Command Palette
Search for a command to run...
记忆迁移学习:Memory 在 Coding Agents 中是如何跨领域迁移的
记忆迁移学习:Memory 在 Coding Agents 中是如何跨领域迁移的
Kangsan Kim Minki Kang Taeil Kim Yanlai Yang Mengye Ren Sung Ju Hwang
摘要
基于记忆的自我进化(Memory-based self-evolution)已成为 Coding Agent(编程智能体)领域一种极具前景的新范式。然而,现有方法通常将记忆利用限制在同质的任务领域内,未能充分利用不同现实编程问题之间共享的基础设施(如运行时环境和编程语言)。为了解决这一局限性,我们通过利用来自异质领域的统一记忆池,研究了记忆迁移学习(Memory Transfer Learning, MTL)。我们使用了四种从具体轨迹(concrete traces)到抽象见解(abstract insights)不等的记忆表示方式,并在 6 个编程 benchmark 上进行了性能评估。实验结果表明,跨领域记忆使平均性能提升了 3.7%,这主要是通过迁移元知识(如验证例程),而非特定于任务的代码实现的。重要的是,我们发现抽象程度决定了迁移能力:高层级的见解具有良好的泛化性,而低层级的轨迹由于过度具体化,往往会导致负迁移(negative transfer)。此外,我们还证明了迁移效果随记忆池规模的扩大而提升,且记忆甚至可以在不同模型之间进行迁移。本研究为打破单领域孤岛、扩展记忆利用范围提供了经验性的设计原则。项目主页:https://memorytransfer.github.io/
一句话总结
通过在异构领域之间利用统一的 memory pool 来研究 Memory Transfer Learning (MTL),研究人员证明,优先考虑抽象的 meta-knowledge 而非特定任务的 traces,可以将六个 coding benchmarks 的性能提高 3.7%,并为扩展 memory 以及实现 model-to-model transfer 建立了设计原则。
核心贡献
- 本工作引入了 Memory Transfer Learning,这是一种使 coding agents 能够利用从异构任务领域生成的统一 memory pool 来提高目标任务性能的范式。
- 该研究在六个 coding benchmarks 上评估了从具体 traces 到抽象 insights 的四种不同 memory 表示形式,证明跨领域 memory 可将平均性能提高 3.7%。
- 研究通过展示验证程序等高层 meta-knowledge 可以有效地泛化,而低层 traces 由于过度具体化往往会导致负迁移,从而建立了经验性的设计原则。
引言
基于 memory 的自我进化是推进 coding agents 的关键范式,因为它允许它们重用成功的 workflow 并避免过去的错误。虽然这些 agents 依赖 memory 来减少推理开销,但现有方法通常将 memory 的利用限制在同质的任务领域,未能利用不同 coding 问题中存在的编程语言和 runtime environments 等共享的基础设施。作者通过利用来自异构领域的统一 memory pool 来研究 Memory Transfer Learning (MTL),以提高 agent 性能。他们的研究表明,通过迁移高层 meta-knowledge 而非特定任务的代码,跨领域 memory 可以将平均性能提高 3.7%。此外,作者确定 memory 抽象是成功的关键驱动因素,发现高层 insights 具有良好的泛化能力,而低层执行 traces 由于过度具体化往往会导致负迁移。
方法
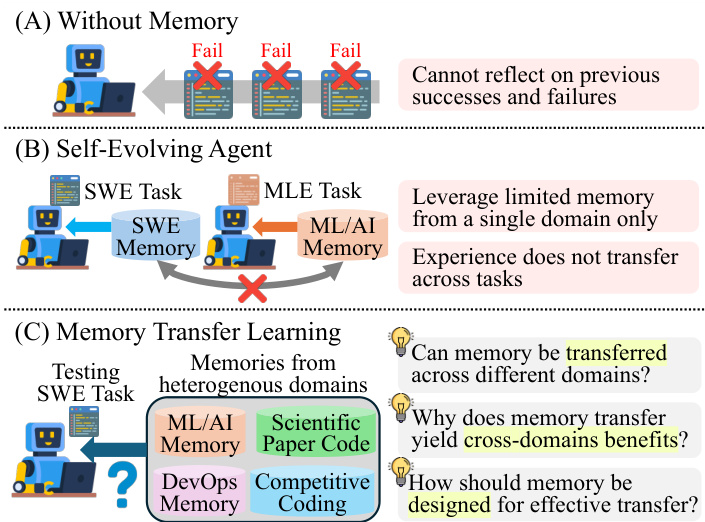
作者设计了一种基于 memory 的 coding agent,它通过两个阶段运行:memory generation 和 memory retrieval。该框架旨在使 agent 能够利用过去的经验来提高任务性能,特别是在跨领域场景中。总体架构如下图所示,其中对比了三种设置:没有 memory 的 baseline agent,使用单一领域 memory 的自我进化 agent,以及所提出的能够实现跨异构领域知识迁移的 memory transfer learning 方法。
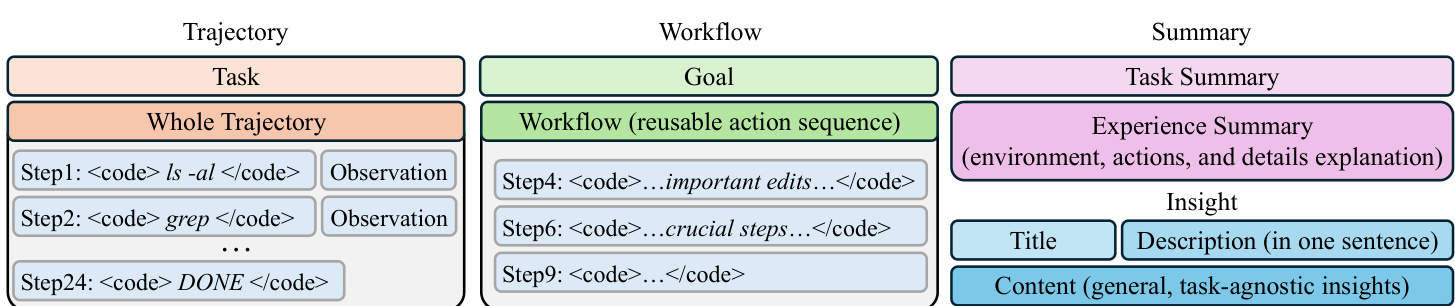
在 memory generation 阶段,agent 在所有 benchmarks 上执行推理以收集 trajectories,即推理、动作和观察的序列。这些 trajectories 构成了构建四种不同 memory 表示的基础。第一种是 Trajectory memory,它保留了完整的动作序列及其相应的观察结果,但不包含推理步骤,从而捕获详细的执行历史。第二种是 Workflow memory,它将 trajectory 抽象为旨在实现特定目标的、可重用的动作序列,从而减少来自无关细节的噪声。第三种是 Summary memory,其中大语言模型 (LLM) 生成任务的简洁摘要以及一段解释推理成功或失败的内容,提供显式分析。第四种是 Insight memory,它将经验提炼为一种可泛化的格式,包括标题、简短描述和内容部分,在不引用具体实现细节的情况下封装可迁移的知识。
生成之后,memory 会被索引并存储在一个异构领域 memory pool 中,该 pool 是通过聚合除当前测试的 memory 类型之外的所有 benchmarks 的 memory 构建而成的。这确保了检索过程是在来自不同领域的知识上运行。在推理期间,agent 通过首先为当前任务生成一个 embedding,然后计算该 embedding 与存储的 memory 的 embeddings 之间的余弦相似度来检索最相关的 memory。选择相似度得分最高的 top-N memory,并在推理过程开始时将其纳入 system prompt,以引导 agent 的推理和动作选择。
通过一个建模抽象与迁移权衡的正式数学框架,进一步分析了 memory transfer 的有效性。该模型将一个 memory embedding 分解为一个代表可迁移 meta-knowledge 的 domain-invariant component(领域不变组件)和一个 domain-specific component(领域特定组件)。memory 的抽象程度被定义为其不变组件所占的比例,而为未见任务检索 memory 的效用被建模为不变组件提供的可迁移指导与由于特定组件导致的领域不匹配惩罚之间的权衡。这种形式化证明了更高的抽象水平会导致更大的迁移增益,为观察到的可泛化 memory 表示的益处提供了理论基础。
实验
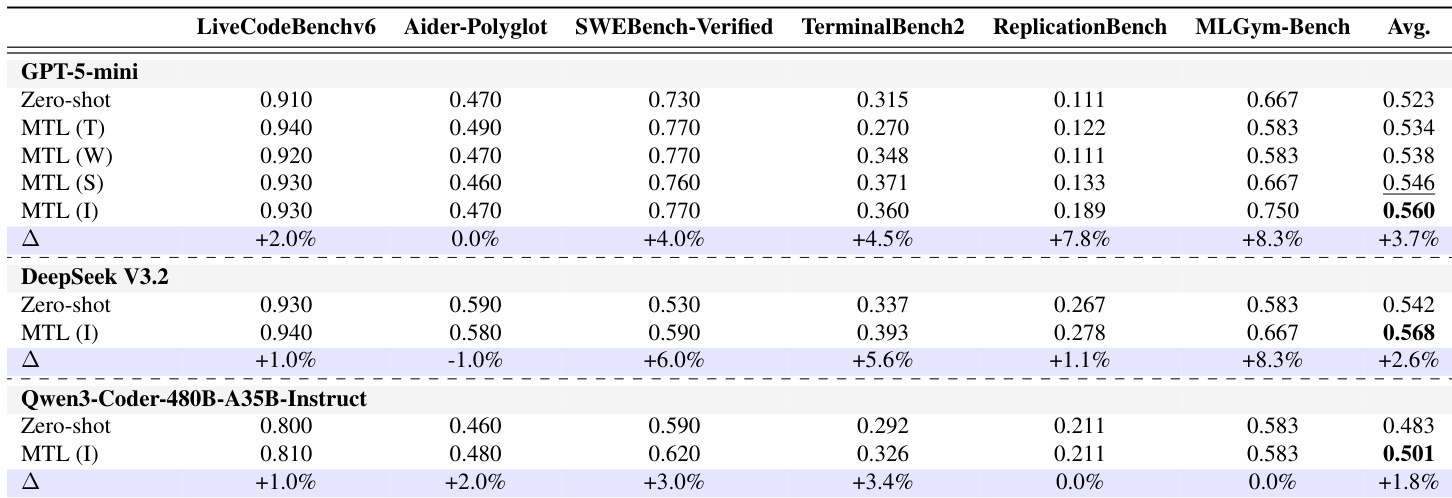
研究人员在从竞赛编程到仓库级任务的六个不同 benchmarks 上评估了 coding agents 的 Memory Transfer Learning (MTL),以验证跨领域知识迁移的有效性。实验表明,MTL 通过提供高层 meta-knowledge 而非特定任务的实现细节,显著优于 zero-shot baselines 和现有的自我进化方法。研究结果表明,与可能导致脆弱执行错误的低层 trajectories 相比,更抽象的 memory 表示(如 Insights)具有更优的迁移性和效率。此外,研究表明 MTL 的益处随着 memory pool 的规模和多样性的增加而扩展,即使在跨不同语言模型迁移 memory 时仍然有效。
作者在多个 coding benchmarks 和模型上评估了 memory transfer learning,显示出相对于 zero-shot baselines 一致的性能提升。Insight memories 实现了最高的平均性能,表明高层、抽象的知识比特定任务的细节迁移得更有效。Memory transfer learning 在不同模型和 benchmarks 上均实现了优于 zero-shot baselines 的性能。捕捉高层程序指导的 Insight memories 实现了最高的平均性能。性能随着更大的 memory pools 和更高的领域多样性而提高,表明可以更好地获取可迁移的 meta-knowledge。
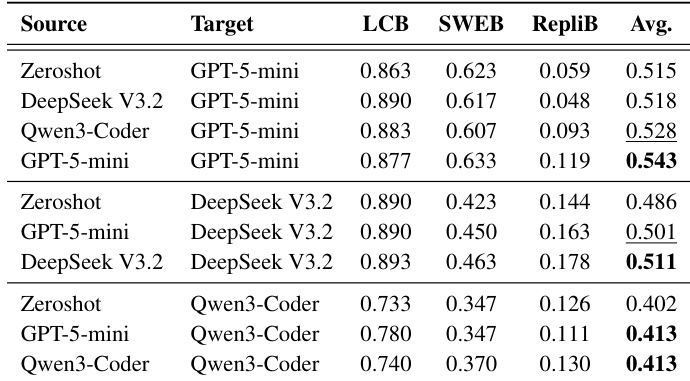
作者在多个 coding benchmarks 和模型上评估了 memory transfer learning,显示出相对于 zero-shot baselines 一致的性能提升。Insight memory 类型实现了最高的平均增益,表明更高的抽象水平增强了迁移效果。与 zero-shot 设置相比,memory transfer learning 在多种 coding benchmarks 和模型上都提高了性能。Insight memory 类型始终优于其他 memory 类型,突显了抽象在 transfer learning 中的重要性。性能增益随着更大的 memory pools 和更高的领域多样性而增加,表明知识迁移受益于更广泛的训练数据。
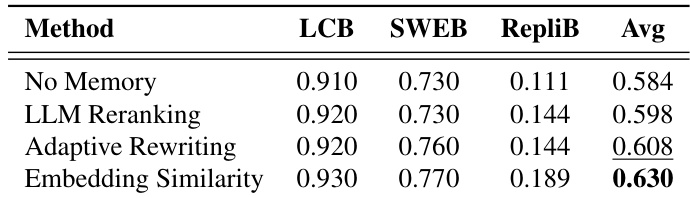
该表比较了多个 benchmarks 下不同的 memory retrieval 方法,显示 embedding similarity 实现了最高的平均性能。Adaptive rewriting 和 LLM reranking 表现相似,但略低于 embedding similarity,而 no memory baseline 最低。在各个 benchmarks 中,embedding similarity 检索方法的表现优于其他方法。Adaptive rewriting 和 LLM reranking 显示出相似的性能,略低于 embedding similarity。no memory baseline 在所有评估指标中性能最低。
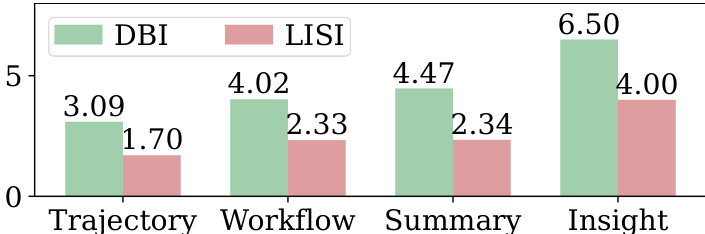
该图使用 DBI 和 LISI 指标比较了不同 memory 类型的 memory 抽象水平。Trajectory 和 Workflow memories 显示出更强的聚类特性,而 Insight memories 则表现出更大的混合度和稀疏性,表明具有更高的抽象度和泛化能力。与 Trajectory 和 Workflow memories 相比,Insight memories 更抽象且更具泛化性。更高的抽象水平与 embedding 空间中更大的混合度和更弱的聚类相关联。DBI 和 LISI 指标表明 Insight memories 具有最高的抽象度和最多样化的表示。
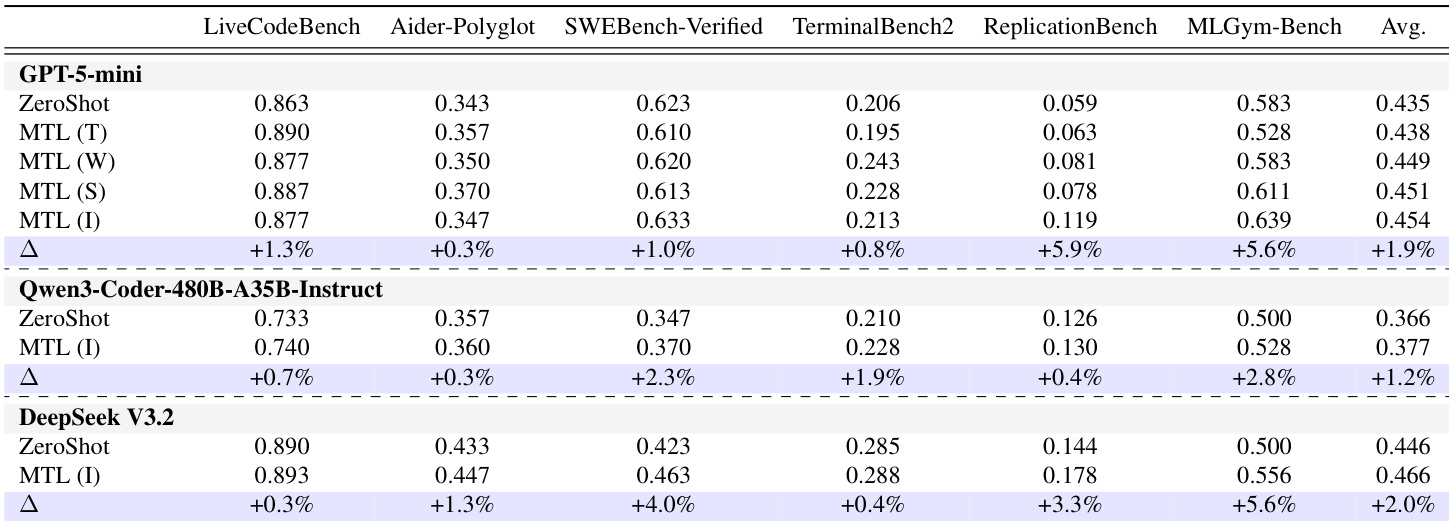
作者在多个 coding benchmarks 和模型上评估了 Memory Transfer Learning,显示出相对于 zero-shot baselines 一致的性能提升。Insight memories 带来了最高的平均增益,表明基于抽象 meta-knowledge 的 memory 对于跨领域迁移最为有效。Memory Transfer Learning 在不同模型和 benchmarks 上始终优于 zero-shot baselines。Insight memories 实现了最高的平均性能增益,表明抽象的 meta-knowledge 最具可迁移性。性能随着更大的 memory pools 和更多样化的源领域而提高,增强了检索有用知识的可能性。
作者在各种 coding benchmarks 和模型上评估了 memory transfer learning,以验证不同 memory 类型和检索方法的有效性。结果表明,memory transfer 一致优于 zero-shot baselines,其中高层 insight memories 由于其抽象和泛化的特性提供了最有效的迁移。此外,性能随着更大、更多样化的 memory pools 而扩展,而 embedding similarity 是最有效的检索机制。