Command Palette
Search for a command to run...
KnowRL: 通过具有最小充分知识引导的 Reinforcement Learning 提升 LLM Reasoning 能力
KnowRL: 通过具有最小充分知识引导的 Reinforcement Learning 提升 LLM Reasoning 能力
摘要
RLVR(强化学习与验证奖励)能够提升大语言模型的推理能力,但其有效性往往受限于难题中严重的奖励稀疏(reward sparsity)问题。近期的基于提示(hint-based)的 RL 方法通过注入部分解决方案或抽象模板来缓解稀疏性,然而,这类方法通常通过增加更多的 tokens 来扩展引导信息,这会引入冗余、不一致性以及额外的训练开销。我们提出了 KnowRL(Knowledge-Guided Reinforcement Learning,知识引导的强化学习),这是一种将提示设计视为“最小充分引导”问题的 RL 训练框架。在 RL 训练期间,KnowRL 将引导信息分解为原子知识点(Knowledge Points, KPs),并利用约束子集搜索(Constrained Subset Search, CSS)构建紧凑且具备交互感知能力的子集用于训练。我们进一步发现了一种“剪枝交互悖论”(pruning interaction paradox)——即移除单个 KP 可能有所帮助,但同时移除多个此类 KP 则可能产生负面影响——并针对这种依赖结构显式地优化了鲁棒的子集筛选过程。我们基于 OpenMath-Nemotron-1.5B 训练了 KnowRL-Nemotron-1.5B。在 1.5B 参数规模下的八项推理 benchmark 中,KnowRL-Nemotron-1.5B 的表现持续优于强大的 RL 及提示引导基准模型。在推理阶段不使用 KP 提示时,KnowRL-Nemotron-1.5B 的平均准确率达到 70.08,已比 Nemotron-1.5B 高出 9.63 个百分点;在使用精选 KP 的情况下,性能进一步提升至 74.16,在该参数规模下刷新了 SOTA(state of the art)记录。该模型、精选训练数据及代码已开源至:https://github.com/Hasuer/KnowRL。
一句话总结
作者提出了 KnowRL,这是一个强化学习框架,通过将提示(hint)设计视为一个最小充分知识问题来增强大语言模型的推理能力。该框架利用约束子集搜索(Constrained Subset Search)来选择紧凑且具备交互感知能力的知识点,使得 KnowRL-Nemotron-1.5B 在八个推理基准测试中达到了最先进的性能。
核心贡献
- 本文引入了 KnowRL,这是一个强化学习训练框架,通过将指导分解为原子知识点,将提示设计视为一个最小充分的指导问题。
- 本研究提出了约束子集搜索(CSS),这是一种选择策略,通过构建紧凑且具备交互感知的知识点子集,来解决剪枝交互悖论(pruning interaction paradox)问题,即移除特定的知识点组合可能会导致性能下降。
- 在八个推理基准测试上的实验结果表明,KnowRL-Nemotron-1.5B 模型在 1.5B 规模上实现了新的最先进水平,在使用选定的知识点提示时,平均准确率达到了 74.16。
引言
来自可验证奖励的强化学习(RLVR)对于提高大语言模型的推理能力至关重要,但当模型在困难任务上无法生成正确答案时,往往会面临奖励稀疏的问题。虽然现有的基于提示的方法试图通过注入部分解决方案或推理模板来缓解这一问题,但它们通常依赖于过度的指导,从而引入了冗余、概念模糊以及增加的计算开销。作者提出了 KnowRL,这是一个将提示设计视为最小充分指导问题的框架,通过将信息分解为原子知识点(KPs)。他们引入了约束子集搜索(CSS)策略,以识别解锁奖励所需的最小且最有效的 KP 子集,专门解决了 KP 表现出复杂依赖关系的剪枝交互悖论。这种方法使模型能够在保持显著更加紧凑和高效的训练指导的同时,在 1.5B 规模上实现最先进的推理性能。
数据集

数据集描述
作者通过多阶段的策划和处理流程构建了 KnowRL 训练数据集:
-
数据集组成与来源
- 核心训练数据源自开源的 QuestA 数据集。
- 去重后,作者保留了 8.8k 个唯一的训练实例。
-
知识点(KP)提取与精炼
- 落地(Grounding): 为了确保推理的准确性,作者首先针对每个问题从 DeepSeek-R1 中采样响应,直到获得正确的解决方案。
- 提取: 利用问题和经过验证的解决方案,通过提示 DeepSeek-R1 仅提取本质的数学原理,从而创建初始的候选 KP 集合。
- 验证: 为了防止数据泄露并确保泛化能力,DeepSeek-R1 充当自动化审查员来验证每个 KP。任何属于实例绑定而非具有泛化能力的 KP 都会进行人工修正。
-
数据处理与选择
- 紧凑性策略: 作者没有使用所有的原始 KP(这可能导致跨提示的不一致性),而是采用了紧凑子集选择(CSS)策略。该过程将 KP 的数量减少了约 38%,以创建更高效的训练提示。
- 采样程序: 对于每个训练实例,作者使用 top_p 为 0.9 和 temperature 为 0.9 采样 32 次生成。该程序重复进行 8 次独立运行,以构建最终的训练集。
方法
作者提出了 KnowRL,这是一个旨在通过结构化知识点(KP)策划和选择来增强数学推理能力的框架。从高层级来看,KnowRL 遵循端到端的流程:对于每个训练问题,它首先构建一组候选 KP,然后过滤掉泄露和冗余以获得紧凑且针对特定问题的子集,最后仅在必要时将此策划出的子集用作强化学习(RL)训练的提示数据。KnowRL 的核心技术贡献在于高质量 KP 数据的构建与选择,这一过程在任何 RL 训练开始前离线完成,以确保可复现性和效率。
KP 构建过程始于从正确解决方案中提取原始知识点。这一阶段(如框架图所示)涉及一个基于提示的提取步骤,其中系统会获得一个问题及其正确解决方案。任务是识别解决该问题所需的本质数学知识,重点关注那些不可或缺、具有通用性且数学基础性的核心概念。提取的 KP 并非旨在重现完整的解决方案或解释推理步骤,而是为了捕捉必须应用的关键词和条件。如下图所示,输出是一个简洁的、带编号的知识点列表,每个知识点都附带了对其应用至关重要的关键注意事项。

提取之后,泄露验证步骤确保了 KP 的质量和独立性。这一阶段将系统视为数学推理数据集的专家审查员。给定一个问题和候选知识描述,任务是确定该描述是否与问题强耦合。如果知识点包含特定的数值、唯一的变量名或与问题结构绑定的配置,则被视为强耦合。目标是过滤掉过于具体或泄露问题本身信息的 KP,确保生成的 KP 具有泛化能力,并能有效地作为类似问题的提示。验证过程需要一个 JSON 格式的响应,指出知识是否强耦合并提供简短解释。

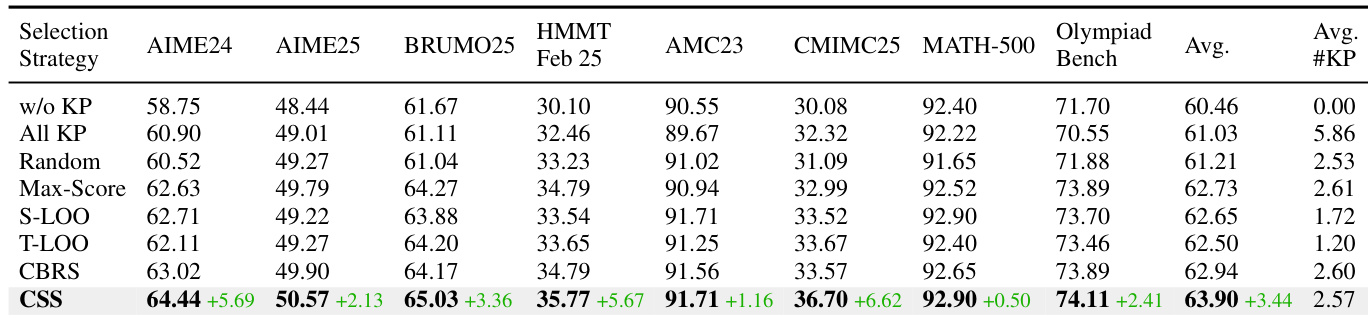
策划后的 KP 集合会经历一个逐问题的选择过程,以确定用作提示的最佳子集。这涉及对各种配置进行离线准确率评估:不使用 KP (A∅)、使用全集 (AK) 以及执行留一法消融 (A−i)。作者评估了多种选择策略,包括 Max-Score、严格留一法 (S-LOO) 和容忍留一法 (T-LOO),这些策略被形式化为参数化决策算子。这些策略旨在减少对 KP 的依赖,同时保持性能。然而,识别出的一个关键挑战是剪枝交互悖论,即移除单个 KP 可能会提高性能,但共同移除它们可能会由于跨提示的不一致性而导致性能显著下降。为了解决这个问题,作者引入了约束子集搜索(CSS),它首先剪掉非降级且接近最优的 KP,然后在剩余的候选空间中进行全局搜索,从而在准确率和紧凑性之间实现更好的平衡。此外,基于共识的鲁棒选择(CBRS)通过汇总多次独立评估运行的结果来识别鲁棒且高性能的配置,进一步提升了选择质量。
实验
实验通过各种训练配置、选择策略和评估协议来评估 KnowRL 框架,以验证其内化结构化推理的能力。结果表明,模型显著改善了其底层策略,而不仅仅是依赖测试时的提示,在复杂的竞赛型推理任务中表现出特别的优势。此外,CSS 选择策略被证明比 CBRS 更鲁棒、更稳定,而熵退火(entropy annealing)等技术可以有效加速收敛并优化性能。
作者在多个推理基准测试上将 KnowRL-Nemotron-1.5B 与基准模型进行了对比,结果显示 KnowRL 在使用和不使用知识点提示的情况下均取得了优异的性能。结果表明,模型的改进源于增强的策略学习,而非依赖测试时的提示。KnowRL-Nemotron-1.5B 在所有评估的基准测试中都优于基准模型,在具有挑战性的竞赛型数据集上增益显著。即使在没有知识点提示的情况下,该模型也表现出强大的性能,这证明了训练过程提高了底层的推理能力。与 CBRS 相比,使用 CSS 选择的知识点带来了更高的平均准确率,表明提示构建更加有效。
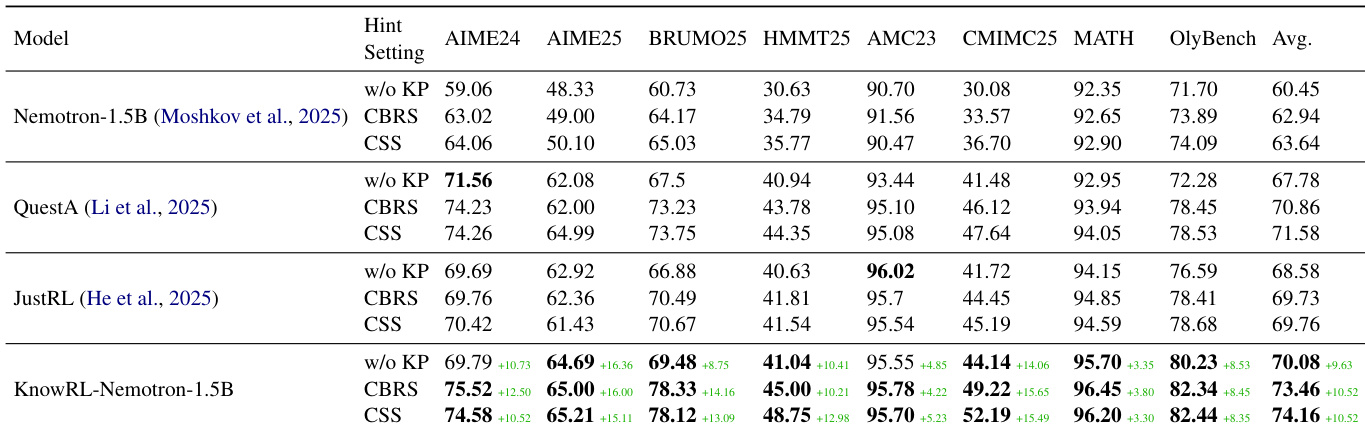
作者在多个推理基准测试中将 KnowRL-Nemotron-1.5B 与变体及基准模型进行了比较。结果显示,KnowRL 取得了优异的性能,尤其是在使用熵退火时,并且在不依赖测试时提示的情况下优于其他模型。与其它模型相比,KnowRL-Nemotron-1.5B 在所有基准测试中实现了最高的平均性能。使用熵退火的模型优于不使用它的变体,证明了收敛性和最终准确率的提升。KnowRL 一致地超越了基准模型,表明其推理能力得到了超越简单提示注入的增强。

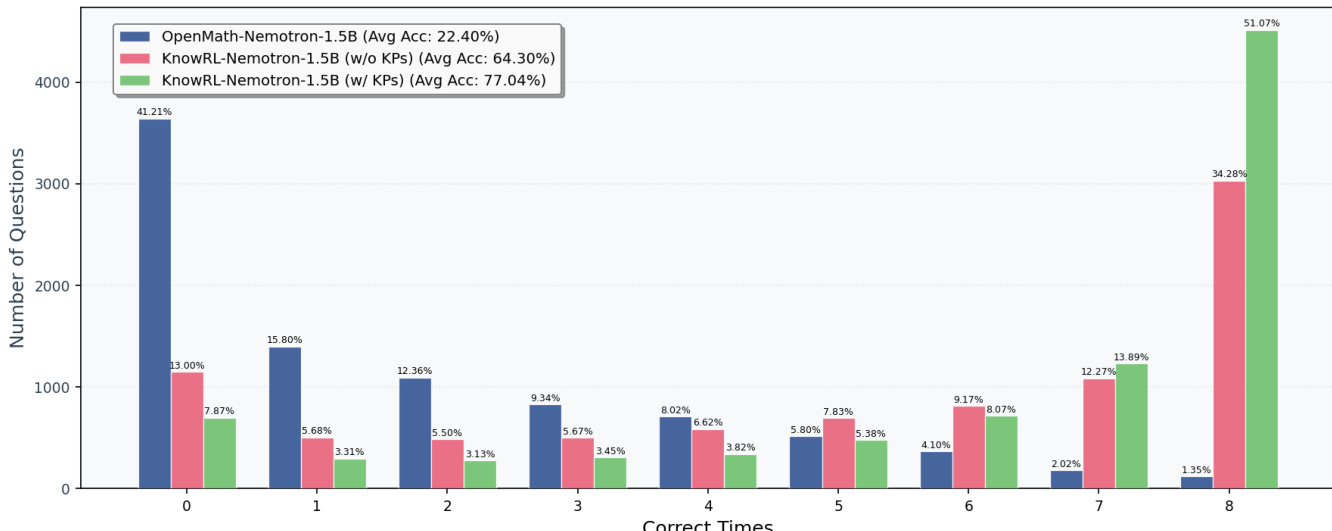
作者比较了三个模型在训练集上的每个查询正确数分布,展示了性能如何随训练和知识点的使用而提高。从基准模型转向训练后的模型时,分布显著向右偏移,而在推理时使用知识点时提升最为明显。基准模型显示出高频率的零正确答案和较低的平均准确率。使用 KnowRL 进行训练改善了分布,减少了零正确查询并增加了完全正确答案的比例。在推理时使用知识点进一步将分布推向更高的正确数,最高区间显著增加。
作者在强化学习设置中比较了不同的知识点选择策略,评估了它们在多个推理基准测试中对模型性能的影响。结果显示,CSS 策略一致优于其他方法,特别是在具有挑战性的竞赛型数据集上,并实现了最高的平均准确率。与其他方法相比,CSS 选择策略在所有基准测试中都实现了最高的性能。性能提升在具有挑战性的竞赛型推理任务上最为显著。CSS 方法在 CBRS 和其他基准选择策略中表现出持续的优越性。
作者分析了训练期间移除知识点对模型性能的影响。结果显示,移除知识点会降低非加性交互(non-additive interaction)的概率和平均性能,不同的移除策略以不同的方式影响这些指标。随着移除的知识点增多,模型的性能会下降,这表明这些点对于有效的推理非常重要。移除知识点降低了非加性交互的概率。随着移除的知识点增多,性能会下降。不同的移除策略对模型性能产生不同的影响。

作者在多个推理基准测试中将 KnowRL-Nemotron-1.5B 与各种基准和配置进行了对比,以验证其性能和训练组件的有效性。结果表明,该模型通过增强的策略学习而非简单依赖测试时提示实现了优异的推理能力,熵退火进一步提高了收敛性和准确性。此外,实验表明 CSS 知识点选择策略对于挑战性任务非常有效,并且包含知识点对于维持高性能和减少非加性交互至关重要。