Command Palette
Search for a command to run...
TurboQuant:具有近乎最优失真率的在线 Vector Quantization 方法
TurboQuant:具有近乎最优失真率的在线 Vector Quantization 方法
Amir Zandieh Majid Daliri Majid Hadian Vahab Mirrokni
摘要
向量量化(Vector quantization)是一个源于香农(Shannon)信源编码理论的问题,其目标是在量化高维欧几里得向量的同时,最大限度地减少其几何结构的失真。针对现有方法无法实现最优失真率(distortion rates)的局限性,我们提出了 TURBOQUANT,旨在同时解决均方误差(MSE)和内积(inner product)失真问题。我们设计的“数据无关”(data-oblivious)算法适用于在线应用场景,在所有比特宽度(bit-widths)和维度下均能实现接近最优的失真率(误差在极小的常数因子范围内)。TURBOQUANT 的实现原理是通过对输入向量进行随机旋转,使坐标呈现集中的 Beta 分布,并利用高维空间中不同坐标之间近似独立的特性,从而能够简单地对每个坐标应用最优标量量化器(scalar quantizers)。考虑到 MSE 最优量化器会在内积估计中引入偏差(bias),我们提出了一种两阶段方法:首先应用 MSE 量化器,随后对残差(residual)进行 1-bit 量化 Johnson-Lindenstrauss(QJL)变换,从而得到一个无偏的内积量化器。此外,我们还对任何向量量化器所能达到的最佳失真率的信息论下界(information-theoretic lower bounds)进行了形式化证明,结果表明 TURBOQUANT 与这些下界高度吻合,仅存在一个极小的常数因子差异。
一句话总结
TurboQuant 是一个数据无关的在线向量量化框架,通过对输入向量进行随机旋转以实现每个坐标的最优标量量化,并采用两阶段方法,先应用 MSE 量化器,再对残差应用 1 比特量化 JL 变换,从而产生无偏内积量化器并匹配信息论下界;该框架在所有位宽和维度下,针对均方误差和内积失真实现了在一个小常数因子内的接近最优的失真率。
核心贡献
- 本文介绍了 TURBOQUANT,这是一种旨在最小化向量量化中均方误差和内积失真的数据无关算法。该方法通过随机旋转输入向量以利用标量量化的近似独立性特性,在所有位宽和维度下实现了接近最优的失真率。
- 提出了一种两阶段方法,通过先应用 MSE 量化器再对残差向量应用 1 比特量化 JL 变换来消除内积估计中的偏差。这种组合产生了一个具有可证明最优失真界限的无偏内积量化器。
- 该工作提供了任何向量量化器最佳可实现失真率的信息论下界的正式证明。TURBOQUANT 紧密匹配这些界限,并在位宽依赖性方面实现了相对于现有方法的指数级改进。
引言
向量量化对于压缩大型语言模型和向量数据库中的高维向量至关重要,以减少内存需求和推理延迟。先前的工作通常面临一种权衡,即算法缺乏实时应用的加速器兼容性,或者相对于位宽遭受次优的失真界限。为了克服这些限制,作者提出了 TurboQuant,这是一种针对现代硬件加速器优化的轻量级在线方法。该方法利用两阶段流程,将 MSE 最优量化器与残差量化器相结合,以提供具有可证明最优失真率的无偏内积估计。
方法
TURBOQUANT 框架通过设计特定映射来最小化均方误差 (MSE) 和内积失真,从而解决向量量化问题。核心目标涉及定义量化映射 Q:Rd→{0,1}B 和逆去量化映射 Q−1:{0,1}B→Rd。作者旨在最小化最坏情况向量的期望失真,而不需要对输入数据集做任何假设。
对于 MSE 优化,该方法采用随机旋转策略以简化量化景观。过程始于将输入向量 x 乘以随机旋转矩阵 Π∈Rd×d。此旋转确保生成的向量均匀分布在单位超球面上。因此,旋转向量的每个坐标遵循 Beta 分布,在高维下收敛于高斯分布。利用高维下不同坐标的近似独立性,作者对每个坐标独立应用最优标量量化器。Beta 分布的最优质心使用 Max-Lloyd 算法预先计算并存储在码本中。在量化期间,算法识别每个旋转坐标的最近质心。去量化涉及检索这些质心并应用逆旋转 Π⊤ 以在原始基中重建向量。这些过程的伪代码在算法 1 中给出。
为了处理内积估计,作者认识到 MSE 最优量化器会引入偏差。他们提出了一种两阶段算法以实现无偏内积估计。第一阶段使用位宽 b−1 应用 MSE 优化量化器 Qmse。第二阶段使用 1 比特量化 Johnson-Lindenstrauss (QJL) 变换处理残差误差向量。QJL 映射将残差投影到具有高斯条目的随机矩阵上并应用符号函数。最终重建结合了 MSE 去量化向量和残差的缩放 QJL 重建。这种混合方法确保内积估计器保持无偏,同时保持低失真率。此过程的伪代码在算法 2 中给出。
理论分析表明 TURBOQUANT 实现了接近最优的失真率。通过利用香农下界和姚氏极小极大原理,作者证明了 MSE 失真在信息论下界的一个小常数因子内。同样,内积失真界限被证明对于任何给定位宽几乎是最佳的。这些保证适用于所有位宽和维度,验证了所提出的数据无关算法用于在线应用的效率。
实验
实验利用 NVIDIA A100 GPU 在 DBpedia 数据集上验证理论误差界限,并使用 Llama-3.1-8B-Instruct 和 Ministral-7B-Instruct 模型评估长上下文任务上的下游性能。结果证实,所提出的方法与理论预测一致,通过保持无偏内积估计并在显著压缩下实现与全精度模型相当的召回分数。此外,近邻搜索评估表明,在召回准确性方面始终优于基线量化技术,突显了该方法在高维搜索和生成任务中的鲁棒性。
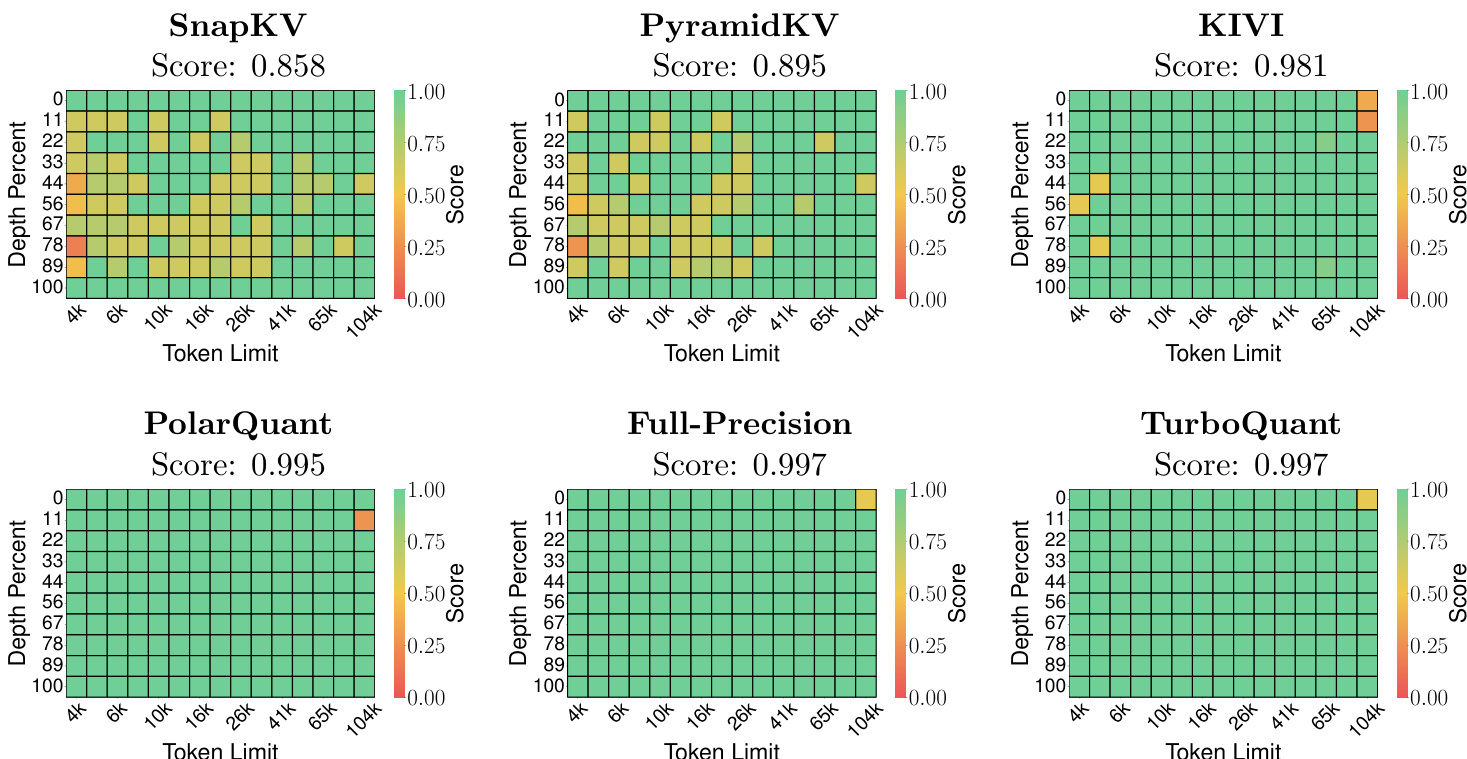
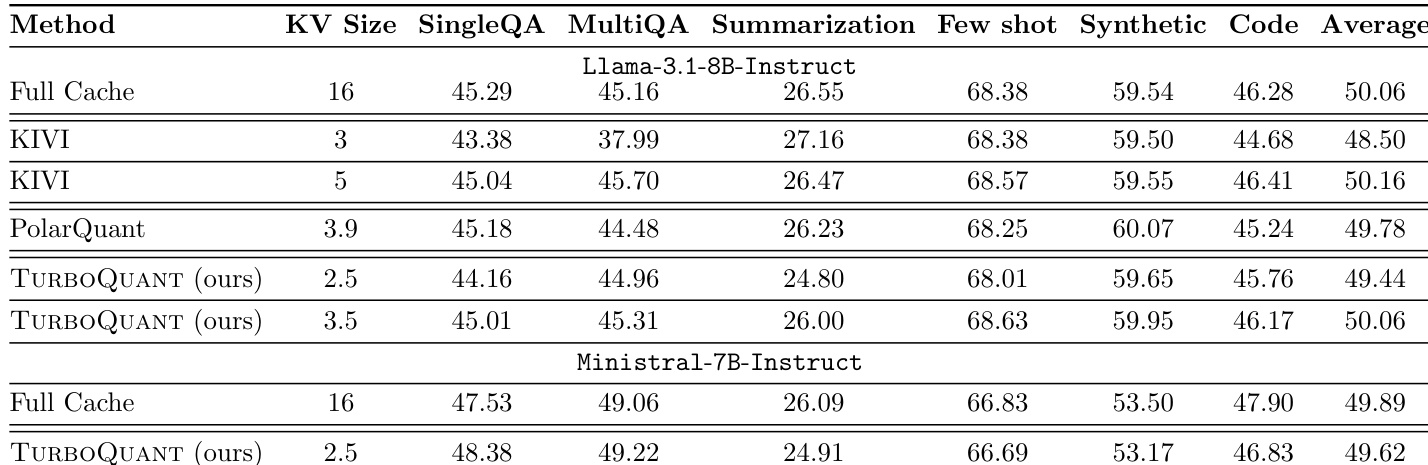
作者使用 Llama-3.1-8B-Instruct 和 Ministral-7B-Instruct 模型在 LongBench 数据集上评估 KV 缓存压缩方法。结果表明,TURBOQUANT 实现了与全精度基线相当的性能,同时利用显著更低的位精度。TURBOQUANT 在 Llama 模型上实现了与全精度基线相当的平均分数。该方法在减少缓存大小的情况下在 Ministral 模型上保持高性能。TURBOQUANT 在各种任务中表现出与 KIVI 和 PolarQuant 等基线有竞争力的结果。
该表比较了三种不同方法在不同向量维度下的量化时间。TURBOQUANT 始终表现出比乘积量化和 RabitQ 显著更快的处理速度。随着数据维度的增长,TURBOQUANT 的效率优势变得越来越明显。TURBOQUANT 在所有测试维度下保持最低的时间成本。RabitQ 产生最高的计算开销,尤其是在较大维度下。乘积量化比 RabitQ 快,但显著落后于 TURBOQUANT。

该评估使用 Llama-3.1-8B-Instruct 和 Ministral-7B-Instruct 模型在 LongBench 数据集上评估 TURBOQUANT,以验证 KV 缓存压缩的有效性。结果表明,该方法实现了与全精度基线相当的性能,并在利用显著更低位精度的情况下保持与 KIVI 和 PolarQuant 等方法有竞争力。此外,量化时间比较显示,TURBOQUANT 在不同向量维度下始终比乘积量化和 RabitQ 处理数据更快,其效率优势随着维度增长而变得更加明显。