Command Palette
Search for a command to run...
如何 Fine-Tune 推理模型?一种用于合成 Student-Consistent SFT 数据的高师生协作框架
如何 Fine-Tune 推理模型?一种用于合成 Student-Consistent SFT 数据的高师生协作框架
Zixian Huang Kaichen Yang Xu Huang Feiyang Hao Qiming Ge Bowen Li He Du Kai Chen Qipeng Guo
摘要
提升模型能力的一种广泛采用的策略是使用由更强模型生成的合成数据进行监督微调(SFT)。然而,对于像 Qwen3-8B 这样新兴的推理模型而言,这种方法往往无法提升其推理能力,甚至可能导致性能大幅下降。在本研究中,我们发现教师模型生成的数据与学生模型的数据分布之间存在显著的风格差异(stylistic divergence),这是影响 SFT 效果的主要因素。为了弥合这一差距,我们提出了一种“教师-学生协作数据合成框架”(Teacher-Student Cooperation Data Synthesis framework,简称 TESSY)。该框架通过交替使用教师模型和学生模型,来轮流生成风格化 token 和非风格化 token。因此,TESSY 能够生成既继承了教师模型先进推理能力,又在风格上与学生模型分布保持一致的合成序列。在以 GPT-OSS-120B 作为教师模型的代码生成实验中,使用教师模型生成的数据对 Qwen3-8B 进行微调,会导致其在 LiveCodeBench-Pro 上的性能下降 3.25%,在 OJBench 上下降 10.02%;相比之下,使用 TESSY 则分别实现了 11.25% 和 6.68% 的性能提升。
一句话总结
为了缓解推理模型在监督微调过程中因风格差异导致的性能下降,作者提出了 TESSY,这是一个教师-学生协作框架。该框架通过交替使用教师模型和学生模型来生成风格一致的合成序列,最终在使用 GPT-OSS-120B 作为教师时,将 Qwen3-8B 在 LiveCodeBench-Pro 上的代码生成性能提升了 11.25%,在 OJBench 上提升了 6.68%。
核心贡献
- 本文指出,教师生成的数据与学生模型分布之间的风格差异是推理模型在监督微调期间性能下降的主要原因。
- 该工作引入了教师-学生协作数据合成(Teacher–Student Cooperation Data Synthesis, TESSY)框架,通过交替使用教师和学生模型来轮流生成风格 token 和非风格 token,从而在保留高级推理能力的同时确保风格一致性。
- 在代码生成任务上的实验表明,TESSY 克服了标准教师生成数据所导致的性能下降,在对 Qwen3-8B 进行微调时,在 LiveCodeBench-Pro 上实现了 11.25% 的提升,在 OJBench 上实现了 6.68% 的提升。
引言
使用来自更强模型的合成数据进行监督微调(SFT)是增强大语言模型的标准方法。然而,对于专门的推理模型,这种方法往往会导致显著的性能下降,因为教师的输出与学生的分布之间存在风格差异。虽然现有方法试图通过自蒸馏或在策略(on-policy)学习来弥补这一差距,但它们往往面临高昂的计算成本或引入推理捷径的问题。作者提出了 TESSY,一个教师-学生协作数据合成框架,它交替使用教师和学生模型来轮流生成风格 token 和非风格 token。这种方法使合成数据能够从教师那里继承高级推理能力,同时保持学生模型所需的风格一致性。
数据集

数据集概览
作者通过以下过程构建了一个专注于编程竞赛任务的专门训练语料库:
- 组成与来源:数据集由 OpenThoughts 和 NVIDIA Nemotron 提供的开源集合构建而成。
- 选择与过滤:为了确保任务相关性,作者使用了精心设计的提示词来引导 GPT-OSS-120B 选择专门与编程竞赛相关的样本。在此过程中,原始回答被丢弃,仅保留相应的题目。
- 数据集规模:从过滤后的语料库中,作者随机抽取了 80k 个问题。该集合包含 37k 个唯一问题。
- 用途:生成的唯一问题集作为生成新回答和训练所有实验中所用模型的基石。
方法
作者提出了一种教师-学生协作数据合成框架,称为 TESSY,旨在通过解决教师模型与学生模型之间的风格失配挑战,来改进推理模型的监督微调(SFT)。其核心目标是将学生模型的输出分布与数据分布对齐,重点关注有助于任务性能的能力 token,同时减轻可能引入冲突风格模式的风格 token 的影响。为了实现这一目标,该框架将训练目标分解为两个部分:优化能力 token 的 LCap(MS),以及处理风格 token 的 LSty(MS)。其关键见解是,能力 token 最适合从更强大的教师模型中采样,而风格 token 则应遵循学生模型固有的分布,以保持风格一致性。
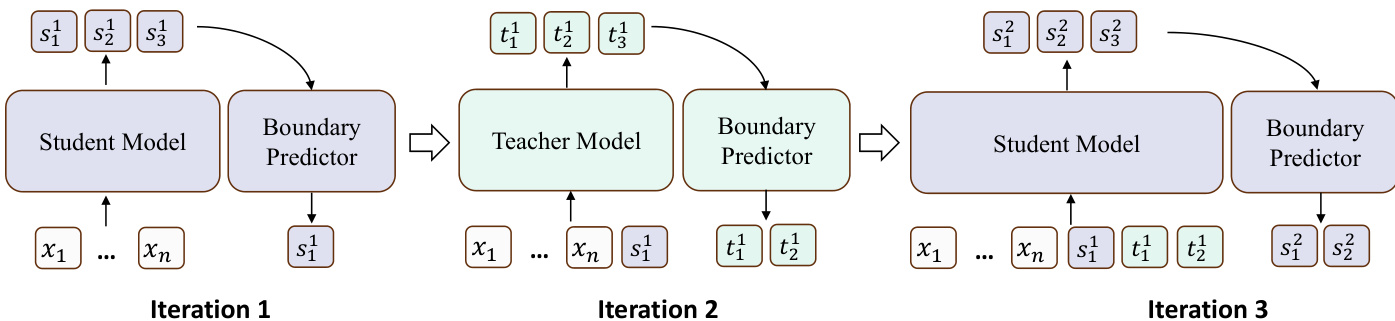
如图所示,TESSY 通过教师和学生模型之间的交替迭代过程生成回答。框架首先由学生模型生成初始的一段风格 token,随后由教师模型产生一段能力 token,并以此交替模式继续。这种设计反映了人类推理的自然结构,即推理步骤通常穿插着过渡性或连接性的陈述。回答 y 被构建为交替片段的序列:y=[s1,t1,s2,t2,…],其中 si 和 ti 分别代表由学生模型和教师模型生成的片段。每个片段的生成取决于之前已生成片段的完整历史,定义为 si=MS(x,[s1,t1,…,si−1,ti−1]) 和 ti=MT(x,[s1,t1,…,si])。
这种交替生成过程中的一个关键挑战是生成边界问题:即如何确定每个片段的合适长度,以确保学生生成的片段仅包含风格 token,而教师生成的片段仅包含能力 token。为了解决这个问题,TESSY 采用了“先生成后回滚”的策略。在每一步中,当前模型生成固定数量的 k 个 token,然后应用边界预测器来识别正确的截断点。对于教师模型,使用能力 token 边界预测器 BT 来定位生成序列中的第一个风格 token,并保留直到最后一个能力 token 为止的所有 token。类似地,学生模型的风格 token 边界预测器 BS 会识别第一个能力 token,并保留直到最后一个风格 token 为止的所有 token。截断后的片段随后被附加到合成序列中,如果发生了截断,则切换生成角色,这表明 token 类型发生了变化。

边界预测器被实现为 token 级别的序列标注模型,经过训练后可以将每个 token 分类为能力 token 或风格 token。为了训练这些预测器,作者从教师和学生模型中各采样了 100k 段思考内容,并使用教师模型对风格片段进行标注。训练是在一个小模型 Qwen3-0.6B-Base 上进行的,以确保效率。最后,通过生成最终答案来完成合成序列,该步骤完全委托给学生模型,以保持与学生输出分布的风格一致性。完整的数据合成过程在算法 1 中列出,该算法形式化了交替生成、边界预测和角色切换的步骤。
实验
实验通过在代码生成、数学和科学任务上对比各种监督微调(SFT)基线方法(包括仅教师方法和教师评分方法)来评估 TESSY 框架。结果表明,直接在风格不同的教师数据上训练学生模型会导致由于分布冲突而引起的性能下降。相比之下,TESSY 通过将推理内容委托给教师,同时通过学生生成的文本保持风格一致性,能够持续提高学生模型的性能,并在不同的教师和学生模型规模下表现出强大的泛化能力。
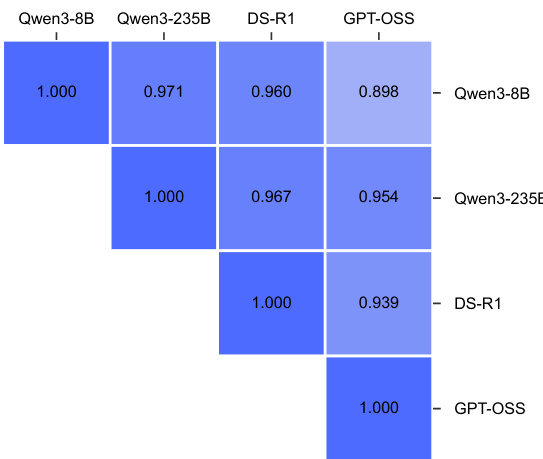
表格展示了不同模型之间输出相似性的比较,表明 TESSY 增加了学生模型与各种教师模型之间的相似性。结果表明,TESSY 有效地减少了生成回答中的分布差异,在同系列模型之间观察到最高的相似性。TESSY 增加了学生模型与教师模型之间的输出相似性。同系列模型之间的相似性最高。TESSY 减少了生成回答中的分布差异。
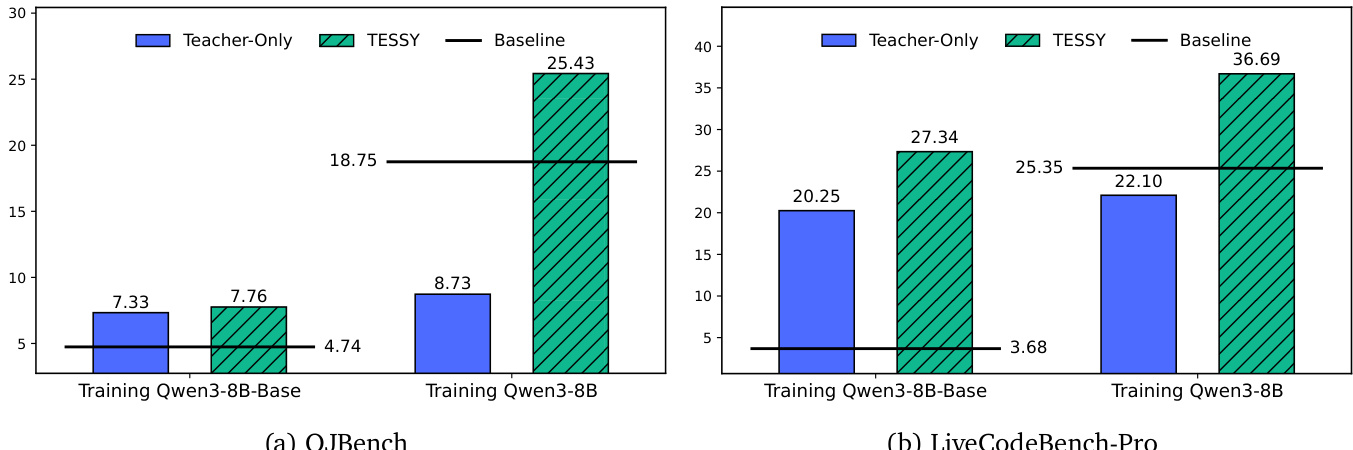
作者在代码生成任务上将 TESSY 的性能与基线方法进行了比较,使用 Qwen3-8B 和 Qwen3-8B-Base 作为学生模型。结果显示,与仅教师(Teacher-Only)和其他基线相比,TESSY 在域内和域外基准测试上均能持续提高性能,而仅教师方法会导致显著的性能下降。与仅教师和其他基线相比,TESSY 在代码生成基准测试上持续提高模型性能。仅教师方法在所有评估的数据集上都导致了大幅的性能下降。即使在基础模型上进行训练,TESSY 也能实现性能提升,尽管增幅小于在推理模型上训练时的增幅。
作者比较了用于微调学生模型的不同数据合成方法,结果显示 TESSY 在多个基准测试中始终优于仅教师方法。结果表明,TESSY 在提高学生模型性能的同时,缓解了由训练数据中风格不匹配引起的性能下降。与仅教师相比,TESSY 在域内和域外基准测试上都提高了学生模型的性能。仅教师方法在多个数据集上导致了性能下降,而 TESSY 避免了这一问题。即使教师模型的基线能力更高,TESSY 也能取得比仅教师更好的结果。
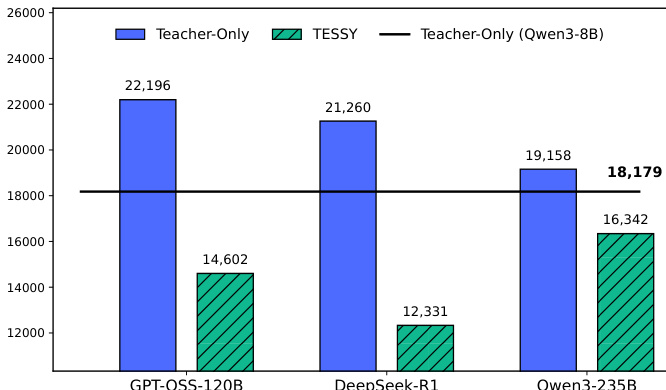
柱状图比较了三种教师模型下,不同方法生成的合成数据的平均 token 数量。结果显示,与仅教师方法相比,TESSY 始终产生更短的回答,减少的程度取决于所使用的教师模型。在所有评估的模型中,TESSY 生成的 token 数量明显少于仅教师方法。在使用 GPT-OSS-120B 作为教师时,token 数量的减少最为显著。TESSY 产生的回答甚至比学生模型 Qwen3-8B 生成的回答还要短。
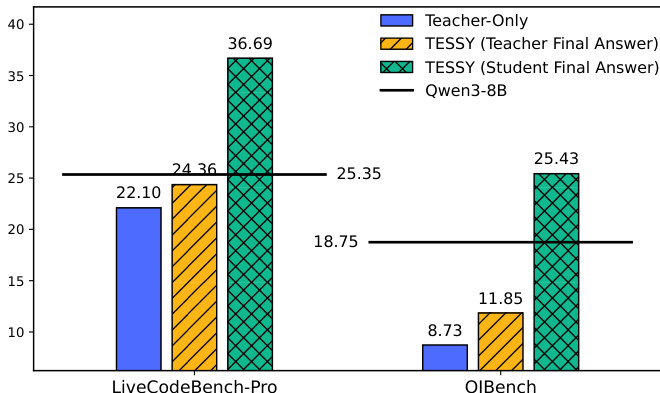
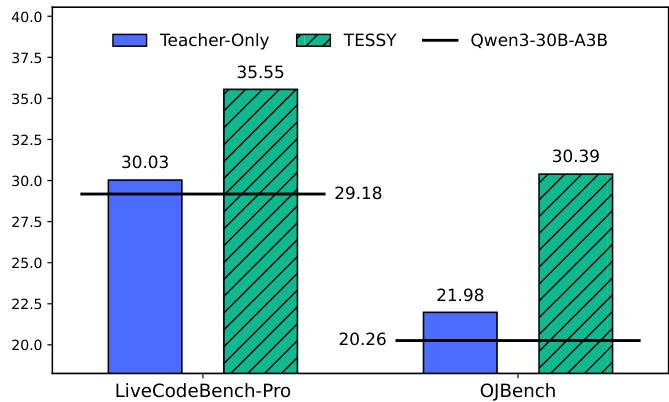
作者在代码生成任务上比较了 TESSY 和仅教师方法的性能。结果显示 TESSY 始终优于仅教师方法,在 LiveCodeBench-Pro 和 OJBench 上均取得了比基线模型更高的分数。在代码生成基准测试上,TESSY 实现了比仅教师更高的性能。与基线相比,TESSY 提高了模型在 LiveCodeBench-Pro 和 OJBench 上的性能。在两个基准测试中,TESSY 与仅教师之间的性能差距都很显著。
实验通过将 TESSY 的输出相似性、代码生成性能和数据合成质量与仅教师及其他基线方法进行对比来对其进行评估。结果表明,TESSY 有效地减少了学生模型与教师模型之间的分布差异,同时防止了通常由风格不匹配引起的性能下降。此外,与仅教师方法相比,TESSY 在域内和域外基准测试上都能持续提高性能,并能产生更简洁的合成回答。