Command Palette
Search for a command to run...
Audio-Omni: 将多模态理解扩展至多功能的 Audio 生成与编辑
Audio-Omni: 将多模态理解扩展至多功能的 Audio 生成与编辑
摘要
多模态模型的最新进展推动了音频理解、生成与编辑领域的飞速发展。然而,这些能力通常由专门的模型来处理,开发一个能够无缝集成这三项任务的真正统一框架的研究仍处于探索阶段。尽管一些先驱性工作已尝试将音频理解与生成进行统一,但它们往往局限于特定的领域。为了解决这一问题,我们推出了 Audio-Omni,这是首个能够在通用声音、音乐及语音领域实现生成与编辑统一的端到端框架,并集成了多模态理解能力。我们的架构将用于高层级推理的冻结(frozen)Multimodal Large Language Model 与用于高保真合成的可训练 Diffusion Transformer 相结合,实现了协同效应。针对音频编辑领域关键的数据匮乏问题,我们构建了 AudioEdit——一个包含超过一百万个经过精心策划的编辑对(editing pairs)的新型大规模数据集。广泛的实验表明,Audio-Omni 在一系列 benchmark 上均达到了 state-of-the-art 的性能,在超越以往统一方法的同时,其表现也达到了与专门的专家模型持平甚至更优的水平。除了核心能力外,Audio-Omni 还展现出了卓越的继承能力,包括知识增强型推理生成(knowledge-augmented reasoning generation)、in-context generation 以及音频生成的 zero-shot 跨语言控制,这为迈向通用生成式音频智能(universal generative audio intelligence)指明了一个极具前景的方向。代码、模型和数据集将公开发布于:https://zeyuet.github.io/Audio-Omni。
一句话总结
作者提出了 Audio-Omni,这是第一个端到端框架,通过将冻结的 Multimodal Large Language Model 与可训练的 Diffusion Transformer 相结合,并利用全新的大规模 AudioEdit 数据集,实现了跨声音、音乐和语音领域的音频理解、生成与编辑的统一,从而达到了最先进的性能和多功能的 zero-shot 控制。
核心贡献
- 本文介绍了 Audio-Omni,这是一个统一了声音、音乐和语音领域音频理解、生成与编辑的端到端框架。该架构结合了用于高层推理的冻结 Multimodal Large Language Model,以及用于分离语义和信号特征的可训练 Diffusion Transformer 和混合调节机制。
- 本研究提出了 AudioEdit,这是一个大规模数据集,包含超过一百万个精心策划的指令引导编辑对,旨在解决音频编辑中数据稀缺的问题。
- 实验结果表明,Audio-Omni 在多个基准测试中达到了最先进的性能,在展现出继承能力(如 zero-shot 跨语言控制和知识增强推理)的同时,其能力达到或超过了专门的专家模型。
引言
现代音频处理依赖于专门的理解、生成和编辑模型,这阻碍了这些任务的无缝集成。现有的统一方法通常缺乏端到端优化,或者仅局限于语音或音乐等单一领域,而音频编辑由于缺乏大规模、指令引导的数据集,仍然特别困难。作者利用了一种解耦架构,将用于推理的冻结 Multimodal Large Language Model 与用于高保真合成的可训练 Diffusion Transformer 连接起来。为了实现多功能性能,他们推出了 Audio-Omni,这是第一个通过其全新的大规模 AudioEdit 数据集支持的、统一了通用声音、音乐和语音理解、生成与编辑的端到端框架。
数据集
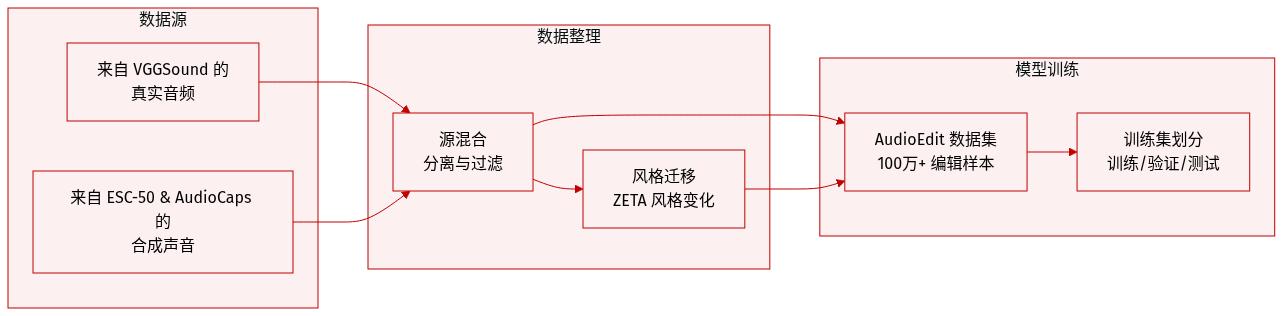
作者推出了 AudioEdit,这是一个包含超过 100 万个样本的大规模数据集,专为指令引导的音频编辑而设计。该数据集通过包含两个主要分支的混合流水线构建:
-
真实数据分支:该分支通过从 VGGSound 数据集中挖掘真实的编辑对来专注于声学保真度。作者使用 Gemini 2.5 Pro 来识别主要声音类别,并使用 SAM-Audio 进行声源分离。这一过程将音频解耦为目标轨道和残差轨道。为了确保高质量,作者应用了多阶段过滤过程:
- 添加、删除和提取任务:从 540,000 个标记样本开始,作者使用 Voice Activity Detection (VAD) 保留了约 347,000 个对,随后进行基于 CLAP 的语义对齐,最终得到约 50,000 个高质量对。
- 风格迁移任务:作者通过使用 Gemini 生成语义相关的关键词来扩展过滤后的目标。在应用 CLAP 过滤后,他们获得了约 500,000 个对。这些对使用 ZETA 进行处理,在保持音高和时间结构的同时转换音频风格,然后将其与残差轨道混合。
-
合成数据分支:该分支使用 Scaper 工具包为添加、删除和提取任务提供规模和多样性。作者通过将 ESC-50 的前景事件混合到 AudioCaps 的 10 秒背景中,以程序化方式生成声景。为了增加复杂度,他们应用了随机参数,包括起始时间、SNR (0 到 3 dB)、音高偏移 (-3 到 +3 个半音) 和时间拉伸因子 (0.8 到 1.2)。
-
数据集使用:生成的 AudioEdit 数据集提供了多样化的任务混合,包括添加、删除、提取和风格迁移,以支持结合真实声学特性和大规模合成多样性的鲁棒模型训练。
方法
作者利用 Rectified Flow 框架作为 Audio-Omni 系统的生成骨干,该框架通过恒定速度场对噪声与数据样本之间的确定性直线轨迹进行建模。这种方法与传统的扩散模型不同,它使用一个常微分方程 (ODE) 定义为 dtdxt=v,其中 v=x1−x0 代表数据样本 x0 与噪声样本 x1∼N(0,I) 之间的速度。沿此路径的解为 xt=(1−t)x0+tx1,其中 t∈[0,1]。训练一个神经网络 vθ(xt,t,c),用于在给定噪声状态 xt、时间 t 和调节信号 c 的条件下预测该速度场。在推理过程中,生成过程通过使用 vθ 的预测值从 t=1 开始反向求解 ODE 来进行,最终输出通过 VAE 解码器进行重建。
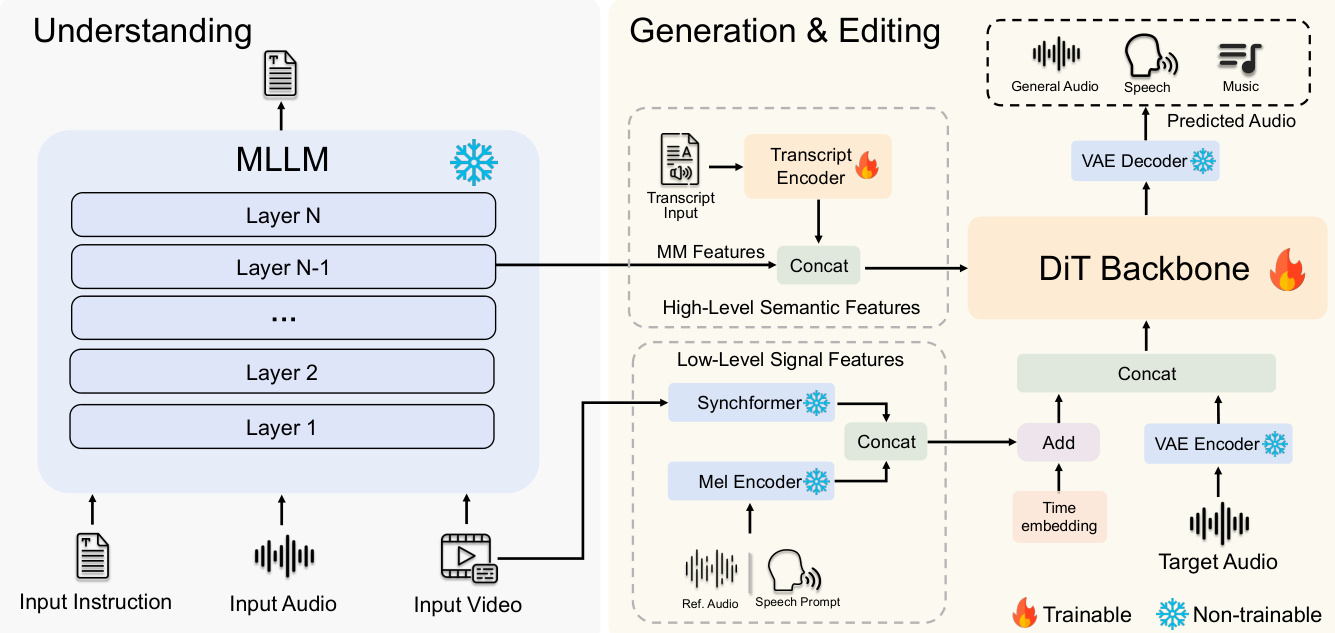
整体框架由两个主要组件组成:一个作为理解核心的冻结多模态大语言模型 (MLLM),以及一个用于音频生成与编辑的可训练 DiT 骨干网络。MLLM 在文本指令、音频波形和视频输入被各自的编码器转换为 token 后对其进行处理。它执行两个关键功能:为理解任务生成文本响应,并从其倒数第二层产生多模态特征表示 Fmm∈RLmm×Dmm,作为生成任务的调节信号。该特征与通过基于 ConvNeXtV2 的 Transcript Encoder 对输入文本进行字符级编码获得的转录特征 Ftrans 相结合,形成高层语义特征流 chigh=Concat(Fmm,Ftrans)。
对于需要精确时间对齐的任务(如编辑和同步),引入了第二个调节流:低层信号特征。该流通过将使用 Mel Encoder 从参考音频或语音提示中提取的 mel 频谱特征 Fmel,与通过预训练 Synchformer 模型从输入视频中获得的同步特征 Fsync 进行拼接来构建,结果为 clow=Concat(Fsync,Fmel)。这两个调节流通过不同的机制注入到 DiT 骨干网络中。高层语义特征通过 cross-attention 作为上下文注入,使模型在整个生成过程中能够关注抽象指令。相比之下,低层信号特征通过逐元素相加与时间嵌入融合,然后与 VAE 编码的噪声音频潜变量 xt 拼接,形成 DiT 的主要输入,从而提供强大的逐帧引导。
训练目标是一个统一的 Rectified Flow 损失,它最小化预测速度 vθ(xt,t,c) 与真实速度 v=x1−x0 之间的均方误差。损失函数定义为:
L=Et∼U(0,1),x0,x1,c[∣∣vθ(xt,t,c)−(x1−x0)∣∣2]其中 t 是从均匀分布中随机采样的时间步,xt=(1−t)x0+tx1 是插值后的潜变量状态,而 c 包含了训练样本的完整调节信号。该目标使模型能够为广泛的音频生成和编辑任务学习单一且统一的表示。
实验
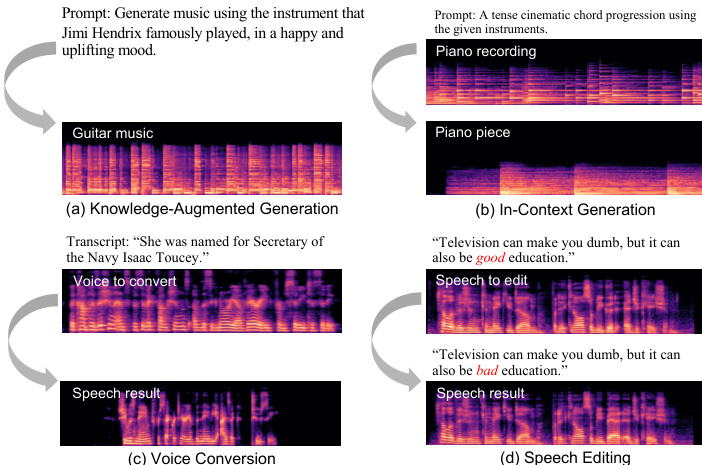
Audio-Omni 通过一套全面的基准测试进行评估,旨在测试其在声音、音乐和语音全频谱上的理解、生成和编辑能力。实验验证了这种解耦架构允许模型从冻结的 MLLM 中继承强大的推理和多语言能力,同时在生成和编辑任务中达到最先进的性能。定性结果进一步展示了涌现的 zero-shot 能力,例如知识增强生成和语音转换,证明了单一统一框架可以作为不同音频领域的通用型 Agent。
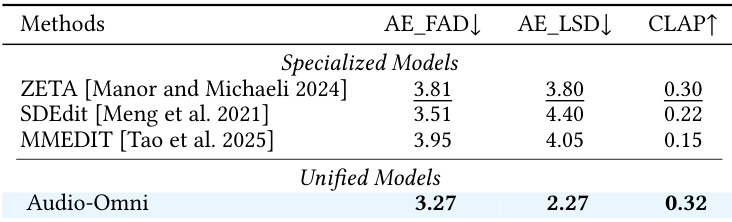
结果显示,与专门模型相比,Audio-Omni 在音频编辑指标上实现了更优越的性能。该模型在保真度和指令遵循方面优于其他模型,展示了在编辑任务中的强大能力。Audio-Omni 在所有编辑指标上均优于专门模型。Audio-Omni 在保真度和指令遵循方面取得了最佳结果。该模型在多个编辑任务中表现出强劲性能。
该表展示了关于数据集组成对音频编辑训练影响的消融研究,比较了不同训练配置下的性能。结果显示,结合合成数据和真实世界数据可以获得最佳的整体性能,混合方法优于单独使用任何一种数据类型。结合合成和真实世界数据可获得最佳的音频编辑性能。仅在真实世界数据上训练的效果优于仅使用合成数据。混合数据方法在所有评估指标上始终优于单一数据配置。
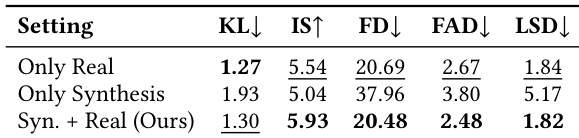
结果展示了多种任务下音频编辑模型的比较,所提出的方法实现了最佳的整体性能。与现有模型相比,Audio-Omni 在所有编辑操作的保真度和质量指标上均表现出更优的结果。Audio-Omni 在编辑任务的平均性能上优于所有基线模型。所提出的方法在 FAD 和 LSD 指标上得分最低,表明具有更高的保真度和质量。Audio-Omni 在所有单个编辑操作中较基线模型表现出持续的改进。

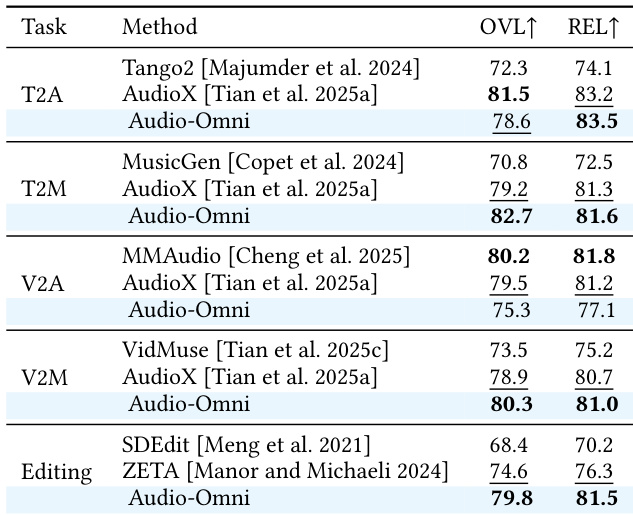
结果显示 Audio-Omni 在多个音频任务中表现强劲,在各种基准测试中始终优于其他统一模型,并达到或超过了专门模型。该框架在理解和生成任务中均表现出优异的结果,突显了其作为综合音频系统的有效性。Audio-Omni 在理解和生成任务中超越了其他统一模型。该模型与专门的专家模型相比取得了具有竞争力的结果。它在包括语音、音乐和声音在内的多种音频领域表现出强劲性能。
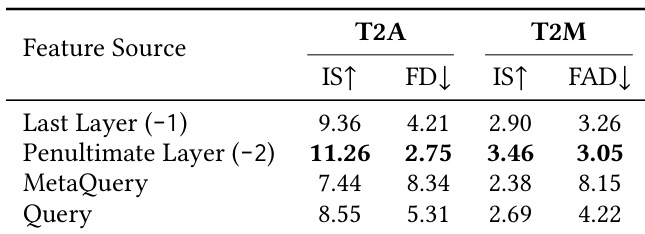
研究比较了来自冻结 MLLM 的不同特征源在音频生成任务中的表现,评估了它们对文本转音频和文本转音乐性能的影响。结果显示,使用倒数第二层的特征在两项任务中始终优于其他方法。使用 MLLM 倒数第二层的特征在文本转音频和文本转音乐任务中均实现了最佳性能。最后一层的特征表现不如倒数第二层,表明其对文本预测存在过度专业化。与直接从倒数第二层进行特征提取相比,MetaQuery 和 Query 等复杂的查询机制会降低性能。
评估表明,Audio-Omni 在各种音频编辑和通用任务中实现了卓越的保真度和指令遵循,通常优于专门模型和现有的统一框架。消融研究显示,结合合成和真实世界数据进行训练可获得最佳结果,而从冻结 MLLM 的倒数第二层提取特征为生成任务提供了最佳性能。总的来说,这些发现突显了所提模型的有效性及其在语音、音乐和声音领域的鲁棒能力。