Command Palette
Search for a command to run...
BERT-as-a-Judge:一种用于高效基于 Reference 的 LLM 评估、替代词法方法的鲁棒方案
BERT-as-a-Judge:一种用于高效基于 Reference 的 LLM 评估、替代词法方法的鲁棒方案
Hippolyte Gisserot-Boukhlef Nicolas Boizard Emmanuel Malherbe Céline Hudelot Pierre Colombo
摘要
准确的评估是 Large Language Model (LLM) 生态系统的核心,它引导着模型选择以及在不同下游场景中的应用。然而在实践中,评估生成式输出通常依赖于僵化的词法方法(lexical methods)来提取和评估答案,这可能会将模型的真实问题解决能力与模型对预定义格式规范的遵循程度混为一谈。虽然近期出现的 LLM-as-a-Judge 方法通过评估语义正确性而非严格的结构一致性缓解了这一问题,但这些方法也引入了巨大的计算开销,导致评估成本高昂。在本研究中,我们首先通过一项涵盖 36 个模型和 15 个下游任务的大规模实证研究,系统地调查了词法评估的局限性,证明了此类方法与人类判断的相关性较差。为了解决这一局限性,我们提出了 BERT-as-a-Judge,这是一种基于 Encoder 的方法,用于在基于参考答案(reference-based)的生成式场景中评估答案的正确性。该方法对输出措辞的变化具有鲁棒性,且仅需在合成标注的“问题-候选答案-参考答案”三元组上进行轻量化 training 即可。我们证明,BERT-as-a-Judge 的表现始终优于词法基准(lexical baseline),同时能够达到规模大得多的 LLM judges 的性能水平,从而在两者之间提供了极具吸引力的权衡方案,并实现了可靠且可扩展的评估。最后,通过广泛的实验,我们对 BERT-as-a-Judge 的性能进行了深入的分析,为从业者提供了实践指导,并发布了所有项目成果以促进其在下游场景中的应用。
一句话总结
为了解决僵化的词法方法与人类相关性差,以及 LLM-as-a-Judge 方法计算成本高的问题,作者提出了 BERT-as-a-Judge。这是一个由 encoder 驱动的框架,通过在合成的“问题-候选答案-参考答案”三元组上进行轻量化训练,为生成式模型提供可靠、可扩展且语义准确的基于参考答案的评估。
核心贡献
- 本研究进行了一项涉及 36 个模型和 15 个下游任务的大规模实证研究,展示了词法评估方法如何通过将问题解决能力与格式合规性混淆,从而导致与人类判断的相关性较差。
- 本文引入了 BERT-as-a-Judge,这是一个由 encoder 驱动的框架,通过在合成标注的问题-候选答案-参考答案三元组上进行轻量化训练,在基于参考答案的生成场景中评估答案的正确性。
- 实验结果表明,所提出的方法始终优于词法基准,并能达到规模大得多的 LLM judge 的性能,同时提供更高效且可扩展的计算权衡。
引言
准确的评估对于在各种任务中选择和部署大语言模型 (LLMs) 至关重要。目前的 zero-shot 评估方法通常依赖词法匹配或基于 regex 的解析来将模型输出与参考答案进行比较。然而,这些方法经常将模型的核心推理能力与其遵循严格格式约束的能力混淆,从而导致性能被低估。虽然 LLM-as-a-Judge 框架提供了一种更具语义性的替代方案,但它们引入了显著的计算开销以及对 prompt 设计的敏感性。作者引入了 BERT-as-a-Judge,这是一种利用双向注意力机制来评估语义正确性的 encoder 驱动方法。这个轻量化框架提供了一种更高效、更可靠的替代方案,能够与人类判断紧密对齐,且没有生成式 judge 那样高昂的推理成本。
数据集
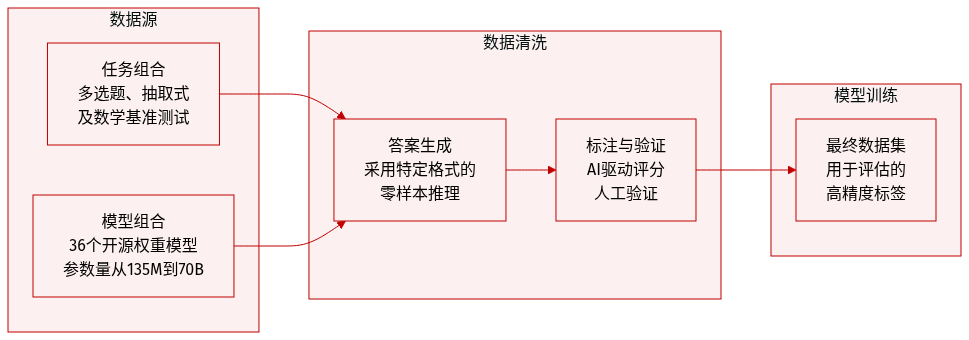
-
数据集组成与来源:作者构建了一个由三个不同的任务族组成、旨在进行客观评估的评估数据集:
- 多选题 (Multiple-choice):包括 MMLU, MMLU-Pro, TruthfulQA, ARC-Easy/Challenge 和 GPQA。
- 上下文提取 (Context extraction):包括 SQuAD-v2, HotpotQA, DROP 和 CoQA。
- 开放形式数学 (Open-form mathematics):包括 GSM8K, MATH, AsDiv, AIME 24 和 AIME 25。
-
数据处理与生成:
- 作者对 36 个不同的开源指令微调模型进行了 zero-shot 推理,参数规模从 135M 到 70B 不等。
- 使用 greedy decoding 生成回答,最大长度为 2048 tokens。
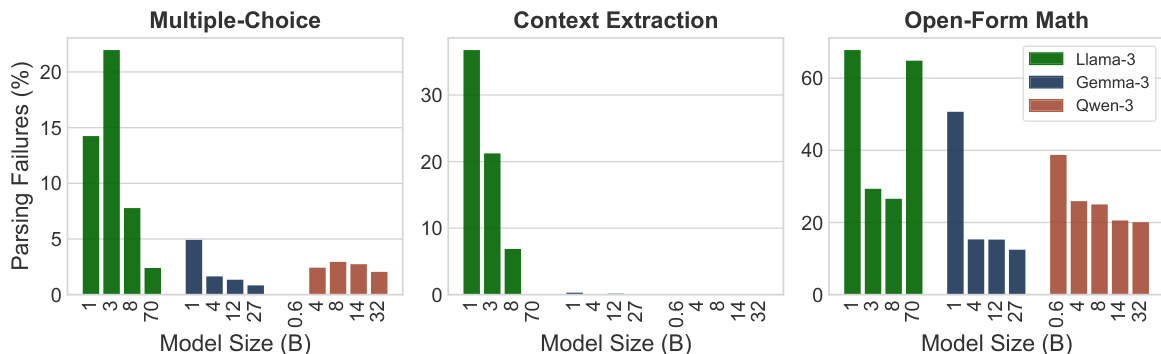
- 为了能够通过正则表达式进行一致的解析,模型被提示使用特定的 "Final answer: [answer]" 格式来结束其输出。
-
标注与验证策略:
- 合成标注:作者使用 Nemotron-Super-v1.5 作为自动化评估器。该模型接收问题、候选回答和参考答案,通过在非推理模式下的 greedy decoding 来确定正确性。
- 人工验证:为了确保合成标签的可靠性,数据集的一个子集由 11 名人类评估员进行了独立标注。这产生了 3,212 条标注,与合成标签相比,平均一致率达到 97.5%。
方法
作者利用了一个类似于 BERT 的 encoder 模型,称为 BERT-as-a-Judge,通过将任务视为结构化文本分类问题来评估模型生成的答案。该模型在由多个基准数据集构建的已标注“问题-候选答案-参考答案”三元组上进行训练,这些数据集包括 MMLU, ARC-Easy, ARC-Challenge, SQuAD-v2, HotpotQA, GSM8K 和 Math。选择这些数据集是因为它们具有明确的训练划分,并且训练混合比例经过精心平衡,以确保在不同任务类别和模型之间拥有约一百万个合成标注样本。encoder 初始化自 EuroBERT 210M,并使用 binary cross-entropy loss 进行单 epoch 的微调。训练采用 2×10−5 的学习率,具有 5% 的 warmup 比例和线性衰减调度,在 8 个 MI250x GPU 上进行,实现了 32 的有效 batch size,每次运行大约需要 20 个 GPU 小时。
该评估框架集成了两个不同的模块:一个基于 regex 的评估系统和一个 BERT-as-a-Judge 模型。在基于 regex 的方法中,模型输出通过一个解析步骤进行处理,该步骤使用正则表达式模式 "Final answer:\s*(.)" 来提取答案,从而实现灵活且通用的答案提取。这种方法依赖于提取的答案与参考答案之间的词法匹配,从而产生二元评分。相比之下,BERT-as-a-Judge 框架使用微调后的 encoder,直接根据参考答案评估生成的回答。模型将问题、候选答案和参考答案作为结构化输入进行处理,利用其双向注意力机制产生置信度评分。这种方法通过捕捉答案与参考答案之间的语义对齐,实现了更细致的评估。如下表所示,两种评估路径都收敛为一个真实的排序机制,用于比较不同模型在各项任务中的表现。
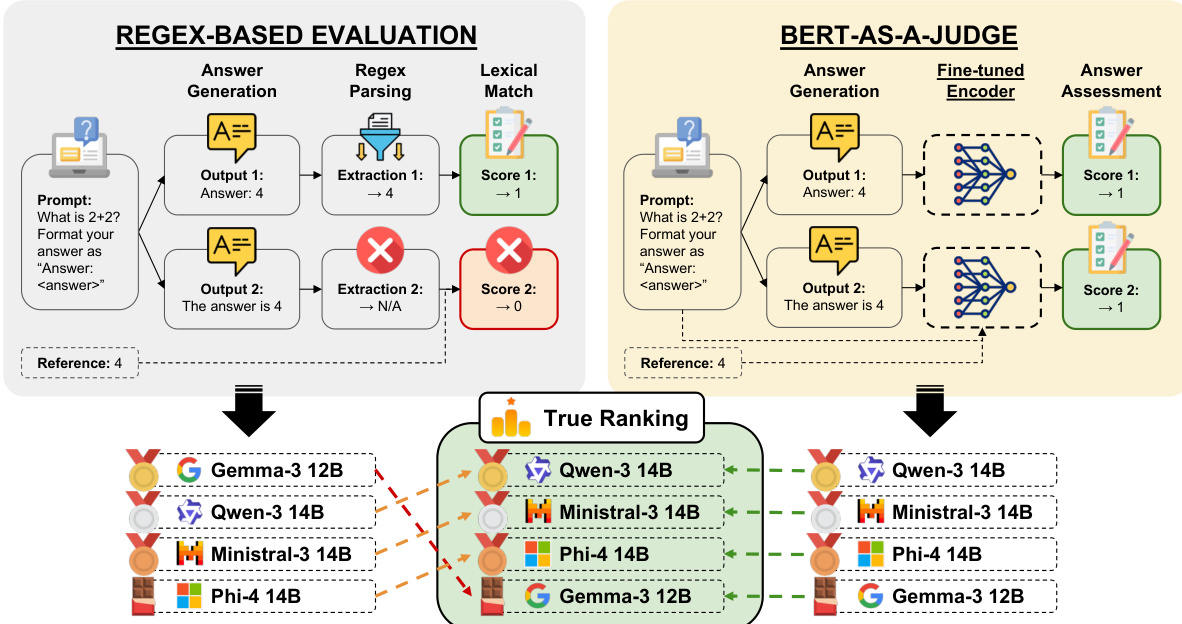
整体架构旨在支持对模型输出的直接和间接评估,其中 BERT-as-a-Judge 模型为答案评估提供了一种可扩展且自动化的解决方案,且不依赖于人工标注。
实验
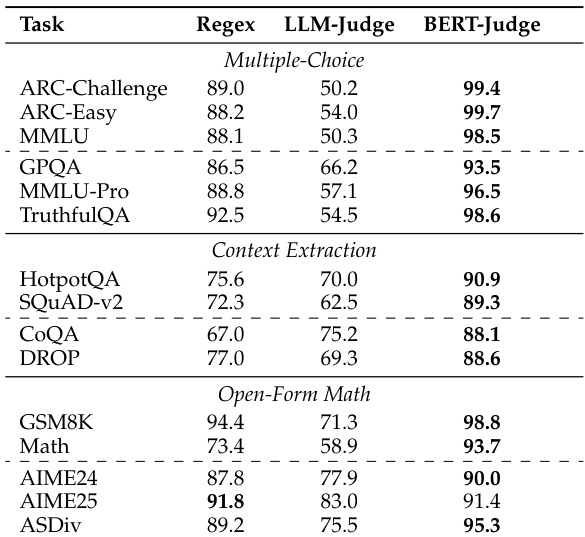
研究人员针对多个任务类别,将包括基于 regex 的解析、LLM-as-a-Judge 以及所提出的 BERT-as-a-Judge encoder 在内的几种评估方法,与合成的 ground-truth 标签进行了对比。结果表明,由于僵化的词法匹配和格式失败,基于 regex 的评估会显著扭曲模型排名并低估性能。相比之下,BERT-as-a-Judge encoder 提供了更高的准确性、对领域外模型强大的泛化能力以及对不同答案格式的高鲁棒性,同时保持了计算效率。
作者在多个任务类别中将基于 regex 的评估与 BERT-as-a-Judge 进行了对比。结果显示,BERT-as-a-Judge 实现了比 regex 更高的准确率,当从输入中排除问题时,性能差异极小。该方法在不同类型的任务中表现出一致的有效性。BERT-as-a-Judge 在所有任务类别中均优于基于 regex 的评估。从输入中排除问题对 BERT-as-a-Judge 的性能影响极小。BERT-as-a-Judge 在多选题、上下文提取和开放形式数学任务上均保持了高准确率。
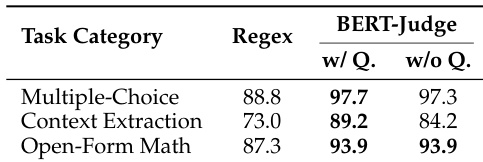
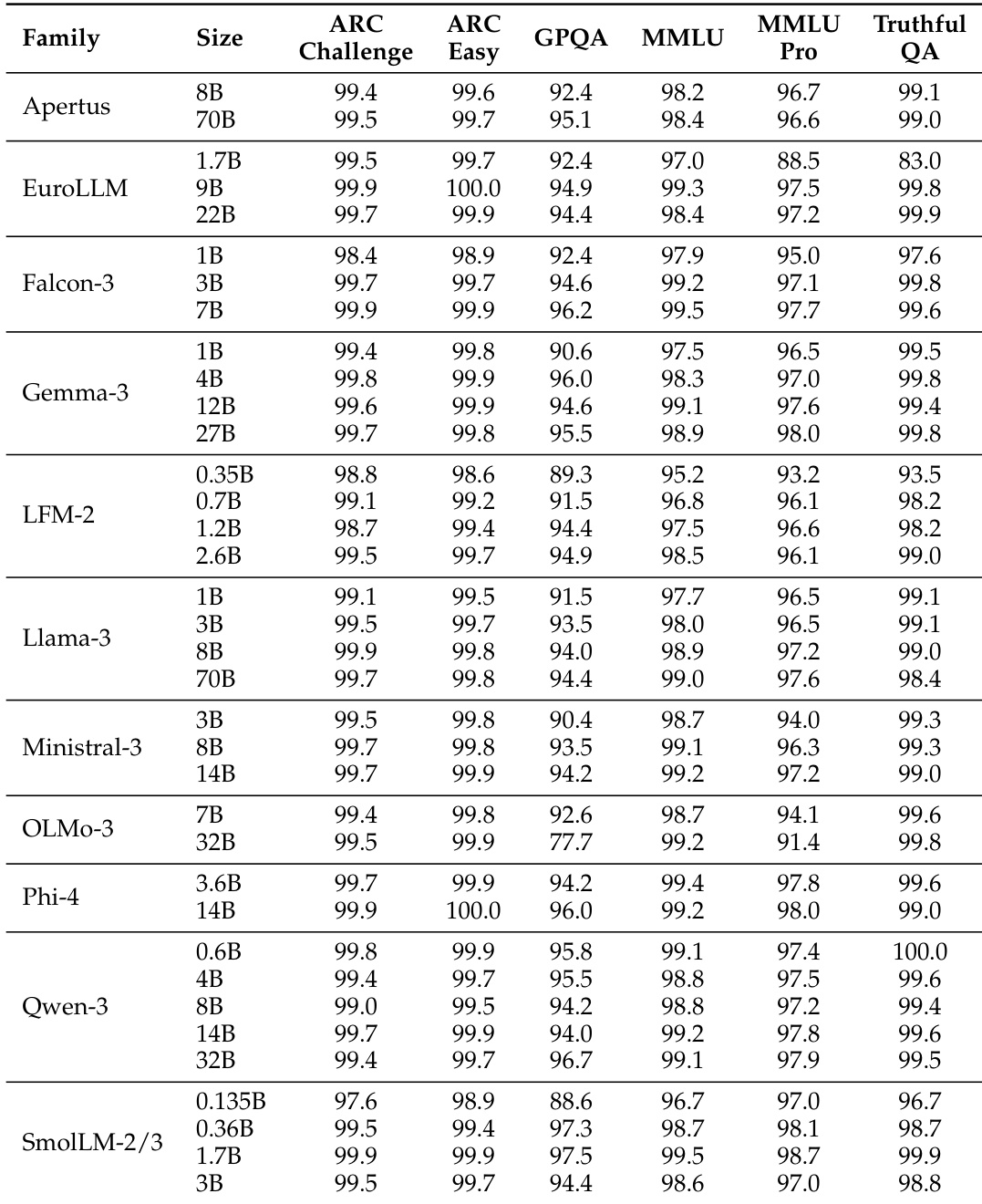
该表展示了各种模型系列在多个基准测试中的准确率得分,显示了模型之间显著的性能差异。BERT-as-a-Judge 在各项任务中均实现了高准确率,优于基于 regex 的方法,并与 ground-truth 标签高度对齐。BERT-as-a-Judge 在所有模型系列和基准测试中始终优于基于 regex 的评估。较大的模型通常获得更高的准确率,但在特定任务中存在例外。性能在不同任务之间差异很大,多选题和开放形式数学的准确率高于上下文提取。
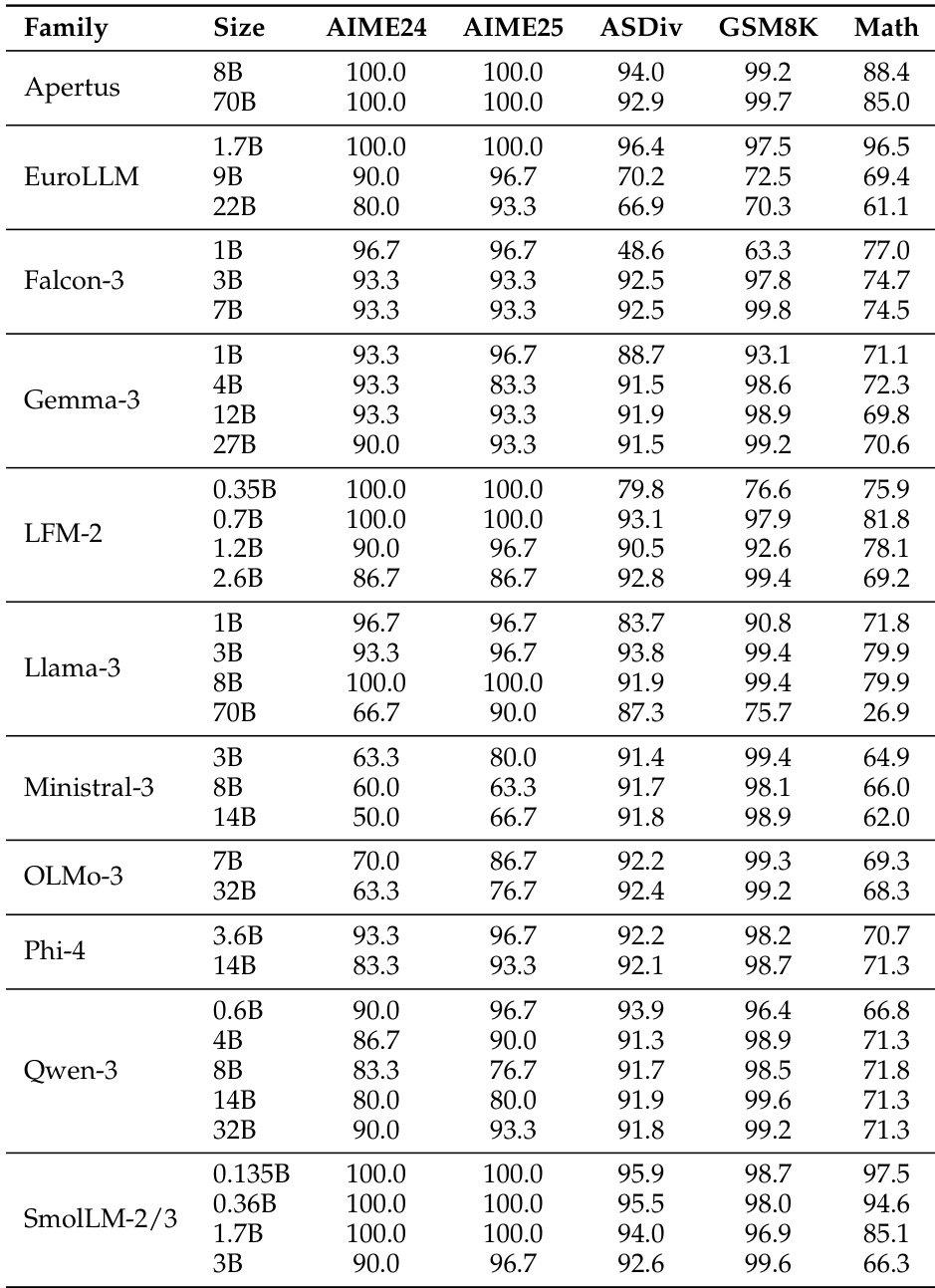
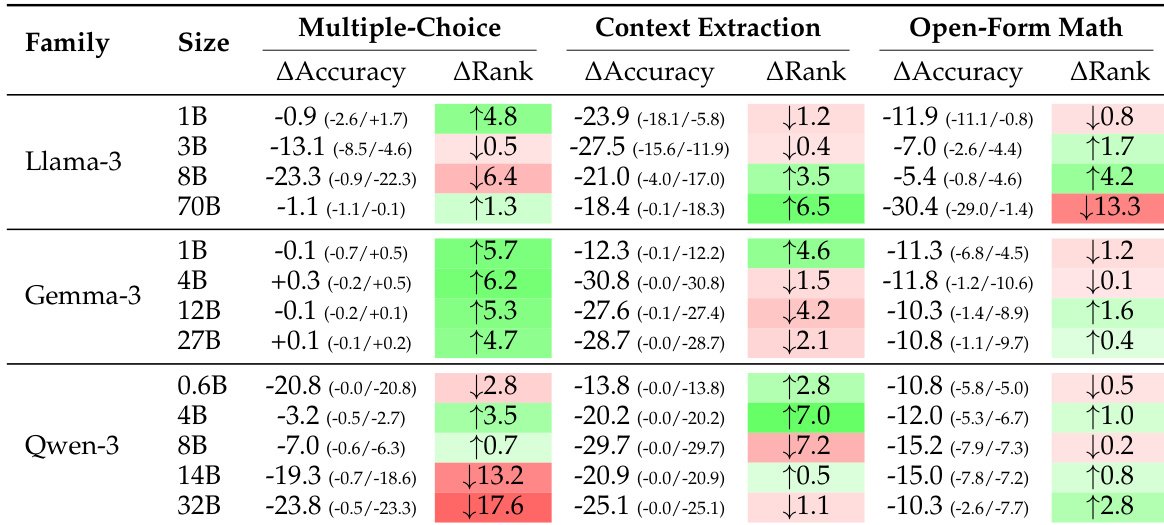
该表展示了各种语言模型系列在多个基准测试中的准确率得分,显示了基于模型规模和系列的性能显著变化。结果表明,较大的模型通常获得更高的准确率,某些系列在任务中表现出一致的性能,而其他系列则表现出更多的波动性。性能在模型系列和规模之间存在显著差异,较大的模型通常优于较小的模型。不同的模型系列在基准测试中表现出不同的性能模式,表明了特定任务的优势。某些模型在特定任务上获得高准确率,而在其他任务上得分较低,突显了任务相关的性能波动。
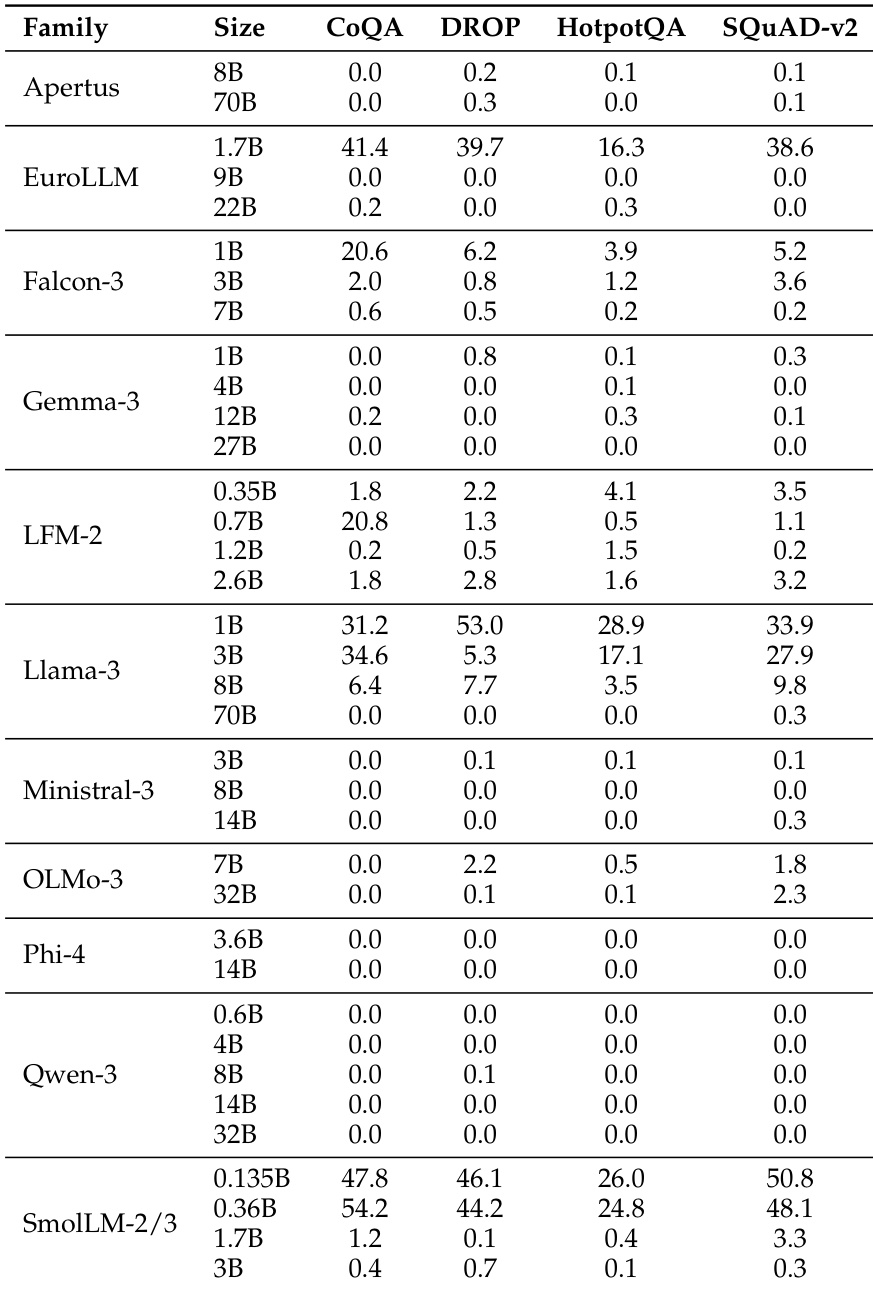
该表展示了各种模型系列和规模在多个基准测试中的模型性能对比。它强调了不同任务之间准确率的差异,某些模型在某些基准测试上获得较高分数,而其他模型在不同的基准测试上表现更好,反映了不同模型架构和规模的各种优势。性能在模型和基准测试之间差异显著,没有单一模型在所有任务中都表现卓越。模型规模影响性能,较大的模型在大多数基准测试上通常显示出更高的准确率。不同的模型系列表现出不同的优势,例如某些模型在 CoQA 或 DROP 等特定任务上表现更好。
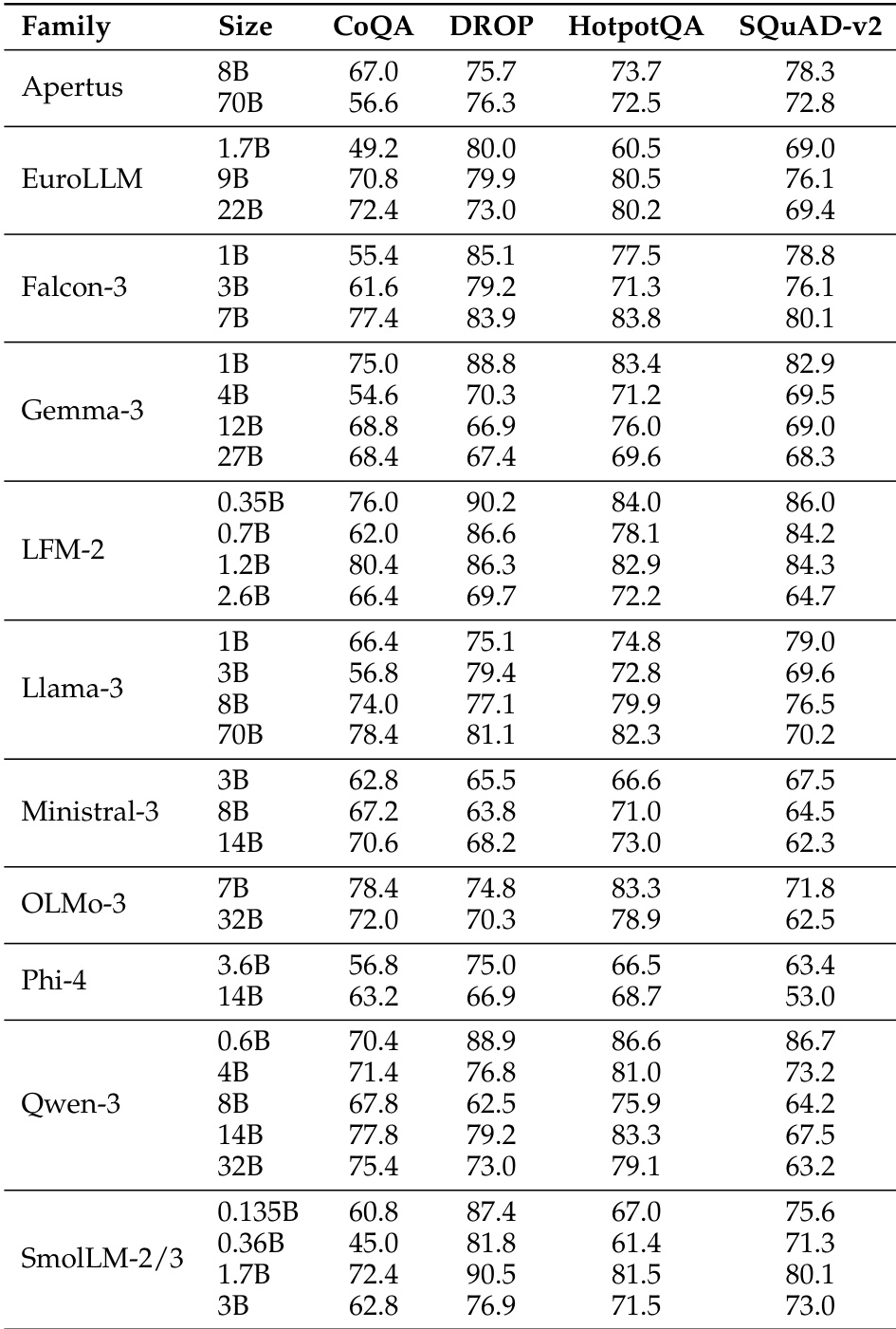
作者将 BERT-as-a-Judge 与基于 regex 和 LLM-as-a-Judge 的方法进行了比较,发现基于 encoder 的方法在各种基准测试中实现了更高的准确率。结果显示,基于 regex 的评估会导致显著的性能扭曲,而 BERT-as-a-Judge 展示了鲁棒性以及与 ground-truth 标签的强对齐。BERT-as-a-Judge 在所有基准测试中均实现了比基于 regex 评估更高的准确率。基于 regex 的评估会导致实质性的性能扭曲和排名错误。BERT-as-a-Judge 对答案格式的变化具有鲁棒性,并能很好地泛化到领域外任务。
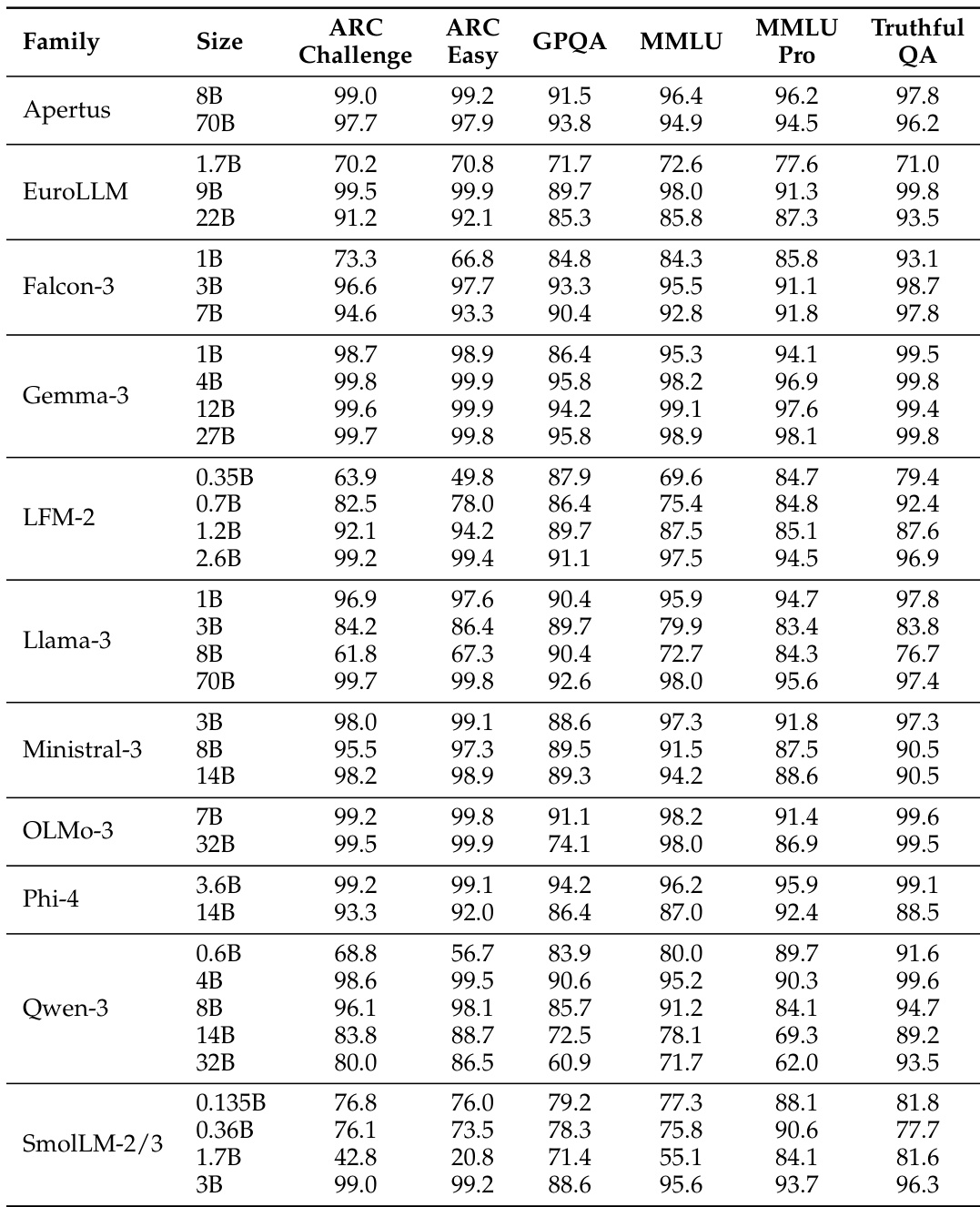
作者通过在各种任务类别和模型系列中将 BERT-as-a-Judge 与基于 regex 和 LLM-as-a-Judge 的方法进行对比,评估了其有效性。结果表明,BERT-as-a-Judge 提供了卓越的准确性和鲁棒性,避免了基于 regex 评估中常见的性能扭曲和排名错误。虽然模型性能会根据架构、规模和特定任务需求而变化,但基于 BERT 的方法在各种基准测试中都能与 ground-truth 标签保持一致的对齐。