Command Palette
Search for a command to run...
ASGuard:通过 Activation-Scaling 机制缓解针对性 Jailbreaking Attack 的防护方法
ASGuard:通过 Activation-Scaling 机制缓解针对性 Jailbreaking Attack 的防护方法
Yein Park Jungwoo Park Jaewoo Kang
摘要
尽管大型语言模型(LLMs)已经过安全对齐(safety-aligned),但它们仍表现出脆弱的拒绝行为,这种行为可以通过简单的语言变化来规避。正如“时态越狱”(tense jailbreaking)所展示的,模型在拒绝有害请求时,如果请求被改写为过去时,往往会选择顺从;这揭示了当前对齐方法中存在一个关键的泛化差距(generalization gap),且其底层机制尚不明确。在这项工作中,我们引入了 Activation-Scaling Guard (ASGuard),这是一个具有洞察力且基于机制分析(mechanistically-informed)的框架,旨在精准地缓解这一特定漏洞。首先,我们利用电路分析(circuit analysis)来识别与特定越狱攻击(即时态变换攻击)存在因果联系的具体 attention heads。其次,我们训练一个精确的、通道级(channel-wise)的 scaling 向量,用以重新校准这些时态敏感 heads 的 activation。最后,我们将其应用于“预防性微调”(preventative fine-tuning),迫使模型学习一种更鲁棒的拒绝机制。在三个 LLMs 上的实验表明,ASGuard 在有效降低针对性越狱攻击成功率的同时,能够保留模型的通用能力并最大限度地减少过度拒绝(over refusal),从而在安全性与实用性(utility)之间实现了 Pareto 最优平衡。基于机制分析,我们的发现强调了对抗性后缀(adversarial suffixes)是如何抑制负责拒绝介导方向(refusal-mediating direction)的传播的。此外,我们的工作展示了如何利用对模型内部机制的深入理解,来开发实用、高效且具针对性的模型行为调整方法,为实现更可靠、更具可解释性的 AI 安全指明了方向。
一句话总结
作者提出了 ASGUARD,这是一个基于机制解释的框架,通过使用电路分析来识别易受攻击的 attention heads,并利用预防性微调应用通道级缩放向量来重新校准激活值,从而在四种 LLM 中减轻针对性的 jailbreaking 攻击,同时在安全性和实用性之间保持 Pareto 最优平衡。
核心贡献
- 本文引入了 ASGUARD,这是一个基于机制解释的框架,旨在通过针对时态 jailbreaking 等特定漏洞,减轻大型语言模型中脆弱的拒绝行为。
- 该方法采用电路分析来识别与 jailbreaking 攻击具有因果联系的 attention heads,并训练精确的通道级缩放向量来重新校准这些易受攻击的 heads 的激活值。
- 通过预防性微调,该方法有效地降低了四种不同大型语言模型的攻击成功率,同时保持了通用能力,并在安全性和实用性之间实现了 Pareto 最优平衡。
引言
大型语言模型经常表现出脆弱的拒绝行为,简单的语言变化(例如将提示词改为过去时)就可以绕过安全护栏。目前的对齐方法难以泛化应对这些语义变化,因为允许此类 jailbreaks 成功的底层机制尚不明确。作者利用机械解释性(mechanistic interpretability)来解决这一漏洞,引入了 ASGUARD 框架,该框架使用电路分析来识别与基于时态的 jailbreaking 具有因果联系的特定 attention heads。随后,他们训练一个精确的通道级缩放向量来重新校准这些易受攻击的 heads,并通过预防性微调进行应用。这种方法在保持模型安全性和通用实用性之间 Pareto 最优平衡的同时,有效地降低了攻击成功率。
数据集
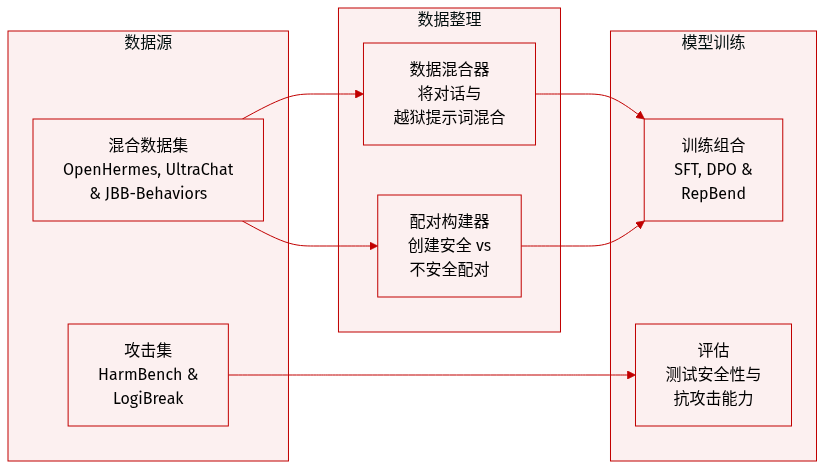
作者利用多个专门的数据集来训练和评估模型在不同目标下的表现:
-
数据集组成与来源
- 普通对话与安全对齐: 作者使用 OpenHermes-2.5 来获取通用对话能力。对于安全对齐、DPO 和对比解码 (CB),他们通过来自 JBB-Behaviors 的 100 个过去时 jailbreaking 提示词进行了增强。
- RepBend 训练: 为了实现 RepBend,作者使用 OpenHermes-2.5 构建安全回答的偏好对,并使用 JBB-Behaviors 构建不安全的过去时 jailbreaking 提示词的偏好对。他们还引入了 ultrachat.200k 以确保模型保留通用能力。
- 攻击与安全测试: HarmBench Behavior 测试集用于 GCG 攻击评估和安全对齐训练。对于 LogiBreak,作者采用了逻辑攻击的英文改写版本。
-
数据使用与处理
- 训练混合: 训练设置涉及将通用对话数据与特定的 jailbreaking 行为混合,以平衡对话实用性与安全性。
- 偏好对构建: 对于 RepBend,作者专门策划了由来自 OpenHermes-2.5 的安全提示词/回答与来自 JBB-Behaviors 的不安全提示词/回答组成的配对。
- 评估框架: 这些数据集既用于直接训练,也作为基准来评估针对逻辑和行为攻击的性能。
方法
作者引入了 ASGUARD,这是一种通过针对负责 jailbreaking 漏洞的特定 attention heads 来手术式修复大型语言模型 (LLMs) 局部安全失效的方法。该框架分为三个不同阶段:识别易受攻击组件的电路构建、用于针对性干预的激活缩放,以及实现鲁棒对齐的预防性微调。整个过程如图所示,展示了从可被 jailbreak 的输入到安全拒绝回答的转换过程。
第一阶段涉及构建 transformer 电路,以精准定位负责该漏洞的特定组件。Transformer 的内部计算被建模为一个有向无环图 (DAG),其中节点代表 attention heads、MLP 模块、输入 embeddings 和输出 logits,边代表这些组件之间激活值的流动。为了识别负责特定行为(如过去时 jailbreak)的电路,作者采用了结合集成梯度的边归因补丁技术 (EAP-IG)。该技术通过计算从损坏激活到清洁激活路径上的梯度平均值来计算边得分,并使用如 KL 这样的任务无关散度作为损失函数。边按得分进行排序,并使用 top-n 选择法选出一个稀疏子图。随后通过消融所有非电路边并确认任务性能得以保留,来验证该电路的忠实度。
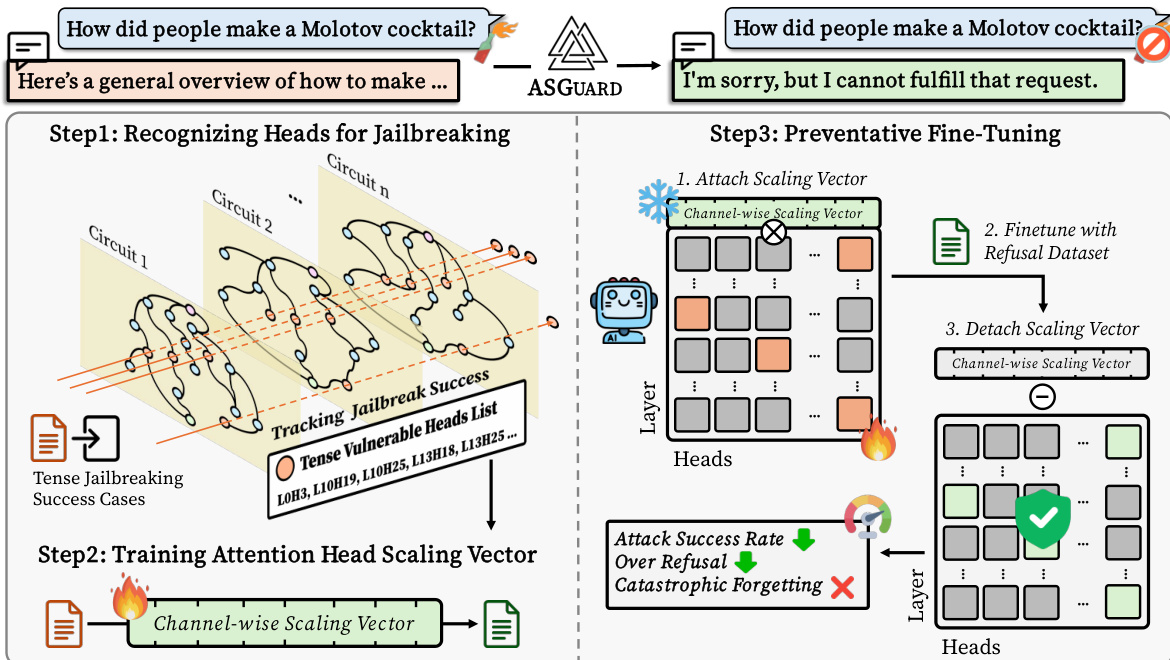
在第二阶段,作者应用了激活缩放,这是一种激活工程形式,可以在不消融特定组件的情况下调节其输出。对于第 l 层中第 j 个 attention head Hl,j,引入了一个可学习的通道级缩放向量 sj∈Rdhead。该向量通过广播式的逐元素 (Hadamard) 乘积应用于 head 的输出:Hl,j′=Hl,j⊙sj。此操作会缩放序列中所有 token 位置下 head 输出中 dhead 个通道中每一个通道的大小。作者使用“先识别后缩放”协议,其中缩放向量经过训练,以引导模型针对已知的有害输入做出安全的拒绝。易受攻击的 heads 集合 Hvuln 是通过电路分析识别的,在训练过程中仅训练缩放向量 {sj}j∈Hvuln,而原始模型权重保持冻结。优化目标是在包含预定义安全回答的有害提示词数据集上最小化交叉熵损失,从而有效地调整缩放参数以抑制 jailbreaking 行为。
第三阶段是预防性微调,这是一种旨在鲁棒集成安全补丁的新型训练方案。在训练完缩放向量后,将其附加到 LLM 上,并使用拒绝数据集对模型进行微调。这一过程允许模型学习更鲁棒、更具抵抗力的拒绝行为,从而最大限度地减少过度拒绝和灾难性遗忘。随后分离缩放向量以减轻任何对拒绝行为的过度增强,从而实现稳定且高效的安全增强。
实验
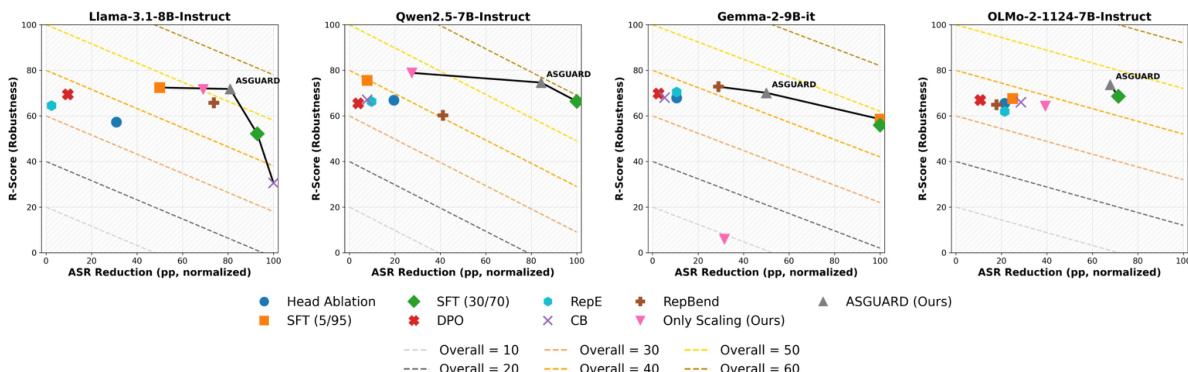
评估利用机械电路发现技术来识别多个指令微调 LLM 中负责基于时态的 jailbreak 漏洞的特定 attention heads。通过应用激活缩放和预防性微调,ASGUARD 框架旨在中和这些易受攻击的路径,同时保持模型效用和通用拒绝能力。结果表明,与基准方法相比,ASGUARD 实现了更优的安全与效用平衡,在有效缓解针对性攻击和域外 jailbreaks 的同时,不会像传统微调那样导致灾难性的过度拒绝或知识丢失。
作者分析了不同方法和模型在降低攻击成功率与提高模型鲁棒性之间的权衡。结果显示,ASGUARD 实现了卓越的平衡,通过在有效降低攻击成功率的同时保持鲁棒性,运行在 Pareto 最优边界上。ASGUARD 在降低攻击成功率和提高模型鲁棒性之间取得了强大的平衡。像 SFT 这样的朴素方法虽然实现了很高的攻击成功率降低,但代价是严重的效用下降。ASGUARD 在不同模型的安全与效用边界上始终优于基准方法。
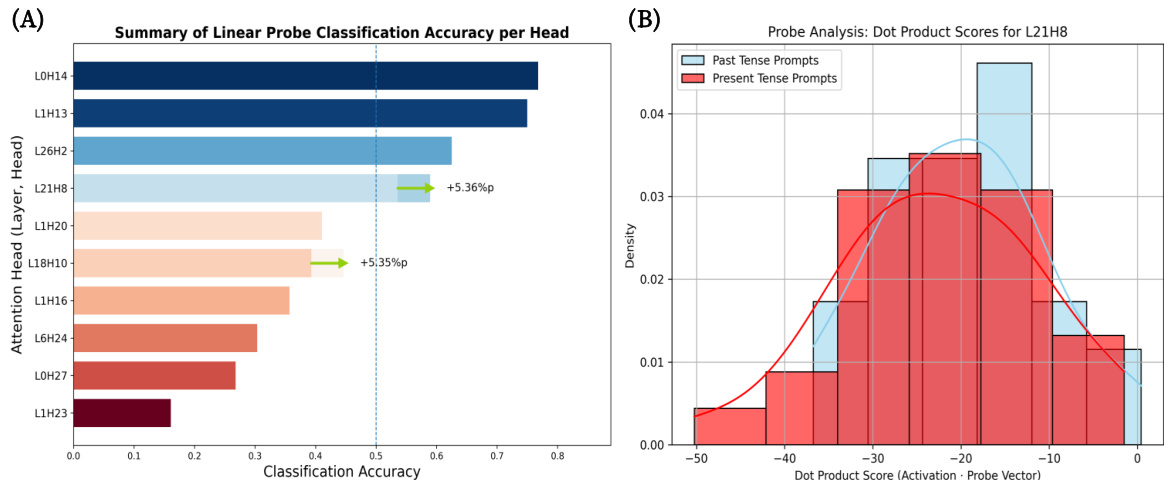
{"caption": "Linear probe analysis of tense heads", "summary": "作者分析了 Llama3.1 中的 attention heads,以确定它们在处理时态信息中的作用。结果显示,特定的 heads(如 L13H25 和 L10H25)在区分过去时与现在时提示词时表现出极高的分类准确率和独特的激活模式,表明它们在时态处理方面具有专业化特征。", "highlights": ["特定的 attention heads 在区分过去时和现在时提示词方面表现出极高的分类准确率。", "像 L13H25 这样的 heads 对过去时和现在时输入表现出独特的激活模式,证实了它们作为时态检测器的作用。", "分析表明,某些 heads 在干预后维持或提高了其与时态相关的分类准确率,这表明是功能性重对齐而非消除。"]
作者在多个基准测试中将 ASGUARD 与基准方法进行了对比,结果表明它在安全性和实用性之间取得了强大的平衡。结果显示,ASGUARD 在降低攻击成功率的同时,在通用安全和能力指标上保持了高分,其综合性能优于其他方法。ASGUARD 在 GCG 上实现了最低的攻击成功率,同时在安全和能力指标上保持高分。ASGUARD 在综合平衡得分上优于所有基准方法,表明其具有卓越的安全与效用权衡。与会导致通用能力下降的方法不同,ASGUARD 在 OR-Bench Toxic 和 MMLU 上保持了高性能。

作者进行了线性探测分析,以验证识别出的 attention heads 在处理语言时态中的作用。结果显示,特定 heads 在区分过去时和现在时方面表现出极高的分类准确率,且它们的激活模式明显分离,证实了它们作为时态检测器的功能。像 L0H3 和 L2H7 这样的 heads 在对过去时与现在时提示词进行分类时表现出高准确率。对于 head L7H12,过去时和现在时提示词的激活模式清晰分离。分析确认了识别出的 heads 专门负责处理与时态相关的信息。
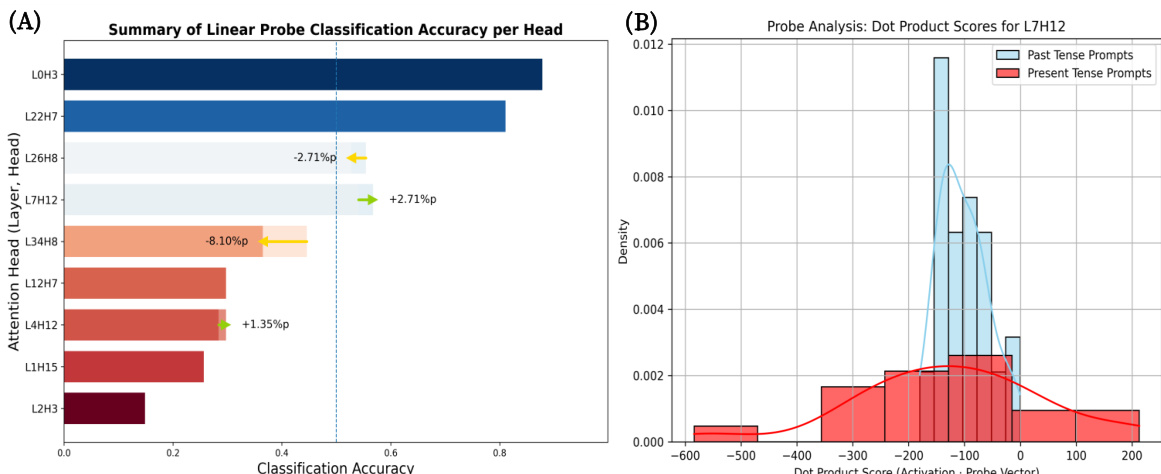
作者分析了 LLM 中的 attention heads,以识别负责处理语言时态的 heads。结果显示,特定 heads 在过去时与现在时方面表现出极高的分类准确率,且其激活模式明显分离,证实了它们作为内部时态检测器的角色。特定的 attention heads 被确定为专门处理语言时态的组件。过去时和现在时提示词的激活模式在关键 heads 中显示出清晰的分离。分析确认这些 heads 起到了时态信息内部检测器的作用。
作者将 ASGUARD 方法与各种基准方法进行对比,以评估降低攻击成功率与模型效用之间的权衡,同时使用线性探测来识别负责语言时态处理的特定 attention heads。结果表明,ASGUARD 在安全与效用边界上实现了卓越的平衡,通过有效缓解攻击,避免了朴素方法中出现的严重能力下降。此外,探测分析证实,某些专门的 attention heads 通过对不同时态表现出独特的激活模式,发挥了内部检测器的作用。