Command Palette
Search for a command to run...
GameWorld:迈向多模态 Game Agents 标准化与可验证性的评估研究
GameWorld:迈向多模态 Game Agents 标准化与可验证性的评估研究
Mingyu Ouyang Siyuan Hu Kevin Qinghong Lin Hwee Tou Ng Mike Zheng Shou
摘要
为了实现面向现实世界交互的具身通用智能体(embodied generalist),多模态大语言模型(Multimodal Large Language Model, MLLM)agent 仍面临着挑战性的高延迟、稀疏反馈以及不可逆错误等问题。视频游戏凭借丰富的视觉观测和闭环交互,为这一领域提供了理想的测试平台,同时也对细粒度感知、长程规划(long-horizon planning)和精确控制提出了极高要求。然而,由于动作接口的异构性和启发式验证方法的局限性,目前仍难以对这些能力进行系统性的评估。为此,我们推出了 GameWorld,这是一个旨在为浏览器环境下的 MLLM 通用游戏 agent 提供标准化且可验证评估的 benchmark。本研究探讨了两种游戏 agent 接口:(i) 直接输出键盘和鼠标控制指令的“计算机使用型”agent(computer-use agents);(ii) 通过确定性的语义动作解析(Semantic Action Parsing)在语义动作空间中运行的通用多模态 agent。GameWorld 包含 34 款多样化的游戏和 170 项任务,每项任务都配有基于状态可验证的指标,用于进行基于结果的评估。对 18 种“模型-接口”组合的评估结果表明,即使是表现最优秀的 agent,距离在视频游戏领域达到人类水平仍有巨大差距。针对全量 benchmark 的多次重复实验证明了该 benchmark 的鲁棒性;此外,针对实时交互、上下文记忆敏感度(context-memory sensitivity)以及动作有效性的进一步研究,揭示了游戏 agent 未来面临的更多挑战。总之,通过提供一个标准化、可验证且可复现的评估框架,GameWorld 为推进多模态游戏 agent 及相关领域的研究奠定了坚实的基础。项目主页位于:https://gameworld-bench.github.io。
一句话总结
为了应对评估多模态大语言模型 agent 的挑战,作者引入了 GameWorld,这是一个针对基于浏览器的视频游戏的标准化基准测试。它利用状态可验证的指标,通过在 34 款多样化游戏和 170 个任务中使用语义动作解析,来评估 computer-use agent 和 generalist agent。
核心贡献
- 本文引入了 GameWorld,这是一个旨在对基于浏览器视频游戏环境中的多模态大语言模型 agent 进行标准化和可验证评估的基准测试。
- 这项工作实现了两种不同的 agent 接口:一种是利用直接键盘和鼠标控制的 computer-use agent,另一种是通过确定性语义动作解析(Semantic Action Parsing)运行的 generalist 多模态 agent。
- 在 34 款多样化游戏和 170 个任务中进行的广泛实验表明,目前表现顶尖的 agent 仍显著低于人类能力,进一步的分析揭示了在实时交互和上下文记忆敏感性方面的关键挑战。
引言
视频游戏是评估多模态大语言模型(MLLM)agent 的关键测试场,因为它们需要视觉感知、长程规划和精确控制的复杂结合。然而,现有的基准测试往往难以应对异构的动作接口,并且依赖于启发式或基于 VLM 的评分方法,这会引入噪声并导致结果难以验证。作者引入了 GameWorld,这是一个包含 34 款多样化浏览器游戏和 170 个任务的标准化基准测试,旨在进行可验证的评估。通过利用将推理延迟与游戏玩法解耦的浏览器沙盒,并采用通过序列化游戏 API 实现的状态可验证指标,作者提供了一个可复现的框架,用于评估低层级的 computer-use agent 和高层级的语义 generalist agent。
数据集
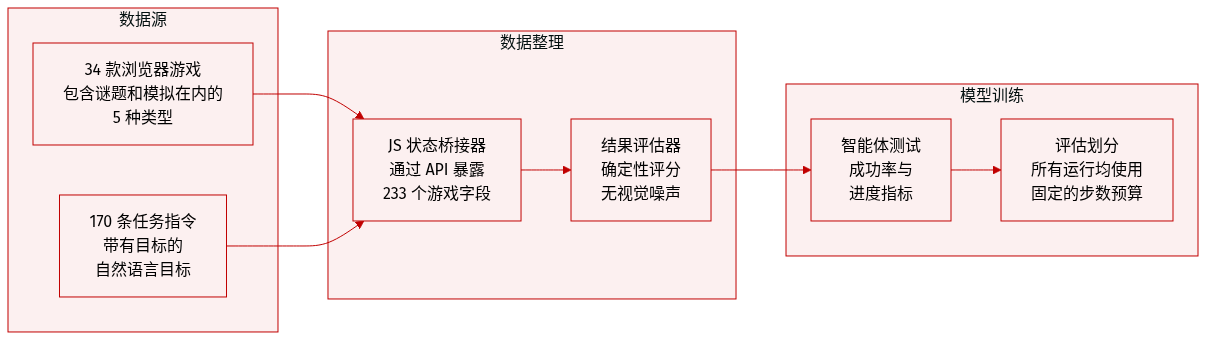
-
数据集构成与来源:作者引入了 GameWorld,这是一个由五种不同类型的 34 款浏览器游戏组成的基准测试:Runner(跑酷)、Arcade(街机)、Platformer(平台跳跃)、Puzzle(解谜)和 Simulation(模拟)。该集合包含了广泛的交互结构,从 2048 和扫雷等游戏中的稀疏棋盘状态推理,到 Pac-Man 和 Temple Run 2 等游戏中的连续实时控制,以及像 Minecraft 克隆版这样的开放式模拟。
-
子集关键细节:数据集包含 170 个任务指令。每个任务都将自然语言指令与定量目标及可验证的评估器配对。游戏按类型分类以测试特定能力:
- Runner 和 Arcade:侧重于高频反应控制和多实体追踪。
- Platformers:需要精确的、具备物理感知能力的空间导航。
- Puzzles:测试逻辑推理和长程规划。
- Simulations:涉及开放式的资源管理和 3D 空间推理。
-
数据处理与元数据构建:为了确保无噪声且可复现的评估,作者实现了一个基于结果的状态可验证系统。他们没有依赖视觉启发式或 VLM-as-judge 流水线,而是在每个游戏中注入了一个结构化的 JavaScript 桥接器,以暴露序列化的 gameAPI 状态。这包括 233 个手动设计的、与任务相关的状态字段(如分数、坐标、生命值和检查点),从而实现对任务成功和进度的确定性测量。
-
评估与使用:该基准测试旨在通过共享的可执行动作空间来评估 Computer-Use Agents 和 Generalist Multimodal Agents。Agent 在固定的步数预算内运行,并使用两个主要指标进行评估:
- 成功率 (SR):一个二元指标,指示 agent 是否达到了任务目标。
- 进度 (PG):一个归一化的测量值 [0,1],代表 agent 朝向目标的推进程度,为未完成的运行提供部分分数。 为了防止早期错误导致整个运行清零,即使发生终止性失败,环境也会保留已达到的最佳进度,允许 agent 在剩余的步数预算内继续运行。
方法
评估游戏 agent 的框架围绕两个主要接口构建:Computer-Use Agents (CUs) 和 Generalist Multimodal Agents,每个接口都旨在原子级人机交互事件的统一控制空间内运行。该架构通过将输出归一化为一组共享的可执行动作(如 mouse_move、key_down 和 scroll),实现了跨不同模型的标准化评估。如下图所示,系统区分了这两个接口:CUs 直接发出低层级的键盘和鼠标控制,而 Generalist Agents 在语义空间中运行,并依赖确定性的 Semantic Action Parsing 将高层意图映射到低层命令。这种共享协议确保了跨模型的一致运行时契约,从而能够对基准测试的鲁棒性和动作有效性进行接口感知的分析。
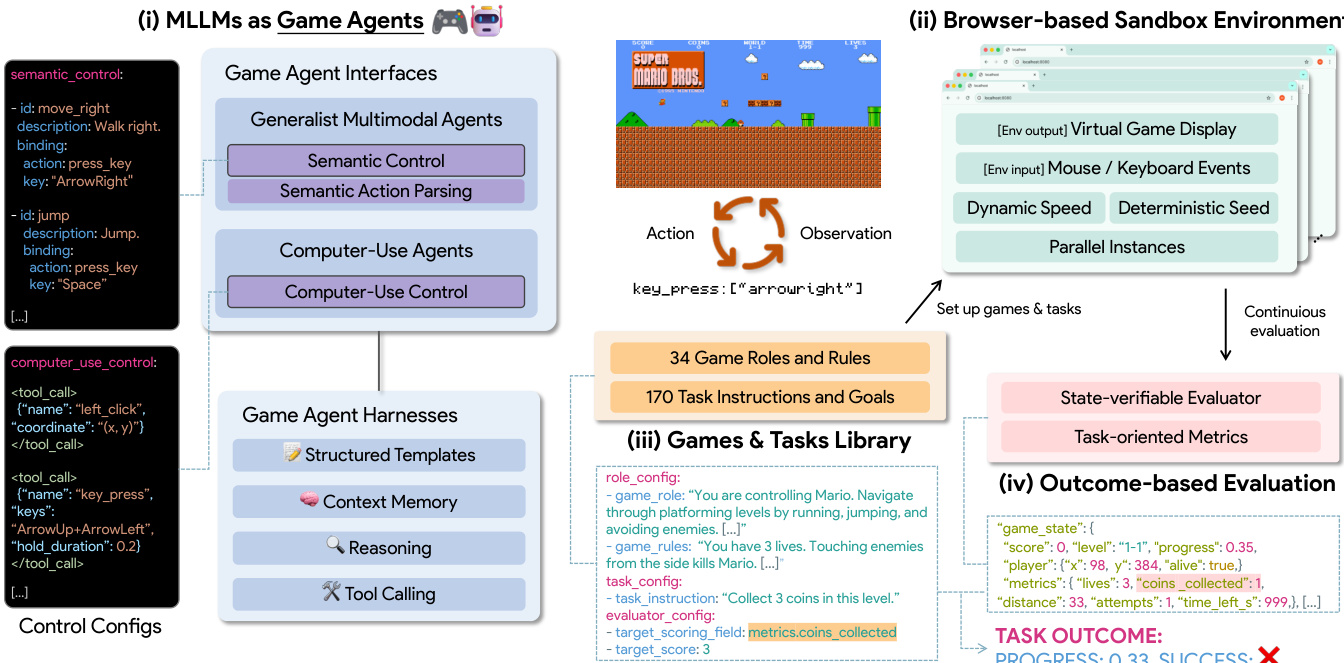
Computer-Use Agents 被限制只能发出源自视觉观察的精确坐标和按键序列,并执行每步一个动作的策略以保持评估的一致性。由于这些 agent 与游戏环境直接交互,它们对推理延迟高度敏感。相比之下,Generalist Agents 虽然具备语义规划能力,但缺乏生成细粒度控制序列的精度。为了弥补这一差距,该框架引入了 Semantic Action Parsing,它在相同的统一运行时契约下将语义动作映射到确定性的低层命令。这一过程消除了解析器端的随机性,并支持可解释的、基于接口条件的比较。两种类型的 agent 都被封装在一个共享的 agent harness 中,该 harness 标准化了结构化提示词、上下文记忆和模型特定工具接口等组件,从而实现了连贯的长程游戏体验。
agent harness 采用包含四个组件的固定提示词模板:#Game Rules、#Role and Controls、#Task Instruction 和 #Output Format。这种结构确保了模型和游戏之间的变动最小化,只有游戏特定的规则、角色描述和任务目标会随配置而变化。上下文记忆以近期交互轮次的滚动历史形式维护,存储 user_prompt、screenshot、reasoning 和 action 的序列。这段历史会被拼接到当前的观察结果之前,为 agent 提供短程轨迹上下文,以避免重复失败的动作并保持一致性。系统还将游戏特定的语义动作和 computer-use 原语注册为可调用工具,利用每个模型提供商的原生 function-calling 接口,在保持统一 harness 级协议的同时保留 agent 能力。
基准测试循环由一个 Runtime Coordinator 协调,它为每个模型管理一个 Agent 对象,包括其 agent ID、模型类型和特定角色的控制。每一轮交互都从捕获当前游戏环境的截图开始,随后进行模型推理,将原始输出解析为可执行的动作负载,并在浏览器中执行。系统随后捕获一个可验证的游戏状态快照,并使用状态可验证评估器评估任务进度。评估器结合了四个停止或重置信号:终止状态、步数预算耗尽、达到目标分数以及任务特定的结束字段规则。如果启用了 continue_on_fail,系统将在发生终止性失败时重置任务并在相同的步数预算下继续,从而促进鲁棒的评估。
执行链在动作到达 Playwright 之前将其归一化为统一的运行时模式。对于低层动作,这包括 click 和 scroll 等鼠标动作、press_key 等键盘动作以及 wait 等计时动作。归一化后的动作随后被转换为 Playwright 原语,以确保与浏览器环境的兼容性。动作的合法性是角色感知的,并由角色定义严格执行,无效的工具调用或不允许的动作将被记录并忽略。对于 Generalist Agents,语义控制负载通过一个构建的注册表语义控制映射进行解析,该映射具有不区分大小写和别名感知查找功能,确保所有动作都进入与 computer-use agents 相同的低层执行链。这种统一的方法支持在一致的评估条件下,对最先进的专有模型和开源模型进行全面评估。
实验
GameWorld 基准测试通过暂停和实时执行两种模式,在 34 款浏览器游戏中评估了 18 个模型-接口对,以将决策质量与推理延迟解耦。通过能力对齐的课程学习和鲁棒性测试,实验表明,虽然目前的 agent 可以取得有意义的部分进度,但在可靠的任务完成、长程规划和精确的计时落地方面仍面临困难。结果表明,agent 的表现仍显著低于人类水平,特别是在推理速度和动作时机紧密耦合的开放式模拟和实时环境中。
实验评估了 Qwen 模型在重复基准测试运行中的稳定性,显示出一致的性能指标。结果表明,多次重复实验中整体进度的方差较低,表明结果可靠且可复现。在重复评估中,性能保持稳定,进度指标的标准差较低。Computer-Use 和 Generalist 接口在重复测试下均显示出一致的结果。该基准测试展示了可复现性,各次运行之间的结果差异极小。

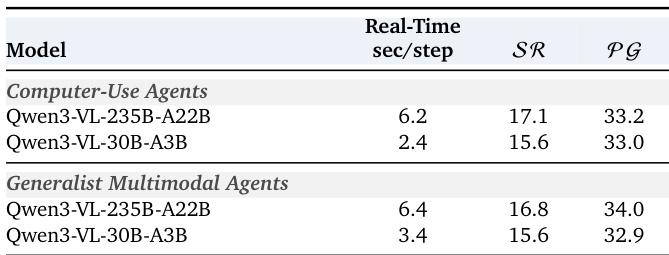
该表比较了两个模型在 computer-use 和 generalist 多模态 agent 接口下的实时性能,展示了它们的响应时间以及任务成功率和进度指标。结果表明,较快的推理时间与两种 agent 类型中较高的成功率和进度呈正相关。在实时评估中,较快的模型实现了更高的成功率和进度率。在两项指标上,Generalist agents 的表现略优于 computer-use agents。模型之间的响应时间差异与其在成功率和进度方面的性能差距是一致的。
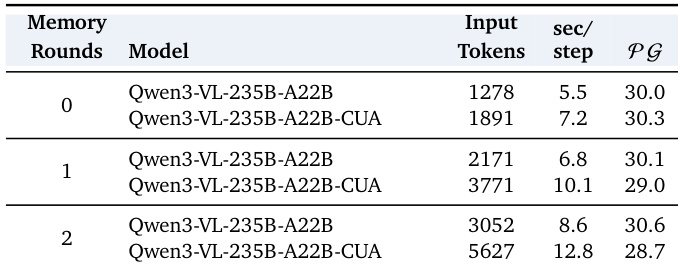
该表展示了增加记忆轮数对两种接口类型的模型性能、输入 tokens 和推理速度的影响。随着记忆轮数的增加,输入 tokens 和每步推理时间均有所增长,而性能在两种接口之间表现出分歧的趋势,其中一种略有提高,另一种则有所下降。增加记忆轮数会导致更高的输入 tokens 和更长的单步推理时间。性能趋势因接口而异,随着记忆增加,一个接口显示出轻微改进,而另一个则出现下降。结果表明,记忆具有选择性的益处,并非对所有接口都同样有效。
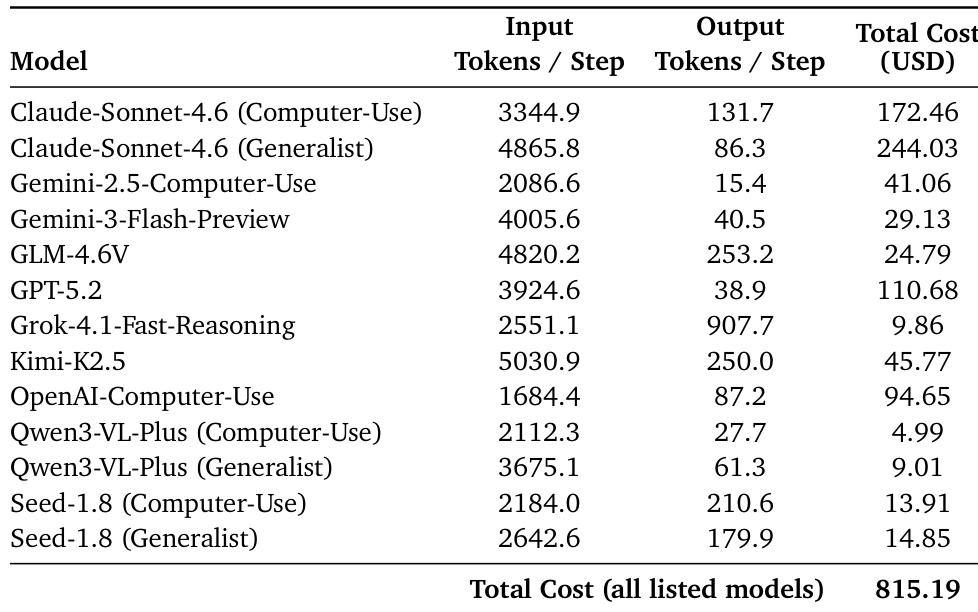
该表将 GameWorld 与现有的交互式基准测试进行了比较,突出了在游戏数量、任务数量、模型数量以及视觉中心性、配置和状态验证等关键特征方面的差异。GameWorld 以大量的游戏和任务、对以视觉为中心和基于配置的任务的支持,以及状态可验证的评估脱颖而出,使其适用于对游戏 agent 进行可扩展且基于结果的评估。与其它基准测试相比,GameWorld 拥有更多的游戏和任务。GameWorld 支持以视觉为中心和基于配置的任务,并具备状态可验证评估。与其它基准测试相比,GameWorld 包含更广泛的模型数量和交互特征。
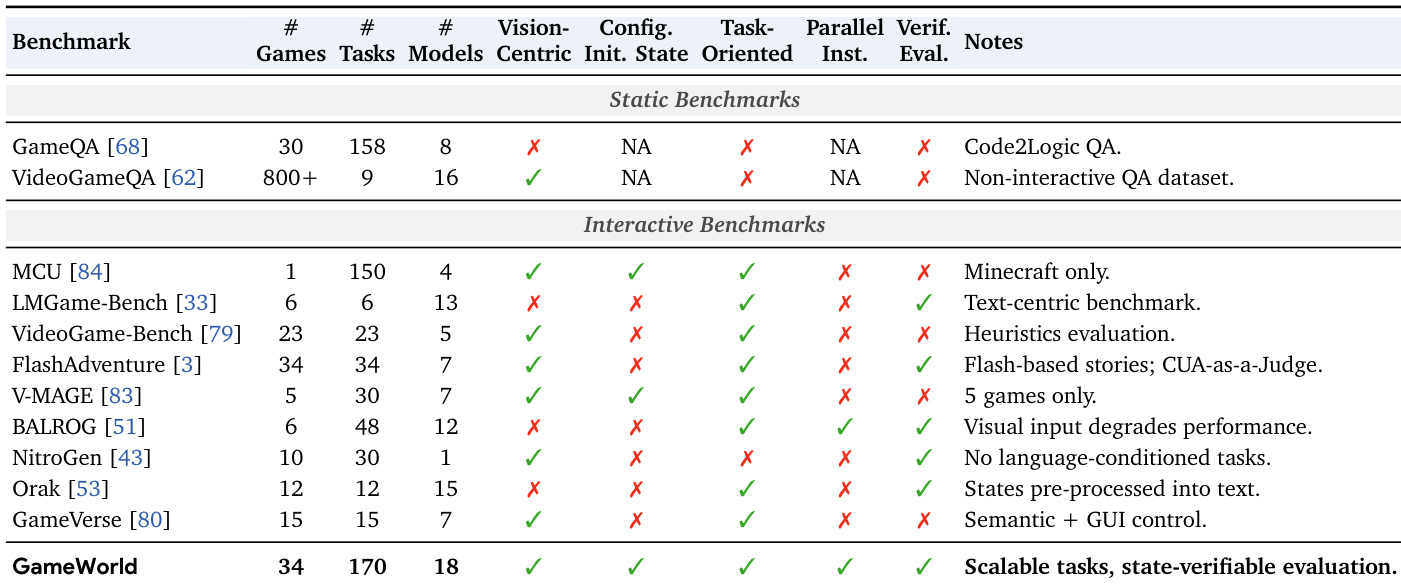
该表展示了在基准测试中评估各种模型的估计成本,包括每步的输入和输出 tokens 以及总成本。不同模型的成本差异显著,一些专有模型比开源替代方案贵得多。成本在不同模型间波动很大,专有模型通常比开源模型更贵。与 computer-use 接口相比,generalist 接口的每步输入 tokens 显著更高。所有列出模型的总评估成本巨大,表明计算资源需求很高。
这些实验评估了 Qwen 模型在各种 agent 接口和记忆配置下的稳定性、实时效率和可扩展性。结果表明,这些模型提供了高度可复现的性能,较快的推理速度与较高的成功率相关,且记忆带来的益处因接口类型而异。此外,GameWorld 基准测试提供了比现有方法更全面且可验证的评估框架,尽管不同接口的高 token 需求导致了显著的计算成本。