Command Palette
Search for a command to run...
RationalRewards:通过推理 Rewards 在训练与测试阶段共同提升视觉生成的 Scale
RationalRewards:通过推理 Rewards 在训练与测试阶段共同提升视觉生成的 Scale
Haozhe Wang Cong Wei Weiming Ren Jiaming Liu Fangzhen Lin Wenhu Chen
摘要
大多数用于视觉生成的 reward model 会将丰富的人类判断简化为一个单一且缺乏解释性的分数,从而丢弃了偏好背后的推理过程。我们证明,通过教导 reward model 在评分前生成显式的、多维度的 critique,可以将它们从被动的评估者转变为主动的优化工具,并从两个互补的方向改进生成器:在训练阶段,结构化的 rationale 为 reinforcement learning 提供了可解释且细粒度的 rewards;在测试阶段,一个 Generate-Critique-Refine 循环能将 critique 转化为有针对性的 prompt 修订,从而在无需任何参数更新的情况下提升输出质量。为了在无需昂贵的 rationale 标注的情况下训练此类 reward model,我们引入了 Preference-Anchored Rationalization (PARROT)——这是一个原则性的框架,通过 anchored generation、consistency filtering 和 distillation,从易于获取的 preference 数据中恢复高质量的 rationale。由此产生的模型 RationalRewards (8B) 在开源 reward model 中实现了最先进的 preference 预测性能,足以媲美 Gemini-2.5-Pro,同时所使用的训练数据仅为同类基准模型的 1/10 到 1/20。作为一种 RL reward,它在提升 text-to-image 和 image-editing 生成器方面的表现持续优于传统的标量(scalar)替代方案。最引人注目的是,其测试阶段的 critique-and-refine 循环在多个 benchmark 上达到了与基于 RL 的 fine-tuning 持平甚至更优的效果,这表明结构化推理可以释放现有生成器中潜在的能力,而这些能力是次优 prompt 无法激发的。
一句话总结
通过利用 Preference-Anchored Rationalization (PARROT) 框架生成显式的、多维度的批判(critiques)以及评分,8B 参数的 RationalRewards 模型通过在训练时进行细粒度的强化学习,以及在测试时进行无需参数更新的 Generate-Critique-Refine 循环,提升了视觉生成质量。
核心贡献
- 本文介绍了 RationalRewards,这是一种基于推理的 reward model,它用结构化的、多维度的思维链(chain-of-thought)批判取代了不透明的标量分数,从而提供可解释且细粒度的反馈。
- 这项工作提出了 PARROT,这是一个变分框架,通过锚定生成(anchored generation)、一致性过滤(consistency filtering)和蒸馏(distillation),从现有的偏好数据中恢复高质量的理由(rationales),从而实现此类模型的训练。
- 所提出的方法展示了卓越的性能,通过比基线模型少 10 到 20 倍的训练数据实现了最先进的偏好预测,并实现了测试时的 Generate-Critique-Refine 循环,在无需更新参数的情况下提升了生成质量。
引言
随着视觉生成模型向更高的照片写实度和更好的指令遵循能力迈进,reward model 的质量已成为一个关键瓶颈。大多数现有的 reward model 充当标量黑盒,将感知质量和文本忠实度等复杂的人类判断压缩成一个单一的、无法解释的数字。这种透明度的缺失往往会导致 reward hacking,即生成器利用统计捷径而非学习原则性的评估标准。
作者介绍了 RationalRewards,这是一种基于推理的 reward model,它在分配分数之前会产生结构化的、多维度的批判。这种方法将 reward model 从被动评估器转变为主动优化工具,其工作方式有两种:在训练期间为强化学习提供细粒度、可解释的反馈;并在测试时通过 Generate-Critique-Refine 循环在不更新参数的情况下优化 prompt。为了在无需昂贵人工标注的情况下实现这一点,作者提出了 Preference-Anchored Rationalization (PARROT) 框架,该框架从现有的偏好数据中恢复高质量的理由。RationalRewards 在开源模型中达到了最先进的性能,通过其测试时的推理能力,达到或超过了昂贵的强化学习的效果。
数据集

作者使用以下方法开发了一个用于图像生成和编辑任务的推理标注数据集:
- 数据集构成与来源: 训练数据源自两个主要的偏好数据集:
- 图像编辑: 来自 EditReward 的 30,000 个查询-偏好对。
- 文本到图像生成: 来自 HPDv3 和 RapidData 的 50,000 个对。
- 数据处理与标注:
- 理由生成: 由于源数据集仅提供二元或排序标签,作者使用 PARROT 流水线,以 Qwen3-VL-32B-Instruct 作为教师模型,将原始偏好对转换为包含结构化推理理由的训练数据。
- 一致性过滤: 应用第二阶段一致性检查以移除幻觉或无信息的样本。该过程保留了大约 72% 生成的理由。
- 数据规模与效率:
- 过滤后的最终数据集包含约 57,600 个样本(从 80,000 个原始对减少而来)。
- 作者指出,由于蒸馏结构化理由而非原始标签的效率更高,这一规模比 EditReward 或 UnifiedReward 等同类基线模型小 10 到 20 倍。
- 特定任务配置:
- 对于文本到图像生成,输入被修改为仅包含两个生成的图像,而不包含源图像。
- 这些任务移除了“图像忠实度”维度,并将指令调整为根据用户 prompt 对比图像。
- 每个成对样本被处理成两个点对点投影样本用于训练。
方法
作者利用一个三阶段流水线 Preference-Anchored Rationalization (PARROT) 来训练一个 reward model,该模型在评分前会产生显式的、多维度的理由。该框架在一个变分推理框架内运行,将理由视为解释源自成对比较数据的偏好的人类偏好的隐变量。整个过程分解为不同的阶段:理由生成、预测一致性过滤和前瞻蒸馏,这些阶段共同构成了一个基于证据下界 (ELBO) 的结构化学习程序。
第一阶段是理由生成,它采用教师视觉语言模型 (VLM) 从比较元组 x=(IA,IB,c) 中为给定的偏好 y(例如 A≻B)推断出自然语言解释 z,其中 IA 和 IB 是生成的图像,c 是条件用户请求。这一阶段被实现为一个“事后”过程,其中教师模型显式地以地面真值(ground-truth)偏好标签 y 为条件来生成理由。这种偏好锚定确保了生成的解释专注于证明观察到的偏好,使模型的概率质量集中在连贯且相关的理由上,而不是开放式、无引导的评估。理由的结构旨在评估四个关键维度:文本忠实度、图像忠实度、物理/视觉质量和文本渲染,每个维度按 1-4 分进行评分。
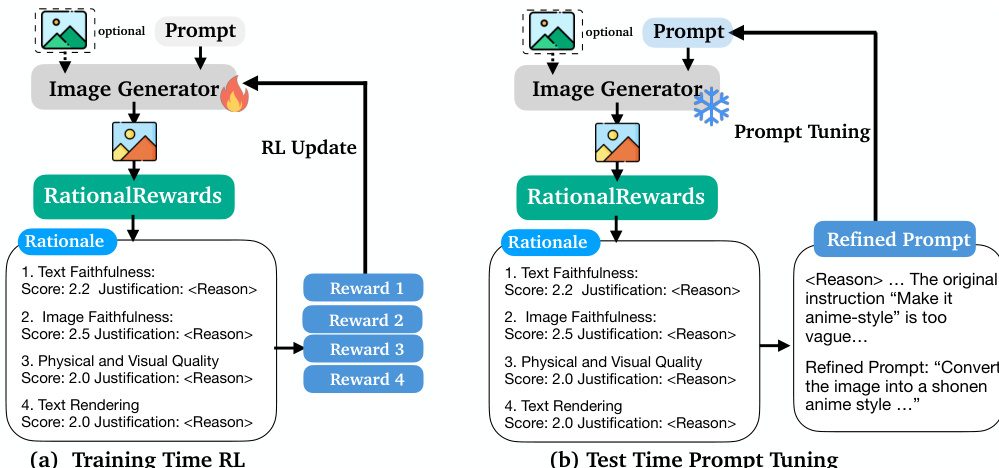
第二阶段是预测一致性过滤,旨在解决生成语言上合理但语义不足的理由的问题。虽然第一阶段产生的理由是以已知偏好为条件的,但一个理由必须能够预测该偏好才有效。为了强制执行这一点,作者通过仅使用生成的理由 z 而不使用偏好标签重新查询教师 VLM 来进行一致性检查。模型被要求仅根据理由来预测偏好 y。只有当预测的偏好与原始地面真值标签匹配时,(x,y,z) 三元组才会被保留用于训练。这个过程最大化了 ELBO 的第一项,过滤掉了幻觉或信息量不足的理由,确保剩余的理由在因果上足以解释观察到的偏好。

第三阶段是前瞻蒸馏,训练学生模型 Pθ(z∣x) 在无法获取偏好标签的情况下生成理由,从而有效地学习“前瞻”能力。这是通过在第一、二阶段过滤后的后验样本上进行监督微调 (SFT) 实现的。目标是最小化学习到的学生先验 Pθ(z∣x) 与固定的变分后验 qϕ(z∣x,y) 之间的 KL 散度,这等同于最大化学生模型生成过滤后理由的期望对数似然。这产生了一个学生模型,它可以为给定的输入图像和 prompt 生成连贯的、多维度的理由,使其能够作为一个点对点 reward 评估器。
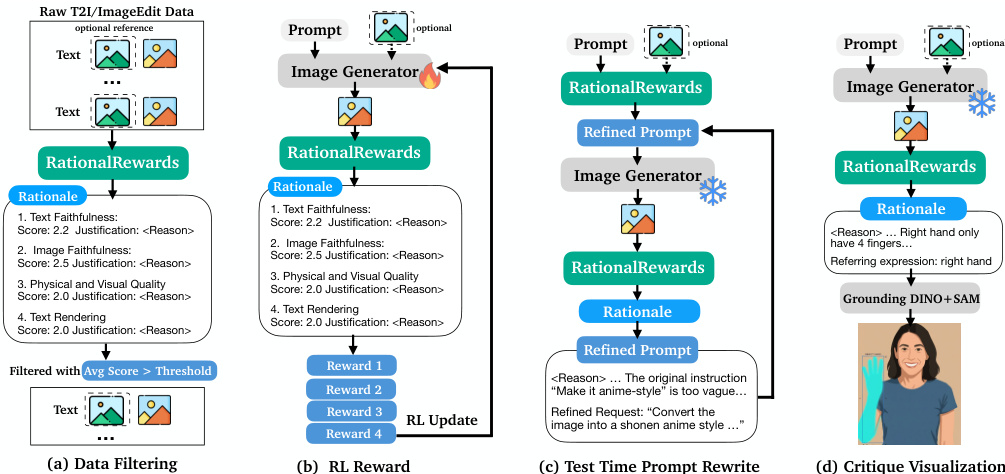
训练好的模型 RationalRewards 设计用于在参数空间和 prompt 空间进行双重部署。对于参数空间优化,多维度分数被聚合为一个标量 reward,用于指导 DiffusionNFT 等强化学习算法。对于 prompt 空间优化,自然语言理由被用于对原始用户 prompt 进行有针对性的细化,从而在测试时实现 Generate-Critique-Refine 循环。这使得无需任何参数更新即可实现高质量的图像生成,利用模型内化的偏好目标来引导 prompt 细化。
实验
实验通过两种优化策略评估了 RationalRewards 在改进文本到图像生成和图像编辑方面的效用:通过强化学习 (RL) 进行参数空间微调,以及通过测试时的批判与细化进行 prompt 空间微调。在包括 ImgEdit-Bench 和 UniGen 在内的多个基准测试中的结果表明,由 RationalRewards 引导的 RL 一致地优于标量 reward model 和通用的推理基线。值得注意的是,推理时的 prompt 微调提供的改进与计算昂贵的 RL 相当甚至更高,这表明模型的潜在能力是通过结构化批判而非仅仅通过权重修改而被有效激发的。
表格显示了研究中使用的三个数据集在过滤后从原始对减少到最终样本的过程。过滤过程显著减少了原始对的数量,同时增加了高质量点对点样本的比例。原始对经过过滤后产生了一组较小的、高质量的最终样本。过滤过程增加了每个数据集的点对点样本密度。数据集在原始对数量和过滤后的最终样本数量上有所不同。

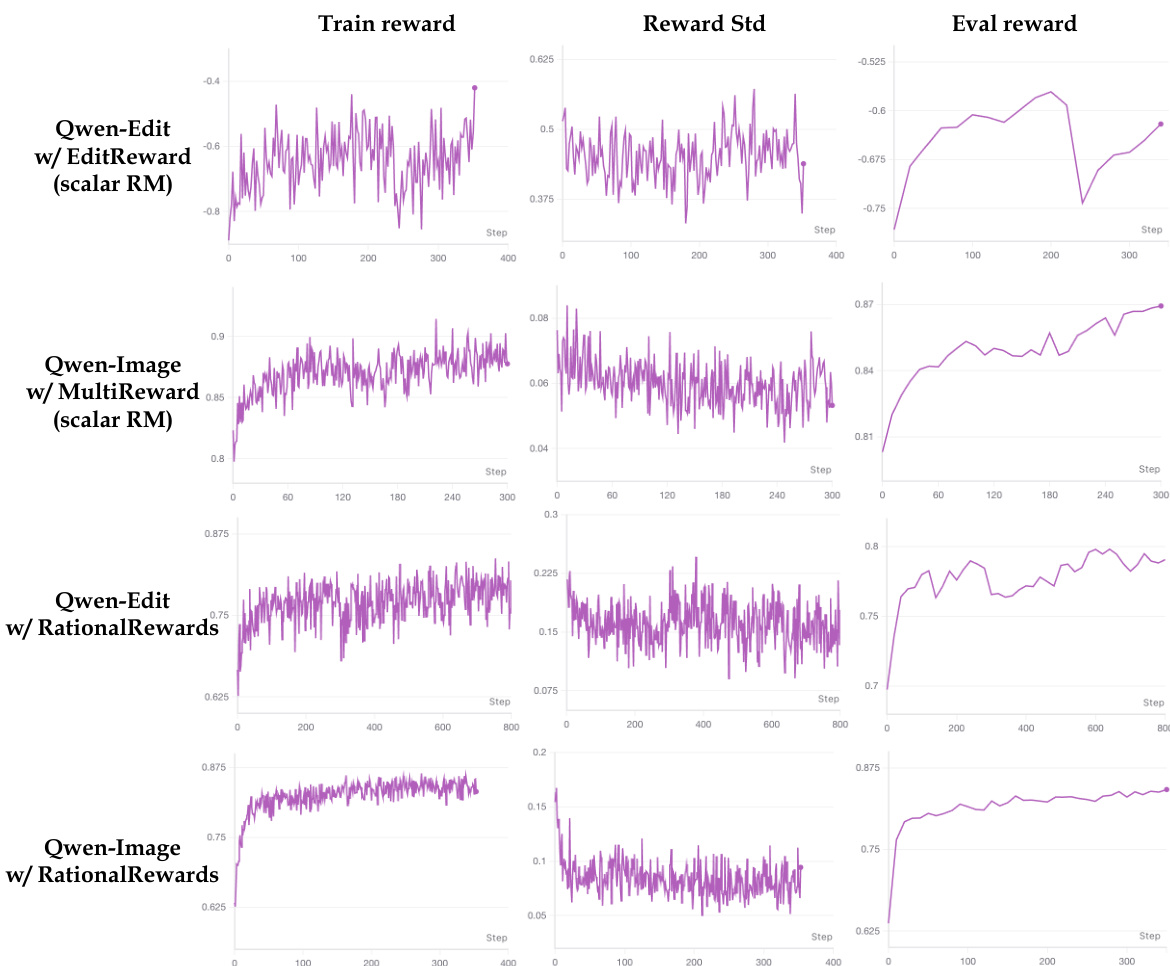
作者比较了不同 reward model 的训练动态,结果表明与标量 reward model 相比,RationalRewards 带来了更稳定且收敛的 reward 信号。RationalRewards 的训练 reward 和评估 reward 曲线随时间表现出更平滑的行为和更小的方差。RationalRewards 产生的训练 reward 信号比标量 reward model 更稳定。使用 RationalRewards 时,reward 标准差随时间降低,表明训练稳定性提高。使用 RationalRewards 时,评估 reward 曲线与目标基准很好地对齐。
{"caption": "RationalRewards 在基准测试上的消融实验", "summary": "作者在多个基准测试中评估了 RationalRewards,将其性能与标量和基于推理的 reward model 进行比较。结果显示 RationalRewards 一致优于基线,在文本到图像和编辑任务上均获得更高分数,在参数空间和 prompt 空间优化方面均有显著改进。", "highlights": ["在所有评估的基准测试中,RationalRewards 的性能均优于标量和通用推理基线。", "使用 RationalRewards 进行 prompt 微调的效果达到或超过了计算昂贵的参数空间微调。", "RationalRewards 在文本到图像和图像编辑任务上均表现出强劲的增益,证明了其在不同领域的广泛适用性。"]}
作者在多个属性上比较了各种模型的性能,包括文本忠实度、图像质量和推理能力。结果表明,通过 RationalRewards 增强的模型在大多数类别中一致优于基线模型,特别是在需要复杂推理和多维度评估的任务中。使用 RationalRewards 的模型在多个属性上的总体得分高于基线模型。RationalRewards 一致地提高了复杂推理和多维度评估任务的性能。增强后的模型在文本忠实度和图像质量指标上表现出显著增益。
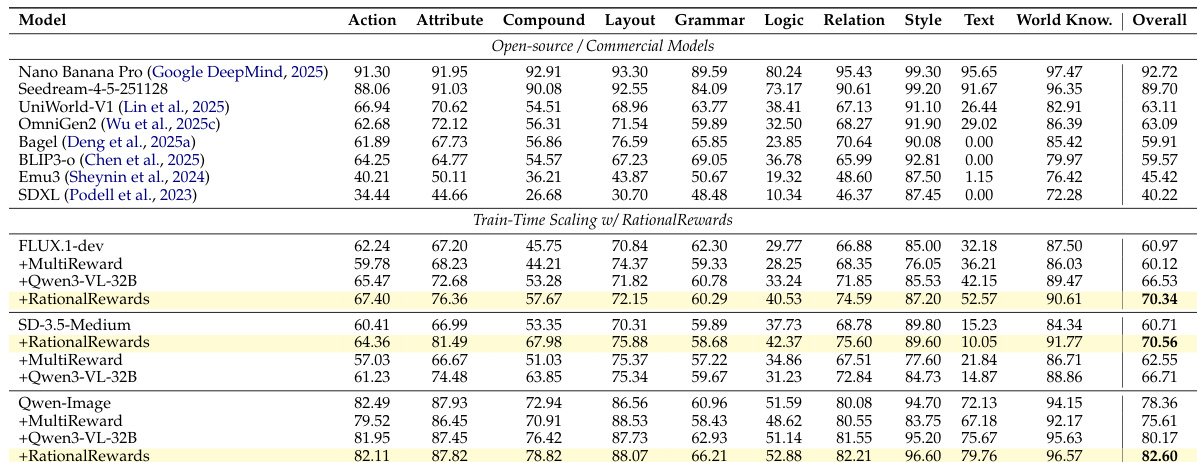
作者进行了消融研究,以评估 RationalRewards 在图像和文本到图像生成任务的双空间优化中的性能。结果显示,与标量和通用推理基线相比,在各个基准测试中均有持续改进,其中 prompt 微调取得了与参数空间微调相当或更好的结果。RationalRewards 在参数空间和 prompt 空间微调中均优于标量和通用推理基线。Prompt 微调实现了与计算昂贵的参数空间微调相当或更好的结果。RationalRewards 在训练期间实现了稳定的 reward 梯度并减少了 reward hacking。

该研究通过数据过滤过程、训练稳定性比较以及在各种文本到图像和编辑基准测试上的消融研究来评估 RationalRewards。结果表明,与标量模型相比,RationalRewards 提供了更稳定且收敛的 reward 信号,同时显著提高了文本忠实度、图像质量和复杂推理方面的性能。此外,该方法实现了高效的 prompt 微调,其效果达到或超过了计算昂贵的参数空间优化。