Command Palette
Search for a command to run...
PROPELLA-1:面向大规模 LLM 数据策展的多属性文档标注
PROPELLA-1:面向大规模 LLM 数据策展的多属性文档标注
Maximilian Idahl Benedikt Droste Björn Plüster Jan Philipp Harries
摘要
自 FineWeb-Edu 发布以来,LLM 预训练的数据清洗(data curation)主要依赖于由小型分类器生成的单一标量质量评分。然而,单一评分往往会将多个质量维度混为一谈,导致无法进行灵活的过滤,且缺乏可解释性。为此,我们推出了 propella-1,这是一系列小型多语言 LLM(参数量分别为 0.6B、1.7B 和 4B),能够针对文本文档的 18 个属性进行标注。这些属性被划分为六大类别:核心内容、分类、质量与价值、受众与用途、安全性与合规性,以及地理相关性。该系列模型支持 57 种语言,并能生成符合预定义 schema 的结构化 JSON 标注。在以顶尖商业 LLM 作为参考标注员的评估中,4B 模型展现出了比体量大得多的通用模型更高的指标一致性(agreement)。我们发布了 propella-annotations,这是一个包含超过 30 亿条文档标注的数据集,涵盖了包括 FineWeb-2、FinePDFs、HPLT 3.0 和 Nemotron-CC 在内的主要预训练语料库。利用这些标注,我们对广泛使用的预训练数据集进行了多维度的成分分析(compositional analysis),揭示了在质量、推理深度和内容构成方面存在的显著差异,而这些差异是单一评分方法无法捕捉到的。目前,所有模型权重和标注数据均已在允许商业用途的宽松许可协议下发布。
一句话总结
作者介绍了 PROPELLA-1,这是一个包含 0.6B、1.7B 和 4B 参数的小型多语言 LLM 家族,用跨 18 个属性和 57 种语言的多属性文档注释替代单个标量分数以生成结构化 JSON,证明 4B 模型在针对前沿商业 LLM 参考注释器时,比大得多的通用模型实现更高的一致性,同时发布了超过三十亿个注释,涵盖 FineWeb-2、FinePDFs、HPLT 3.0 和 Nemotron-CC 等主要预训练语料库,且采用宽松的商业使用许可。
核心贡献
- propella-1 是一个小型多语言 LLM 家族(0.6B、1.7B、4B 参数),用于跨 18 个属性注释文本文档,这些属性组织成六个类别:核心内容、分类、质量与价值、受众与目的、安全与合规性以及地理相关性。这些模型支持 57 种语言,并产生符合预定义模式的结构化 JSON 注释。
- 与作为参考注释器的前沿商业 LLM 相比,4B 参数模型实现了比大得多的通用模型更高的一致性。
- propella-annotations 作为包含超过三十亿个文档注释的数据集发布,涵盖 FineWeb-2、FinePDFs、HPLT 3.0 和 Nemotron-CC 等数据的主要预训练语料库。利用这些注释进行的多维组合分析揭示了单分数方法无法捕捉的质量和推理深度的实质性差异。
引言
数据质量作为大语言模型预训练中的高杠杆因素,严格的策划可以比原始 token 数量产生乘数效率增益。现有管道通常依赖单个标量分数,这些分数混淆了不同的质量维度,且往往缺乏多语言支持。作者介绍了 PROPELLA-1,这是一个小型多语言模型家族,支持跨 18 个不同质量维度进行结构化多属性注释。该框架支持 57 种语言,并发布超过三十亿个文档注释,以促进 LLM 训练的灵活、可组合的过滤策略。
数据集
-
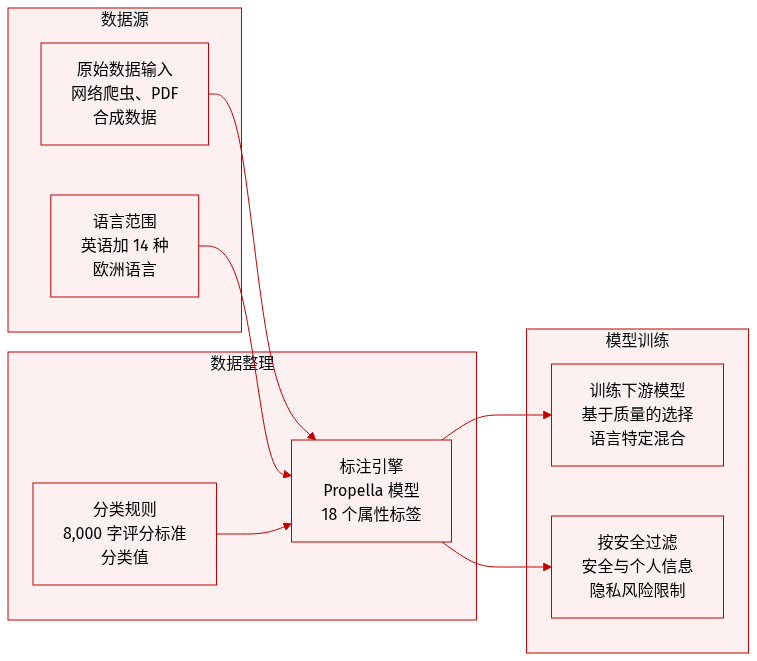
数据集组成与来源
- 作者发布了 propella-annotations,这是一个托管在 Hugging Face Hub 上的超过三十亿个文档注释的数据集,采用 CC-BY-4.0 许可。
- 数据涵盖多种预训练来源,包括网络爬虫(FineWeb-2、HPLT 3.0、Nemotron-CC、German Commons)、提取的 PDF(FinePDFs)、百科全书文本(finewiki)和合成指令遵循数据(SYNTH)。
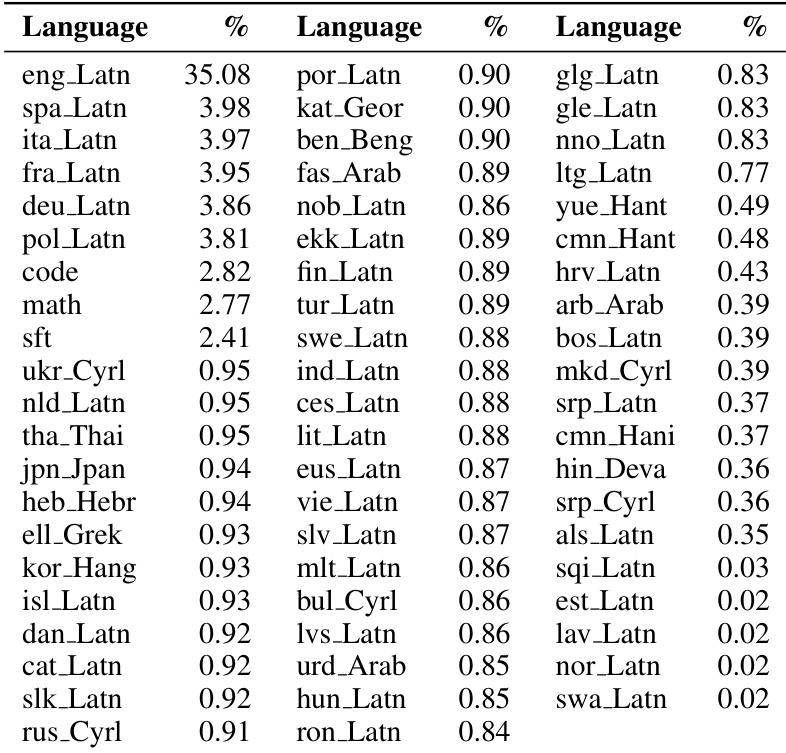
- 尽管注释模型支持 57 种语言,但当前公开版本涵盖英语和 14 种欧洲语言,其中德语、西班牙语、法语和意大利语的量最大。
-
注释结构与属性
- 每条记录包含 18 个结构化分类属性,组织成六个类别,如内容质量、安全和商业部门。
- 注释通过源数据集中的文档标识符进行键控,以便在不重新分发原始文本的情况下直接连接。
- 模式包括商业部门和技术内容的多选字段,以及质量和完整性的序数评级。
- 一份全面的 8000 字评分标准指导分类过程,为每个属性值提供详细的定义和示例。
-
处理与模型训练
- 所有注释均使用 propella-1-4b 模型通过 3,936 个 A100 GPU 上的分布式推理生成。
- 底层注释模型在涵盖 57 种语言的多样化样本上进行了训练,其中约 35% 为英语内容。
- 为了解决 API 内容过滤器限制,训练数据的一小部分被手动注释。
- 推理管道扩展到在大约 3.5 小时内注释来自 FineWeb-2 的约 5 亿个文档。
-
使用与应用
- 作者使用该数据集分析不同语言和来源的内容概况,揭示了质量和商业偏见的显著差异。
- 实践者可以使用元数据构建灵活的过滤谓词,例如同时选择具有高教育价值和低商业偏见的文档。
- 结构化标签支持特定语言的过滤策略,而不是在所有语言上应用统一的质量阈值。
- 安全和 PII 注释允许进行合规感知过滤,同时通过仅存储分类标签而非源文本来限制隐私风险。
方法
propella-1 家族引入了从单个标量质量分数到结构化多维注释的方法论转变。该系统采用一系列小型多语言大语言模型来跨 18 个属性注释文本文档。这些属性组织成六个类别,涵盖核心内容、分类、质量与价值、受众与目的、安全与合规性以及地理相关性。
底层架构由三个基于 Qwen-3 框架的模型组成,大小分别为 0.6B、1.7B 和 4B 参数。作者选择了仅解码器模型而非基于编码器的分类器,以利用原生处理长达 64K 上下文窗口的长文档。这一设计选择还使得所有 18 个注释都能作为结构化 JSON 输出生成,从而消除了每属性分类器训练的需求。通过微调,模型内化了详细的注释指南,以紧凑的提示实现强大的性能。
提示设计利用了一个约 800 tokens 的系统提示,列出了所有具有枚举值和简要描述的属性。这显著短于训练数据创建期间使用的完整注释提示。模型支持 57 种语言,并产生符合预定义模式的结构化 JSON 注释。
评估逻辑涵盖几个关键维度。信息密度衡量有价值信息与冗余的比率。内容范围从密集(每句话都增加新信息)到空(内容主要由重复主导)。推理深度使用思维轨迹信号进行评估,如逐步结构和假设检验。自动化启发式计算词汇线索,如 therefore 或 thus,以及结构线索,如证明块。阈值设定确定分类,其中 ≥2 个结构线索或 ≥5 个词汇线索表示至少为解释性内容。
安全评估指南优先考虑背景和意图。根据受众的不同,敏感话题的医疗或教育讨论可能是合适的。区域识别依赖于主要指标,包括地理引用、机构引用和文化标记。语言背景提供线索,但并非决定性因素。
实验
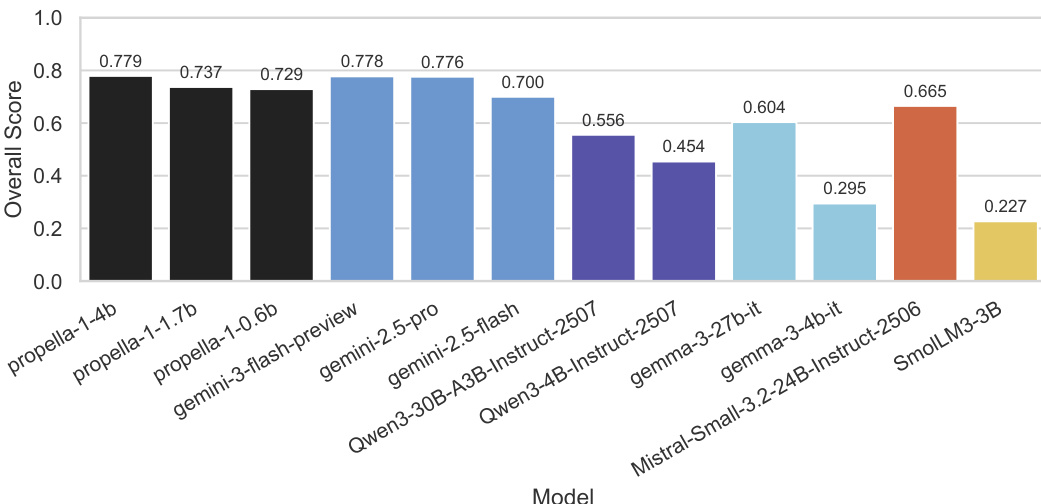
评估将专用的 Propella-1 模型与通用基线进行比较,使用由 Gemini-3-Pro 注释的测试集作为高质量参考标准。实验验证了小型微调模型可以匹配显著更大模型的注释质量,同时通过优化精度和结构化输出保持高推理效率。此外,定性案例研究表明,多属性注释揭示了单分数质量分类器忽略的细微数据特征和异质性。
该表比较了两种 propella-1 模型变体在 bf16 和 fp8 推理精度下的注释质量。结果表明,fp8 精度保持了与 bf16 相当的性能,在不同模型大小之间的两种设置中仅观察到微小差异。较大的 4B 模型在 fp8 精度下比 bf16 精度下实现略好的性能。较小的 1.7B 模型在切换到 fp8 时表现出可忽略的性能下降。两种精度模式之间的总体分数差异在两种模型大小中都很小。

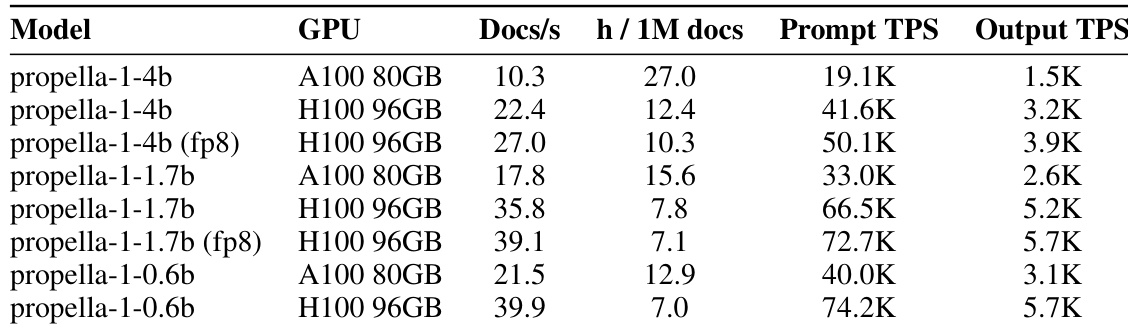
作者评估了 propella-1 模型家族在不同硬件配置和精度下的服务基础设施和吞吐量。结果表明,与 A100 GPU 和标准精度相比,更新的 H100 GPU 和 fp8 精度显著提高了处理速度。此外,基准测试显示系统受 prefill 限制,提示处理速度远超输出生成速率。对于所有模型变体,H100 GPU 提供比 A100 GPU 更高的吞吐量。启用 fp8 精度进一步加速了 H100 硬件上的推理速度。推理性能由提示处理主导,提示 TPS 显著高于输出 TPS。
该表概述了注释数据集中的语言分布,确认了 57 种不同语言的覆盖范围。英语是主要语言,代表数据的绝大多数,而其余语言表现出长尾分布,代表性显著较低。英语是代表性最强的语言,占据数据集的最大份额。数据集包括跨越多种书写系统的多样化 57 种语言。许多语言出现在长尾中,代表性最小,占总量的可忽略部分。
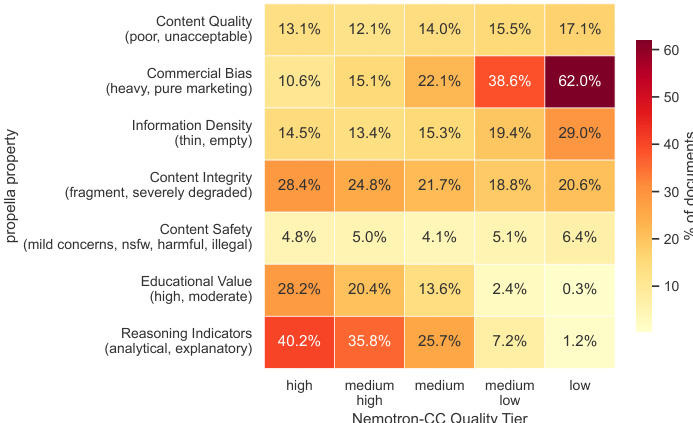
作者审核了五个 Nemotron-CC 质量层级中的文档,以使用 propella-1 注释检查多维质量概况。分析显示,虽然更高层级通常表现出更好的内容质量,但高层级仍包含大量具有特定问题的文档,如商业偏见和碎片化完整性,这是单分数分类无法捕捉的。较低层级的文档表现出比高层级显著更高的商业偏见和更低的教育价值。推理指标在高层级中普遍存在,但在较低质量层级中急剧减少。令人惊讶的是,高质量层级包含所有层级中最高的碎片化内容完整性问题率。
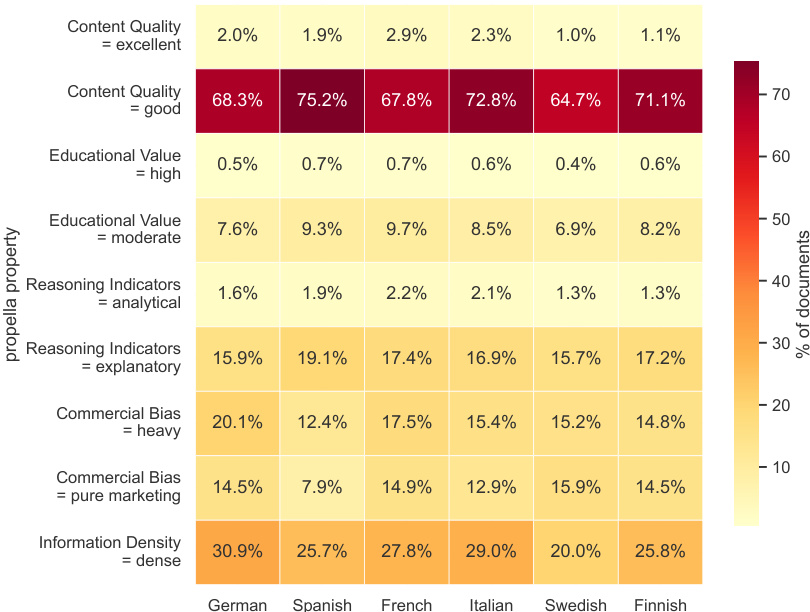
热力图可视化了跨六种语言的注释文档属性分布,证明了系统的多语言一致性。数据显示,“良好”内容质量是压倒性多数类别,而其他属性如商业偏见和信息密度在不同语言中显示出不同的分布模式。被评为“良好”的内容质量在所有语言中都是主导类别,显著超过“优秀”评级。被分类为“密集”的信息密度代表的文档份额大于中等教育价值。被标记为“重”的商业偏见通常比被标记为“纯营销”的偏见更普遍。
实验评估了 propella-1 模型家族在不同精度和硬件配置下的注释质量和服务效率。结果表明,fp8 精度保持了与 bf16 相当的性能,同时在 H100 GPU 上显著提高了吞吐量,注释数据集涵盖 57 种语言,其中英语是主要类别。此外,质量审核显示,较高的数据层级通常表现出更好的内容,但仍包含商业偏见和碎片化完整性等单分数分类无法捕捉的特定问题,而一致性检查确认良好内容质量是跨语言的主导类别。