Command Palette
Search for a command to run...
RAD-2:在生成器-判别器框架下扩展 Reinforcement Learning
RAD-2:在生成器-判别器框架下扩展 Reinforcement Learning
Hao Gao Shaoyu Chen Yifan Zhu Yuehao Song Wenyu Liu Qian Zhang Xinggang Wang
摘要
高级自动驾驶要求运动规划器(motion planners)不仅能够对多模态的未来不确定性进行建模,还要在闭环交互(closed-loop interactions)中保持鲁棒性。尽管基于 Diffusion 的规划器在建模复杂轨迹分布方面表现出色,但如果仅通过模仿学习(imitation learning)进行训练,往往会面临随机不稳定性以及缺乏纠错性负反馈的问题。为了解决这些问题,我们提出了 RAD-2,这是一个用于闭环规划的统一生成器-判别器(generator-discriminator)框架。具体而言,该框架利用基于 Diffusion 的生成器来产生多样化的候选轨迹,并使用经强化学习(RL)优化的判别器根据长期驾驶质量对这些候选轨迹进行重排序。这种解耦设计避免了将稀疏的标量奖励直接应用于全维高维轨迹空间,从而提升了优化的稳定性。为了进一步增强强化学习的效果,我们引入了“时间一致性分组相对策略优化”(Temporally Consistent Group Relative Policy Optimization),该方法利用时间相干性(temporal coherence)来缓解信用分配(credit assignment)问题。此外,我们还提出了“在策略生成器优化”(On-policy Generator Optimization),将闭环反馈转化为结构化的纵向优化信号,并逐步引导生成器向高奖励轨迹流形(trajectory manifolds)偏移。为了支持高效的大规模训练,我们引入了 BEV-Warp,这是一个高吞吐量的仿真环境,通过空间扭曲(spatial warping)技术直接在鸟瞰图(Bird's-Eye View)特征空间内进行闭环评估。实验结果表明,与强大的基于 Diffusion 的规划器相比,RAD-2 将碰撞率降低了 56%。在真实世界的部署进一步证明,该方法在复杂的城市交通场景中提升了感知安全性与驾驶平顺性。
一句话总结
为了提高多模态自动驾驶场景下的稳定性并纠正模仿学习错误,研究人员提出了 RAD-2。这是一个统一的生成器-判别器框架,利用基于 diffusion 的生成器产生轨迹候选集,并使用经 RL 优化的判别器对其进行重排序,同时采用时间一致性组相对策略优化(Temporally Consistent Group Relative Policy Optimization)来增强强化学习。
核心贡献
- 本文引入了 RAD-2,这是一个统一的生成器-判别器框架,利用基于 diffusion 的生成器进行多样化轨迹生成,并利用经 RL 优化的判别器根据长期驾驶质量对候选轨迹进行重排序。
- 该工作提出了时间一致性组相对策略优化(Temporally Consistent Group Relative Policy Optimization)以通过时间相干性改进 credit assignment,并提出了 On-policy Generator Optimization 以利用结构化纵向信号来精细化轨迹分布。
- 作者开发了 BEV-Warp,这是一个高吞吐量的特征级仿真流水线,它通过绕主车进行 BEV 特征变换,从而在无需昂贵的图像级渲染的情况下实现可扩展的闭环训练。
引言
高层自动驾驶需要运动规划器能够在保持闭环交互鲁棒性的同时,对多模态不确定性进行建模。虽然基于 diffusion 的规划器擅长捕捉复杂的轨迹分布,但如果仅通过模仿学习进行训练,它们往往面临随机不稳定性且缺乏纠错反馈。此外,由于奖励稀疏和严重的 credit assignment 挑战,直接将强化学习应用于高维轨迹空间非常困难。作者利用统一的生成器-判别器框架将这些任务解耦,使用基于 diffusion 的生成器产生多样化的候选轨迹,并使用经 RL 优化的判别器根据长期驾驶质量对其进行重排序。为了支持这一点,他们引入了时间一致性组相对策略优化以稳定 RL 搜索空间,以及 BEV-Warp,一种在高维鸟瞰图(BEV)特征空间中进行闭环评估的高吞吐量仿真环境,从而绕过昂贵的图像级渲染。
数据集
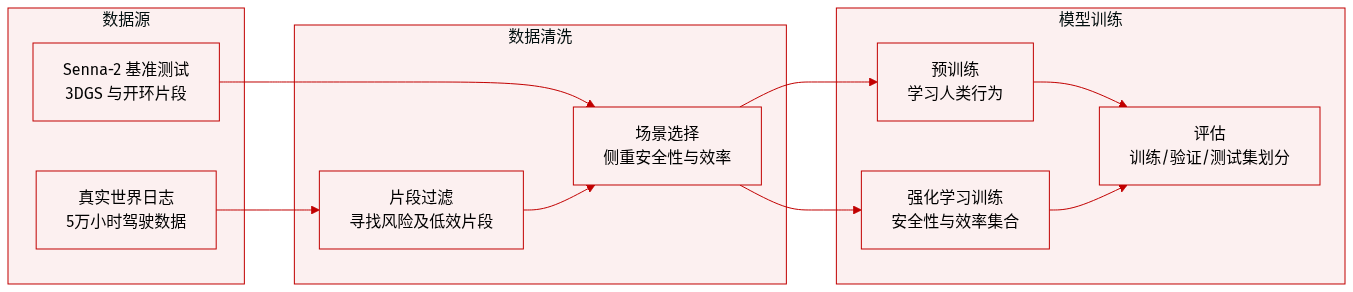
数据集概览
作者利用多阶段数据集策略来训练和评估其运动生成和强化学习框架:
- 生成器预训练数据:作者使用了约 50,000 小时的真实驾驶数据,其中包含主车轨迹。这一大规模数据集用于预训练运动生成器,以捕捉人类驾驶行为的多模态分布。
- BEV Warp 环境子集:
- 来源与过滤:作者最初从真实日志中收集了 50,000 个片段,每个片段持续 10 到 20 秒。这些片段在 BEV Warp 环境中进行闭环仿真,以识别特定的驾驶行为。通过过滤片段来分离安全关键场景(高碰撞风险)和效率相关场景(次优性能)。
- 训练集:创建了两个经过策划的训练集用于闭环强化学习,每个训练集包含 10,000 个片段,分别侧重于安全或效率目标。
- 评估集:构建了两个互不相交的子集,每个子集包含 512 个片段,用于闭环评估,分别对应安全和效率类别。
- 3DGS 环境子集:
- 来源:作者利用了来自 Senna-2 的照片级逼真 3D Gaussian Splatting (3DGS) 仿真基准,该基准专注于高风险安全场景。
- 用途:1,044 个片段用于训练轨迹判别器,而 256 个片段保留用于闭环评估。
- 开环评估场景: 作者采用 Senna-2 开环评估数据集,在六个代表性场景中测试规划质量:跟车启动、跟车停止、换道、交叉路口、弯道和紧急制动。
方法
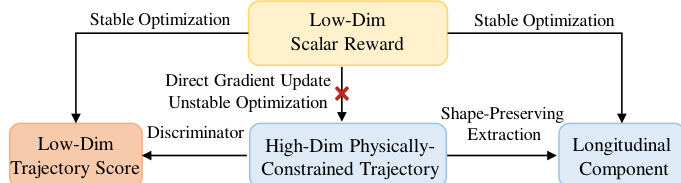
所提出的 RAD-2 框架采用生成器-判别器架构,以实现自动驾驶中鲁棒且安全的运动规划。这种设计将高维轨迹生成过程与低维强化学习 (RL) 优化解耦,从而实现稳定且高效的策略训练。如框架图所示,系统通过两个主要组件运行:基于 diffusion 的生成器和经 RL 训练的判别器。生成器根据当前观测产生一组多样化的候选轨迹,而判别器根据预期的长期结果对这些候选轨迹进行评估和重排序。该联合策略定义为 \\Pi_{\\theta,\\phi}(\\tau|o) = \\mathbb{E}_{c \\sim \\mathcal{G}_\\theta(\\cdot|o)}[\\mathcal{D}_\\phi(\\tau|o, \\mathcal{C})],这允许构建一种结构化策略,其中生成器探索广泛的可行动作空间,而判别器有选择性地优先考虑高质量行为。该架构本质上支持推理时扩展,即通过增加候选轨迹的数量而无需重新训练。
如图所示,基于 diffusion 的生成器对未来轨迹进行多模态建模。它首先将当前观测 ot 编码为鸟瞰图 (BEV) 特征 Tb,并从静态地图元素、动态 agent 以及导航输入中提取场景特定信息。这些组件通过轻量级编码器处理以获得 token 嵌入,然后与 BEV 特征融合形成统一的场景嵌入 Etextscene。该嵌入通过交叉注意力机制为基于 DiT 的轨迹生成器提供条件。对于 M 个独立的模式,生成器在 K 个步骤内迭代地对初始噪声轨迹进行去噪,以产生一组候选轨迹 widehatmathcalT。这些轨迹随后被传递给判别器进行评估。
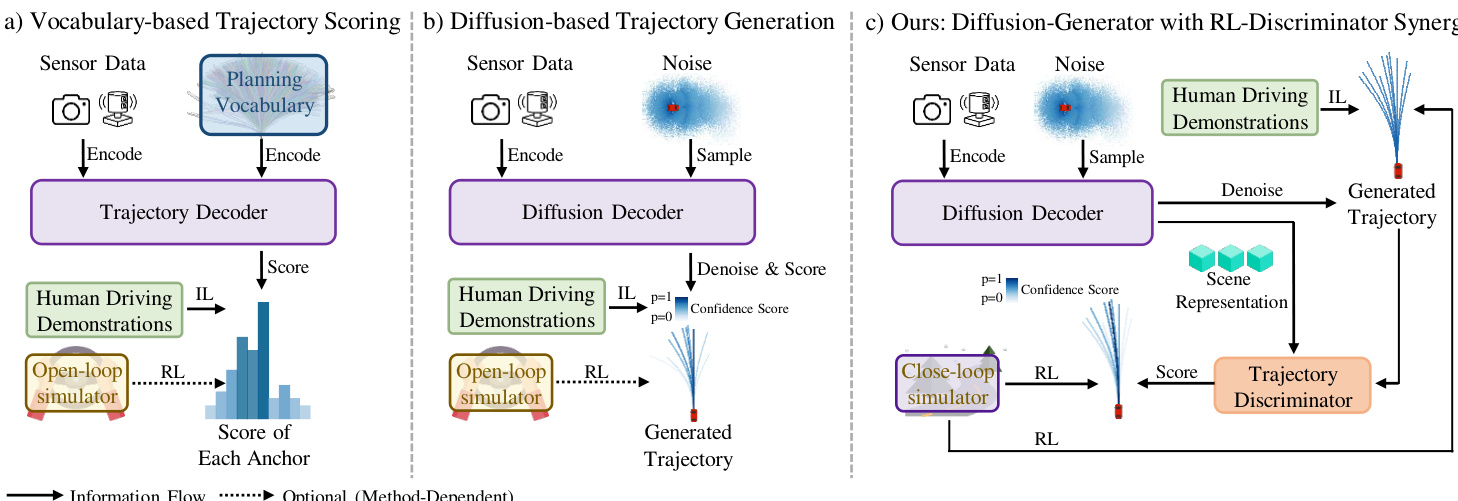
判别器通过首先使用共享 MLP 编码轨迹中的每个点,然后使用 Transformer 编码器处理生成的序列,从而产生轨迹级查询 Qtau,以此来评估候选轨迹。该查询聚合了整个轨迹的信息,并用于与场景上下文进行交互。场景表示由与生成器相同的输入构建,并对静态和动态元素使用独立的编码器。轨迹查询通过交叉注意力机制与场景上下文交互,产生融合嵌入 Etextfusion。对该融合表示应用最终的 sigmoid 激活函数,为每个候选轨迹生成一个标量分数,用于重排序。这一过程使判别器能够提供基于长期结果的精确反馈,进而用于指导生成器的优化。
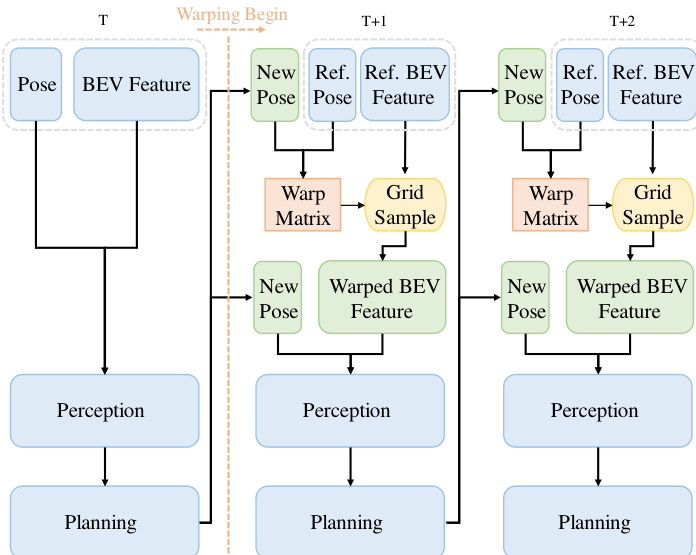
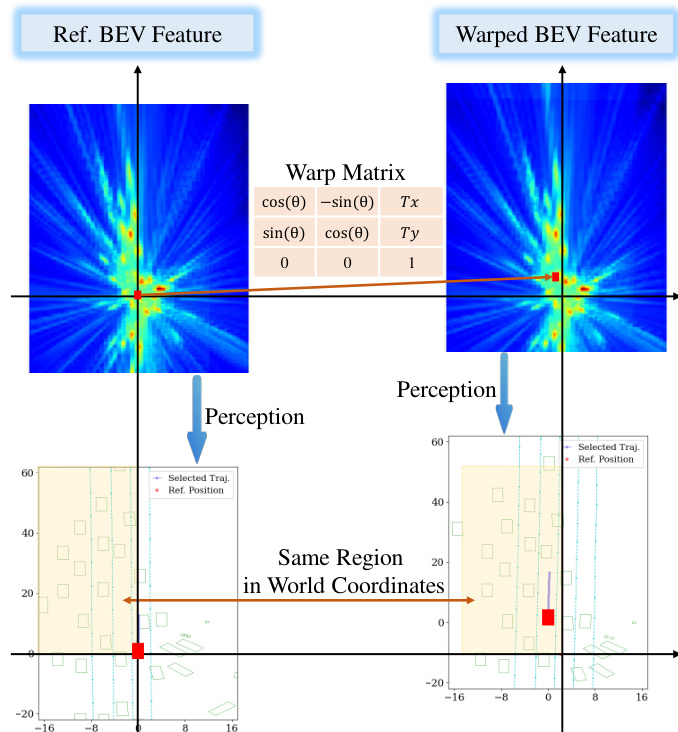
为了扩展 RL 训练过程,系统利用了一个名为 BEV-Warp 的高吞吐量特征级仿真环境。该环境通过直接操作 BEV 特征来实现高效的闭环交互,从而绕过昂贵的图像级渲染。仿真从真实序列初始化,在每个时间步,系统提取参考 BEV 特征和当前 agent 位姿。规划器生成候选轨迹,从中选择最优轨迹。为了保持时间相干性并确保稳定的探索,系统采用了轨迹重用机制。一旦选中某条轨迹,其对应的控制命令将在固定时界内执行,从而稳定 agent 的运动。该机制确保累积奖励能够准确反映所选轨迹的质量,从而促进有效的策略梯度。闭环评估由递归特征变换机制驱动,其中从模拟 agent 与日志参考位姿之间的相对位姿偏差导出的变换矩阵被应用于参考 BEV 特征,以合成下一个高保真观测。
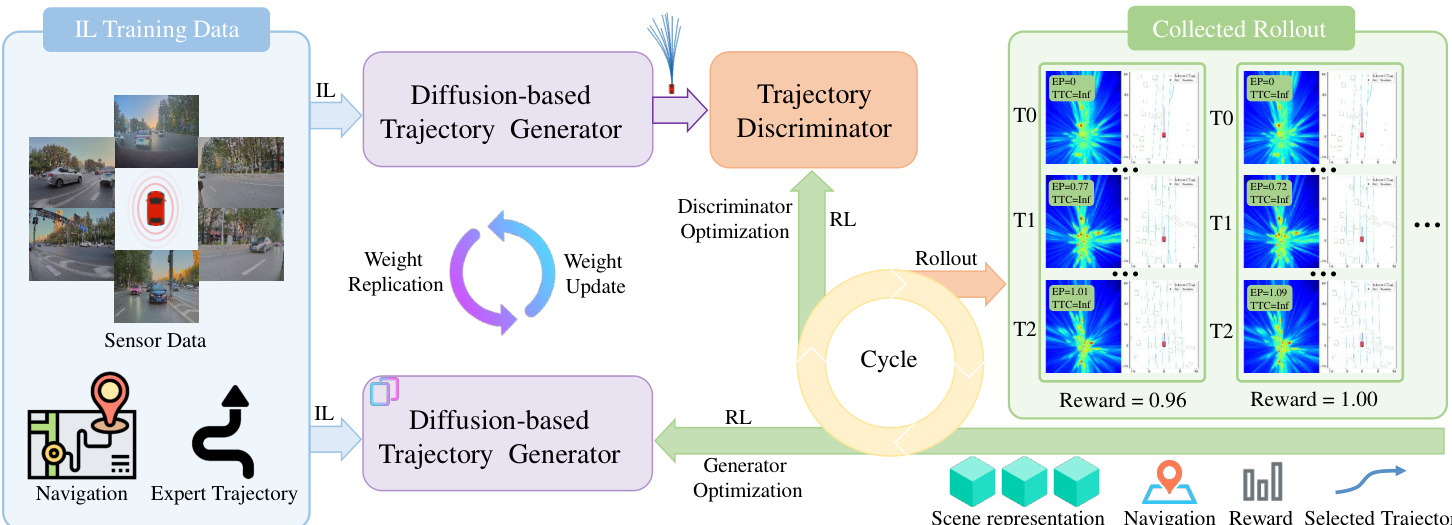
联合策略优化通过一个多阶段迭代过程实现。全局目标是最小化混合策略与理想的高效率分布之间的 KL 散度。训练流水线由三个阶段组成:(i) 时间一致性展开 (Temporally Consistent Rollout),用于收集稳定的闭环交互数据;(ii) 判别器优化,通过时间一致性组相对策略优化 (TC-GRPO) 框架优化判别器以增强其评分精度;(iii) 生成器优化,采用 On-policy Generator Optimization (OGO) 将生成器的分布转向更安全、更高效的行为。TC-GRPO 框架引入了结构化展开和奖励分配机制,以解决连续驾驶中的 credit assignment 问题,确保稀疏的环境奖励能直接归因于每个持续区间内维持的具体轨迹假设。OGO 机制将闭环奖励信号转换为结构化的纵向优化,调整原始轨迹段的加速度曲线,使其更好地符合安全和效率目标。这使得生成器能够迭代地将其输出分布转向有利的长期结果,而不会损害稳定性。
训练过程始于预训练阶段,通过在专家演示上进行模仿学习来初始化基于 diffusion 的生成器,以捕捉多模态轨迹先验。随后是闭环展开阶段,联合策略与 BEV-Warp 环境交互以生成多样化的展开数据。接着通过 TC-GRPO 框架优化判别器,利用闭环反馈增强其对轨迹进行排序的能力。最后,通过 OGO 优化生成器,利用从低奖励展开中获得的结构化纵向优化信号来精细化其分布。系统采用循环优化回路,判别器的更新频率高于生成器,以确保持续的协同适应。整个框架实现了一个自我改进的闭环,生成器和判别器共同优化整体策略,逐步将轨迹分布转向更安全、更高效的行为。
实验
所提出的方法通过 BEV Warp 和 3DGS 环境中的闭环仿真来评估交互式驾驶行为,并结合开环基准来验证轨迹准确性。结果表明,与解耦或单目标训练策略相比,生成器和判别器的协同联合优化显著改善了安全与效率之间的平衡。定性分析和消融实验进一步证实,通过有效的基于奖励的过滤和鲁棒的推理时扩展,该框架实现了卓越的避障能力和更平滑的导航。
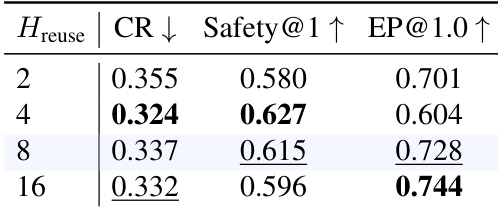
该表展示了关于执行时界 (execution horizon) 的消融研究,显示了不同值如何影响碰撞率、安全性和效率指标。结果表明,中间时界在性能和稳定性之间达到了最佳平衡。执行时界为 8 时实现了最高的效率以及安全与碰撞率之间的最佳权衡。较低的时界会导致更高的碰撞率并降低安全性,而较高的时界会降低效率。最优时界在稳定的 credit assignment 与反应灵活性之间取得了平衡,从而实现有效训练。
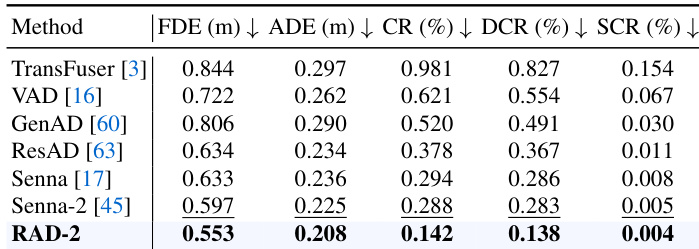
作者使用包含各种驾驶场景的基准,在开环轨迹准确性方面比较了多种方法。结果显示,所提出的方法实现了最低的碰撞率和最佳的轨迹质量指标,在所有评估指标上都优于以往的方法。与所有基线方法相比,所提出的方法实现了最低的碰撞率和轨迹误差指标。该方法显著降低了开环场景中的动态和静态碰撞组件。它展示了卓越的轨迹质量,在所有评估方法中具有最低的 ADE 和 FDE 值。
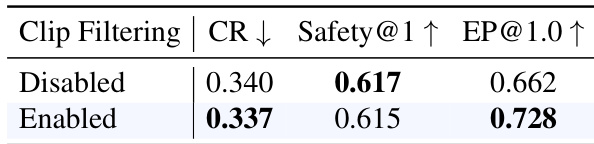
结果表明,启用片段过滤 (clip filtering) 在保持轨迹规划安全性的同时提高了效率。这表明过滤掉低方差场景可以带来更稳定和有效的训练结果。片段过滤在不损害安全性的情况下提高了效率。启用片段过滤增强了 [email protected] 性能。过滤低方差片段稳定了训练动态。
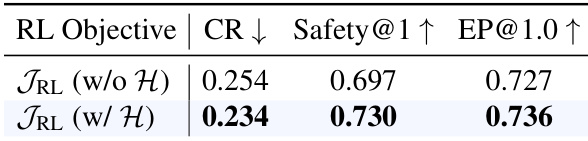
作者比较了两种强化学习目标,一种不包含熵项,另一种包含熵项,以评估它们对安全性和效率的影响。结果显示,与不含熵项的版本相比,加入熵项提高了安全性和效率指标。在 RL 目标中包含熵项可提高安全性和效率。带有熵项的版本实现了较低的碰撞率。带有熵项的版本实现了更高的安全性和效率分数。
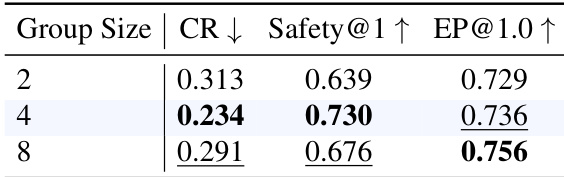
该表显示了不同组大小 (group size) 对模型性能的影响,其中组大小为 4 时在安全性和效率指标之间达到了最佳平衡。较大的组大小会导致安全性下降,同时略微提高效率。组大小为 4 时实现了最高的安全性和效率分数。将组大小增加到 4 以上会降低安全性指标。效率随组大小增加而提高,但以牺牲安全性为代价。
实验通过消融研究和对比基准评估了各种架构和训练组件,以优化驾驶性能。结果表明,中间执行时界、在 RL 目标中加入熵项以及使用片段过滤都有助于实现更稳定和高效的训练。此外,所提出的方法在开环轨迹准确性方面优于基线方法,同时需要最优的组大小来平衡安全性与运行效率。