Command Palette
Search for a command to run...
Uni-ViGU:通过基于 Diffusion 的 Video Generator 实现统一的视频生成与理解
Uni-ViGU:通过基于 Diffusion 的 Video Generator 实现统一的视频生成与理解
Luozheng Qin Jia Gong Qian Qiao Tianjiao Li Li Xu Haoyu Pan Chao Qu Zhiyu Tan Hao Li
摘要
集成视觉理解与生成的统一多模态模型面临着一个根本性挑战:视觉生成的计算成本远高于理解任务,在视频领域尤为显著。这种不平衡性促使我们反转传统的范式:我们不再是将以理解为中心的 MLLMs 扩展到支持生成,而是提出了 Uni-ViGU,这是一个通过扩展视频生成器作为基础,来统一视频生成与理解的框架。我们引入了一种统一的流(flow)方法,在单一流程中分别对视频执行连续流匹配(continuous flow matching)以及对文本执行离散流匹配(discrete flow matching),从而实现连贯的多模态生成。此外,我们提出了一种模态驱动的基于 MoE 的框架,通过为 Transformer block 添加轻量级层来增强文本生成能力,同时保留生成先验。为了将生成知识重新用于理解任务,我们设计了一种包含两个阶段的双向训练机制:知识召回(Knowledge Recall)通过重构输入 prompt 来利用已学习到的文本-视频对应关系;而能力精炼(Capability Refinement)则通过在详细描述(detailed captions)上进行 fine-tuning,以建立具有判别力的共享表示。实验表明,Uni-ViGU 在视频生成和理解方面均取得了具有竞争力的性能,验证了以生成为中心的架构是通往统一多模态智能的一种可扩展路径。项目主页与代码:https://fr0zencrane.github.io/uni-vigu-page/。
一句话总结
Uni-ViGU 通过统一的 flow matching 方法和模态驱动的 MoE 架构,扩展了基于扩散的视频生成器,并利用两阶段双向训练机制将生成先验重新用于判别式理解,从而实现了视频生成与理解的统一。
核心贡献
- 本文介绍了 Uni-ViGU,这是一个通过扩展预训练视频生成器作为基础来利用现有时空先验,从而统一视频生成与理解的框架。
- 提出了一种统一的 flow 公式,通过在单个过程中对视频进行连续 flow matching 并对文本进行离散 flow matching,实现了连贯的多模态生成。
- 该工作实现了一种模态驱动的混合专家(MoE)架构和由知识召回(Knowledge Recall)与能力精炼(Capability Refinement)组成的双向训练机制,旨在将生成知识重新用于判别式视频理解。
引言
将视觉理解与生成集成到单个模型中对于开发通用视觉智能至关重要。目前的方法通常通过扩展以理解为中心的多模态大语言模型来支持生成,但这面临着巨大的扩展性问题,因为视频生成需要通过迭代去噪来处理数百万个 token。作者提出了 Uni-ViGU,这是一个通过使用视频生成器作为基础架构来反转这一范式的框架。他们引入了一种统一的 flow 方法,在单个过程中将视频的连续 flow matching 与文本的离散 flow matching 相结合。为了实现这一点,作者利用了模态驱动的 MoE 架构,该架构通过为文本添加轻量级层来增强 Transformer 块,同时保留生成先验,并结合双向训练机制,将学习到的文本与视频的对应关系重新用于视频理解。
数据集
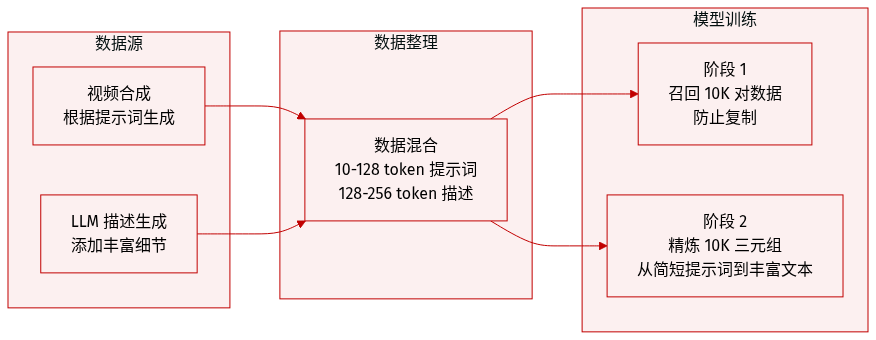
作者利用精心策划的合成视频-文本对数据集,通过两阶段双向框架来训练 Uni-ViGU。数据集详情如下:
- 数据集构成与来源: 数据是通过使用最先进的视频生成器,根据一组初始条件提示词(conditioning prompts)合成视频而成的。随后使用 LLM 分析每个视频-提示词对,以生成高度详细的描述(captions),从而丰富原始提示词的信息。
- 子集与训练用途:
- 第一阶段(知识召回): 模型在 10K 个视频-提示词对上进行训练。在此阶段,目标文本与条件提示词相同,但应用了条件丢弃(condition dropout)以防止模型仅仅是简单地复制输入。
- 第二阶段(能力精炼): 模型在额外的 10K 个“视频-提示词-详细描述”三元组上进行微调。在这里,模型以简短的提示词为条件,但任务是生成语义精确且详细的描述。
- 处理与约束: 为了确保模型培养的是真正的理解能力而非简单的推理,作者实施了严格的 token 长度约束。条件提示词限制在 0 到 128 个 token 之间,而详细描述则限制在 128 到 256 个 token 之间。这种长度上的分离迫使模型依靠共享的注意力机制来弥合简短提示词与丰富描述之间的差距。
方法
作者利用了 WAN2.1(一种最先进的文本到视频生成器)的潜在扩散(latent diffusion)框架作为其统一模型的基础。该框架在压缩的潜在空间中运行,通过迭代去噪实现高效的视频生成。该过程始于视频 x 被变分自编码器(VAE)编码为潜在表示 z1=E(x)。模型通过定义从高斯噪声 z0 到数据潜在表示 z1 的连续传输路径(通过线性插值实现,zt=(1−t)z0+tz1)来学习扩散过程。一个神经网络,具体为 Diffusion Transformer (DiT),被训练用于在给定文本提示词 c、中间潜在表示 zt 和时间步 t 的条件下预测速度场 u=z1−z0,从而优化 flow matching 损失。推理过程通过从 t=0 到 t=1 积分这个学习到的速度场来生成最终的潜在表示,然后将其解码为输出视频 x^=D(z1)。
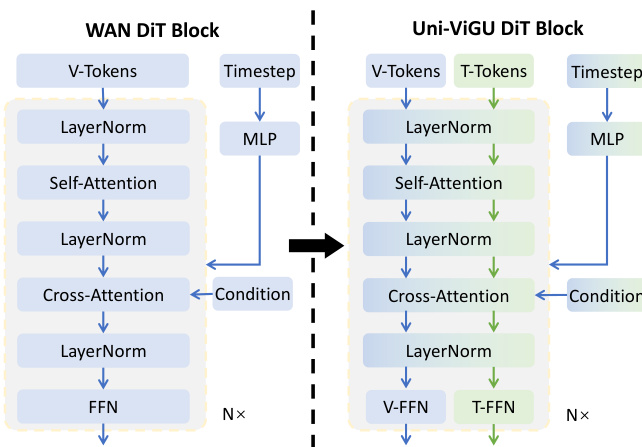
视频生成器的核心架构是 DiT,由多个 transformer 块组成。每个块通过一系列层处理输入:自注意力(self-attention)、交叉注意力(cross-attention)和前馈网络(FFN)。自注意力层捕捉视频特征中的空间和时间依赖关系,而交叉注意力层则整合来自文本提示词 c(用作键值对)的语义信息。FFN 层执行逐位置的变换。如下所示,该结构被扩展以支持统一的文本-视频生成框架。
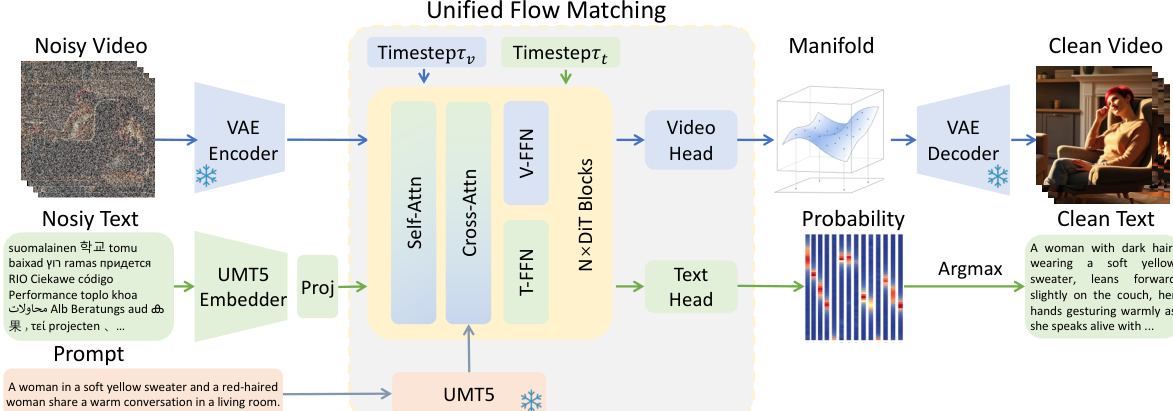
为了统一视频和文本生成,作者提出了一种新颖的 uni-flow 过程,在单个生成框架内对两种模态进行建模。对于视频,保留在潜在空间中运行的连续 flow matching 公式。对于文本,采用了一种离散 flow matching 方法,其中文本 token 通过可学习矩阵 E 映射到连续嵌入(embeddings)。模型学习在此嵌入空间中预测速度场 ut=zt,1−zt,0。至关重要的是,两种模态在单个 Transformer 主干网络中进行联合学习。其核心创新在于模态驱动的混合专家(MoE)架构,该架构共享注意力层以保持跨模态对齐,同时采用特定模态的 FFN 分支来捕捉特定领域的知识。注意力机制在拼接后的视频和文本 token 序列上运行,从而实现双向跨模态交互。生成的表示随后被路由到特定模态的专家 FFNv 和 FFNt,确保在预训练期间学习到的共享注意力模式得到充分利用,同时 FFN 层可以针对各自的模态进行专业化。这种设计允许将知识从预训练的视频生成器高效地转移到文本生成任务中。
训练过程由一个两阶段双向框架组成,以有效地转移和精炼能力。第一阶段“知识召回”使用预训练的视频生成器初始化模型,并训练其学习从视频到文本的反向映射。为了防止捷径学习(shortcut learning),条件提示词会以一定的概率被丢弃,迫使模型从带噪声的视频潜在表示中恢复文本。第二阶段“能力精炼”将目标文本替换为详细的视频描述,迫使文本生成分支关注视频潜在表示以恢复细粒度的视觉细节,从而培养真正的视频理解能力。推理过程是对称的:对于视频生成,模型在文本提示词的引导下,从噪声中对视频潜在表示进行去噪;对于视频理解,模型在清晰视频的引导下,从噪声中对文本潜在表示进行去噪。对于联合生成,两种模态都从噪声开始初始化并并行去噪,它们的 flow 通过共享注意力相互耦合,从而实现相互精炼。