Command Palette
Search for a command to run...
GTR:引导式思维强化通过防止 RL 基础的 VLM Agent 训练中的思维崩溃(Thought Collapse)来提升性能
GTR:引导式思维强化通过防止 RL 基础的 VLM Agent 训练中的思维崩溃(Thought Collapse)来提升性能
Tong Wei Yijun Yang Junliang Xing Yuanchun Shi Zongqing Lu Deheng Ye
摘要
基于可验证结果奖励的强化学习(Reinforcement Learning with Verifiable Outcome Rewards, RLVR)已有效地提升了大语言模型(LLMs)在思维链(Chain-of-Thought, CoT)推理方面的规模。然而,这种方法在训练视觉语言模型(VLM)Agent 以实现在视觉环境中的目标导向动作推理方面的有效性尚未得到充分证实。本研究通过在复杂的卡牌游戏(如“24点”)以及来自 ALFWorld 的具身任务(Embodied tasks)上进行广泛实验,对这一问题进行了深入探讨。我们发现,当奖励完全基于动作结果时,RL 无法激励 VLM 进行 CoT 推理,反而会导致一种我们称之为“思维坍塌”(Thought Collapse)的现象。其特征表现为:Agent 的思维多样性迅速丧失、推理过程与当前状态无关且不完整,并由此导致后续动作无效,最终产生负面奖励。为了应对“思维坍塌”,我们强调了过程引导(Process Guidance)的必要性,并提出了一种自动化修正器(Automated Corrector),用于在每个 RL 步骤中对 Agent 的推理进行评估和优化。这种简单且具备可扩展性的 GTR(Guided Thought Reinforcement,引导式思维强化)框架能够同时训练推理与动作,且无需密集的人工逐步标注。实验结果表明,GTR 显著提升了 LLaVA-7B 模型在各种视觉环境下的性能和泛化能力;与现有最先进(SoTA)模型相比,GTR 在模型参数量显著更小的情况下,实现了高出 3 到 5 倍的任务成功率。
一句话总结
为了抵消视觉 - 语言模型 Agent 因仅结果奖励导致的思维坍塌,作者提出了 GTR(Guided Thought Reinforcement)框架,该框架利用自动修正器评估并细化每一步的推理,无需密集的每步人工标注,使 LLaVA-7B 模型在各种视觉环境中的任务成功率比 SoTA 模型高出三到五倍。
核心贡献
- 论文实证识别了一种称为思维坍塌的现象,即视觉 - 语言模型在强化学习过程中因仅结果奖励而丧失推理多样性。这一发现表明,标准训练无法激励复杂视觉环境中的思维链推理。
- 该工作引入了 Guided Thought Reinforcement 框架,利用自动修正器在强化学习的每一步评估并细化推理。该方法允许同时训练推理和行动,无需密集的每步人工标注。
- 实验结果表明,该框架显著提升了 LLaVA-7B 模型在各种视觉环境中的性能和泛化能力。该方法在利用明显更小的模型规模的同时,实现了比最先进模型高出三到五倍的任务成功率。
引言
虽然具有可验证结果奖励的强化学习已成功扩展了大语言模型中的思维链推理,但在动态视觉环境中训练视觉 - 语言模型 Agent 时效果较差。现有仅依赖最终行动奖励的方法常导致思维坍塌,即 Agent 的推理多样性迅速退化为与状态无关的模式,从而导致无效行动。作者提出 Guided Thought Reinforcement 以通过利用自动修正器在强化学习的每一步评估并细化推理来抵消此问题。该框架提供了必要的过程指导,无需密集的人工标注,使模型能够在卡牌游戏和具身任务等复杂场景中实现显著更高的任务成功率。
数据集
-
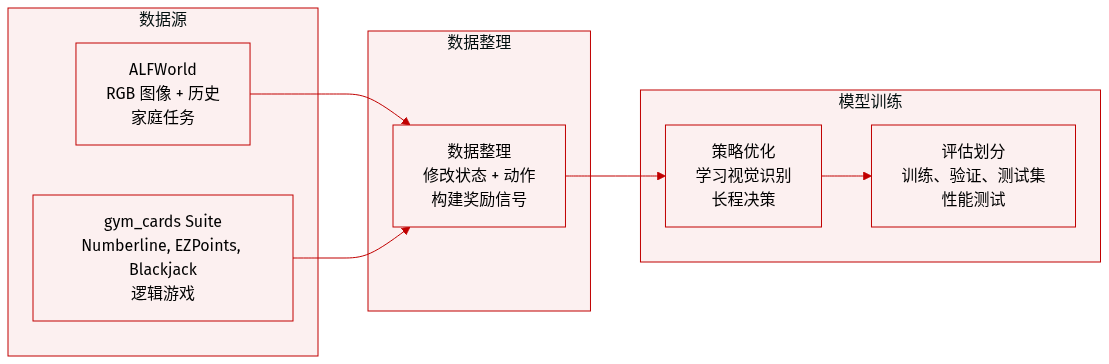
数据集组成与来源
- 作者利用两个仿真环境进行数据生成:ALFWorld 用于具身家庭任务,gym_cards 套件用于更简单的逻辑游戏。
- 这些环境提供状态 - 行动序列,作为训练和评估的基础。
-
每个子集的关键细节
- ALFWorld: 状态包括 RGB 观测图像和过去的行动历史。行动空间涵盖 go to、take、put、open、close、toggle、clean、heat 和 cool 等交互。
- Numberline: Agent 调整当前整数以在五步内使用加法或减法匹配 0 到 5 之间的目标值。
- EZPoints: 此简化版 Points24 变体要求使用两张牌在恰好四步内求解目标值 12。
- Blackjack: Agent 与庄家对战,具有部分卡牌可见性,并选择 hit 或 stand 行动以赢得游戏。
-
数据使用与处理
- 状态修改: 作者移除了 ALFWorld 中的文本场景描述,以强制依赖视觉观测并增加任务难度。
- 元数据构建: 行动序列被附加到状态历史中,以更好地模拟现实场景并测试长视野决策。
- 奖励信号: 奖励函数为达成目标或子目标授予分数,并对非法行动施加惩罚以指导策略优化。
方法
作者提出了一个名为 GTR(Guided Thought Reinforcement)的框架,以增强视觉 - 语言模型(VLMs)在序列决策任务中的推理能力。该方法结合监督微调(SFT)与近端策略优化(PPO),同时优化 Agent 的推理思维及其行动。
参考框架图以了解系统架构概述。该过程涉及三个主要组件:VLM Agent、VLM Corrector 和 RL 微调循环。VLM Agent 与环境交互,生成包含思维链(CoT)推理和具体行动的文本文本。为确保 Agent 从高质量推理中学习,外部 VLM 充当修正器模型。该修正器评估 Agent 生成的思维在视觉识别准确性和逻辑一致性方面。如果检测到不一致或错误,修正器模型将细化原始思维。该框架通过对思维 token 应用 SFT 损失来使 Agent 的推理与这些修正轨迹对齐,而 PPO 损失则根据环境奖励优化行动 token。
核心强化学习算法遵循用于微调 VLMs 的标准 PPO 框架。后处理函数从 VLM 的文本文本输出中提取关键词"action : a"以确定执行的操作。如果输出缺少此关键词,Agent 默认通过从合法行动集合 A 中选择行动来进行随机探索。形式上,给定 VLM 的输出 vout 和合法行动集合 A,后处理函数 f 定义为:
f(vout)={a,Unif(A),if "action: a"∈ voutotherwise策略梯度所需的行动概率从输出文本中每个 token 的生成概率计算得出。采用缩放因子 λ 以平衡 CoT 输出与行动输出相比更长的长度。如果 πθ 表示策略,ot 和 at 代表观测和行动,vtth 和 vtact 分别代表 CoT 推理 token 和行动 token,则计算如下:
logπθ(at∣ot,vtin)=λlogπθ(vtth∣ot,vtin)+logπθ(vtact∣ot,vtin,vttht)=λ∑logp(ot,vtin,v[:i−1]tht)p(ot,vtin,v[:i]tht)+∑logp(ot,vtin,vttht,v[:i−1]act)p(ot,vtin,vttht,v[:i]act)GTR 的目标结合了行动的 PPO 损失和思维的 SFT 损失。如果论文将 Agent 的思维输出表示为 th,行动表示为 a,给定 Agent 模型 πθ 和修正器模型 πcorr,目标表示为:
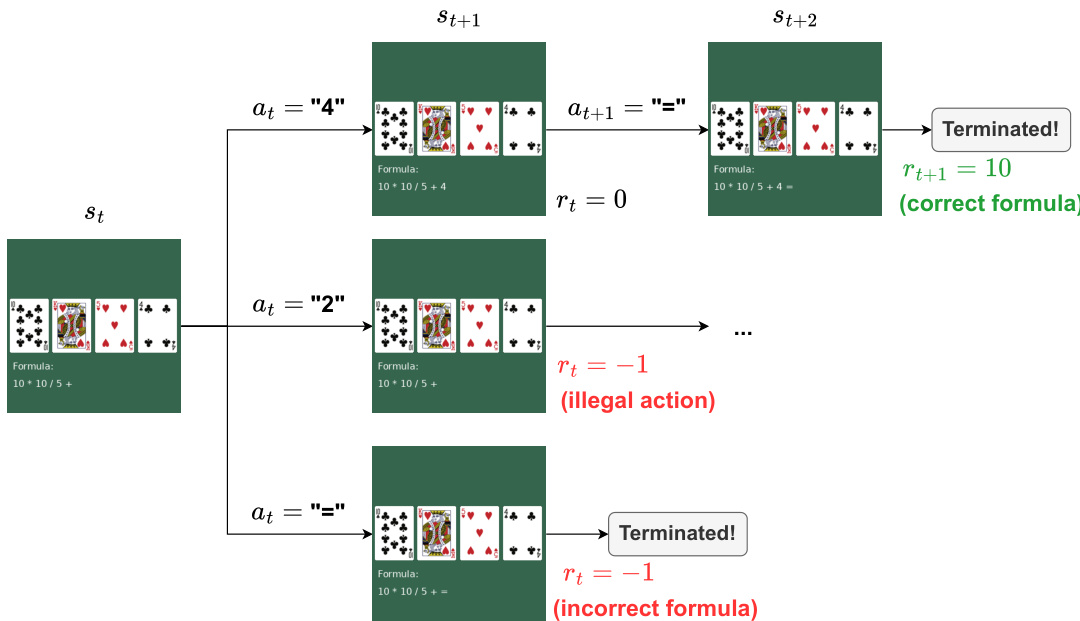
θminEo,(th,a)∼πθ[LPPO(o,a)+LSFT(o,πcorr(o,th))]如下图所示,该框架应用于特定环境,如 Points24 卡牌游戏。在此任务中,Agent 观察四张牌的图像和当前公式。目标是形成等于 24 的公式。环境根据行动的有效性和最终结果提供奖励。例如,非法行动产生 −1 的奖励,而合法行动产生 0。如果回合以评估为 24 的正确公式结束,Agent 获得 10 的奖励。
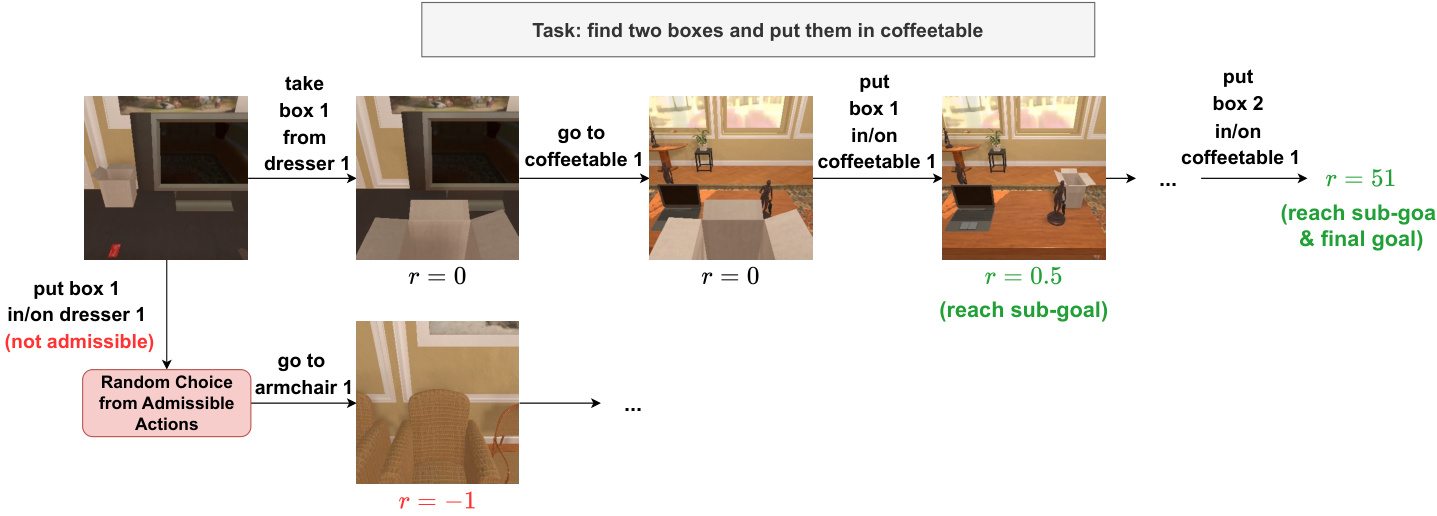
该方法也适用于更复杂的机器人操作任务,如任务执行流程所示。在此类环境中,Agent 必须导航、拾取物体并将其放置在指定位置。奖励结构鼓励在实现最终目标之前达到子目标,例如将盒子放在桌子上。这种分层奖励信号有助于指导 Agent 完成长视野任务。
为了解决将思维克隆纳入 PPO 训练时出现的分布偏移问题,作者采用了一种称为数据集聚合(DAgger)的交互式模仿学习算法。随着 Agent 策略的更新,先前的数据被丢弃并重新采样。在此非独立同分布数据集上执行思维克隆可能导致灾难性遗忘。通过聚合所有历史修正和样本,DAgger 方法确保收敛到由修正器模型提供的专家策略。目标函数被重写以分离 PPO 数据缓冲区 B 和 DAgger 思维数据集 D 的期望:
θmin(s,a)∼BELPPO(s,a)+(s,th)∼DELSFT(s,πcorr(s,th)).最后,为了提高 RL 训练期间的数据质量,作者加入了 token 级重复惩罚,并明确将格式判断集成到修正器模型中。这确保了具有有效格式的答案在每一步都能获得格式奖励。此外,修正器模型可以利用函数调用能力访问特定信息,例如计算 Points24 游戏中的可能方程。此能力允许数据采样控制,如果 Agent 进入不可解状态,回合可被截断,从而提高 RL 训练的效率。
实验
该研究在复杂的 Points24 推理任务和 multimodal ALFWorld 基准上评估 Guided Thought Reinforcement 框架,以评估长视野决策中的性能。实验表明,过程指导有效防止了思维坍塌,使 Agent 能够比仅依赖结果奖励的基线强化学习方法实现显著的性能提升。此外,消融分析确认,保持连续的思维监督和利用有能力的修正器模型对于稳定训练和确保整个学习过程中推理连贯性至关重要。
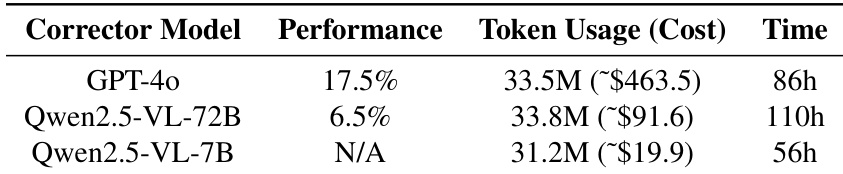
该研究评估了在使用不同修正器模型时 GTR 框架的性能与计算开销之间的权衡。GPT-4o 提供最高的成功率,但伴随最高的财务成本和训练时长。开源替代品提供成本节约,但在性能方面挣扎,其中较大模型因工具使用问题表现不佳,较小模型无法遵循修正格式。GPT-4o 实现最佳任务成功率,但比开源模型需要显著更多的时间和财务资源。Qwen2.5-VL-72B 模型相比 GPT-4o 具有成本优势,但性能大幅下降。Qwen2.5-VL-7B 模型是最资源高效的选项,但无法遵循有效训练所需的必要修正格式。
作者在 Points24 任务上评估 GTR 框架,展示了其相对于包括商业模型和标准强化学习方法在内的各种基线的优越性能。结果表明,GTR 实现了最高的成功率和回合回报,显著优于缺乏过程指导的方法。这些发现验证了将自动思维修正与强化学习集成用于复杂视觉推理任务的有效性。GTR 在所有评估模型中展示了最高的成功率和回合回报。该方法显著优于强化学习基线和仅 SFT 方法。商业模型和其他基线相比 GTR 难以有效解决该任务。
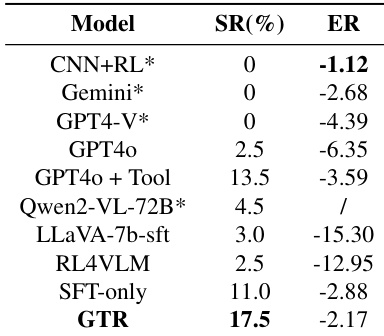
该表评估了 gym_cards 环境中更简单任务上的模型性能,具体为 Numberline、EZPoints 和 Blackjack,其中决策空间较小。提出的 GTR 框架展示了稳健的能力,在实现与更大模型相当结果的同时,显著优于其他 7B 参数基线。GTR 在 Numberline 任务上实现了完美的成功率,与显著更大的 Qwen2-VL 模型的性能相匹配。在 EZPoints 任务上,GTR 在成功率和回合回报方面大幅优于 RL4VLM 基线。该框架在所有三个评估任务上显示出相对于仅 SFT 方法的持续改进。
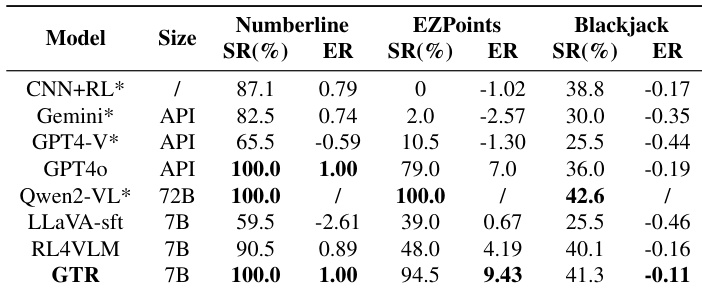
该表评估了 ALFWorld 具身任务上的视觉 - 语言模型,区分了利用文本观测的配置和仅依赖视觉输入的配置。提出的 GTR 框架在无文本辅助的模型中展示了优越性能,实现了最高的平均分数并在特定类别中领先。利用文本描述的模型通常比仅限制于视觉输入的模型实现更高的平均分数。GTR 在无文本设置中优于其他基线,特别是在涉及冷却和拾取多个物体的任务中表现出色。MiniGPT-4 在 Look 任务中显示出明显优势,而 LLaMA-Adapter 在 Heat 相关场景中表现显著良好。
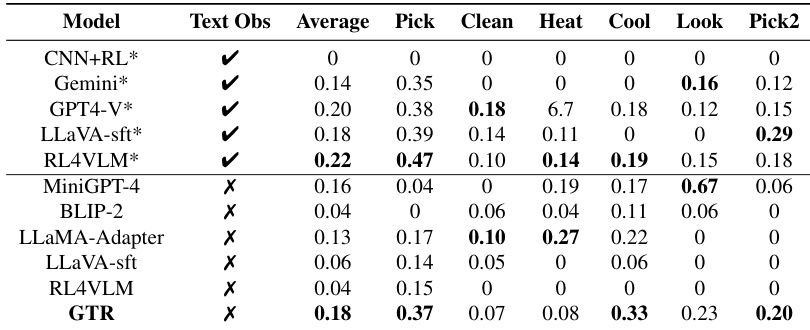
提供的数据评估了 GTR 框架和 RL4VLM 基线在 ALFWorld 基准上的成功率,具体比较了有无文本场景描述的性能。结果表明,虽然基线方法严重依赖文本来成功,但 GTR 即使在移除文本描述时也保持高性能。这表明 GTR 有效利用视觉信息和过程指导来解决复杂任务,而不依赖文本捷径。GTR 在基线方法严重失败的无文本设置中保持稳健性能。当提供文本描述时,两种方法实现可比的成功率。当文本输入不可用时,该框架展示了优于基线的视觉推理能力。
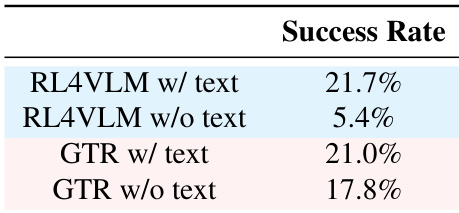
本研究通过比较修正器模型权衡并在 Points24、gym_cards 和 ALFWorld 任务上对标各种基线来评估 GTR 框架。虽然 GPT-4o 产生最高的成功率,但开源替代品因工具使用和格式遵循挑战而遭受显著性能下降。该框架始终优于强化学习和监督微调方法,验证了其在复杂视觉推理中的有效性,并在没有文本场景描述的情况下保持稳健结果。