HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
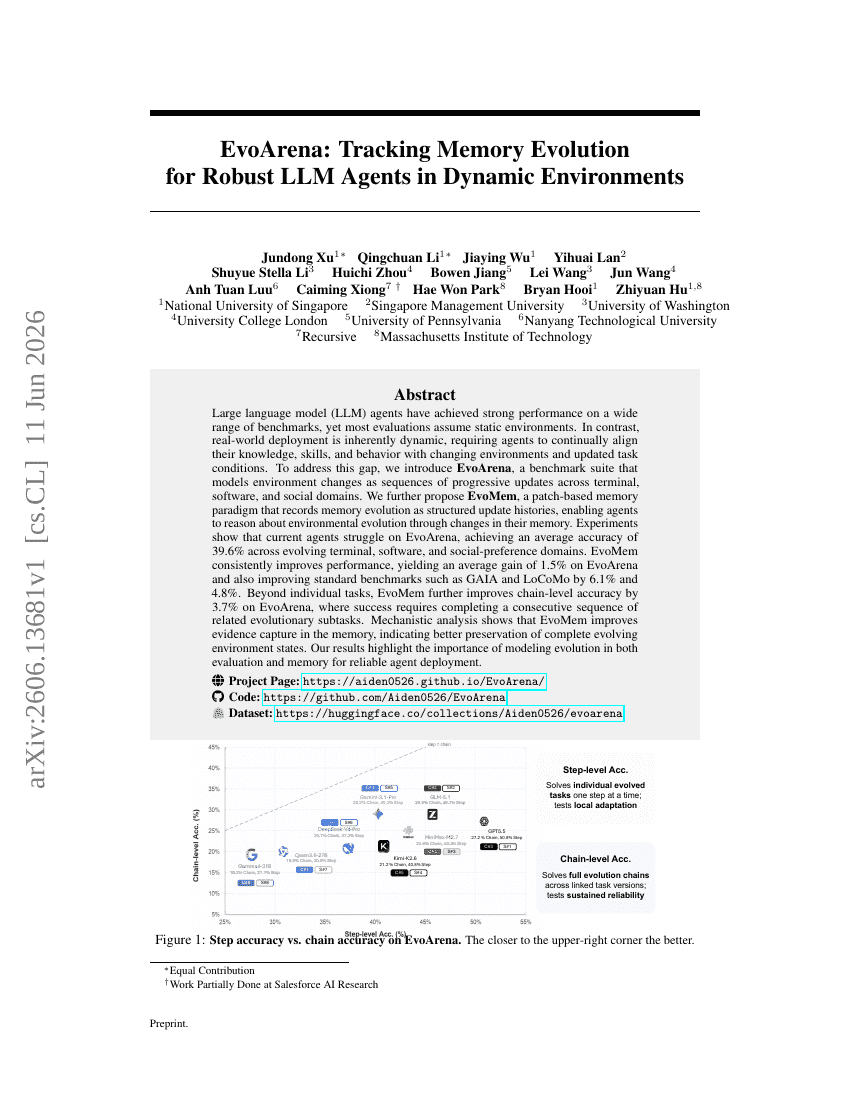
EvoArena:追踪动态环境中鲁棒 LLM Agents 的记忆演化

Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型












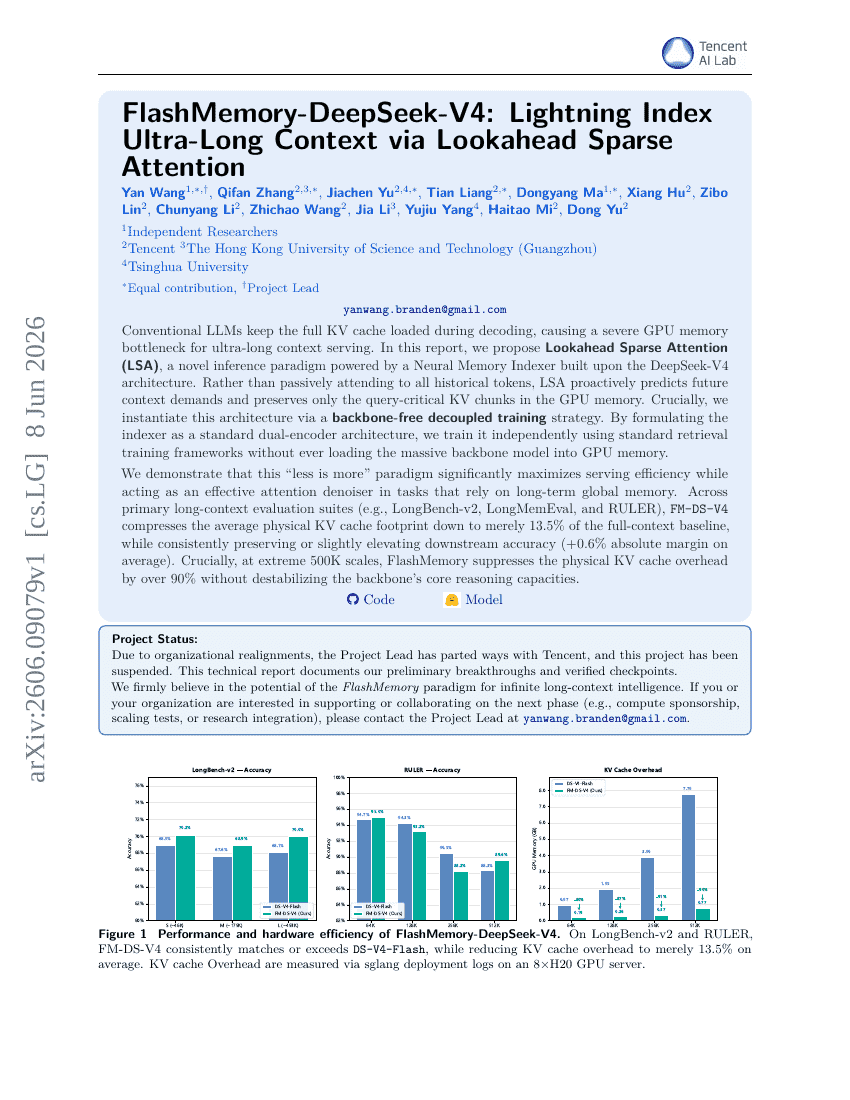













EvoArena:追踪动态环境中鲁棒 LLM Agents 的记忆演化
Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型
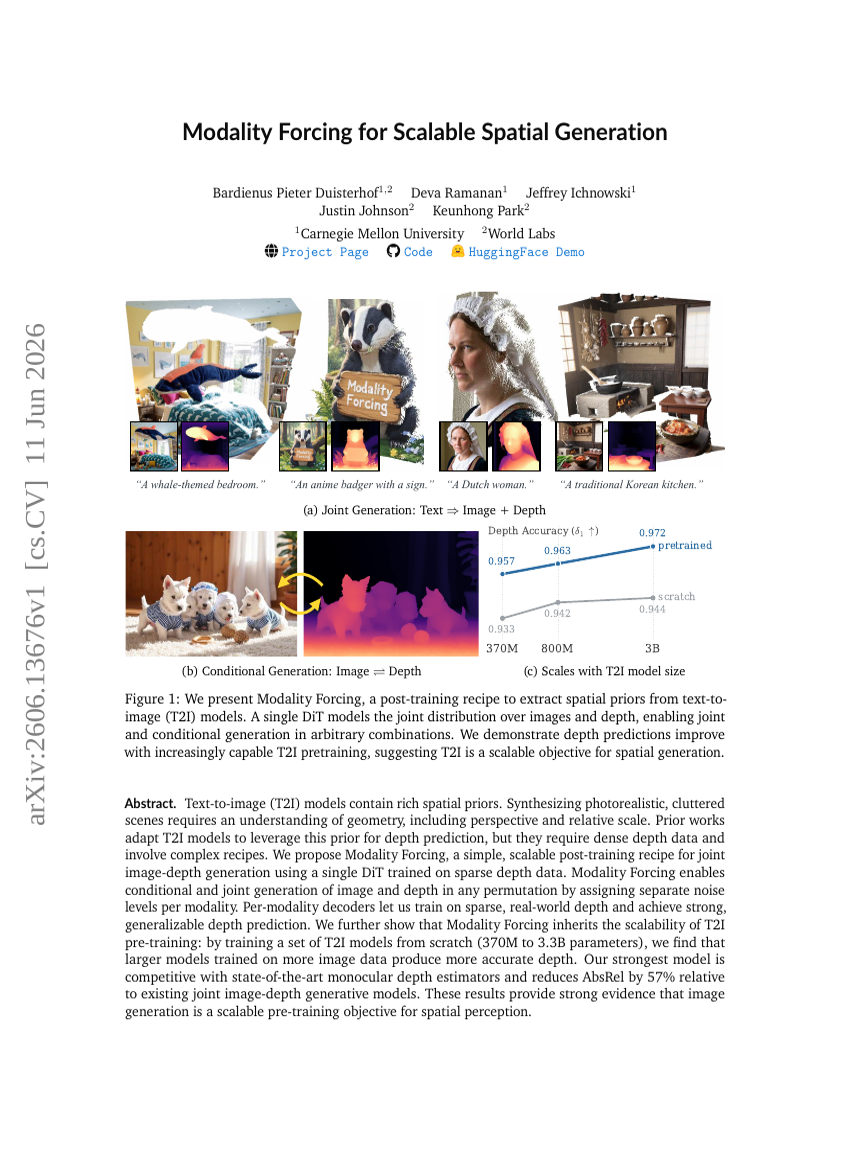
模态强制用于可扩展的空间生成
从AGI到ASI
世界追踪:超越可视范围的生成式像素对齐几何
正则化 f-散度核检验
无需循环机制进行循环网络的预训练
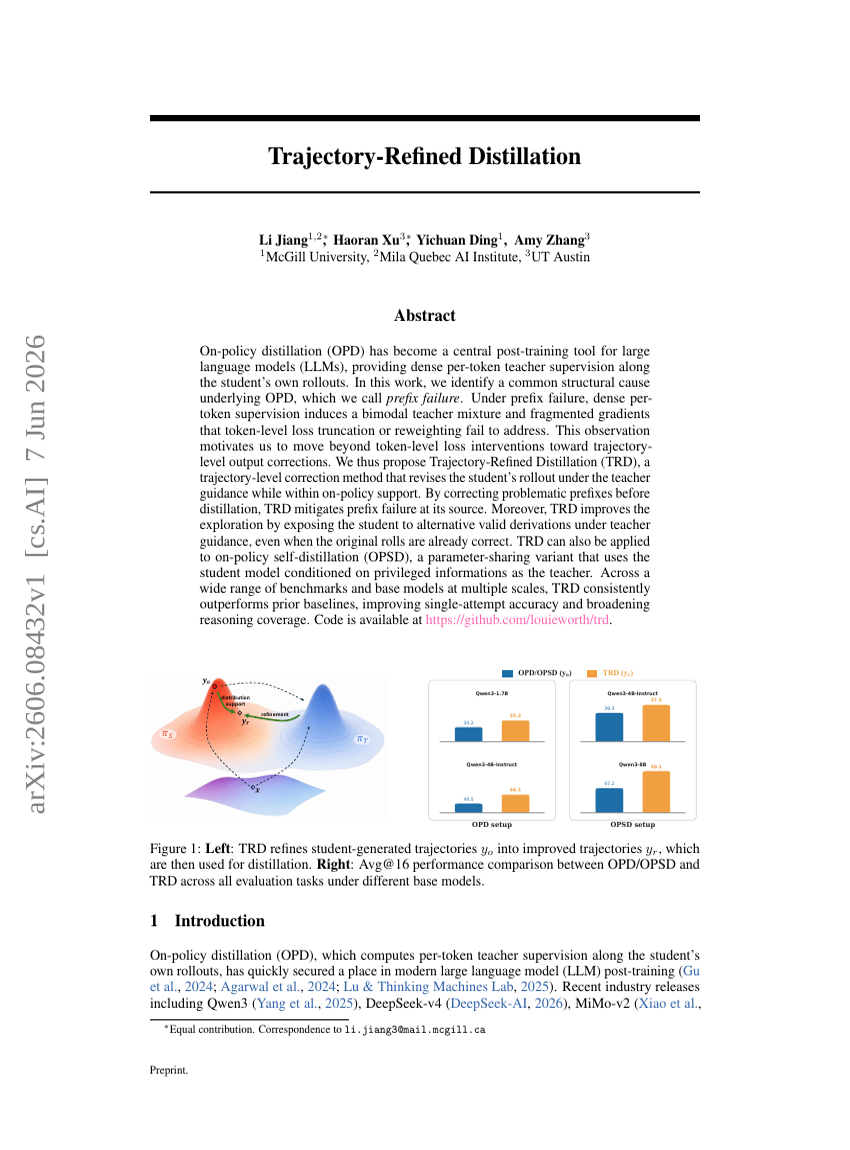
轨迹精炼蒸馏
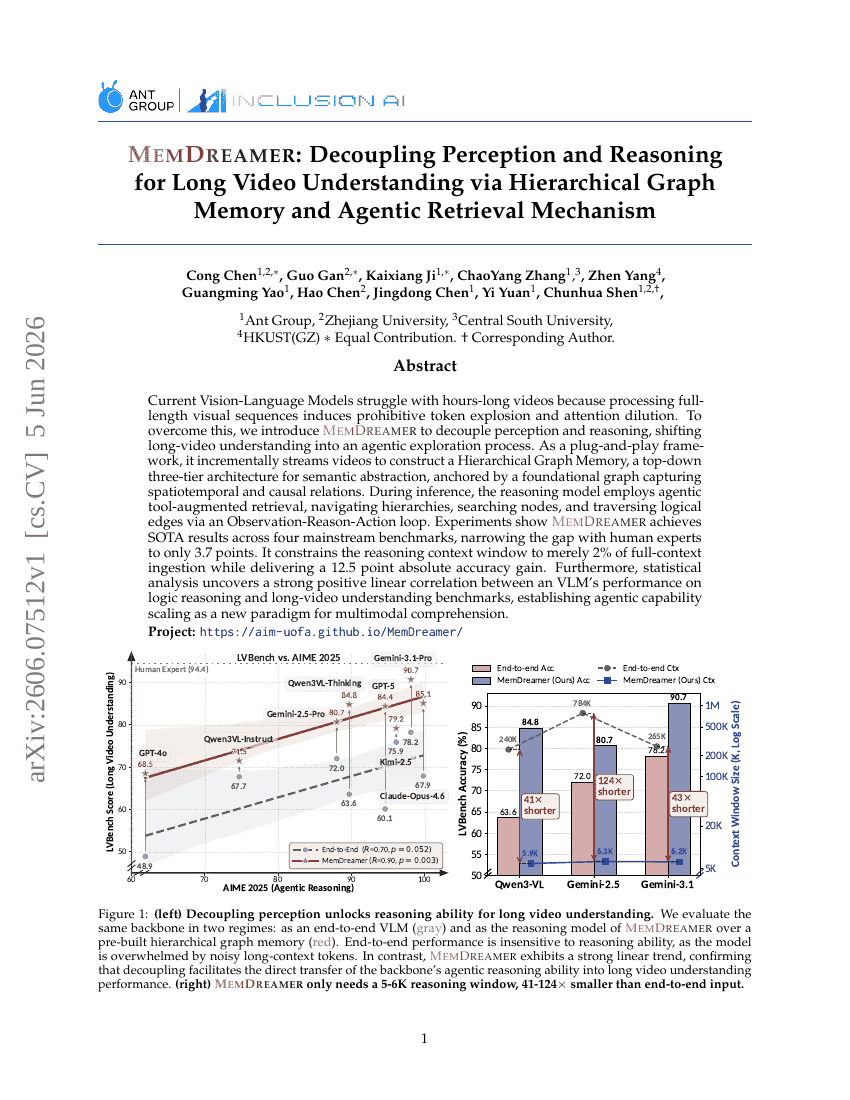
MemDreamer:通过分层图记忆与智能体检索机制解耦感知与推理用于长视频理解
SearchSwarm:迈向智能体大语言模型中的委托智能,用于长周期深度研究
回溯式驾驭优化:通过轨迹展开上的自我偏好改进 LLM Agents
角色-Agent:通过双角色演化自举LLM Agents
ABot-Earth 0.5:生成式3D地球模型
Kwai Keye-VL-2.0 技术报告
TESSERA:用于地球表示与分析的表面光谱时间嵌入
如果大型语言模型(LLMs)具有类似人类的属性,那么《帝国时代 II》亦然。
最后一篇人类撰写的论文:原生智能体研究产物
FlashMemory-DeepSeek-V4:基于前瞻稀疏注意力的超长上下文闪电索引
潜在技能:从上下文文本技能到权重内潜在技能,用于大语言模型 Agents
CoVEBench:视频编辑模型能否处理复杂指令?
用于视频世界模型的潜在空间记忆
关于在线策略蒸馏的几何
SWE-Explore:基准测试编码 Agents 如何探索代码库
VoxCPM2 技术报告
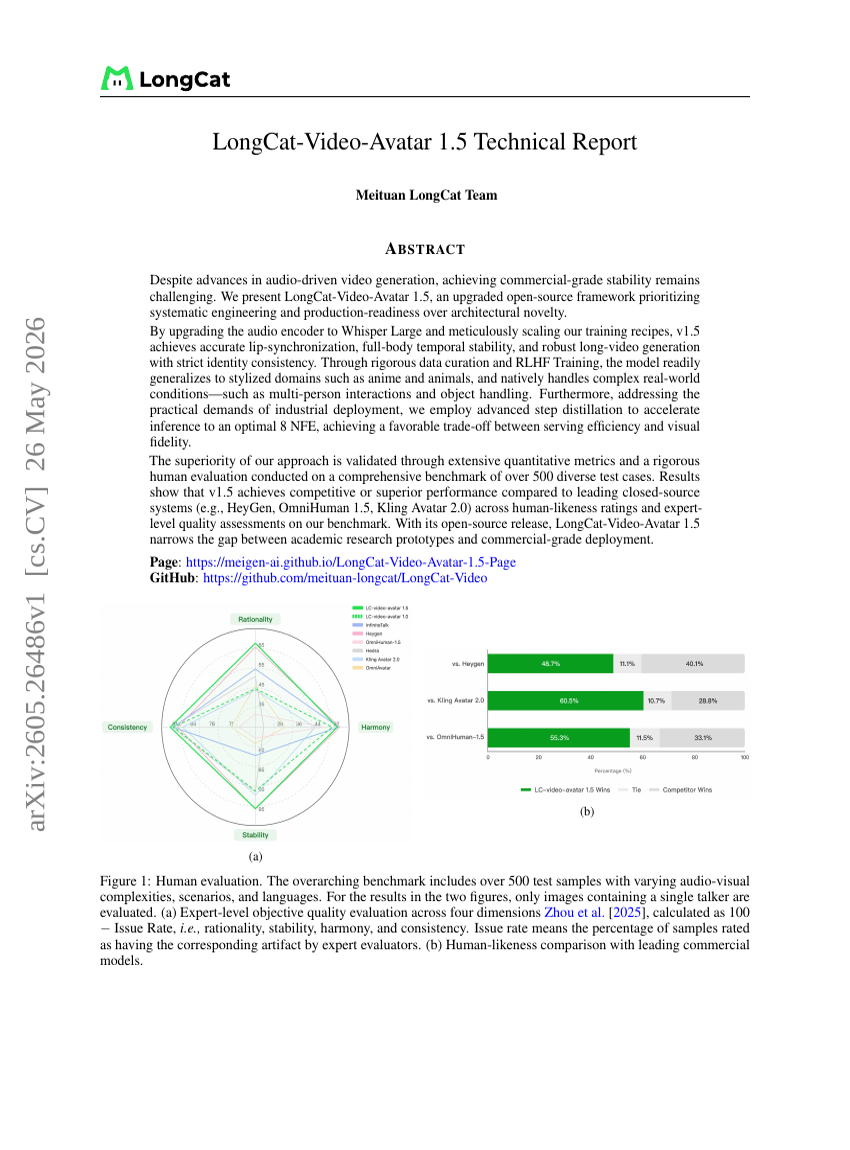
LongCat-Video-Avatar 1.5 技术报告
ChartNet:一个用于稳健图表理解的大规模高质量多模态数据集
ACL-Verbatim:面向研究的可信问答
超越静态对话:基准测试真实、异构且不断演变的长期记忆
软件工程的终结:AI智能体如何从根本上重构软件范式
为何大模型学得更多:容量、干扰与罕见任务保留的影响
当工具失效时:LLM Agent 动态重规划与异常恢复的基准测试
基于分解视觉代理的直接3D感知物体插入
模态强制用于可扩展的空间生成
从AGI到ASI
世界追踪:超越可视范围的生成式像素对齐几何
正则化 f-散度核检验
无需循环机制进行循环网络的预训练
轨迹精炼蒸馏
MemDreamer:通过分层图记忆与智能体检索机制解耦感知与推理用于长视频理解
SearchSwarm:迈向智能体大语言模型中的委托智能,用于长周期深度研究
回溯式驾驭优化:通过轨迹展开上的自我偏好改进 LLM Agents
角色-Agent:通过双角色演化自举LLM Agents
ABot-Earth 0.5:生成式3D地球模型
Kwai Keye-VL-2.0 技术报告
TESSERA:用于地球表示与分析的表面光谱时间嵌入
如果大型语言模型(LLMs)具有类似人类的属性,那么《帝国时代 II》亦然。
最后一篇人类撰写的论文:原生智能体研究产物
FlashMemory-DeepSeek-V4:基于前瞻稀疏注意力的超长上下文闪电索引
潜在技能:从上下文文本技能到权重内潜在技能,用于大语言模型 Agents
CoVEBench:视频编辑模型能否处理复杂指令?
用于视频世界模型的潜在空间记忆
关于在线策略蒸馏的几何
SWE-Explore:基准测试编码 Agents 如何探索代码库
VoxCPM2 技术报告
LongCat-Video-Avatar 1.5 技术报告
ChartNet:一个用于稳健图表理解的大规模高质量多模态数据集
ACL-Verbatim:面向研究的可信问答
超越静态对话:基准测试真实、异构且不断演变的长期记忆
软件工程的终结:AI智能体如何从根本上重构软件范式
为何大模型学得更多:容量、干扰与罕见任务保留的影响
当工具失效时:LLM Agent 动态重规划与异常恢复的基准测试
基于分解视觉代理的直接3D感知物体插入