Command Palette
Search for a command to run...
pi0.7:一种具有涌现能力的、可控的通用机器人 Foundation Model
pi0.7:一种具有涌现能力的、可控的通用机器人 Foundation Model
摘要
我们提出了一种名为 π0.7 的新型机器人 foundation model,它能够在广泛的场景中实现强大的开箱即用(out-of-the-box)性能。π0.7 能够遵循在未知环境下的多样化语言指令,包括涉及各种厨房电器的多阶段任务;它还具备零样本跨具身泛化(zero-shot cross-embodiment generalization)能力,例如使机器人在未见过该任务的情况下能够完成折叠衣物的工作;此外,它还能执行具有挑战性的任务,例如在无需额外训练的情况下操作意式浓缩咖啡机,其表现水平足以媲美经过专门 RL-finetuned 的模型。π0.7 的核心思想是在训练过程中使用多样化的 context conditioning。这些包含在 prompt 中的调节信息,使得模型能够被精确地引导,从而以不同的策略执行多种任务。其 conditioning 信息不仅限于描述任务内容的语言指令,还包括描述执行方式或策略的其他多模态信息,例如关于任务表现的元数据(metadata)和子目标图像(subgoal images)。这使得 π0.7 能够利用极其多样化的数据。
一句话总结
pi0.7 是一个可操控的通用机器人基础模型,利用多样化的上下文条件设置与多模态提示信息来精确引导任务策略,在未见过的环境中提供强大的开箱即用性能,并在如折叠衣物等任务上实现零样本跨本体泛化,同时在操作意式咖啡机等挑战性任务上匹配专门强化学习微调模型的性能。
核心贡献
- 本文介绍了 π0.7,一种旨在无需特定任务后训练即可在各种场景中提供强大开箱即用性能的机器人基础模型。
- 该方法在训练期间利用多样化的上下文条件设置,通过用策略元数据和子目标图像增强语言指令,以解决多样化数据集中的歧义。
- 评估结果展示了零样本跨本体泛化能力,以及在不专门微调的情况下,执行挑战性任务的性能可与专门强化学习微调模型相匹配。
引言
物理智能旨在在机器人领域建立类似于大型语言模型的通用能力,但先前的视觉 - 语言 - 动作模型缺乏组合泛化能力,且通常需要特定任务的微调。在多样化数据集上训练往往导致模型平均化不同的策略,从而导致性能次优。作者介绍了 pi_0.7,这是一种可操控的通用机器人基础模型,利用多样化的上下文条件设置来解决混合质量数据中的歧义。通过用详细的语言、子目标图像和策略元数据丰富提示,该模型学习在不进行微调的情况下有效组合技能,从而实现零样本跨本体迁移,并在复杂灵巧任务上表现稳健。
数据集

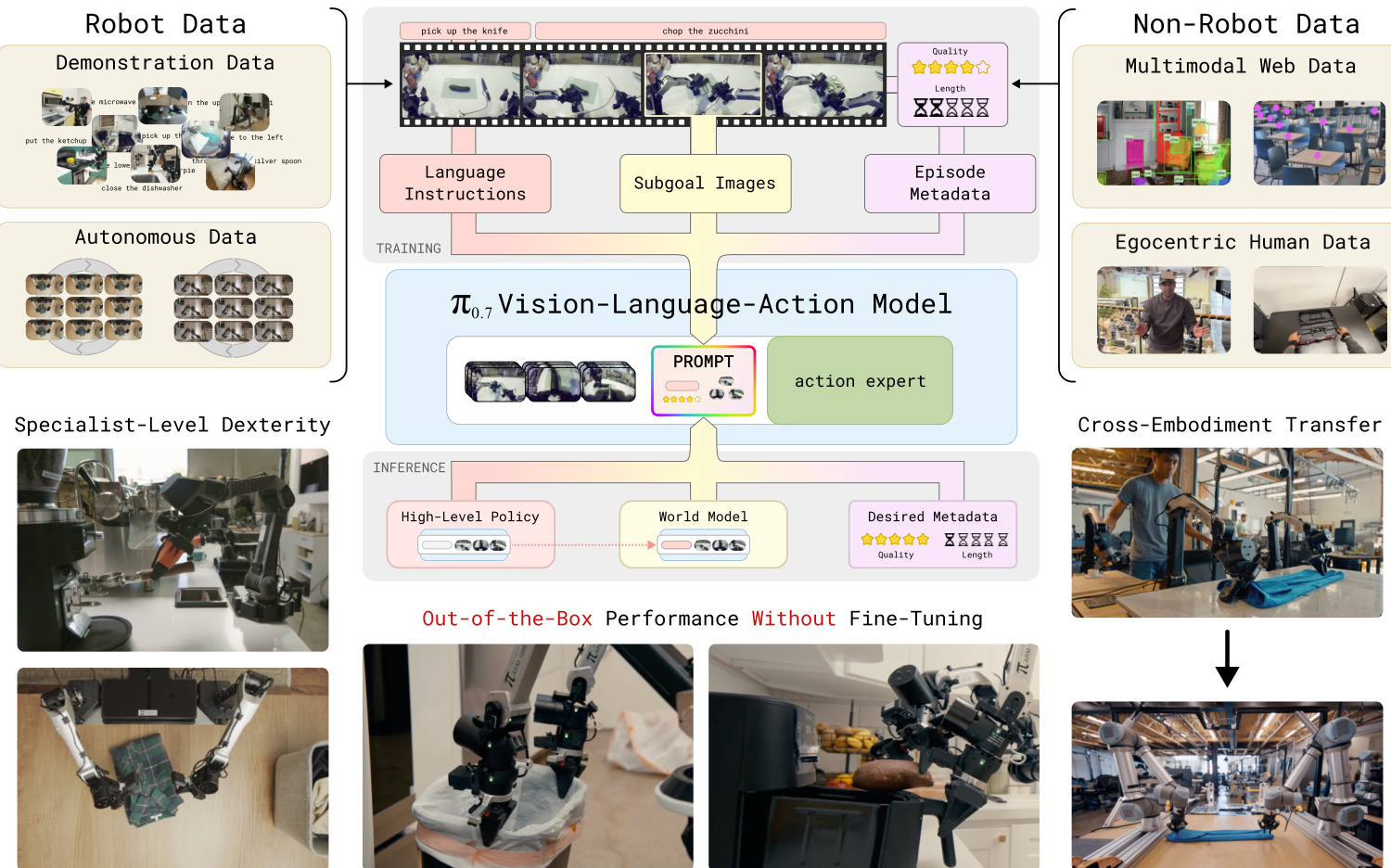
- 组成与来源: 作者聚合了来自不同机器人平台(静态、移动、单臂和双臂)在实验室、家庭和野外环境中运行的演示数据。混合数据还包括来自策略评估的自主数据、人工干预、开源机器人数据集、第一人称人类视频,以及用于视觉问答和物体预测的辅助网络数据。
- 次优数据策略: 不同于经典流程,该数据集故意包含较低质量的演示、失败片段以及先前模型版本的轨迹。这种方法使模型能够从强化学习训练的专业模型中提炼能力,并提高在不同状态下的稳健性。
- 元数据处理: 构建片段元数据以标记任务执行属性。速度被离散化为 500 步区间,质量获得 1 到 5 的评分,人工标注者识别动作序列中的错误片段。
- 训练与使用: 上下文模态,包括指令、图像和元数据,在训练期间进行 dropout 以确保灵活的提示。在推理时,模型使用真实元数据来根据所需的速度、质量和准确性调节性能。
方法
π0.7 模型是一个专为通用机器人操作设计的视觉 - 语言 - 动作(VLA)基础模型。它建立在 π0.6 架构和 MEM 记忆系统之上,并扩展了多模态上下文条件设置。该模型由一个源自 Gemma 3 的 40 亿参数 VLM 骨干网络组成,其中包括一个 4 亿参数 SigLIP 视觉编码器,以及一个独立的 8.6 亿参数动作专家。总参数数量约为 50 亿。
作者利用流匹配目标让动作专家预测连续动作块。VLM 骨干网络处理视觉观察和语言输入,而动作专家关注这些激活以生成机器人命令。这种分离允许在运行时进行快速推理,同时通过 FAST tokens 上的离散交叉熵损失保持骨干网络的稳定训练,该技术被称为知识隔离(Knowledge Insulation)。
参考下方的架构图以详细了解模型组件和数据流。
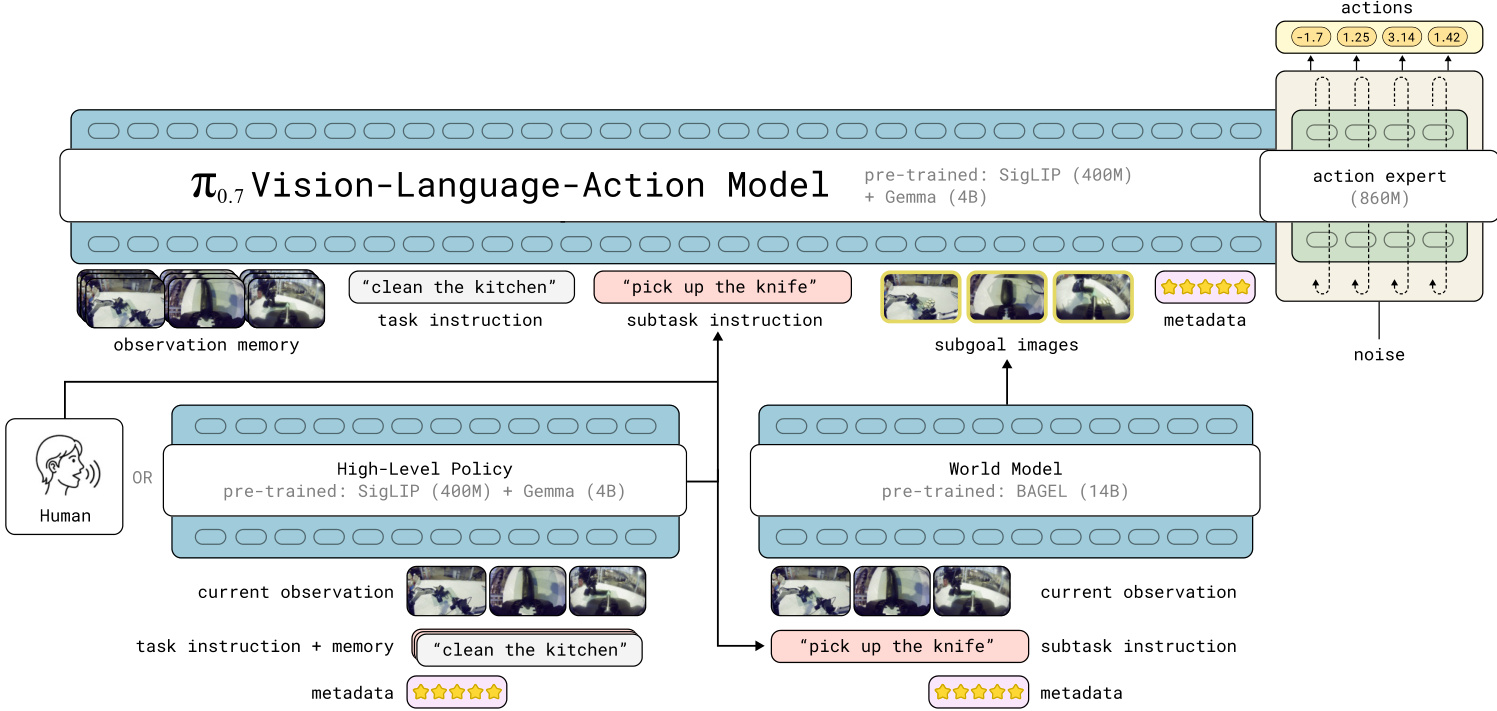
π0.7 的一项关键创新是将上下文提示 Ct 扩展到简单的语言指令之外。该模型接受丰富的输入集,包括多视角观察记忆、任务指令、子任务指令、片段元数据和子目标图像。这种多模态提示使模型能够从多样化和异构的数据集中学习,包括次优行为和失败。
该系统集成高级策略和世界模型以在运行时生成这些上下文元素。高级策略生成语义子任务指令,而世界模型生成描绘场景期望近未来状态的子目标图像。这些子目标图像提供了语言本身可能缺乏的空间定位。
参考下方的系统概览图,说明机器人和非机器人数据如何输入训练流程以及模型如何在推理期间运行。
在训练期间,模型暴露于真实未来图像和生成的子目标图像的组合中。为了处理图像质量和延迟的变异性,作者采用了一种特定的采样方案,其中真实图像从未来时间步采样或由世界模型生成。训练目标最大化给定观察和上下文的动作块的对数似然:
maxθED[logπθ(at:t+H∣ot−T:t,Ct)]
该模型利用块因果掩码方案,其中观察和子目标 tokens 使用双向注意力,而文本 tokens 使用因果注意力。该结构在下方的注意力掩码图中可视化。
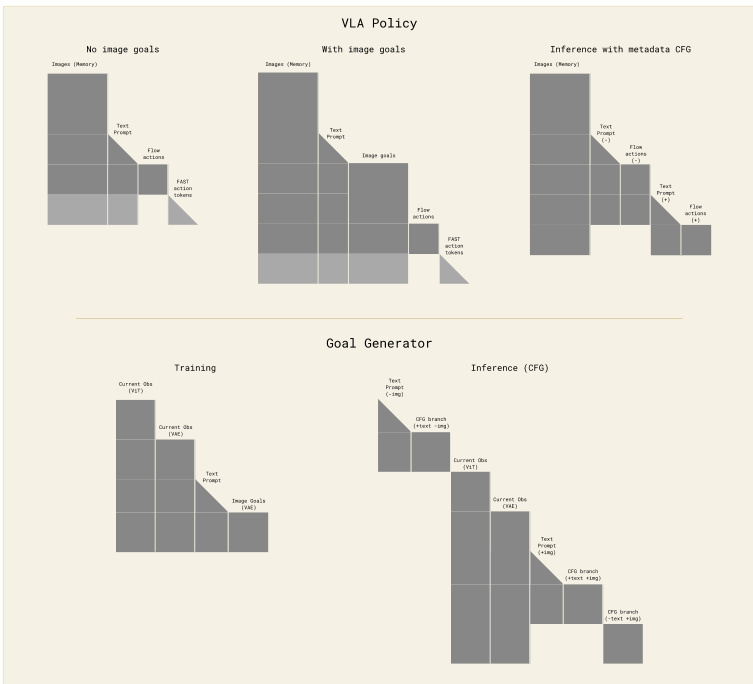
在推理时,模型支持对片段元数据进行无分类器引导(CFG),以激发特定行为,如更高的速度或质量。每当语义意图改变或经过固定时间间隔后,子任务指令和子目标图像会刷新。以下序列展示了模型使用逐步口头指导和子任务指令执行涉及空气炸锅的复杂任务。

实验
评估针对 π0.7 模型在各种机器人平台和任务上的表现,具体测试开箱即用的灵巧性、指令遵循、跨本体迁移和组合泛化。结果表明,π0.7 在复杂操作任务上无需后训练即可与专门微调模型相匹配,并通过调整操作策略成功将技能迁移到未见过的机器人形态上。此外,该模型表现出卓越的语言遵循能力,使其能够克服数据集偏差,通过口头指导执行新的长视野任务,同时有效利用大规模混合质量数据集以改进泛化。