Command Palette
Search for a command to run...
Transformers 中的 Attention Sink:关于其利用、解释与缓解的研究综述
Transformers 中的 Attention Sink:关于其利用、解释与缓解的研究综述
摘要
作为现代机器学习的基础架构,Transformer 推动了各类 AI 领域的显著进步。尽管 Transformer 具有变革性的影响力,但其在不同变体中普遍面临着一个持久的挑战,即 Attention Sink (AS) 现象——即注意力权重不成比例地集中在极少数特定且无信息的 tokens 上。AS 增加了模型的可解释性难度,显著影响了 training 和 inference 的动态过程,并加剧了诸如幻觉(hallucinations)等问题。近年来,已有大量研究致力于理解和利用 AS。然而,目前仍缺乏一项能够系统性整合 AS 相关研究,并为未来发展提供指导的全面综述。为了填补这一空白,我们提出了首篇关于 AS 的综述,该综述围绕定义当前研究格局的三个关键维度展开:基础利用(Fundamental Utilization)、机制解释(Mechanistic Interpretation)以及策略缓解(Strategic Mitigation)。我们的工作通过阐明核心概念,并引导研究人员了解该领域的演进与趋势,做出了关键性的贡献。我们期望本综述能成为一项权威资源,助力研究人员和从业者在当前的 Transformer 范式下有效管理 AS,同时也为下一代 Transformer 的创新突破提供灵感。本文的相关论文列表已发布于:https://github.com/ZunhaiSu/Awesome-Attention-Sink。
一句话总结
这是关于 Transformer 中 Attention Sink 的首份全面综述,通过将研究系统地分为基础利用、机制解释和策略缓解,旨在阐明核心概念,并为管理无信息 token 关注提供框架,从而改进训练、推理和可解释性。
核心贡献
- 本工作通过系统性地综合超过 180 项研究,展示了关于 Transformer 架构中 Attention Sink (AS) 的首份全面综述。该综述围绕三个关键维度构建:基础利用、机制解释和策略缓解。
- 本文详细分析了 AS 如何在各种架构中影响训练动态、模型可解释性和推理效率。它阐明了核心概念,并探讨了如何利用经验性的利用策略、机制研究和缓解技术来提高模型的性能和鲁棒性。
- 该综述为理解 AS 建立了基础框架,并确定了关键的未来研究方向。这些方向包括开发用于缓解措施的标准基准、探索跨架构和跨模态的迁移,以及研究多种 AS 处理技术之间的协同集成。
引言
Transformers 是现代 AI 的基础架构,但它们经常表现出 Attention Sink (AS) 现象,即不成比例的注意力集中在极少数无信息的 tokens 上。这种行为增加了模型可解释性的难度,使训练和推理变得不稳定,并导致幻觉和量化误差等问题。虽然最近的研究探索了利用或减少 AS 的各种方法,但现有文献仍然是碎片化的,导致研究人员缺乏统一的参考来指导开发。作者通过对 180 多项研究的全面回顾,提出了该领域的第一份系统性综述。他们根据三个维度将研究组织成一种新颖的分类法:基础利用、机制解释和策略缓解。
方法
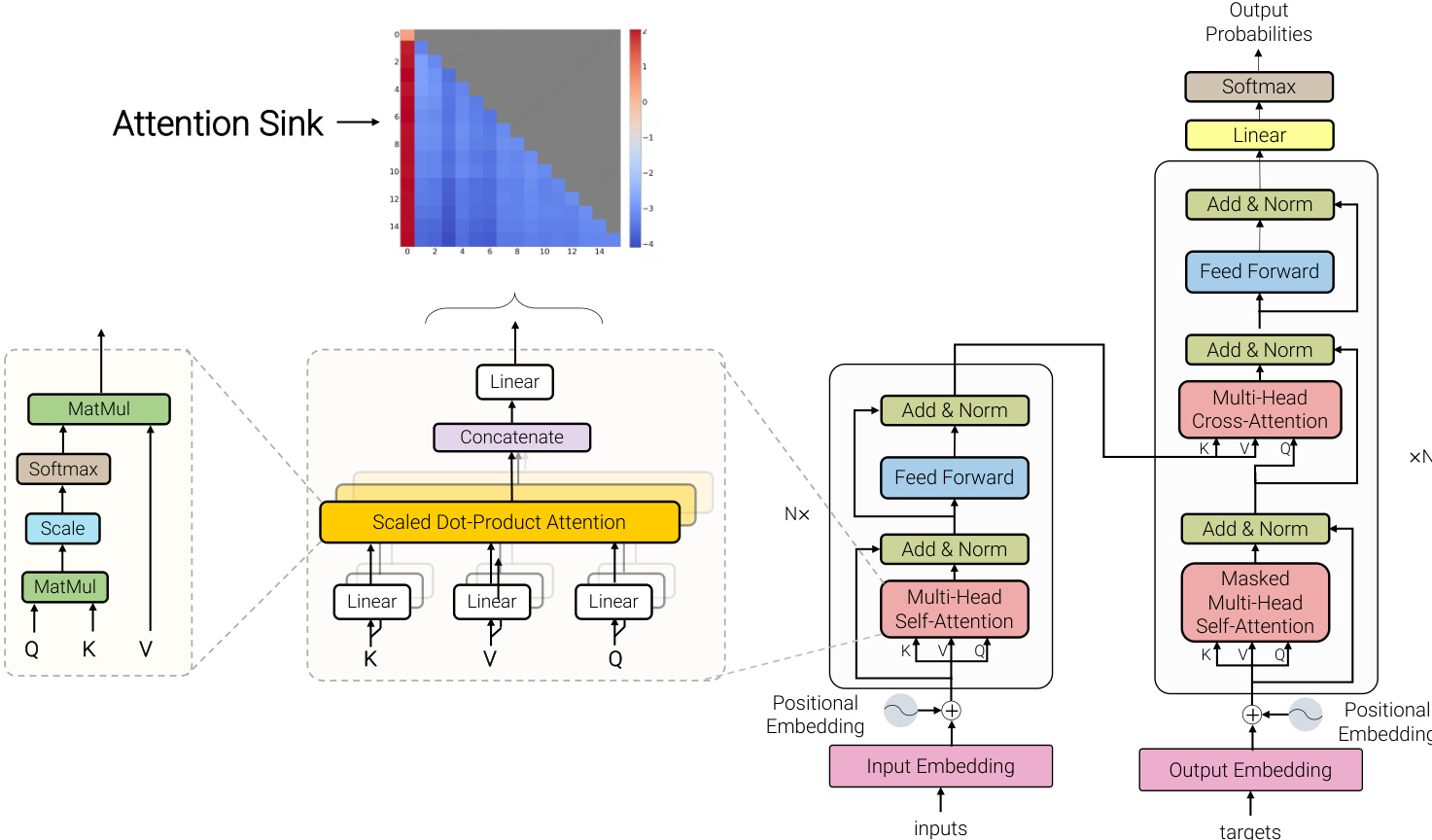
现代大语言模型 (LLMs) 的基础架构源自 Transformer,它运行在编码器-解码器框架上。如下图所示,一个标准的 Transformer 块由两个主要组件组成:多头自注意力 (MHSA) 模块和逐位置前馈网络 (FFN)。MHSA 机制使模型能够捕获长距离全局依赖关系,而无需序列处理的归纳偏置。对于输入序列 X∈RN×D,查询 Q、键 K 和值 V 通过线性投影获得:Q=XWQ,K=XWK,V=XWV,其中 WQ,WK,WV∈RD×dk。注意力计算为 Attention(Q,K,V)=Softmax(dkQKT)V。FFN 独立应用于每个位置,定义为 FFN(x)=σ(xW1+b1)W2+b2。为了稳定训练并缓解梯度消失问题,每个子层都包含一个残差连接,随后是层归一化 (LayerNorm):Xout=LayerNorm(X+SubLayer(X))。
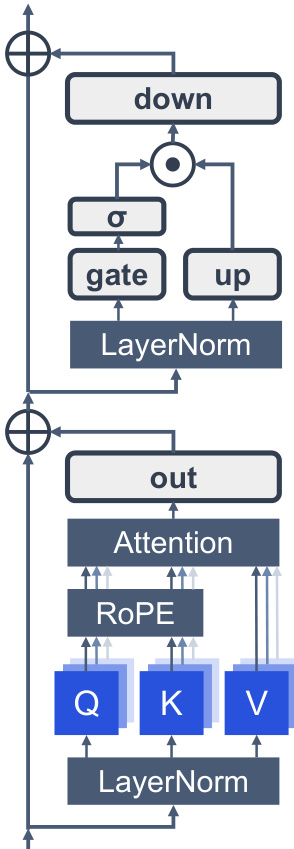
现代 LLMs 是 Transformer 的专门化适配,从根本上植根于 decoder-only 配置。这些模型的结构布局如图 7 所示。从 decoder-only 架构继承的一个定义性约束是因果掩码 (causal masking) 机制,它确保位置 i 处的每个查询向量 qi 只能关注先前的键向量 kj,其中 j≤i。形式上,注意力模式定义为 Attention(Q,K,V)=softmax(dkQK⊤+M)V,其中 M 是因果掩码,对于 j>i 有 Mij=−∞,否则为 0。在这种设置下,只有初始 tokens 对整个序列可见,使其成为注意力卸载 (attention offloading) 最稳定的候选对象。除了因果掩码,当代 LLMs 还结合了一系列架构改进,共同增强了训练稳定性、模型表达能力和推理效率。在归一化方面,使用均方根层归一化 (RMSNorm) 的预归一化已在很大程度上取代了原始的 post-LN 设计,缓解了梯度方差并实现了更大规模的稳定训练。前馈网络已从原始的两层 MLP 升级为门控线性单元 (GLU),其中 SwiGLU 由于在表达能力和计算成本之间具有卓越的权衡而成为主流变体。对于位置编码,旋转位置嵌入 (RoPE) 通过旋转矩阵对相对位置信息进行编码,与绝对或可学习的位置嵌入相比,提供了改进的长度外推能力。
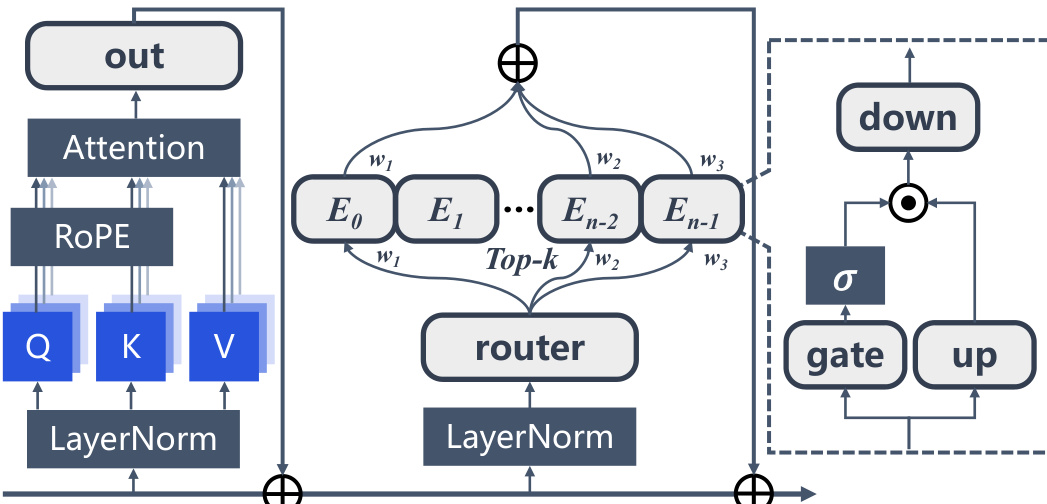
混合专家 (MoE) LLMs 通过将静态前馈网络替换为稀疏 MoE 层来扩展 vanilla Transformer 架构,如图 8 所示。多头自注意力后的隐藏表示 Hl′∈Rn×d 通过层归一化并输入 MoE 层。路由网络通过权重矩阵 WG∈Rd×E 决定激活哪些专家,其中路由权重 G∈Rn×E 计算为 G=softmax(Hl′WG)。通过为每个输入 token 选择前 k 个路由权重来实现专家的稀疏激活,从而产生 MoE 层输出:MoE(Hl′)=∑i∈Top−k(Gi)Gji⋅FFN(LNmoe(Hjl′)),∀j=1…n。在稠密 LLMs 中,AS 表现为锚定在初始 tokens 上的稳定模式。在 MoE LLMs 中,稀疏激活机制在推理过程中将不同的 tokens 动态路由到不同的专家。AS 机制与 MoE 架构之间的相互作用导致了 MoE LLMs 中独特的 AS 表现形式,其中 AS 的分布可能会影响专家路由决策,或者受到其影响。
多模态 LLMs (MLLMs) 通过跨模态连接器将视觉编码器与因果 LLM 主干集成,从而扩展了标准 Transformer 架构。形式上,给定输入图像 x∈RH×W×C,视觉编码器首先提取一系列视觉 tokens:V={v1,v2,…,vN}=fvision(x),其中 N 表示 patch 的数量,fvision 代表视觉编码器。然后,这些视觉 tokens 通过跨模态连接器 P 进行投影,以对齐 LLM 的嵌入空间:V′=P(V)={v1′,v2′,…,vN′},其中 vi′∈RDllm。投影后的视觉 tokens V′ 与文本 tokens T={t1,…,tM} 拼接,形成完整的输入序列 S=[V′,T],随后由因果 LLM 进行处理。与仅文本的 Transformers 不同,MLLMs 在异构感受野上运行,要求文本查询能够关注信息丰富的视觉 patches,而这些 patches 本质上是非因果的。这种多模态集成迫使注意力机制去协调视觉和文本嵌入之间的量级或方差差异,直接影响了多模态推理过程中 AS 的出现及其空间分布。
Vision Transformer (ViT) 引入了基于 patch 的 tokenization 机制,以使 Transformer 适应图像识别。给定图像 x∈RH×W×C,它首先被划分为 N=HW/P2 个 patch 的网格,其中 (P,P) 是每个 patch 的分辨率,每个 patch pi∈RP2C 对应图像的一个空间段。然后每个 patch 被展平并线性投影到 D 维嵌入中:ei=Epi,其中 E∈RD×(P2C) 是一个可学习的投影矩阵。生成的 N 个 patch 嵌入序列连同可学习的 [CLS] token ecls 作为 Transformer 编码器的输入。基于核心 ViT 架构,后续工作通过新颖的训练范式扩展了其能力。这种架构选择对 AS 行为有直接影响:由于没有将注意力集中在初始 tokens 上的强制因果性,ViT 中的 AS 不受限于序列开始处,而是可能出现在背景 patches 或低语义区域,这些区域在整个图像中充当结构稳定的锚定点。
实验
隐式注意力偏差 (Implicit Attention Bias) 框架通过在包括 LLMs 和 ViTs 在内的各种架构上进行因果干预和可视化进行了评估,以验证其在解释 attention sinks 中的作用。结果表明,Softmax 之和为 1 的约束诱导了一种固定的、与输入无关的偏差,这解释了 sink tokens 接收到不成比例注意力的原因。虽然该框架为这一现象提供了统一的解释,但潜在的训练动态以及不同形式隐式偏差之间的关系仍是未来研究的领域。