Command Palette
Search for a command to run...
存储智能 Agent
存储智能 Agent
Jingyang Qiao Weicheng Meng Yu Cheng Zhihang Lin Zhizhong Zhang Xin Tan Jingyu Gong Kun Shao Yuan Xie
摘要
深度研究 Agent(Deep Research Agents, DRAs)将 LLM 的推理能力与外部工具相结合。Memory 系统使 DRAs 能够利用历史经验,这对于实现高效推理和自主进化至关重要。现有方法主要依赖从 memory 中检索相似的轨迹(trajectories)来辅助推理,但面临着 memory 进化效率低下以及存储与检索成本不断增加等关键局限。为了解决这些问题,我们提出了一种新颖的 Memory Intelligence Agent (MIA) 框架,该框架采用 Manager-Planner-Executor 架构。Memory Manager 是一个非参数化(non-parametric)memory 系统,能够存储压缩后的历史搜索轨迹;Planner 是一个参数化(parametric)memory agent,能够针对问题制定搜索计划;Executor 是另一个 agent,能够在搜索计划的指导下进行信息搜索与分析。为了构建 MIA 框架,我们首先采用交替强化学习(alternating reinforcement learning)范式来增强 Planner 与 Executor 之间的协作。此外,我们使 Planner 能够在测试时学习(test-time learning)过程中持续进化,其更新在推理过程中实时完成,不会中断推理流程。同时,我们建立了参数化 memory 与非参数化 memory 之间的双向转换环路,以实现高效的 memory 进化。最后,我们引入了反思(reflection)和无监督判断机制,以提升在开放世界中的推理与自我进化能力。在 11 个 benchmark 上的广泛实验证明了 MIA 的优越性。首先,MIA 显著提升了当前 SOTA LLMs 在深度研究任务中的表现。例如,MIA 使 GPT-5.4 在 LiveVQA 和 HotpotQA 上的性能分别进一步提升了高达 9% 和 6%。此外,通过使用轻量级的 Executor(如 Qwen2.5-VL-7B),MIA 在所有评估数据集上的平均提升仍能达到 31%,并以 18% 的优势超越了规模大得多的 Qwen2.5-VL-32B,彰显了其卓越的性能。此外,训练分析表明,强化学习使 Planner 和 Executor 能够协同优化其策略,有效地捕捉数据集的特定特征,并增强跨领域推理与 memory 能力。工具分析显示,长上下文(long-context)memory 方法在多轮工具交互中表现挣扎,而我们提出的 MIA 显著优于以往的方法。在无监督设置下,MIA 达到了与有监督版本相当的性能,同时在多个训练迭代中展现出渐进式的自我进化能力。
一句话总结
Memory Intelligence Agent (MIA) 框架采用管理器 - 规划器 - 执行器架构,通过双向转换和交替强化学习统一参数化与非参数化记忆,实现持续的测试时进化。该框架使 GPT-5.4 在 LiveVQA 和 HotpotQA 上的性能分别提升高达 9% 和 6%,同时允许轻量级 Qwen2.5-VL-7B Executor 在十一个基准测试中平均提升 31%,并优于 Qwen2.5-VL-32B 18%。
核心贡献
- 本文介绍了 Memory Intelligence Agent (MIA) 框架,该框架采用管理器 - 规划器 - 执行器架构来存储压缩的历史搜索轨迹并生成搜索计划。此设计促进了参数化与非参数化记忆之间的双向转换循环,以实现推理期间的高效记忆进化。
- 采用交替强化学习范式来增强规划器与执行器之间的协作,使规划器能够在测试时学习期间持续进化而不中断推理。训练分析表明,这种方法能够实现策略的协同优化,有效捕捉特定数据集的特征并增强跨域推理能力。
- 在十一个基准测试上的广泛实验证明了 MIA 的优越性,显示了当前 SOTA LLM 在深度研究任务中的显著性能提升。该方法将 GPT-5.4 在 LiveVQA 上的性能提升高达 9%,并使轻量级 Executor 以 18% 的优势超越更大模型,同时在无监督设置中实现可比性能。
引言
深度研究 Agent 将大型语言模型与外部工具相结合以处理复杂任务,严重依赖记忆系统来积累经验并随时间完善策略。然而,现有方法通常依赖于存储原始搜索轨迹的长上下文记忆,导致存储臃肿、检索效率低下和注意力稀释。此外,先前的规划器缺乏特定任务的训练,而记忆系统侧重于事实数据,而非有效搜索规划所需的面向过程的策略。为了解决这些问题,作者介绍了 Memory Intelligence Agent (MIA) 框架,具有管理器 - 规划器 - 执行器架构。他们利用非参数化系统进行压缩历史存储,利用参数化 Agent 进行动态规划。通过交替强化学习和双向记忆转换,MIA 实现了持续的测试时进化。这种方法显著增强了推理性能,并允许较小模型在深度研究基准测试中超越较大模型。
数据集
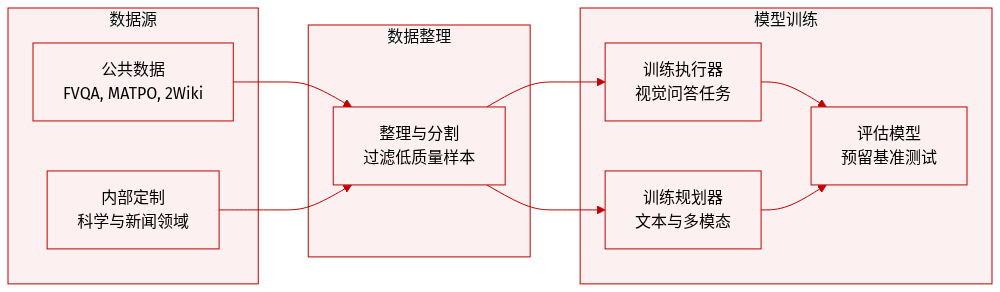
作者在多模态和纯文本数据集上评估了其框架,以评估不同模态下的性能。
多模态数据组成与使用
- 训练: 作者采用 FVQA-train,其中包含来自 MMSearch-R1 设置的 4,856 个图像 - 问题 - 答案示例,用于训练 Executor 和 Planner。
- 公开评估集: 他们利用 FVQA-test (1,800 个示例)、InfoSeek (2,000 个示例)、SimpleVQA (1,013 个示例) 和 MMSearch (171 个示例) 作为保留基准。对于 LiveVQA,他们使用可访问的公开版本(2,384 个示例),而不是已弃用的 3,602 个示例版本。
- 内部多模态集: 构建了两个自定义子集以解决特定领域的问题。内部 1 包括 295 个科学领域(如物理和化学)的示例,通过爬取文本、合成 QA 对和检索匹配图像创建。内部 2 由 505 个来自动态领域(如体育和娱乐)的示例组成,这些示例源自新闻语料库,其中 Qwen2.5-VL-72B-Instruct 锚定视觉实体以构建复杂的多跳问题。
纯文本数据组成与使用
- 训练: 作者将 6,175 个来自 MATPO 的示例纳入 Planner 训练数据中,以增强文本环境中的规划能力。
- 评估: 纯文本评估套件包括 2Wiki (12,576 个样本)、HotpotQA (7,405 个样本)、SimpleQA (4,327 个样本) 和 GAIA-Text (103 个示例)。这些数据集测试多跳推理、事实知识检索和通用问题解决技能。
方法
提出的 MIA 框架引入了管理器 - 规划器 - 执行器架构,旨在解决深度研究 Agent 中的存储瓶颈和推理低效问题。该架构解耦了历史记忆、参数化规划和动态执行。核心组件包括 Planner,作为生成搜索计划的认知枢纽;Executor,作为通过工具使用实施计划的操作终端;以及 Memory Manager,负责记忆压缩和检索。
参考下方的框架图以获取整体架构和推理过程的可视化表示。
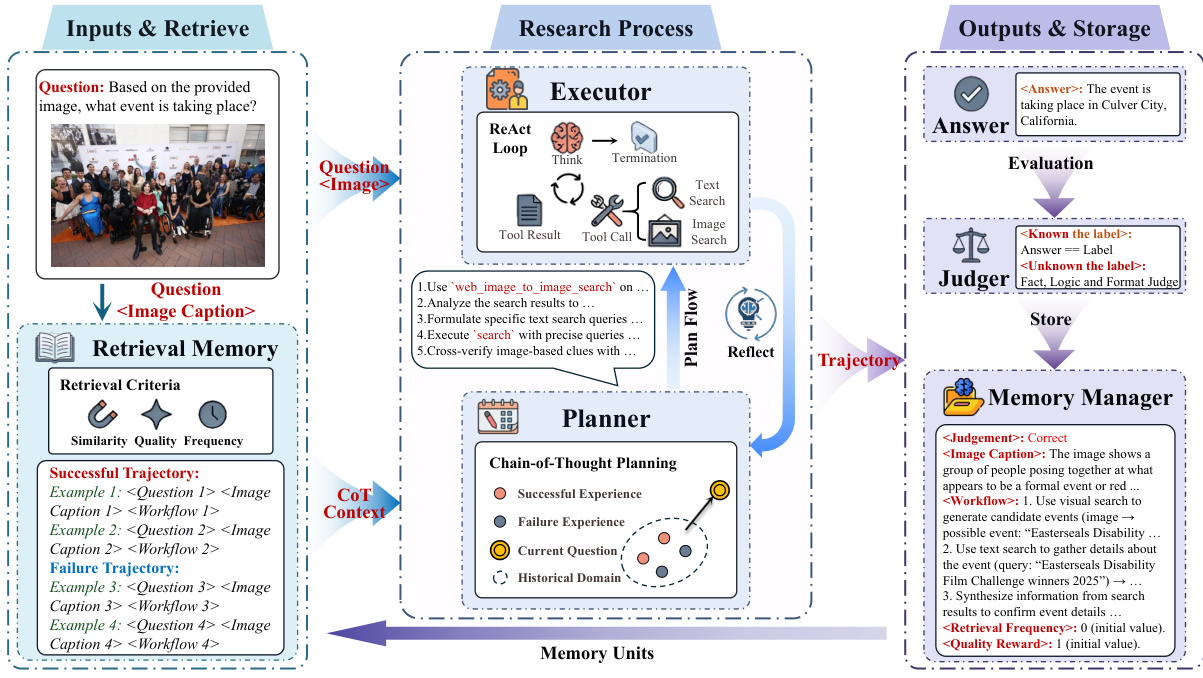
推理过程通过包含三个阶段的规划 - 执行 - 记忆循环运行:记忆检索、协作推理和经验巩固。最初,Memory Manager 基于语义相似性、价值奖励和频率奖励检索相关的历史轨迹,以提供上下文支持。Planner 随后使用少样本思维链策略将复杂任务分解为可执行的子目标。Executor 通过 ReAct 循环与环境交互,执行任务推理和工具使用。动态反馈循环连接两个 Agent;如果 Executor 遇到僵局,Planner 触发反思 - 重规划机制以调整搜索计划。
为确保高效的记忆存储,系统将冗长的轨迹压缩为结构化的工作流摘要。此过程涉及将视觉输入转换为文本标题并抽象动作模式。用于此记忆压缩的提示在下方图中详细说明。

为了优化 Planner 和 Executor 之间的协作,作者提出了一种基于组相对策略优化 (GRPO) 的两阶段交替强化学习 (RL) 训练策略。在第一阶段,Planner 被冻结,而 Executor 被训练以理解和遵循计划。在第二阶段,Executor 被冻结,Planner 使用记忆上下文进行优化,以增强计划生成和反思能力。训练流程,包括前向滚动和反向奖励计算,如下所示。
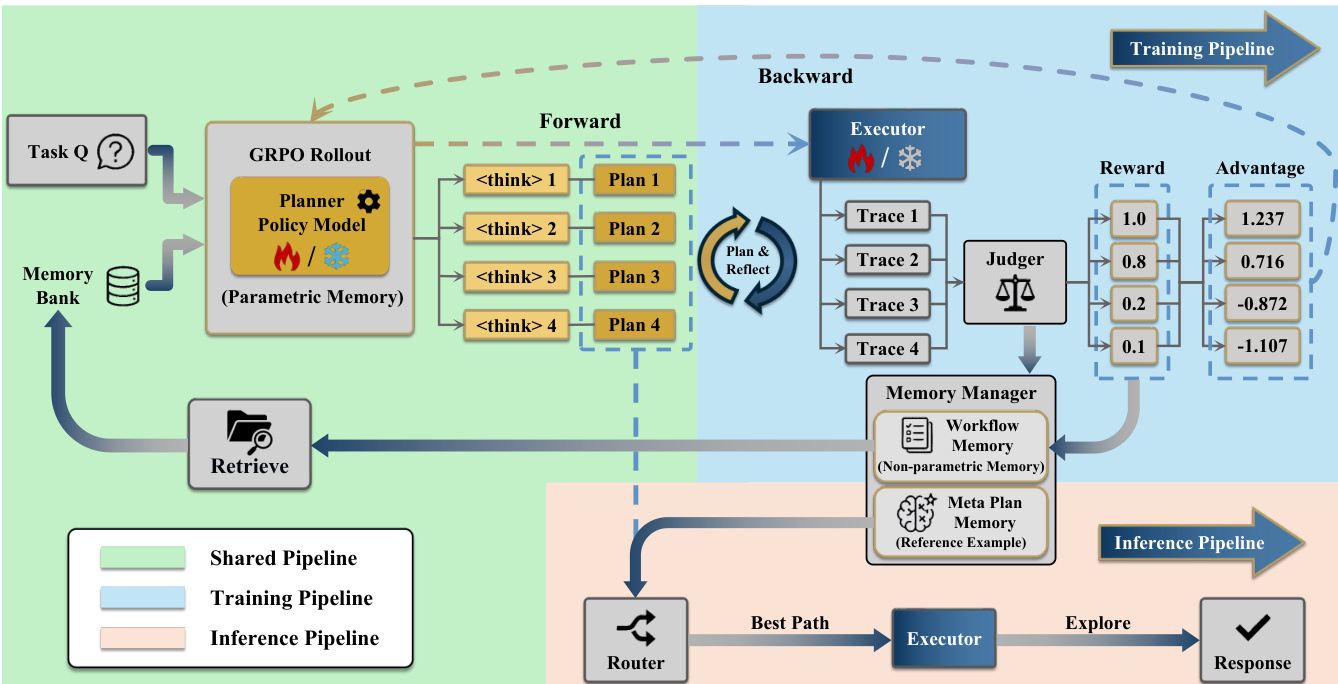
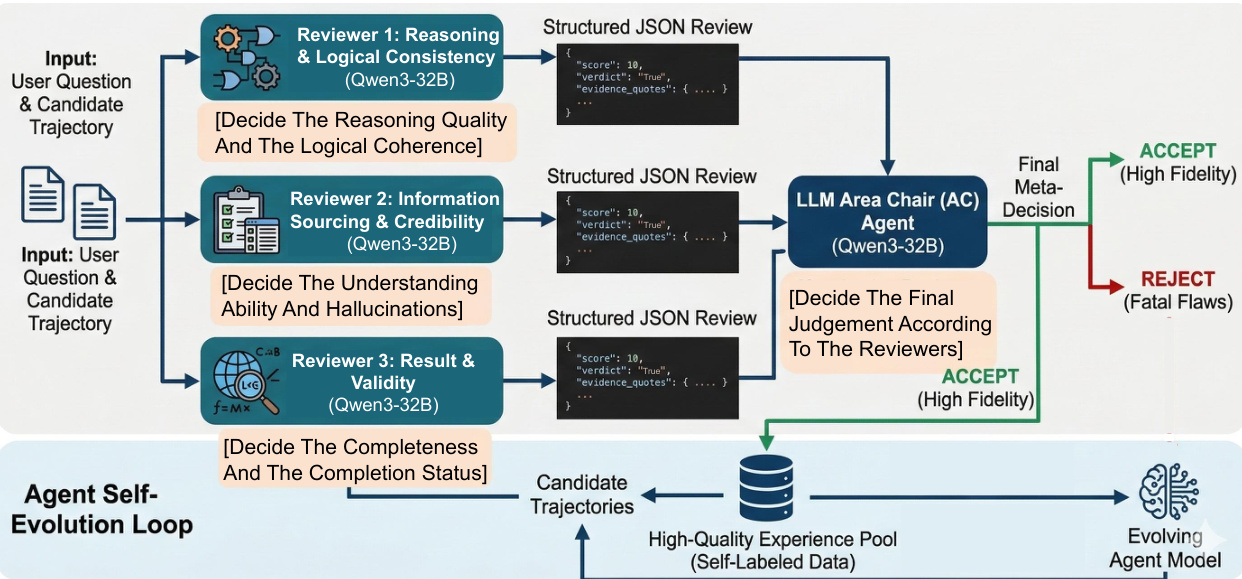
在测试时学习 (TTL) 期间,MIA 采用在线学习范式,同时执行探索、存储和学习。此机制允许 Agent 在不中断推理工作流的情况下更新其参数化记忆 (Planner 参数) 和非参数化记忆 (工作流记忆)。在没有真实答案的无监督环境中,该框架采用一种新颖的评估机制来模拟同行评审过程。这涉及针对推理、信息来源和结果有效性的专门评审员,由 Area Chair Agent 监督以确保稳健的自我进化。此无监督评估框架如下所示。
实验
MIA 在多样化的多模态和纯文本基准测试上针对闭源模型和基于记忆的 Agent 进行了评估。结果表明,MIA 的双重记忆机制和在线更新减轻了传统上下文方法中发现的噪声,超越了许多闭源模型和 Agent。消融和泛化分析进一步验证,通过记忆而非直接执行来指导规划,结合测试时学习,确保了跨模态和执行器类型的稳健推理。
作者在多个多模态数据集上针对直接答案模型、搜索 Agent 和基于记忆的 Agent 评估了其提出的 MIA 框架。结果表明,与大多数基线相比,MIA 实现了优越的性能,有效地弥合了内部化历史经验的差距,优于上下文记忆方法。提出的 MIA 模型在开源模型中实现了顶级性能,并在各种基准测试中与 Gemini-3-Flash 等领先的闭源系统的能力相媲美。上下文记忆方法(如 RAG 和 Mem0)通常表现低于无记忆基线,表明长记忆上下文可能会引入噪声。MIA 的无监督变体展示了强大的能力,取得了接近完全监督版本性能的竞争性结果。
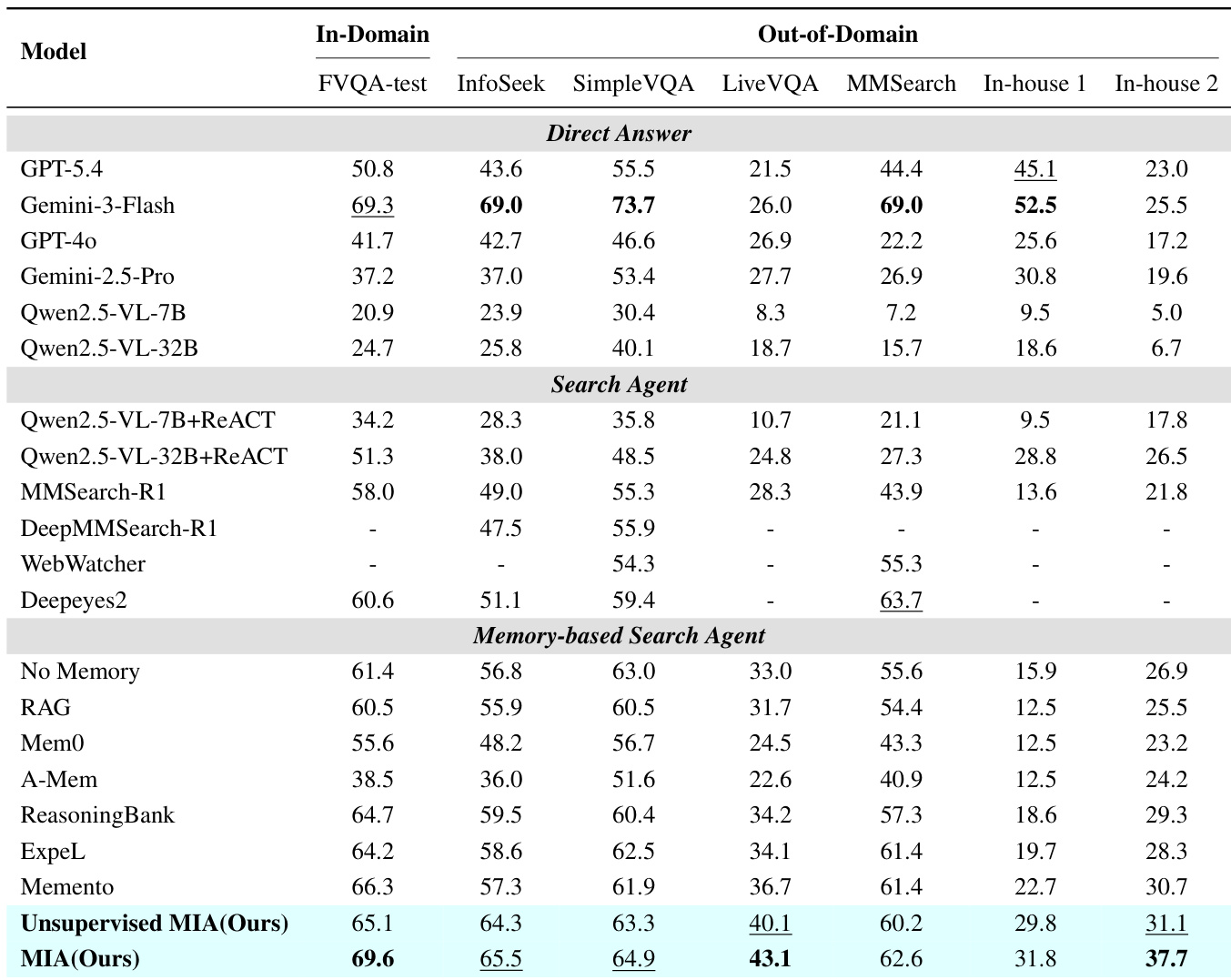
下表评估了其提出的框架中各个组件在多模态数据集上的贡献。结果表明,逐步引入记忆引导规划和测试时学习等模块,性能始终优于基线。与中间变体相比,完整系统在所有一域和域外基准测试中实现了最高准确率。专门集成记忆以指导规划过程,与单独使用记忆或无记忆基线相比,产生了显著的性能提升。通过交替强化学习训练规划器组件,与使用标准预训练规划器相比,提供了实质性改进。包含测试时学习的完整框架在所有评估数据集上均优于所有消融版本,证明了完整架构的有效性。
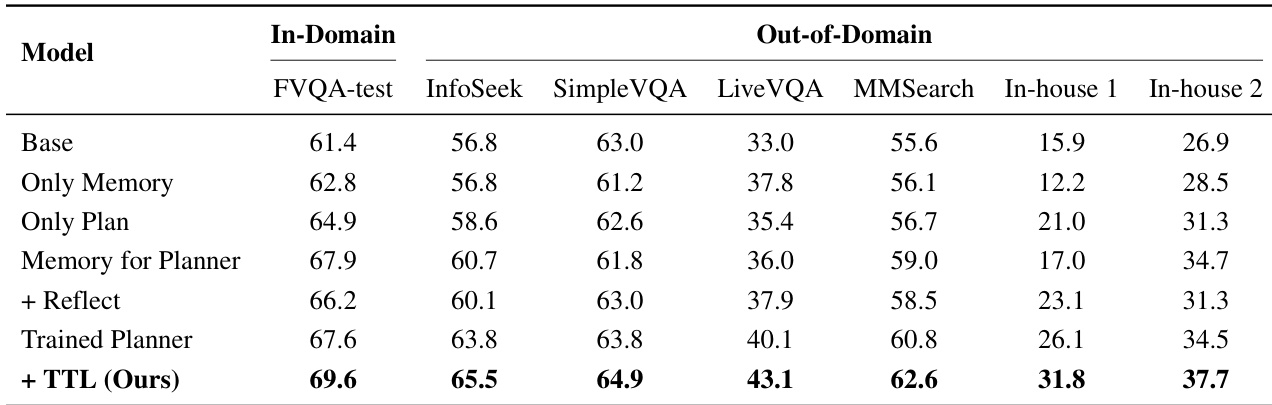
下表展示了无监督 MIA 模型在多模态和纯文本基准测试上的评估,将其性能与 Base 和 Plan 以及 Reflect 基线进行了比较。它特别跟踪了模型在三 epoch 无监督自我进化过程中的进展,以证明所提出方法的有效性。结果表明,模型始终优于基线,并且随着经历更多 epoch 的训练,准确率稳步提高。无监督 MIA 在所有评估数据集上的准确率均高于 Base 和 Plan 以及 Reflect 模型。性能从 epoch-1 到 epoch-3 表现出一致上升趋势,验证了自我进化机制的有效性。与基线配置相比,模型在纯文本推理任务上表现出显著改进。
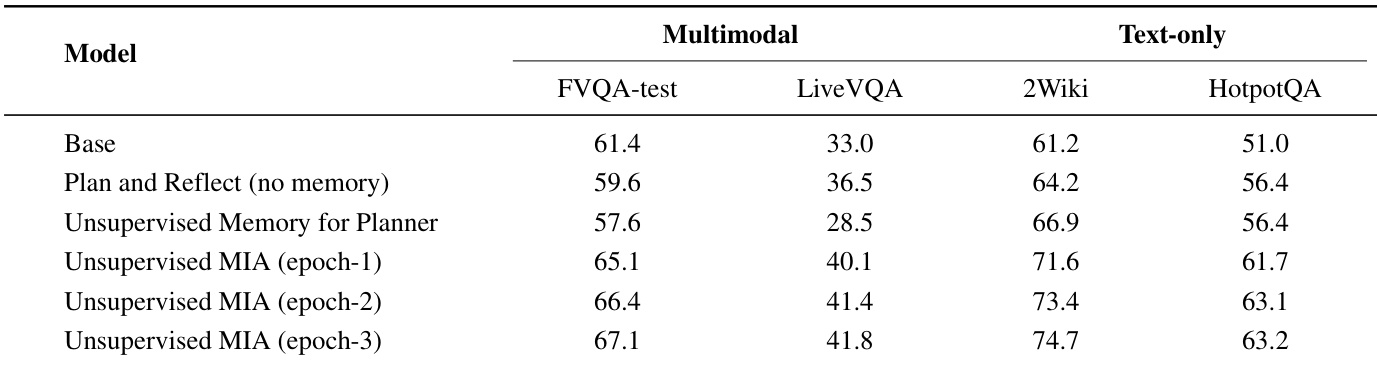
下表展示了一项消融研究,评估了特定架构组件对纯文本域外推理任务的影响。结果显示,随着模型集成记忆引导规划、反思和测试时学习机制,性能一致增加。完整框架在所有数据集列上均优于所有中间变体和基线。用记忆指导规划器比单独使用记忆或规划产生了明显更好的结果。通过强化学习训练规划器模型,与标准预训练规划器相比,带来了实质性性能提升。在线测试时学习的引入提供了最终的实质性改进,确保了所有基准测试中的最高准确率。
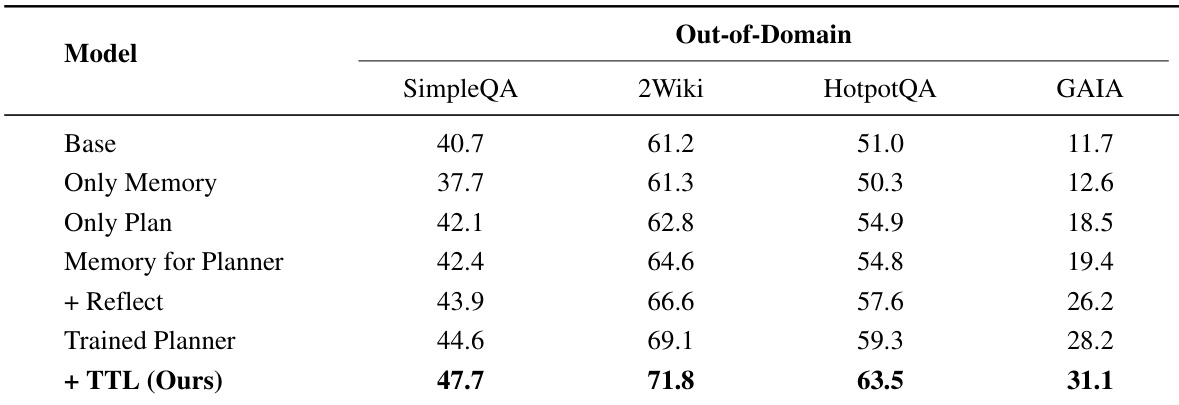
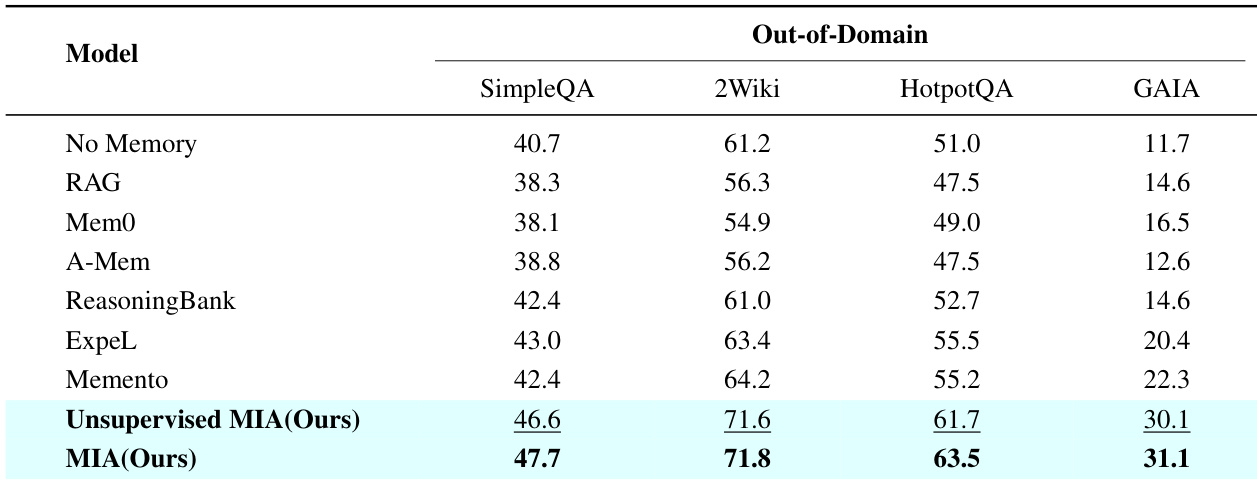
下表将提出的 MIA 模型与各种基线在纯文本域外数据集(包括 SimpleQA、2Wiki、HotpotQA 和 GAIA)上进行了比较。MIA 在所有指标上均表现出优越性能,而传统上下文记忆方法通常落后于无记忆基线。结果验证了 MIA 架构在处理复杂推理任务时不降低性能的有效性。MIA 始终优于所有基线模型,包括 SimpleQA、2Wiki、HotpotQA 和 GAIA 上的 Memento 和 ExpeL。上下文记忆方法(如 RAG 和 Mem0)通常表现低于无记忆基线,表明可能存在噪声引入。MIA 的无监督变体取得了竞争性结果,接近监督版本的性能。
作者在多模态和纯文本域外数据集上针对多样化基线评估了提出的 MIA 框架,证明了其优越性能,可与领先的闭源系统相媲美。消融研究证实,集成记忆引导规划、强化学习和测试时学习,与孤立组件或标准预训练规划器相比,显著提高了准确率。值得注意的是,传统上下文记忆方法通常因噪声而表现不佳,而无监督变体通过有效的自我进化实现了竞争性结果。