Command Palette
Search for a command to run...
Large Language Models 的 Agent Skills:架构、获取、安全与未来路径
Large Language Models 的 Agent Skills:架构、获取、安全与未来路径
Ranjun Xu Yang Yan
摘要
从单体化语言模型向具备模块化技能(skill-equipped)的 Agent 转型,标志着大语言模型(LLMs)在实际应用部署方式上的决定性转变。Agent 的技能并非将所有程序性知识编码在模型权重中,而是作为一种由指令、代码和资源构成的可组合软件包,由 Agent 根据需求按需加载,从而实现无需重新训练即可动态扩展能力。这一转变被形式化为一种包含渐进式披露(progressive disclosure)、可移植技能定义以及与 Model Context Protocol (MCP) 集成的范式。本综述对近几个月内快速演进的 Agent 技能领域进行了全面的梳理。我们将该领域的研究划分为四个维度:(i) 架构基础,探讨 SKILL.md 规范、渐进式上下文加载(progressive context loading),以及技能与 MCP 之间的互补角色;(ii) 技能获取,涵盖结合技能库的强化学习(SAGE)、自主技能发现(SEAgent)以及组合式技能合成;(iii) 规模化部署,包括计算机使用 Agent(CUA)技术栈、GUI Grounding 的进展,以及在 OSWorld 和 SWE-bench 等 benchmark 上的进展;(iv) 安全性,近期的实证分析揭示了……
一句话总结
Ranjun Xu 和 Yang Yan 提供了一项最新调查,将 agent 技能定义为模块化包,能够在无需重新训练的情况下实现动态能力扩展,并根据 SKILL.md 和 Model Context Protocol 等架构基础、包括 SAGE 和 SEAgent 在内的获取方法、通过 computer-use agent 堆栈的大规模部署、GUI grounding 进展以及 OSWorld 和 SWE-bench 上的基准测试和安全分析来组织该领域。
核心贡献
- 本调查沿四个轴线组织 agent 技能格局,涵盖架构基础、技能获取、部署和安全。它检查了 SKILL.md 等规范和 OSWorld 等基准,以描绘该领域的快速演变。
- 引入了一种信任与生命周期治理框架,通过将信任决策与二元接受或拒绝操作解耦来解决安全挑战。这种方法将权限与来源和验证深度对齐,以管理开放性与安全性之间的紧张关系。
- 分析强调了 SAGE 和 SEAgent 等系统中的模型内部技能学习与将技能外部化为可移植、可审计工件的能力之间的脱节。弥合这一差距将统一获取和部署范式,以实现更好的治理。
引言
向模块化 agent 技能的转变解决了通用模型与现实部署所需的专业过程专业知识之间的紧张关系。先前的方法(如微调)成本高昂且缺乏组合性,而检索增强生成提供的是无法执行复杂工作流的被动知识。作者提供了第一份全面调查,专门关注这一新兴的技能抽象层,而非广泛的 agent 工具使用。他们对架构、获取、部署和安全领域的格局进行了分类,同时提出了一种新的技能信任与生命周期治理框架,以减轻社区贡献技能中的漏洞。
数据集
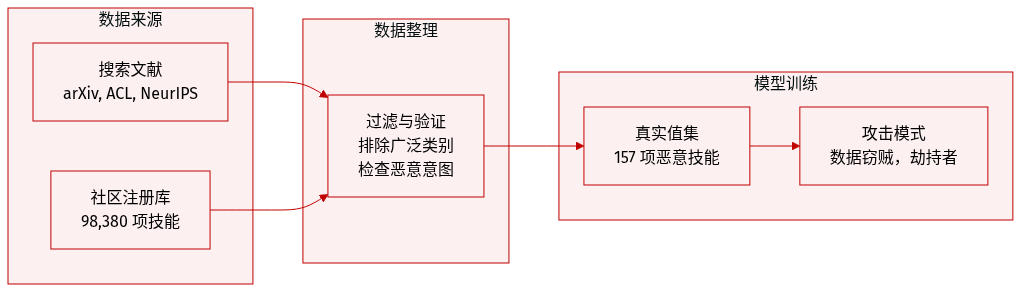
数据集组成和来源
- 作者从 arXiv、ACL Anthology、NeurIPS、ICML、ICLR 会议论文集和 Anthropic 出版物中收集文献。
- 一个真实数据集由包含 98,380 个技能的两个社区注册表构建而成。
每个子集的关键细节
- 调查数据针对技能抽象层,排除通用 LLM agent 架构。
- 恶意技能子集包括 157 个已确认案例,其中识别出 632 个漏洞。
- 攻击模式分为数据窃贼或 agent 劫持者。
数据使用和数据处理
- 搜索查询侧重于 agent 技能和 computer use agents 等术语。
- 技能经过行为验证,以建立恶意意图的真实情况。
- 分析显示,一个工业化行为者负责 54.1% 的已确认案例。
元数据和过滤
- 过滤规则排除了涵盖广泛工具使用分类的早期调查。
- 元数据构建识别每个技能的具体漏洞数量和攻击原型。
方法
提出的框架侧重于编码过程知识的结构化方法,称为"Agent Skills"。该方法通过采用渐进式披露架构解决了标准上下文窗口的局限性。系统不使用一次性加载整个技能定义,而是利用三层加载机制来平衡信息密度与计算效率。
参考下面的框架图以可视化此层次结构。
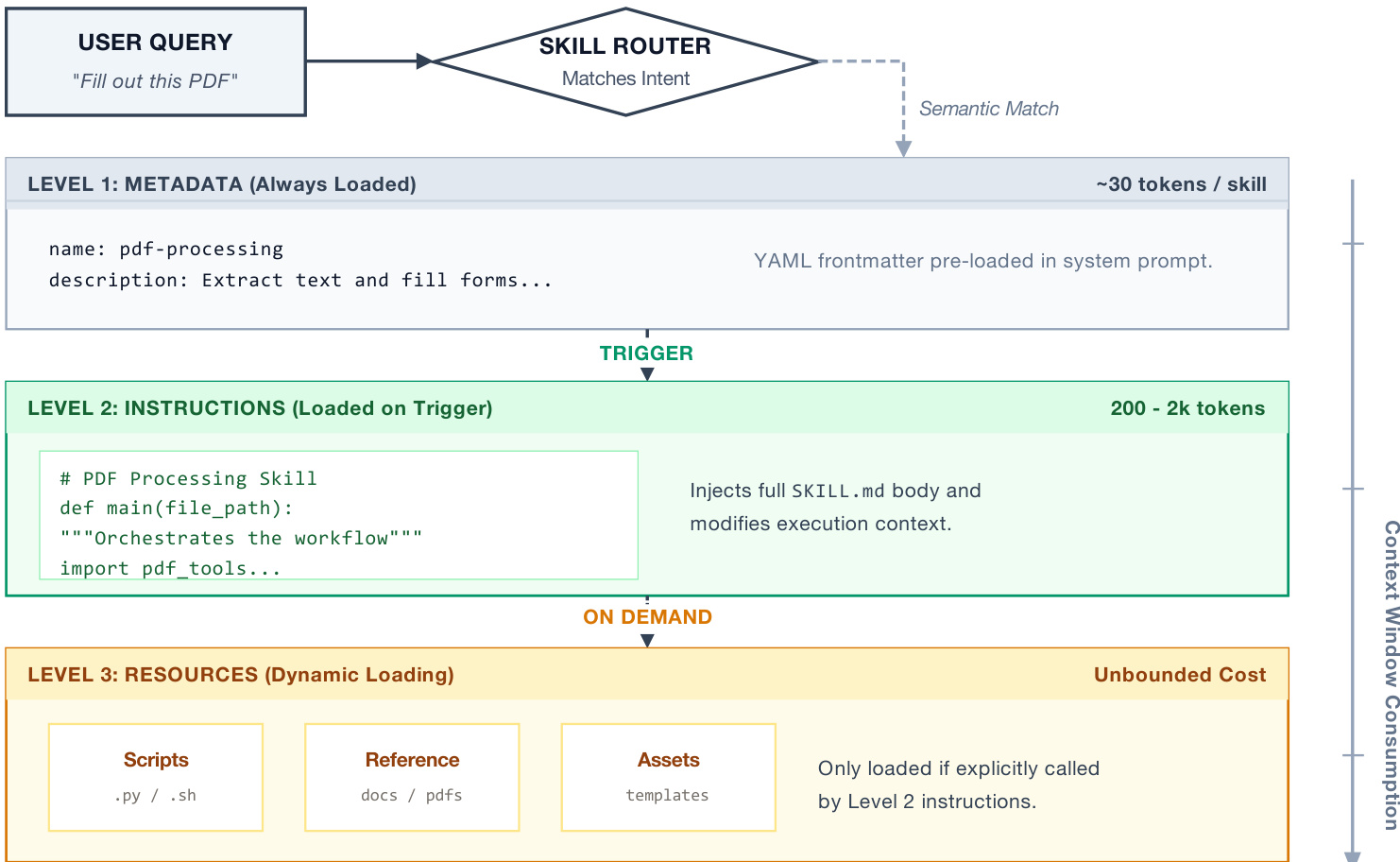
第 1 层由元数据组成,例如技能名称和描述,这些内容预加载到系统提示中。这每个技能仅需大约 30 tokens,允许拥有大型库而不会带来显著的上下文惩罚。第 2 层包含 SKILL.md 正文中的完整过程指令。这些仅在通过语义匹配触发特定技能时加载。第 3 层包含动态资源,包括脚本、参考文档和资产。如果第 2 层指令明确调用,这些资源将严格按需加载。此设计确保 agent 在保持活动上下文窗口最小的同时,仍能访问深层过程知识。
这些技能的执行遵循 agent 堆栈内的特定生命周期。当指定用户意图时,Skill Router 将请求匹配到库中的技能。执行过程涉及两个不同的阶段:将技能的指令和资源作为隐藏消息注入对话上下文,以及修改 agent 的执行环境以激活预先批准的工具。
操作流程在下面的架构图中详细说明。
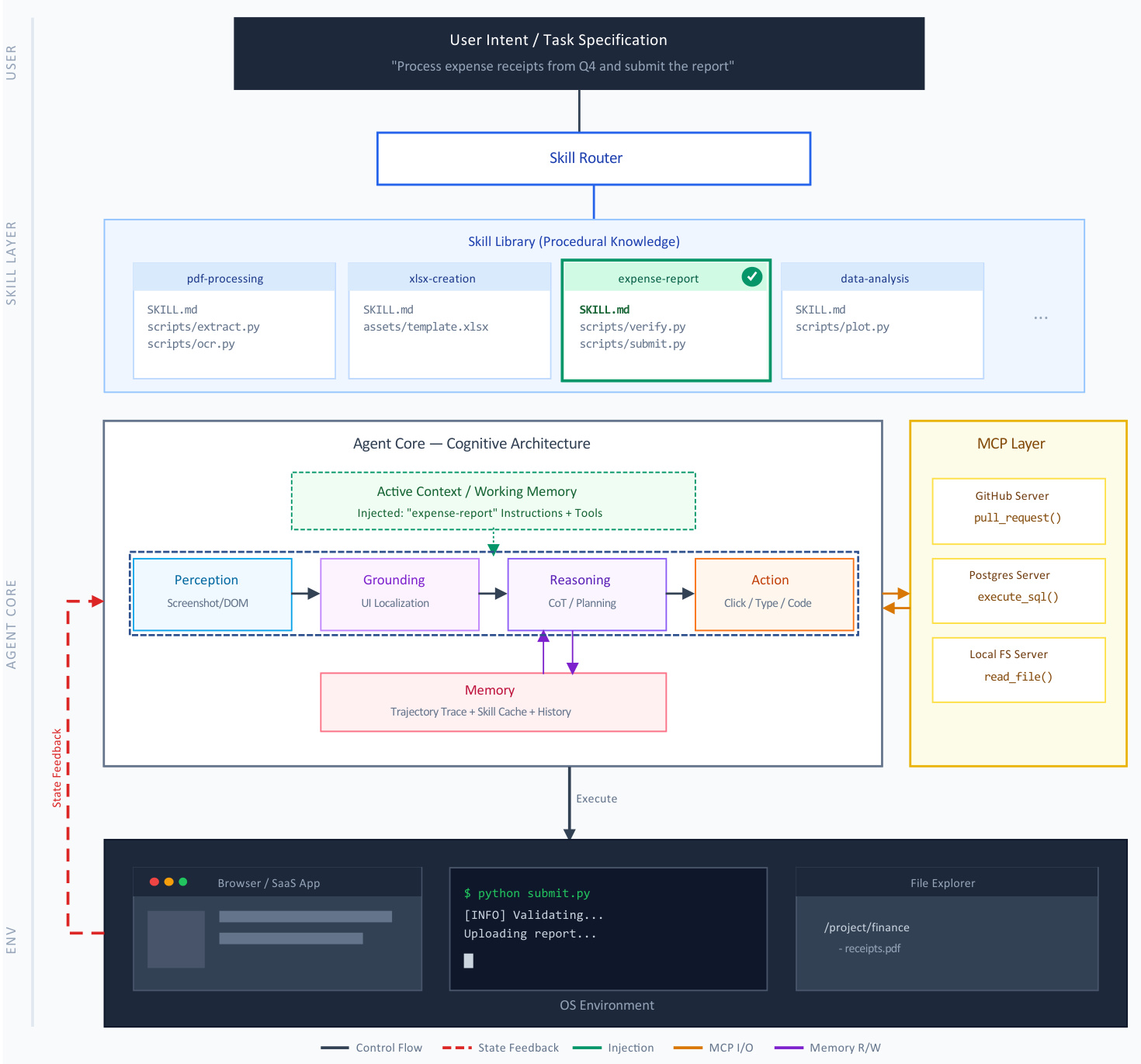
Agent Core 通过感知、Grounding、推理和行动的循环处理丰富的上下文。该核心与外部 Model Context Protocol (MCP) 层交互,该层标准化了与 GitHub 或 PostgreSQL 等数据源和工具的连接。技能和 MCP 作为正交层运行。虽然 MCP 提供连接原语,但技能提供过程智能,指导 agent 如何解释输出和处理故障。
为了确保跨不同获取路径的安全性,作者提出了一种技能信任与生命周期治理框架。该系统考虑了技能的不同来源,范围从人工编写的文档到 RL 学习或自主 agent。
治理模型在下面的图表中说明。
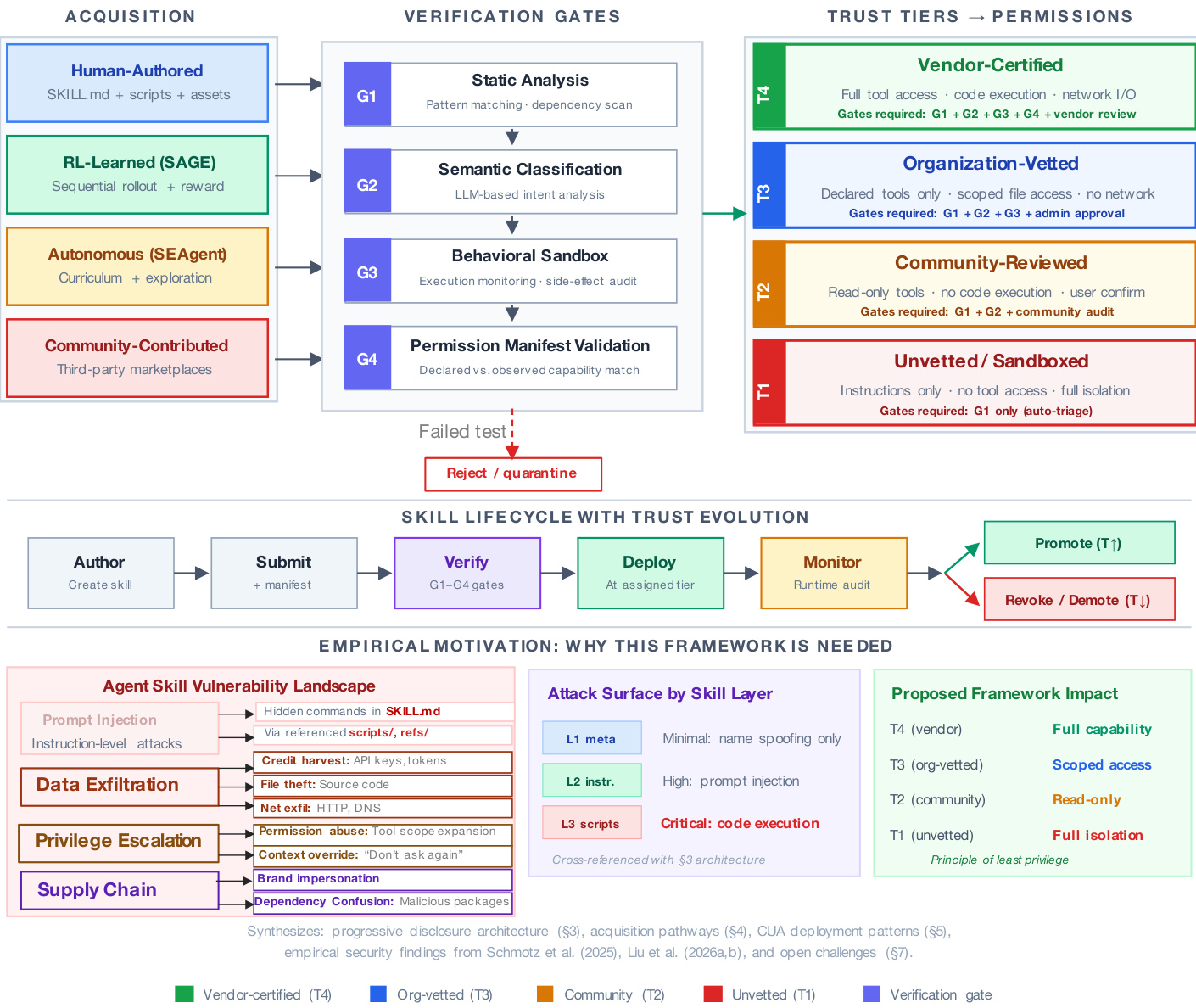
安全通过四个连续验证门强制执行。G1 应用静态分析和依赖扫描。G2 使用基于 LLM 的语义分类来检测意图不匹配。G3 在行为沙箱中执行技能以监控副作用。G4 根据观察到的行为验证权限清单。基于这些门的结果和技能的来源,框架将技能分配给特定的信任层级。这种分层方法遵循最小特权原则。例如,未经验证的技能 (T1) 仅获得指令访问权限并完全隔离,而供应商认证的技能 (T4) 则被授予完整的工具访问权限和代码执行能力。此映射将治理决策与渐进式披露层的具体攻击面保持一致,确保可执行脚本仅对高信任层级可访问。
实验
实验验证了通过强化学习、自主发现和结构化表示集成技能库可显著提高跨软件环境的任务完成率和效率。虽然 GUI grounding 和组合合成使较小的模型能够在复杂基准测试中胜过较大的模型,但在专业应用和扩展任务中仍存在挑战。安全分析进一步表明,这些架构引入了关键风险,例如市场仓库中的提示注入和数据泄露漏洞。
该表格概述了 Computer-Using Agents 在不同基准测试中的当前性能格局,确定了表现最佳的模型及其相对于人类基准的成功率。它表明,虽然 agent 在某些通用操作系统任务上已达到人类水平的熟练度,但在专业应用等特定领域中仍存在显著的性能差距。专有模型在 OSWorld-V 上实现了与人类基准相当的性能。像 CUA-Skill 这样的专用 agent 在 Windows 特定基准测试中领先。编码任务的成功率通常高于专业 GUI 交互。
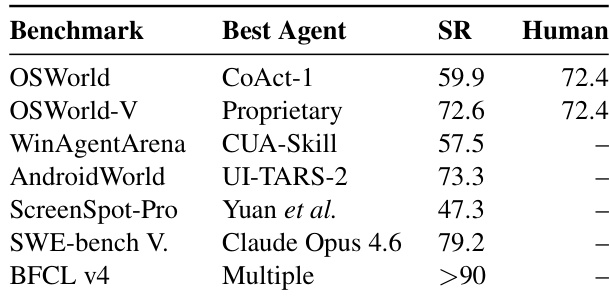
此评估评估了 Computer-Using Agents 在不同基准测试中相对于人类基准的性能格局。结果表明,虽然专有模型在通用操作系统任务上实现了人类水平的熟练度,并且专用 agent 在 Windows 特定环境中表现出色,但在专业应用领域仍存在显著差距。此外,编码任务的成功率通常高于专业图形用户界面交互,突显了复杂 GUI 操作中的持续挑战。