Command Palette
Search for a command to run...
SPPO:面向长程推理任务的 Sequence-Level PPO
SPPO:面向长程推理任务的 Sequence-Level PPO
Tianyi Wang Yixia Li Long Li Yibiao Chen Shaohan Huang Yun Chen Peng Li Yang Liu Guanhua Chen
摘要
近端策略优化(Proximal Policy Optimization, PPO)是利用可验证奖励(verifiable rewards)来对齐大语言模型(LLMs)推理任务的核心技术。然而,在这一场景下,标准的 token 级别 PPO 面临着严峻挑战:一方面,在长链式思考(Chain-of-Thought, CoT)过程中,时间信用分配(temporal credit assignment)的不稳定性会导致训练难以收敛;另一方面,value model 带来了极高的显存开销。虽然像 GRPO 这样无需 critic 的替代方案缓解了上述问题,但它们需要通过多次采样来估计 baseline,从而产生了巨大的计算开销,严重限制了训练吞吐量。在本文中,我们提出了序列级 PPO(Sequence-Level PPO, SPPO),这是一种能够将 PPO 的采样效率与基于结果更新(outcome-based updates)的稳定性相统一的可扩展算法。SPPO 将推理过程重新建模为一个序列级上下文多臂老虎机(Sequence-Level Contextual Bandit)问题,通过采用解耦的标量 value function,在无需多次采样的情况下推导出低方差的 advantage 信号。在数学 benchmark 上的广泛实验表明,SPPO 的表现显著优于标准 PPO,并能达到计算密集型分组方法(group-based methods)的性能水平,为对齐推理型 LLMs 提供了一个资源高效的框架。
一句话总结
作者提出了 SPPO,这是一种可扩展的序列级强化学习算法。它将长程推理重新建模为上下文 Bandit 问题,并采用解耦的标量价值函数,在无需像基于组的方法那样进行多样本采样的情况下,实现了低方差的 advantage 信号,在数学基准测试中显著优于标准 PPO。
核心贡献
- 本文引入了 Sequence-Level PPO (SPPO),该算法将推理过程重新建模为 Sequence-Level Contextual Bandit 问题,从而使样本效率与基于结果更新的稳定性相协调。
- 该工作实现了一种 Decoupled Critic 策略,使用轻量级 critic 来对齐更大的 policy,在实现高吞吐量单样本更新的同时,将内存占用降低了 12.8%。
- 在 AIME、AMC 和 MATH 等数学基准测试上的广泛评估表明,SPPO 在达到与 GRPO 等基于组的方法相当性能的同时,实现了 5.9 倍的训练加速。
引言
为了使大语言模型 (LLMs) 适应复杂的推理任务,需要使用具有可验证奖励的强化学习 (RLVR) 来确保逻辑正确性。虽然标准的 token 级 Proximal Policy Optimization (PPO) 被广泛使用,但在处理长 Chain-of-Thought 长度时,它面临着不稳定的时间信用分配 (temporal credit assignment) 和高内存成本的问题。相反,像 Group Relative Policy Optimization (GRPO) 这样的无 critic 方法虽然减少了偏差,但由于需要针对每个 prompt 采样多个响应来估计基准,从而引入了高方差和显著的计算开销。作者利用了一个新的视角,将推理视为 Sequence-Level Contextual Bandit 问题,而不是多步马尔可夫决策过程 (MDP)。他们引入了 Sequence-Level PPO (SPPO),它使用学习到的标量价值函数来提供稳定的 advantage 信号。这种方法允许高吞吐量的单样本更新,在匹配基于组的方法性能的同时,实现了显著的训练加速。
方法
作者利用序列级优化框架来解决长程推理任务中的信用分配挑战。所提出的 SPPO 方法将标准的 token 级马尔可夫决策过程 (MDP) 重新建模为 Sequence-Level Contextual Bandit (SL-CB) 设置,其中整个生成的响应序列被视为单个原子动作。这种转变通过消除对尝试从中间状态估计未来回报的 token 级 critic 的需求,从根本上改变了 policy 优化过程。相反,SPPO 引入了一个标量价值模型 Vϕ(sp),用于预测给定 prompt sp 的成功概率。该价值函数使用二元交叉熵 (BCE) 损失进行训练,以确保其作为 advantage 计算的校准基准。
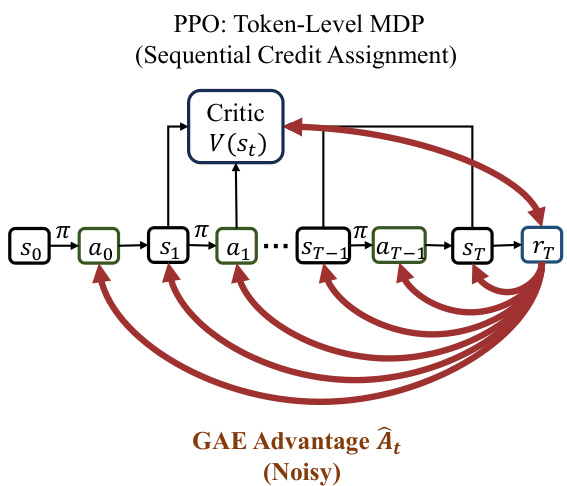
如下图所示,标准 PPO 框架在 token 级 MDP 内运行,其中 policy π 从状态 st 顺序生成动作 at。critic V(st) 估计每个中间状态的价值,并通过广义优势估计 (GAE) 计算 advantage A^t,GAE 通过累加折扣时间差分误差来实现。这种机制会导致带有噪声且依赖位置的信用分配,因为 advantage 信号受 token 在序列中位置的影响很大,从而导致“尾部效应”,即奖励只能在生成接近结束时才得到有效传播。
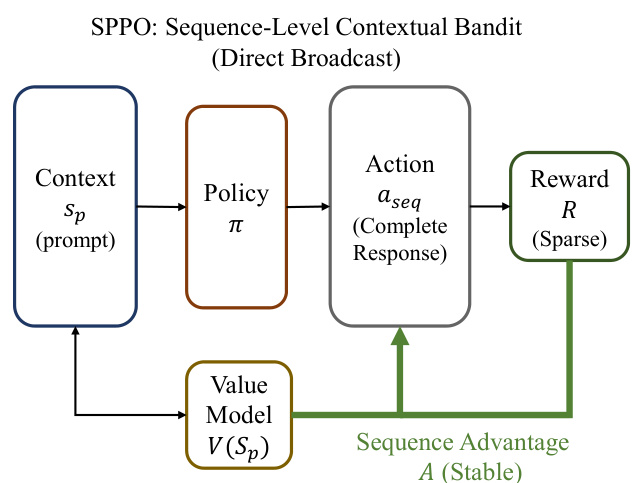
相比之下,如下所示的 SPPO 框架将 prompt sp 作为唯一的上下文进行操作。policy π 输出一个完整的响应序列 aseq,然后由稀疏奖励函数 R 进行评估以确定其正确性。advantage 被计算为一个简单的标量差值 A(sp,a)=R−Vϕ(sp),然后直接广播到生成序列中的每个 token。这种序列级 advantage A 是稳定的,且与响应长度无关,通过根据最终结果统一强化或惩罚整个动作链,有效地解决了时间信用分配问题。policy 优化目标改编自 PPO 的剪切代理目标 (clipped surrogate objective),但将单一的序列级 advantage 应用于所有 token,确保 policy 更新与推理过程的整体成功或失败保持一致。
实验
评估通过使用数学推理基准和强化学习控制任务,将所提出的 SPPO 算法与包括标准 PPO、GRPO、RLOO 和 ReMax 在内的几种基准方法进行了对比。结果表明,SPPO 通过利用序列级上下文 Bandit 公式,有效地解决了稀疏奖励设置下的信用分配问题,从而实现了卓越的性能和更快的收敛速度。此外,研究证实,将 critic 大小与 policy 解耦可以在不牺牲准确性的情况下显著降低内存开销,使大规模推理模型的对齐更加节省资源。
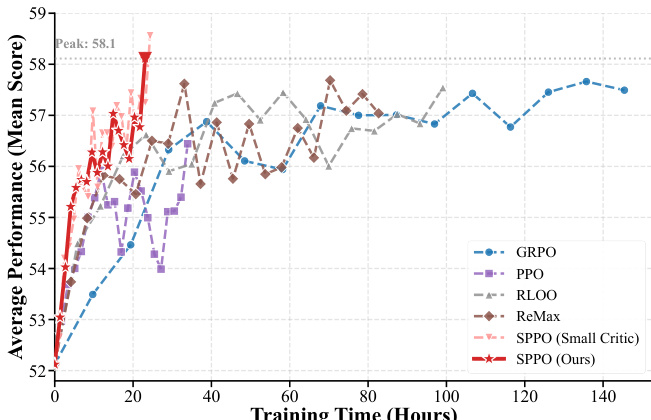
结果显示,与基准方法相比,SPPO 实现了更高的平均性能和更快的收敛速度。该方法展示了改进的训练效率,SPPO 比其他算法更快达到峰值性能。SPPO 在平均性能和收敛速度方面优于所有基准方法,其达到峰值性能的速度明显快于基于组的方法。SPPO 的小型 critic 变体在降低计算开销的同时保持了高性能。
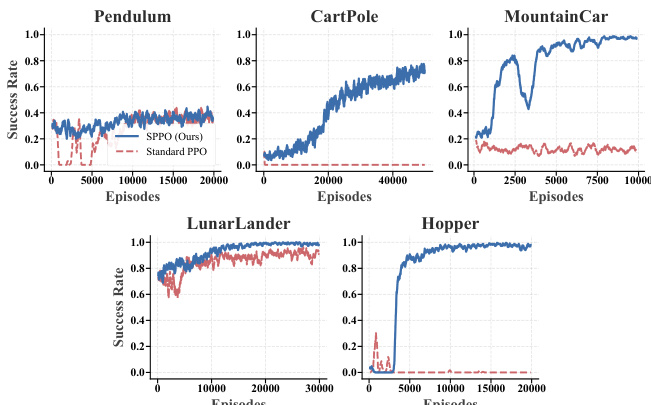
作者在五个具有稀疏奖励的控制任务中将 SPPO 与标准 PPO 进行了评估。结果显示 SPPO 能够持续收敛并优于标准 PPO,特别是在基准方法失效的长程任务中。SPPO 在所有控制任务中都实现了稳健的收敛,而标准 PPO 在复杂环境中表现不佳。在长程任务中,SPPO 成功解决了标准 PPO 成功率仍然较低的问题。SPPO 展示了卓越的样本效率,在 CartPole 等精度任务中迅速提升。
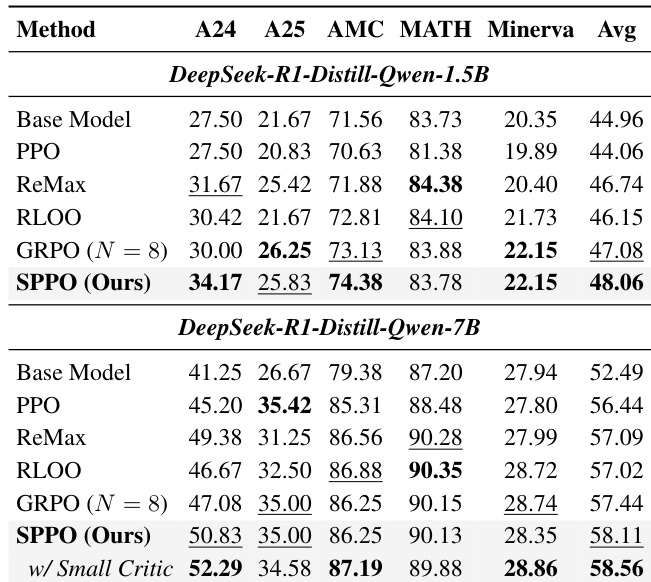
该表对比了各种强化学习方法在数学推理基准上的性能。SPPO 一致地获得了比基准方法更高的平均分数,在使用较小的 critic 模型时观察到了最佳结果。作者使用序列级 advantage 估计方法来提高训练稳定性和效率。SPPO 在两种模型规模上都优于所有基准方法,并获得了最高的平均分数。使用较小的 critic 模型在保持有效性的同时提高了性能并减少了内存占用。标准 PPO 相对于基础模型的提升有限,表明其在稀疏奖励设置中存在不稳定性。
SPPO 在具有稀疏奖励的控制任务和数学推理基准上与标准 PPO 及其他基准方法进行了对比,以验证其训练效率和稳定性。结果表明,SPPO 实现了卓越的平均性能和更快的收敛速度,特别是在基准方法经常失效的复杂、长程环境中。此外,采用较小的 critic 模型在不牺牲有效性的情况下增强了性能并降低了计算开销。