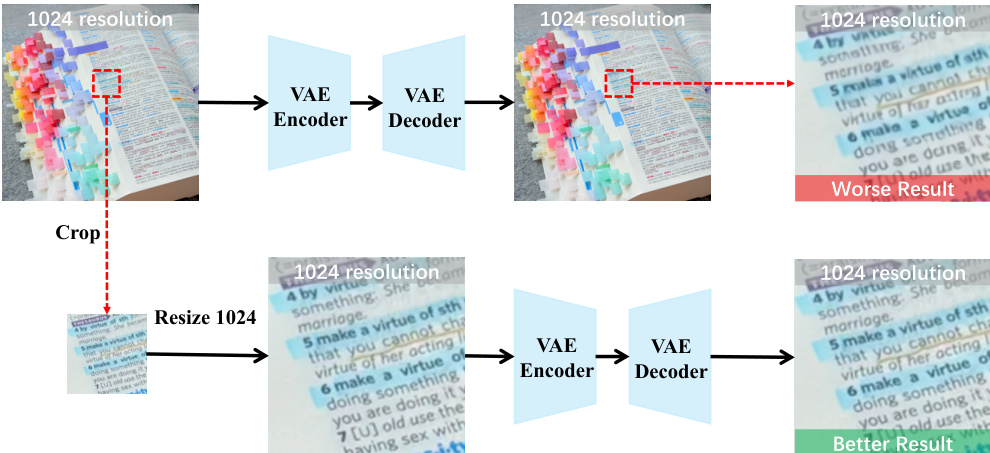
为了解决局部细化中分辨率预算有限的挑战,作者引入了 Focus-and-Refine 方法。如概览图所示,该方法包含三个阶段。首先,通过计算涂鸦掩码周围的紧凑边界框并进行边距扩展来定位感兴趣区域,从而创建一个聚焦裁剪区域(focus crop)。其次,模型在裁剪视图上执行聚焦生成,使用裁剪后的涂鸦掩码作为空间线索,并以输入、参考和文本指令为调节条件。这一聚焦生成步骤使用 RefineAnything 模型完成,其架构与框架图中所示相同。第三,为了避免可见的接缝,使用混合掩码将细化后的裁剪区域无缝地粘贴回原始图像。该混合掩码通过对裁剪掩码进行形态学膨胀和高斯平滑创建,然后用于将细化结果与原始图像进行合成。
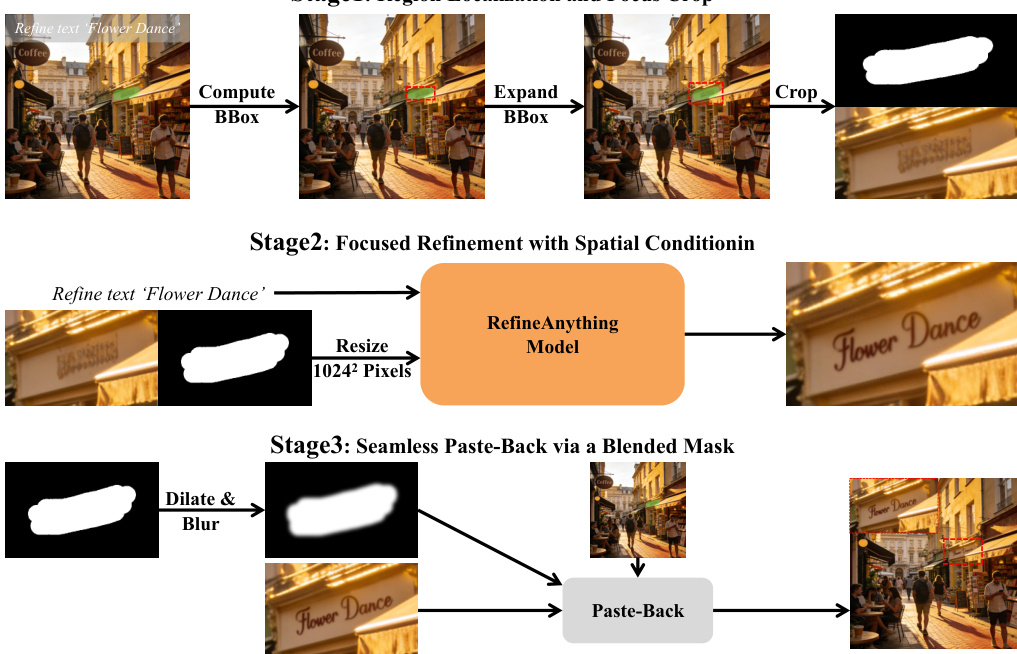
为了进一步增强粘贴回过程的自然度,作者在训练期间采用了边界一致性损失(boundary consistency loss)。该损失增加了编辑边界附近的监督权重,以确保平滑过渡。通过对裁剪掩码进行膨胀和腐蚀操作来定义一个边界带 Bc,该边界带用于对基础损失图进行加权,基础损失图是潜在空间中预测速度与目标速度之间的均方误差。总训练目标是边界加权损失的期望值。
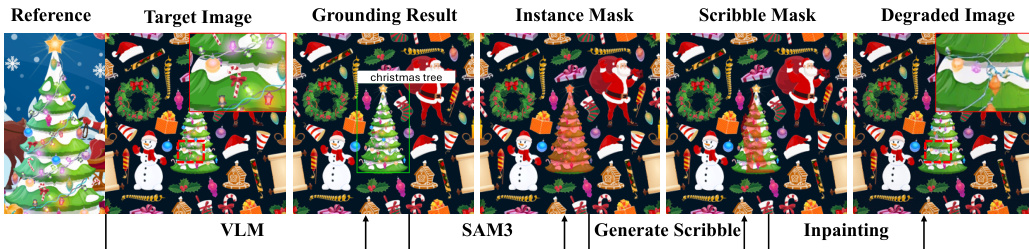
实验
评估利用 RefineEval 基准,通过编辑区域保真度和背景保留指标,对基于参考和无参考的图像细化进行评估。通过消融研究以及与具有竞争力的基准模型的对比,实验验证了 Focus-and-Refine 策略和 Boundary Consistency Loss 的有效性。结果表明,所提出的方法在保持近乎完美的背景一致性和无缝边界的同时,显著提高了局部细节恢复和语义对齐能力。
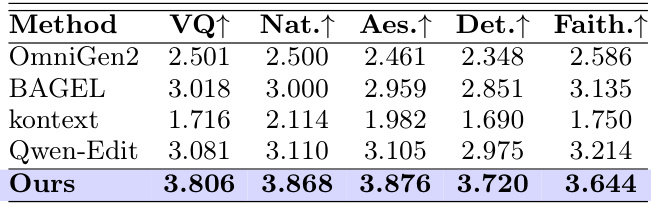
作者使用多维度评分系统,在无参考图像细化任务上将自己的方法与基准模型进行了对比。结果显示,该方法在所有评估维度上均取得了卓越的性能,在视觉质量、自然度、美感、细节保真度和指令忠实度方面均优于现有模型。我们的方法在视觉质量、自然度、美感、细节保真度和指令忠实度方面均超过了所有基准模型。与现有模型相比,该方法在所有五个评估维度上均获得了最高分。结果证明,该方法在生成既详细又忠实于输入指令的细化图像方面具有强大的性能。
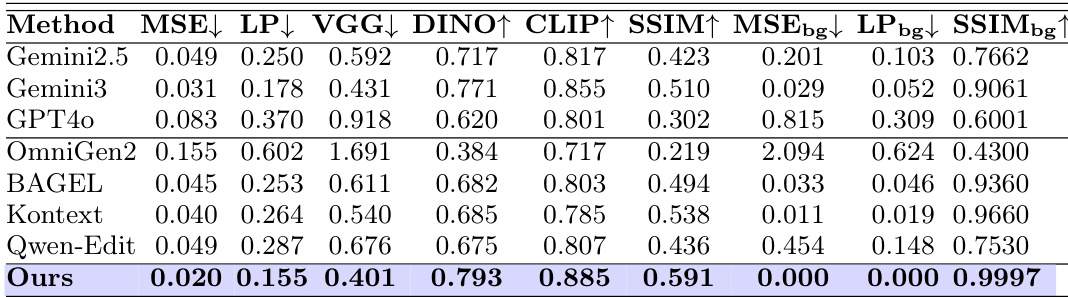
作者在基于参考的图像细化任务上将自己的方法与基准模型进行了对比,重点关注区域保真度和背景一致性。结果显示,该方法在多个指标上均取得了最佳性能,特别是在保留背景和提高局部细节准确性方面。所提出的方法在区域保真度和背景保留方面均优于基准模型。它实现了近乎完美的背景一致性,且重建误差极小。该方法在保持背景严格不变的同时,提高了局部细节的恢复能力。

作者在基于参考的图像细化任务上将自己的方法与多个基准模型进行了对比,衡量了编辑区域保真度和背景保留。结果显示,该方法在多个指标上均取得了最佳性能,特别是在维持背景一致性和提高局部细节质量方面。我们的方法在编辑区域保真度方面取得了最低的误差指标,包括 MSE 和 LPIPS。它保持了近乎完美的背景一致性,对非目标区域的改变极小。该方法在区域保真度和背景保留方面均优于所有基准模型,展示了卓越的综合性能。
作者通过无参考和基于参考的图像细化设置评估了其方法,以评估视觉质量和结构完整性。在无参考场景中,与现有基准相比,该方法表现出更优的指令忠实度和美学自然度。对于基于参考的任务,该方法擅长在保持近乎完美的背景一致性和区域保真度的同时,恢复局部细节。