Command Palette
Search for a command to run...
DR3-Eval:迈向真实且可复现的深度研究评估
DR3-Eval:迈向真实且可复现的深度研究评估
摘要
Deep Research Agents (DRAs) 旨在解决涉及规划、检索、多模态理解和报告生成的复杂、长程(long-horizon)研究任务,然而,由于动态的网络环境和模糊的任务定义,对其进行评估仍然具有挑战性。我们提出了 DR3-Eval,这是一个用于评估 Deep Research Agents 在多模态、多文件报告生成能力上的真实且可复现的 benchmark。DR3-Eval 基于用户提供的真实材料构建,并配有针对每个任务的静态研究沙盒语料库(sandbox corpus);该语料库在模拟开放网络复杂性的同时保持了完全的可验证性,其中包含了辅助文档、干扰项以及噪声。此外,我们引入了一个多维度的评估框架,用于衡量信息召回率(Information Recall)、事实准确性(Factual Accuracy)、引用覆盖率(Citation Coverage)、指令遵循能力(Instruction Following)以及深度质量(Depth Quality),并验证了该框架与人类判断的一致性。基于多种最先进(state-of-the-art)语言模型构建的多 Agent 系统 DR3-Agent 的实验表明,DR3-Eval 具有极高的挑战性,并揭示了在检索鲁棒性和 hallucination 控制方面的关键失效模式。我们的代码和数据已公开。
一句话总结
作者提出了 DR3-Eval,这是一个真实且可复现的基准测试,用于评估深度研究 agent 在多模态、多文件报告生成任务上的表现。该基准利用静态研究沙盒语料库来模拟开放网络的复杂性,并采用多维评估框架来评估信息召回率、事实准确性、引用覆盖率、指令遵循能力以及深度质量。
核心贡献
- 本文引入了 DR3-Eval,这是一个旨在评估深度研究 agent 在多模态、多文件报告生成任务上表现的真实且可复现的基准。
- 这项工作提出了一个由真实用户材料构建的研究沙盒语料库,通过使用辅助文档、干扰项和噪声,模拟了开放网络的复杂性。
- 作者开发了一个多维评估框架,用于衡量信息召回率(Information Recall)、事实准确性(Factual Accuracy)、引用覆盖率(Citation Coverage)、指令遵循(Instruction Following)和深度质量(Depth Quality),并验证了该框架与人类判断的一致性。
引言
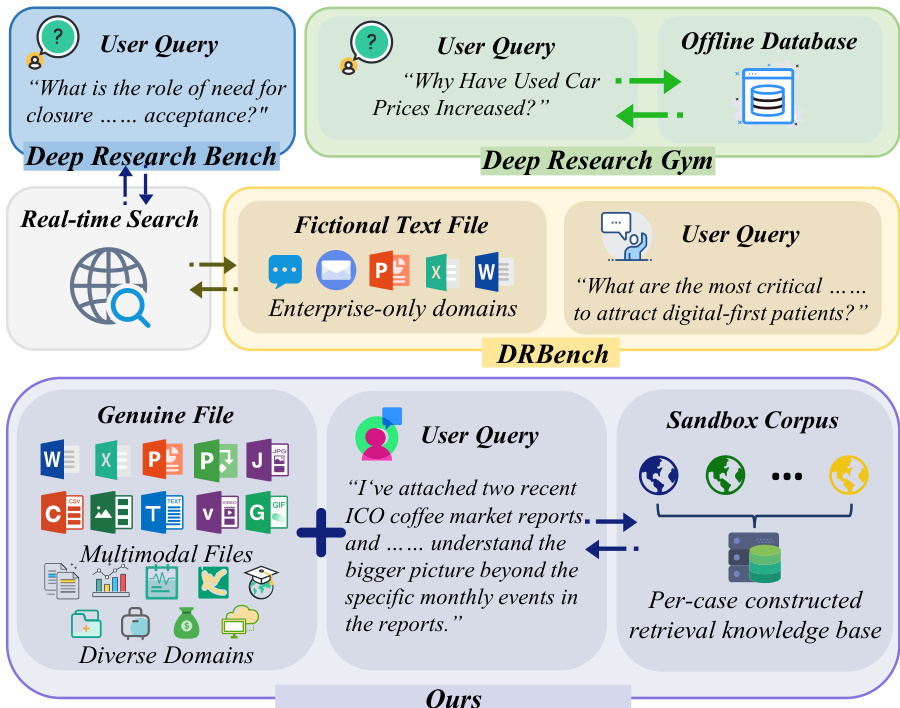
深度研究 Agent (DRAs) 旨在实现复杂、长程任务的自动化,例如规划、多模态信息检索以及结构化报告的合成。虽然这些 agent 的能力日益增强,但评估它们却非常困难,因为实时网络环境具有时间波动性且难以复现。现有的基准测试往往难以应对这一矛盾,要么依赖于不可预测的实时网络访问,要么使用简化的纯文本沙盒,缺乏现实研究中常见的多模态复杂性和噪声、误导性信息。
作者利用名为 DR3-Eval 的新基准来弥补这一差距。他们引入了一个受控的静态研究沙盒,使用精心挑选的文档、干扰项和噪声来模拟开放网络的复杂性,以确保结果既真实又完全可验证。为了提供严谨的评估,作者实现了一个多维评估框架,衡量信息召回率、事实准确性和引用覆盖率等指标,确保 agent 的性能在证据获取和分析深度两个维度上都得到评判。
数据集

作者开发了 DR3-Eval,这是一个通过五个阶段构建过程设计的高纯度基准,用于评估深度研究能力。
-
数据集构成与来源
- 数据集包含 100 个独立任务,在英文和中文样本之间均匀分配。
- 内容基于现实需求,使用由学术志愿者提供的多模态材料集(文本、结构化数据、静态视觉内容和动态媒体)。
- 主题涵盖三大主要领域:技术、经济和人文,包括计算机科学、医疗保健和金融等 13 个特定子领域。
- 输入模态包括文档 (45.98%)、图像 (27.68%) 和视频 (13.84%),其中 68% 的任务是多模态的。
-
沙盒语料库与网页子集 为了模拟现实世界的研究环境,作者采用发散-收敛关键词生成策略为每个任务构建了静态沙盒语料库。网页被分为三种不同类型:
- 辅助网页 (Supportive Web Pages): 来自信号关键词的高相关性结果,提供充分且必要的证据。
- 干扰网页 (Distractor Web Pages): 来自信号关键词但已过时、片面或不准确的结果,用于测试从误导性信息中区分有用证据的能力。
- 噪声网页 (Noise Web Pages): 来自噪声关键词的结果,用于调整信噪比。
-
处理与难度缩放
- 脱敏: 所有材料都经过自动化 PII(个人身份信息)脱敏脚本处理,随后进行人工交叉验证,以确保完全匿名化。
- 清洗: 使用统一的流水线爬取网页结果,移除失效页面,并剥离广告和导航栏等模板元素。
- 上下文缩放: 为了模拟信息质量的长尾效应,作者实施了精细的难度缩放策略,设有五个上下文长度:32k, 64k, 128k, 256k 和 512k tokens。
- 混合策略: 所有设置都包含全套辅助网页。随着目标上下文长度的增加,干扰页面的数量按比例增加,剩余配额由噪声网页填充。
-
质量控制与查询构建
- 作者使用基于证据的反向构建方法,即根据预定文档合成查询,以确保答案是可验证的并且需要综合推理。
- 应用“QC 漏斗”将最初的 280 个候选任务筛选至最终的 100 个。如果任务缺乏综合必要性、可以通过公开搜索轻松获取捷径或包含歧义解释,则会被丢弃。
方法
作者利用 MiroFlow 框架构建了 DR³-Agent,这是一个由大语言模型 (LLM) 驱动的系统,旨在解决 DR³-Eval 提出的深度研究挑战,特别是涉及用户提供文件和离线沙盒语料库的任务。系统的架构围绕一个核心推理枢纽——主 agent 构建,该 agent 通过动态的“计划-行动-观察”循环来编排信息获取和报告生成。该主 agent 维护全局任务上下文,并协调专门的 sub-agents 来处理特定的信息获取任务,从而减轻主要推理组件的负担。如下图所示,系统同时处理用户提供的文件和沙盒语料库(这是一个针对每个案例构建的检索知识库)。主 agent 配备了感知工具,使其能够直接处理音频和视频等多模态用户文件,从而能够在全局上下文中合成内容,而不是将其视为孤立的提取任务。这种设计对于系统从多样化来源合成信息的能力至关重要。
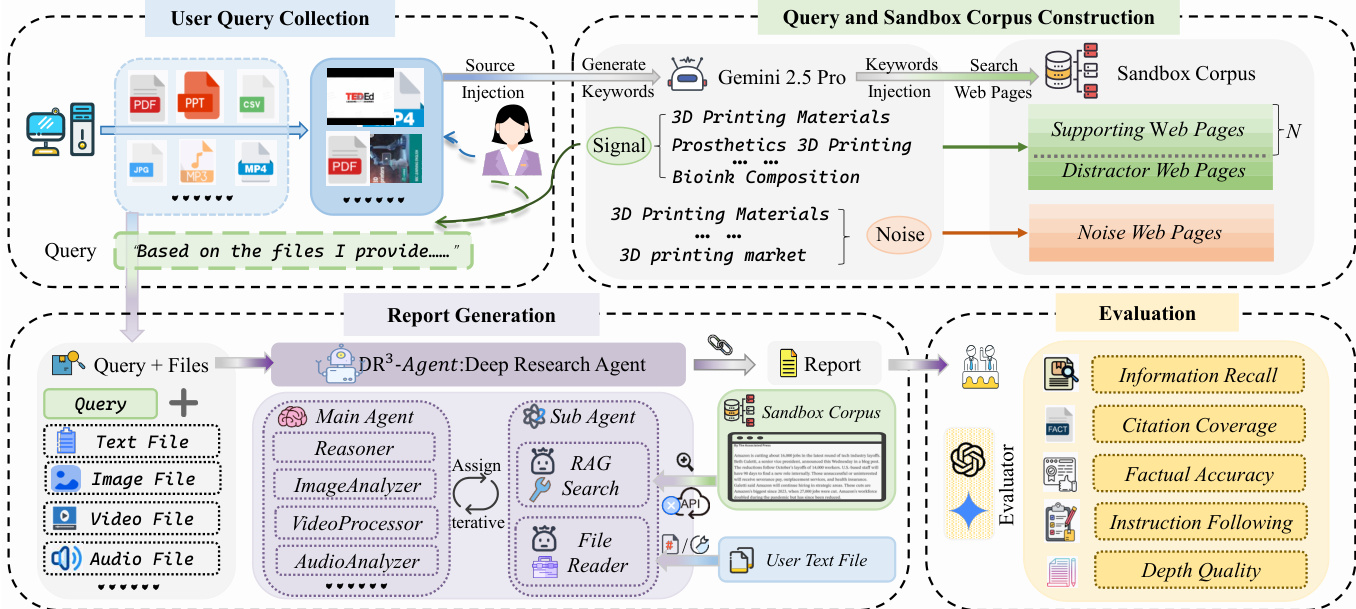
在信息获取层面,系统采用了两个专门的 sub-agents(均由相同的底层 LLM 提供支持)来执行特定任务。RAG 搜索 sub-agent 负责与静态沙盒语料库进行交互。它在受控环境中,使用基于 text-embedding-3-small 模型的迭代密集检索机制取代了传统的开放网络搜索。该 agent 使用 ReAct 范式进行自主、多步骤的检索,并进行迭代查询优化。这一过程允许 agent 评估不完整或冲突的证据,并在迭代中修正搜索方向,使得搜索在功能上类似于在超链接图上的启发式探索。文件阅读 sub-agent 专门用于解析长文本用户文件,利用工具执行精细的关键词查询并按页码检索内容。两个 sub-agents 独立运行,不共享全局状态,且仅向主 agent 返回高度浓缩的摘要。
报告生成过程始于主 agent,它根据查询和文件生成一份详尽的报告。随后,该报告通过一系列指标进行评估以衡量其质量。评估框架包括:信息召回率 (IR),衡量从用户文件和沙盒语料库中提取特定见解的覆盖范围;引用覆盖率 (CC),评估模型检索和引用查询所需文档的能力;事实准确性 (FA),通过模型验证文本陈述,并使用 Gemini-2.5-Pro 验证基于视频或音频内容的陈述,从而评估报告内主张的真实性;指令遵循 (IF),确保报告满足任务查询衍生的所有要求;以及深度质量 (DQ),使用模型作为专家评委来评估报告的分析实质和逻辑严密性。这一全面的评估框架确保了生成的报告在准确性、完整性和分析深度方面均达到高标准。
实验
DR3-Eval 框架通过结合自动化指标和基于 LLM 的评委,评估信息寻求质量和报告生成,从而对长程研究任务进行评估。实验表明,虽然模型性能随规模增长,但增加上下文长度会引入噪声并降低证据检索效果,且高指令遵循能力并不能本质上保证事实准确性。最终结果表明,当前模型的主要瓶颈在于报告生成过程中维持对外部证据的落地(grounding),而非简单的信息获取。
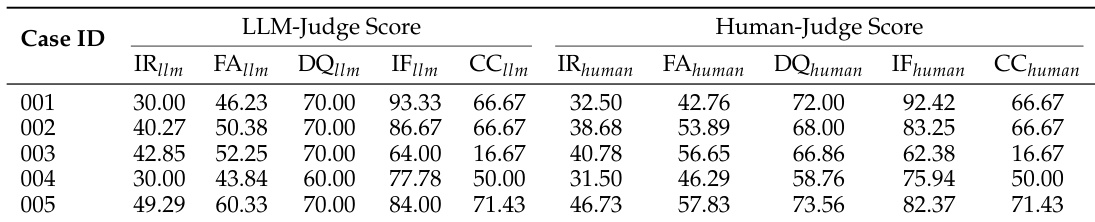
该表比较了五个案例在多个指标上的 LLM 生成评分与人类评估评分。结果显示,LLM 与人类评委在大多数维度上表现出一致的性能,但在单个指标的分数上存在细微差异。LLM 和人类评委在所有案例的评分上表现出强一致性。信息召回率和引用覆盖率指标在 LLM 和人类评估之间表现出最一致的对齐。某些指标如事实准确性和指令遵循在 LLM 和人类评分之间显示出较小的差异。
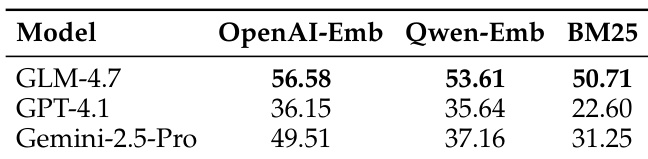
该表比较了三种模型下不同检索方法的性能,结果显示 OpenAI-Emb 获得了最高分,其次是 Qwen-Emb,而 BM25 表现最低。结果表明,embedding 方法的选择显著影响检索效果。OpenAI-Emb 在所有模型中均优于 Qwen-Emb 和 BM25。BM25 在三种检索方法中表现最差。基于 embedding 的方法显著优于传统的基于词汇的方法。
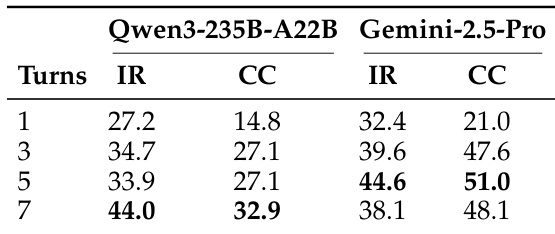
该表展示了改变 RAG 迭代轮数对模型性能的影响,包含信息召回率 (IR) 和引用覆盖率 (CC) 指标。性能通常随着迭代轮数的增加而提高,但某些模型在达到峰值后会出现下降,表明存在收益递减现象。增加 RAG 迭代轮数通常在一定范围内能提升性能,对于某些模型,性能在较高迭代次数下会达到峰值后下降。与信息召回率相比,引用覆盖率随着轮数增加表现出更明显的提升。
{"caption": "Model performance across domains", "summary": "作者在不同领域评估了多个语言模型,显示出性能存在显著差异。结果表明模型排名因领域而异,某些模型在特定领域表现出色,而其他模型在大多数领域表现稳定。", "highlights": ["不同领域的性能差异显著,顶尖模型展现出强大的领域特定优势。", "模型在大多数领域表现出一致的排名,表明其相对性能稳定。", "评估显示没有单一模型能统治所有领域,突显了领域特定适配的重要性。"]}
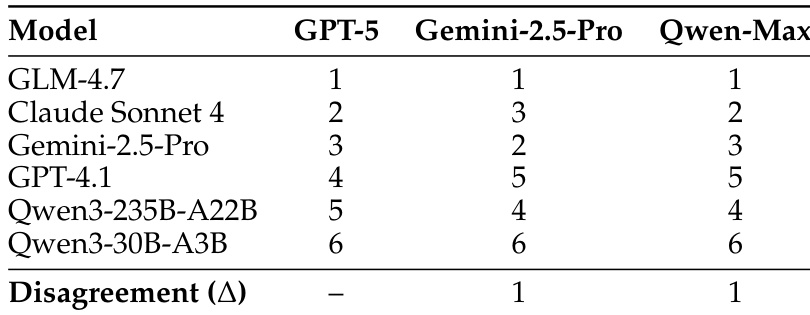
该表展示了三个评委模型对不同模型的排名,各评委之间的排名具有高度一致性。顶尖模型的排序争议极小,表明评估结果稳健且稳定。不同评委模型之间的排名高度一致,争议极小。Claude Sonnet 4 在所有三个评委模型中均获得最高排名。GPT-5、Gemini-2.5-Pro 和 Qwen-Max 产生的模型排名几乎完全相同。
这些实验评估了基于 LLM 评分的可靠性、各种检索方法的有效性,以及 RAG 迭代轮数对不同领域模型性能的影响。结果表明,LLM 评委与人类评估紧密对齐,并在不同评委模型之间保持一致的排名。此外,基于 embedding 的检索方法显著优于基于词汇的方法,虽然增加 RAG 迭代通常能提升性能,但模型最终会遇到收益递减的情况。