Command Palette
Search for a command to run...
GlobalSplat: 通过 Global Scene Tokens 实现高效的 Feed-Forward 3D Gaussian Splatting
GlobalSplat: 通过 Global Scene Tokens 实现高效的 Feed-Forward 3D Gaussian Splatting
Roni Itkin Noam Issachar Yehonatan Keypur Yehonatan Keypur Anpei Chen Sagie Benaim
摘要
基元(primitives)的高效空间分配是 3D Gaussian Splatting 的基石,因为它直接决定了表示紧凑性(representation compactness)、重建速度与渲染保真度(rendering fidelity)之间的协同效应。以往的解决方案,无论是基于迭代优化还是前馈 inference,在实现这些目标时都面临显著的权衡问题,这主要是由于其依赖于缺乏全局场景感知能力的局部、启发式分配策略所致。具体而言,目前的 feed-forward 方法在很大程度上是像素对齐(pixel-aligned)或体素对齐(voxel-aligned)的。通过将像素反投影为密集的、视图对齐的基元,这些方法将冗余信息固化到了 3D 资产中。随着输入视图数量的增加,表示规模随之增大,且全局一致性变得脆弱。为此,我们提出了 GlobalSplat,这是一个基于“先对齐,后解码(align first, decode later)”原则构建的框架。我们的方法学习一种紧凑的、全局的潜在场景表示(latent scene representation),在解码任何显式 3D 几何结构之前,该表示即可对多视图输入进行编码并解决跨视图对应关系。至关重要的是,这种公式化设计能够在不依赖预训练的像素预测骨干网络(backbones)或复用密集基线模型(dense baselines)潜在特征的情况下,实现紧凑且全局一致的重建。通过采用逐渐增加解码能力的从粗到精(coarse-to-fine)训练课程,GlobalSplat 从本质上防止了表示膨胀(representation bloat)。在 RealEstate10K 和 ACID 数据集上,我们的模型仅使用 16K 个 Gaussians 就实现了极具竞争力的新视角合成性能,远低于密集 pipeline 所需的数量,且模型占用空间仅为 4MB。此外,GlobalSplat 的 inference 速度显著快于基线模型,在单次前馈 pass 中的运行时间低于 78 毫秒。项目主页位于:https://r-itk.github.io/globalsplat/
一句话总结
GlobalSplat 是一个前馈框架,它利用全局场景 tokens 在解码显式几何之前学习紧凑的潜表示,在 RealEstate10K 和 ACID 数据集上实现了高保真 3D Gaussian Splatting 重建,仅需 16K Gaussians,占用 4MB 空间,且推理速度低于 78 毫秒。
核心贡献
- 本文介绍了 GlobalSplat,这是一个基于“先对齐,后解码”原则的前馈 3D Gaussian Splatting 框架,它将多视图观测聚合为一组紧凑且固定大小的全局场景 tokens。该方法在解码显式 3D 几何之前,先在全局潜表示中解决跨视图对应关系,从而消除了密集、以视图为中心的流水线中所存在的冗余。
- 该方法实现了一种解耦的双分支架构,并结合了由粗到精的训练课程,逐步增加解码容量。这种设计防止了表示膨胀,并在重建大上下文场景时实现了更强的质量与效率权衡。
- 在 RealEstate10K 和 ACID 数据集上的实验表明,该模型仅使用 16K Gaussians 和 4MB 的占用空间即可实现具有竞争力的新视角合成性能。该框架还提供了极高的效率,在单次前馈传递中推理时间不足 78 毫秒。
引言
前馈 3D Gaussian Splatting (3DGS) 旨在通过单次网络传递,从多个输入视图生成显式的 3D 表示,从而实现无需逐场景优化的快速新视角合成。然而,现有方法通常依赖于密集的、与视图对齐的中间表示,例如像素对齐或体素对齐的预测。这种设计引入了显著的冗余,并导致表示规模随着输入视图的增加而膨胀,使得大上下文重建难以扩展。作者利用“先对齐,后解码”的原则引入了 GlobalSplat,该框架在解码任何显式几何之前,将多视图输入聚合为一组紧凑、固定的全局潜场景 tokens。通过利用双分支迭代注意力架构和由粗到精的训练课程,GlobalSplat 在保持仅 16K Gaussians 的超紧凑占用的同时,实现了极具竞争力的重建质量。
数据集

由于提供的文本仅包含关于图像缩放和裁剪的实现细节,而非数据集的组成、来源或混合比例,因此以下描述侧重于数据处理流水线:
- 图像预处理: 在评估期间,作者在保持原始宽高比的同时,将每张图像的高度缩放为 256 像素。宽度被舍入到最接近的 8 的倍数,以适应 patch 大小。
- 相机参数调整: 为了保持空间精度,在缩放步骤之后会相应地更新相机内参。
- 裁剪与最终缩放: 流水线对缩放后的图像进行中心正方形裁剪。如果尺寸仍不正确,则进行最终缩放以生成精确的 256 by 256 像素图像。
- 一致性: 这种确定性的预处理工作流被一致地应用于上下文视图和目标视图。
方法
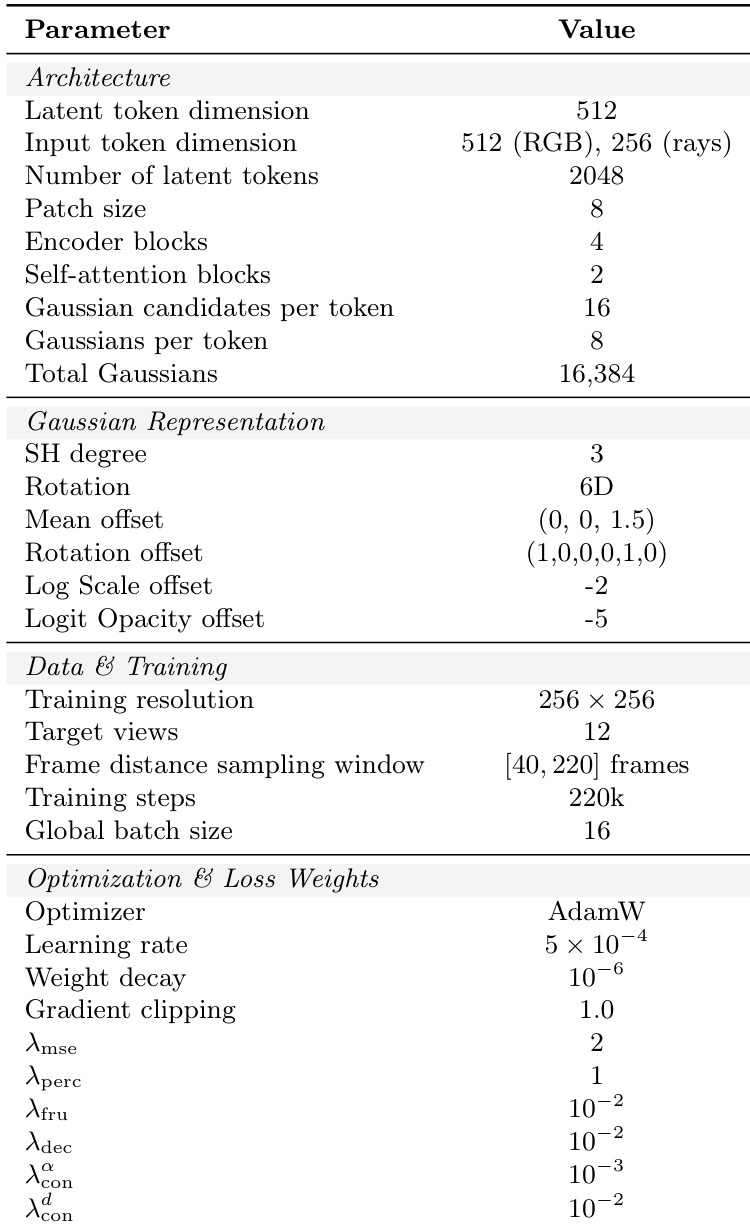
作者利用了一种名为 GlobalSplat 的新颖架构,它采用可学习的潜表示来高效建模 3D 场景。整个框架的运行方式是:首先从输入视图中提取特征,然后通过双分支注意力机制迭代细化一组固定的潜场景 tokens,最后将其解码为显式的 3D Gaussians。模型始于一个视图编码器,用于处理输入图像以生成 patch 化特征。随后,这些特征通过将 patch 化的 Plücker-ray 嵌入与逐视图相机代码相结合,来增强每个 patch 的上下文,该相机代码显式编码了相机的全局上下文,包括绝对位置和焦距参数。增强后的上下文被送入核心处理流水线。
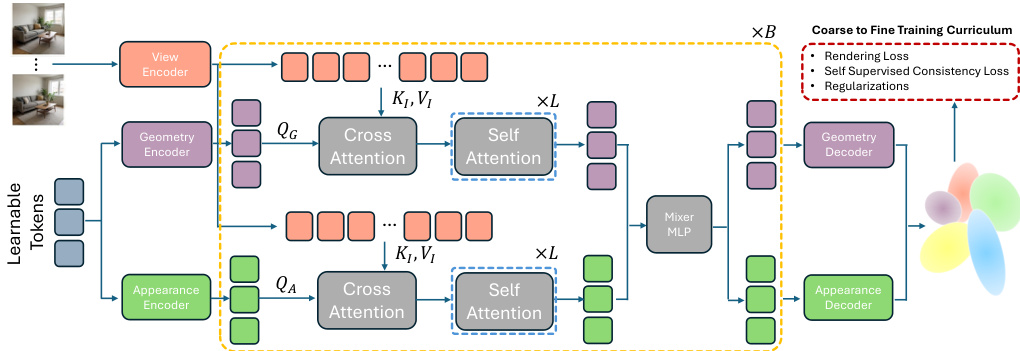
如下图所示,模型初始化了一组固定的 M=2048 个可学习的潜 tokens,作为场景的主要表示。这些 tokens 通过由 B=4 个迭代块组成的双分支编码器进行处理。在每个块内,tokens 被投影到独立的几何和外观流中。几何流处理查询 QG,它们对多视图特征 KI,VI 进行交叉注意力处理,然后对全局上下文进行自注意力处理;而外观流则使用查询 QA 执行类似操作。这种架构上的解耦确保了几何结构和外观被独立处理,防止纹理掩盖较差的结构预测。两个流的输出通过一个 mixer MLP 进行融合以更新潜 tokens,然后传递到下一个块。
在迭代细化之后,最终的潜 tokens 被解码为显式的 3D Gaussian 表示。这是通过两个专门的解码器实现的:几何解码器预测 3D 均值、各向异性缩放、旋转(使用连续 6D 参数化)、不透明度和重要性评分;外观解码器使用 3 阶球谐函数 (SH) 预测与视图相关的颜色系数。模型采用由粗到精的训练课程来管理表示的复杂度。最初,每个潜 token 预测一组固定的 16 个 Gaussian 候选者,但只有单个代表性 Gaussian (G=1) 会暴露给渲染器。随着训练的进行,通过减少候选者的合并来逐步增加容量,最终每个 token 展示 G=8 个 Gaussians。这种分阶段的方法确保了模型在细化局部细节之前首先建立稳定的全局几何,从而防止表示膨胀并提高训练稳定性。
实验
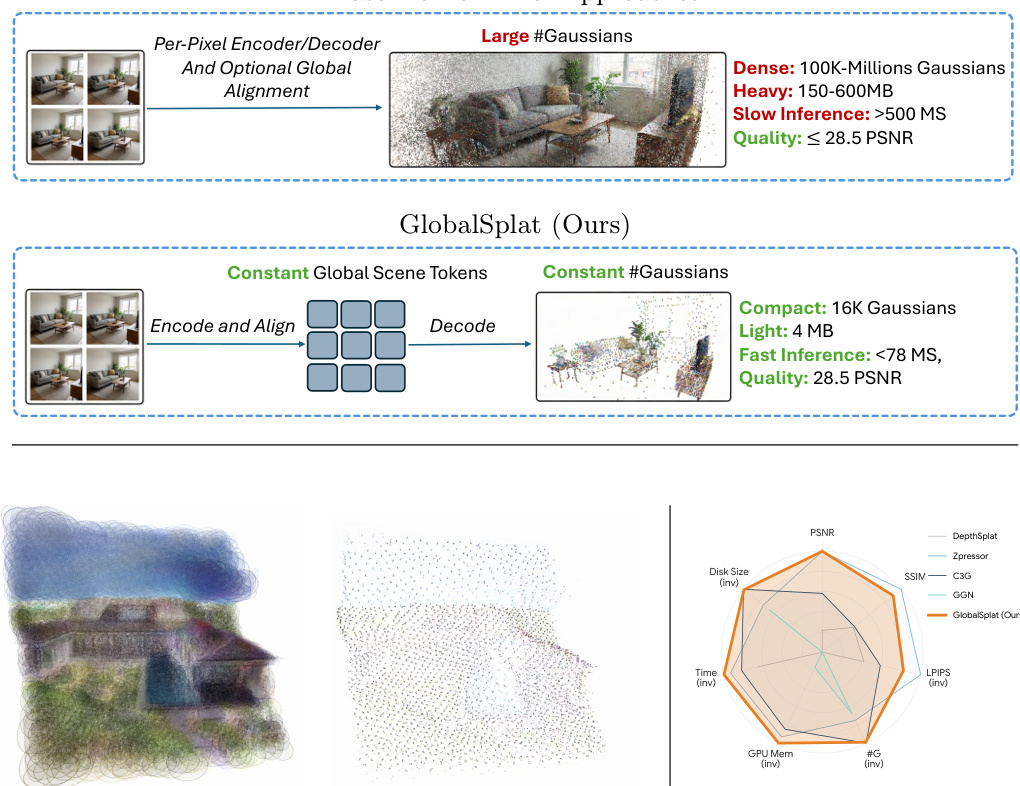
所提出的方法在 RealEstate10K 数据集上与最先进的前馈新视角合成基准进行了主要性能测试,并使用 ACID 数据集评估零样本跨数据集泛化能力。消融研究进一步验证了双流架构、由粗到精的容量课程以及相机元数据的有效性。结果表明,该模型在重建质量和表示紧凑性之间实现了卓越的权衡,提供了清晰、无伪影的渲染效果,且与现有的重量级方法相比,内存和计算需求显著降低。
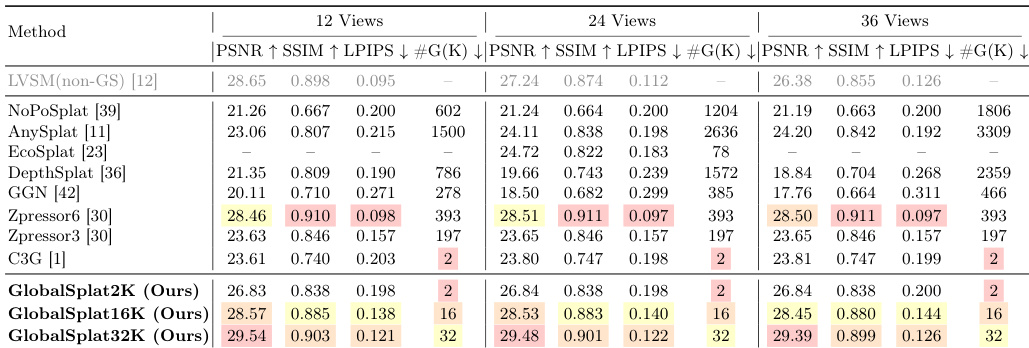
作者在 RealEstate10K 和 ACID 数据集上将其方法与最先进的前馈新视角合成基准进行了对比。结果显示,所提出的方法以紧凑的表示实现了强大的重建质量,展示了质量与模型大小之间良好的权衡,并在跨数据集泛化和计算效率方面表现出色。与基准方法相比,该方法在显著减少 Gaussians 数量的同时实现了具有竞争力的重建质量。该方法展示了鲁棒的跨数据集泛化能力,尽管仅在 RealEstate10K 上训练,但在 ACID 上仍能保持性能。该方法具有很高的计算效率,在对比方法中需要最低的峰值 GPU 内存和最快的推理时间。
作者在 RealEstate10K 上将其方法与最先进的前馈新视角合成基准进行了比较,评估了重建质量、紧凑性和效率。结果表明,与其他方法相比,该方法在 Gaussians 数量显著减少的情况下实现了具有竞争力的图像质量,展示了良好的质量与紧凑性权衡。该方法在不同数量的输入视图下均保持了强劲的性能,并表现出极高的计算效率。GlobalSplat 在使用其他方法所需 Gaussians 极小部分的情况下,实现了具有竞争力的重建质量。该方法在 12、24 和 36 个输入视图下保持了性能的一致性,表明其具有视图不变性的表示。在推理时间和磁盘占用方面,GlobalSplat 是内存效率最高且速度最快的方法。
作者将其方法的效率与几个基准进行了比较,重点关注峰值 GPU 内存、推理时间和磁盘大小。结果显示,该方法在保持较小磁盘占用的同时,实现了显著降低的内存使用量和更快的推理速度。这些效率提升是在不牺牲重建质量的情况下实现的,突显了紧凑表示的优势。与基准相比,所提出的方法使用的峰值 GPU 内存和推理时间大幅减少。该方法保持了极小的磁盘占用,显著小于所有其他方法。在保持高重建质量的同时实现了效率提升。

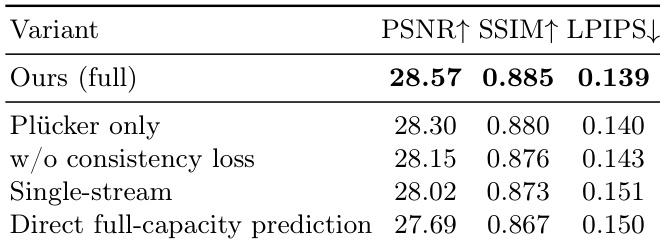
作者进行了消融研究,以评估不同设计选择对模型性能的影响。结果表明,移除一致性损失或使用单流架构会导致重建质量下降,而从一开始就预测完整的 Gaussian 容量也会降低性能。完整模型在所有指标上均取得了最佳结果。移除一致性损失会降低重建质量并增加伪影;使用单流架构代替双流设计会降低性能;从训练开始就预测完整的 Gaussian 容量会导致比渐进式容量增长更差的结果。
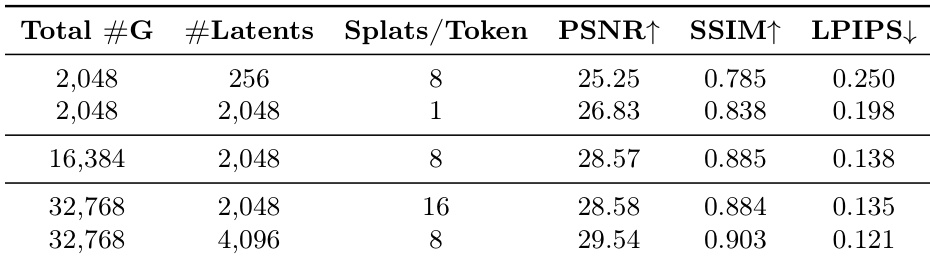
该表研究了在固定 Gaussian 预算下,潜场景表示大小和解码器密度对重建质量的影响。结果表明,增加潜 tokens 的数量比增加每个 token 的 Gaussians 数量更有效,更大的潜容量在各项指标上都能带来更好的性能。增加潜容量对重建质量的提升比增加每个 token 的 Gaussians 更多;在相同的 Gaussian 预算下,更大的潜表示实现了更高的 PSNR、SSIM 和更低的 LPIPS;潜大小与解码器密度之间的权衡显示,更高的解码器密度收益递减。
所提出的方法在 RealEstate10K 和 ACID 数据集上与最先进的前馈新视角合成基准进行了评估,以衡量重建质量、效率和泛化能力。结果表明,该方法以显著更紧凑的表示实现了具有竞争力的图像质量,提供了卓越的计算效率,并在不同数据集和输入视图数量下表现出鲁棒的性能。消融研究和架构分析进一步证实,双流设计、一致性损失和渐进式容量增长对于在优化潜表示大小与解码器密度权衡的同时保持高质量重建至关重要。