Command Palette
Search for a command to run...
重新思考 Large Language Models 的 On-Policy Distillation:现象学、机制与方法论
重新思考 Large Language Models 的 On-Policy Distillation:现象学、机制与方法论
摘要
On-policy distillation (OPD) 已成为大语言模型(LLM)后训练(post-training)阶段的核心技术,然而其训练动力学(training dynamics)仍缺乏深入研究。本文对 OPD 的动力学及其机制进行了系统性的调查。我们首先发现,OPD 的成功与否受两个条件的制约:(i) 学生模型与教师模型应具备兼容的思维模式;(ii) 即使思维模式一致且得分更高,教师模型也必须提供学生在训练期间未曾见过的、真正具有新增能力的知识。我们通过“弱到强”的反向 distillation(weak-to-strong reverse distillation)验证了这些发现,结果表明,从学生模型的视角来看,同家族的 1.5B 和 7B 教师模型在分布上是无法区分的。通过对 token 级机制的深入探究,我们发现成功的 OPD 特征在于:在学生模型访问过的状态下,模型会在高概率 token 上实现渐进式的 alignment,即存在一个较小的共享 token 集合,该集合集中了绝大部分的概率质量(97%-99%)。此外,针对失败的 OPD,我们进一步提出了两种实用的恢复策略:off-policy 冷启动(off-policy cold start)和教师对齐的 prompt 选择(teacher-aligned prompt selection)。最后,我们指出,OPD 表面上看似通过密集的 token 级 reward 获得了“免费午餐”,但实际上是有代价的,这引发了一个疑问:OPD 是否能够扩展到长程 distillation(long-horizon distillation)任务中。
一句话总结
通过对大语言模型后训练中 on-policy distillation (OPD) 动态机制的系统性研究,本文发现其成功取决于兼容的思维模式和 teacher 的新颖性,揭示了一种以高概率 tokens 的渐进式对齐为特征的 token 级机制,并提出了 off-policy cold start 和 teacher-aligned prompt selection 策略来挽救失败的 distillation 过程。
核心贡献
- 本文确定了成功进行 on-policy distillation 的两个基本条件:student 与 teacher 之间需要具备兼容的思维模式,以及 teacher 必须提供 student 在训练期间未曾接触过的真正新能力。
- 研究揭示了一种 token 级机制,即成功的 distillation 以 student 访问状态下高概率 tokens 的渐进式对齐为特征,其中一小部分共享 token set 集中了 97% 到 99% 的概率质量。
- 引入了两种实用策略:off-policy cold start 和 teacher-aligned prompt selection,用于在未满足上述成功条件时恢复 distillation 性能。
引言
On-policy distillation (OPD) 已成为大语言模型后训练中至关重要的技术,因为它提供了密集的、逐 token 的监督,从而缓解了 off-policy 方法中存在的 exposure bias。然而,OPD 通常是脆弱的,从业者经常遇到更强的 teacher 无法提升 student 模型的场景。作者通过研究发现,成功的 distillation 需要模型之间兼容的思维模式,以及 student 尚未掌握的真正新知识的存在,从而解释了这种不稳定性。为了解决这些失败情况,作者提出了两种实用策略:通过 off-policy cold start 来弥合思维模式差距,以及通过 teacher-aligned prompt selection 来强化对齐。
数据集
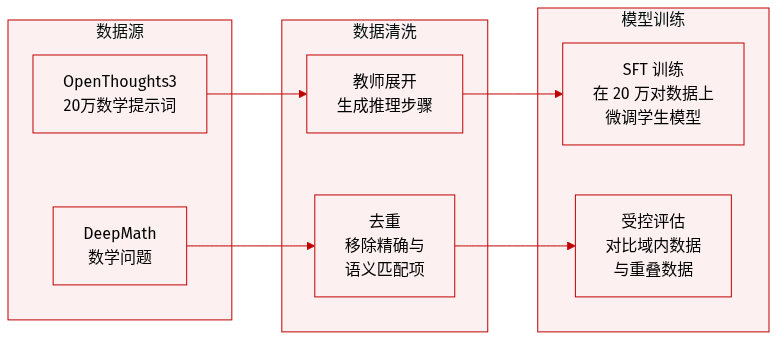
作者构建了多个专门的数据集,以促进 cold-start distillation 和受控评估:
- Cold-Start SFT 数据集:为了初始化 student 模型,作者从 OpenThoughts3-1.2M 的数学子集中采样了 200,000 个数学 prompts。这些 prompts 通过使用 Qwen3-4B (Non-thinking)、temperature 为 0.7 且最大生成长度为 12,288 tokens 的离线 teacher rollout 进行处理。生成的数据集经过过滤,以移除不完整或退化的重复响应。
- DeepMath 去重子集:为了进行跨规模实验,作者创建了一个 DeepMath 子集的版本,该版本针对 DAPO-Math-17K 进行了去重,以将领域内 prompts 与出现在 teacher RL 后训练数据中的 prompts 区分开来。该过程包含两个阶段:
- 精确匹配去重:移除指令后缀,任何与 DAPO-Math-17K 问题完全匹配的 DeepMath 问题都会被丢弃。
- 语义去重:使用 all-mpnet-base-v2 模型对问题进行编码。利用 FAISS 索引,作者通过计算余弦相似度来识别近乎重复的问题。任何与 DAPO-Math-17K 中最近邻相似度得分达到 0.6 或更高的 DeepMath 问题都会被移除。
- 模型训练与使用:
- 过滤后的 200,000 个 teacher 生成的对被用于 Qwen3-1.7B-Base 模型的全参数监督微调 (SFT),从而产生 Qwen3-1.7B-SFT。
- 去重的 DeepMath 子集用于在与 teacher 后训练数据重叠的 prompts 与严格领域内的 prompts 之间进行受控比较。
方法
作者提出了一个 On-Policy Distillation (OPD) 框架,该方法通过最小化在从当前 student policy 采样的轨迹上,student 与 teacher 的 next-token 分布之间的差异,将知识从 teacher 语言模型 πT 转移到 student 模型 πθ。核心机制在 on-policy 设置下运行,对于从数据集 Dx 中抽取的每个 prompt x,student 通过自回归采样生成响应 y^=(y^1,…,y^T)。在每个步骤 t,会将 student 的分布 pt(v)=πθ(v∣x,y^<t) 与 teacher 的分布 qt(v)=πT(v∣x,y^<t) 进行比较。主要目标是最小化 student 和 teacher 生成轨迹之间的序列级反向 Kullback-Leibler (KL) 散度,该散度可以分解为整个 rollout 过程中逐 token KL 散度的总和。

如上图所示,整体框架由三个相互关联的部分组成。第一部分“现象学 (Phenomenology)”识别了区分有效 OPD 的两个经验模式:一致的思维模式,以及观察到更高的分数并不一定意味着获得了新知识。核心部分“机制 (Mechanism)”解释了 OPD 为何在 token 级别有效,强调了高概率 tokens 的渐进式对齐主导了这一过程,并且仅靠重叠 tokens 就足以实现有效的 distillation。最后一部分“方案 (Recipe)”提出了两种策略来挽救失败的 OPD 实例,即通过弥合思维模式差距,具体包括 off-policy cold start 和 teacher-aligned prompts。
该框架包含三种不同的 OPD 实现方式,其区别在于用于计算 KL 散度的监督粒度。最轻量级的变体 sampled-token OPD 仅在每个步骤中 student 采样的特定 token 处评估散度,使用损失函数 ℓtsample=logpt(y^t)−logqt(y^t)。相比之下,full-vocabulary OPD 在每个步骤计算整个词表上的 KL 散度,提供了更密集的梯度,但计算成本更高。Top-k OPD 提供了一种折中方案,将散度计算限制在词表的子集 St 中,通常是 student 分布下概率最高的 top-k tokens。这种方法在显著减少 teacher 查询次数的同时,近似了 full-vocabulary KL 散度,将监督重点放在 student 的高概率区域。作者进一步定义了用于监控 distillation 过程的指标,包括衡量 student 与 teacher 的 top-k 集合之间对齐程度的 overlap ratio,评估重叠 tokens 内分布一致性的 overlap-token advantage,以及追踪两个模型之间不确定性差异的 entropy gap。
实验
这些实验通过比较各种 teacher-student 模型配对和训练配置,研究了控制 On-Policy Distillation (OPD) 有效性的条件和机制。结果表明,成功的 distillation 取决于思维模式的一致性和新知识的存在,而非仅仅取决于基准测试性能或模型规模。从机制上看,有效的 OPD 由共享高概率 tokens 的渐进式对齐驱动,这一过程可以通过 off-policy cold starts 或使用 teacher-aligned prompts 来增强。
表格列出了用于 On-Policy Distillation (OPD) 训练的默认超参数,包括 batch size、learning rate 和 token support 的设置。这些参数定义了论文中所述实验的训练配置。OPD 使用 1e-6 的固定学习率和 64 的全局 batch size。训练采用 Student Top-K 策略,LogProb top-K 为 16。训练期间 KL 正则化被禁用,系数为 0.0。
该图比较了成功的和失败的 on-policy distillation 训练运行情况,显示成功的 distillation 以在高概率 tokens 上的稳定对齐为特征,而失败则发生在对齐停滞时。主要的梯度和 advantages 来自于重叠 tokens,它们驱动了优化过程。成功的 OPD 在高概率 tokens 上显示出不断增加的重叠,而失败的 OPD 则显示出停滞的对齐。OPD 中的主要优化信号来自 student 和 teacher 之间的共享 tokens。当 student 无法与 teacher 的高概率 tokens 对齐时,就会发生失败,导致梯度微弱且没有改进。

作者研究了 on-policy distillation (OPD) 成功的条件,发现 student 与 teacher 模型之间的思维模式一致性对于有效的知识转移至关重要。即使 teacher 模型优于 student,如果它们的推理模式不匹配,OPD 也会失败;只有当 teacher 拥有超出 student 现有知识的新能力时,才会发生成功的 distillation。student 与 teacher 之间的思维模式一致性对于成功的 OPD 至关重要;当 teacher 的推理模式与 student 不兼容时,无论基准测试性能如何,OPD 都会失败;teacher 通过后训练获得的新知识能够使 OPD 实现更强的增益。
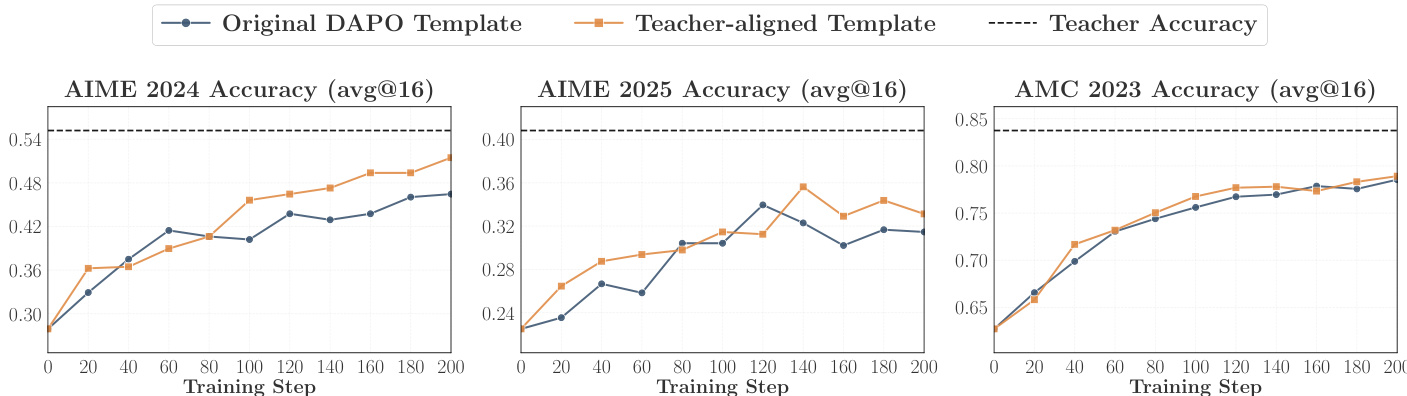
实验比较了使用不同 prompt 模板下的 OPD 性能,结果显示 teacher-aligned 模板在各个基准测试中带来了更高的准确率和更好的重叠增长。结果表明,将 prompt 格式与 teacher 的训练数据对齐,可以通过提高 student 与 teacher 思维模式之间的兼容性来增强 distillation 的有效性。使用 teacher-aligned prompt 模板可以提高 OPD 的准确率和重叠增长;teacher-aligned 模板在多个基准测试中产生了一致的增益;prompt 对齐增强了 student-teacher 的兼容性,从而带来了更好的 distillation 结果。
实验比较了将两种具有不同思维模式的 teacher 蒸馏到同一个 student 模型中的情况。结果显示,具有更兼容思维模式的 teacher 实现了更强的性能和更高的初始重叠,这表明思维模式的一致性决定了 OPD 的有效性。尽管基准测试性能相似,但更对齐的 teacher 产生了更好的 distillation 结果。来自具有兼容思维模式的 teacher 的蒸馏优于来自不匹配 teacher 的蒸馏。初始重叠率与下游性能相关,这表明早期的模式对齐至关重要。尽管重叠曲线趋于一致,但性能差距依然存在,这表明早期的不匹配会降低 distillation 的收益。
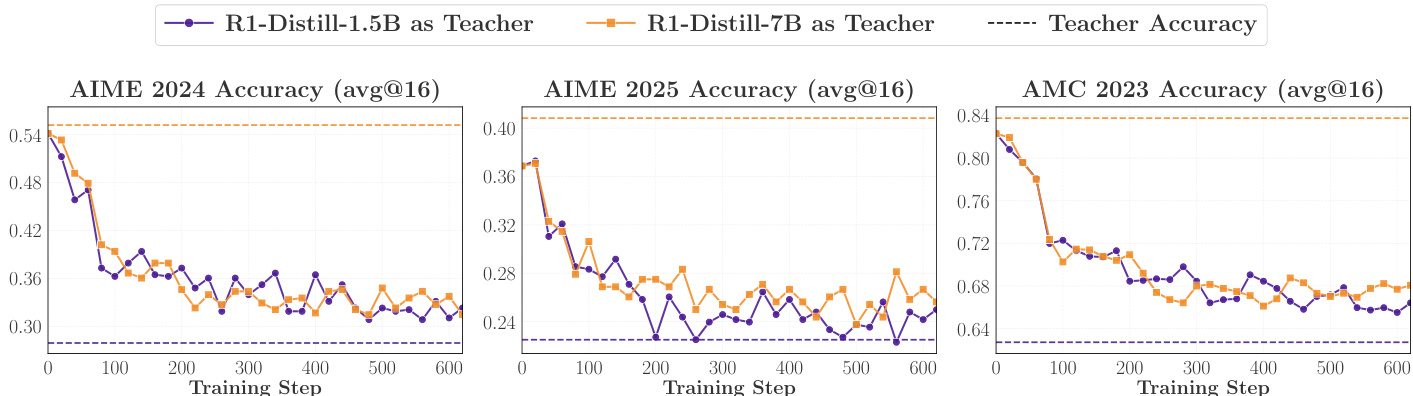
实验通过分析训练稳定性、思维模式一致性和 prompt 对齐,评估了 On-Policy Distillation (OPD) 的动态机制和成功因素。结果表明,成功的 distillation 依赖于 student 与 teacher 高概率 tokens 对齐的能力,这一过程由共享的推理模式驱动。最终,OPD 的有效性取决于 teacher 与 student 之间思维模式的兼容性,这可以通过使用 teacher-aligned prompt 模板进一步优化。