Command Palette
Search for a command to run...
ChartNet:一个用于稳健图表理解的大规模高质量多模态数据集
ChartNet:一个用于稳健图表理解的大规模高质量多模态数据集
摘要
理解图表要求模型能够联合推理几何视觉模式、结构化数值数据以及自然语言,而当前的视觉-语言模型(VLMs)在这一能力上仍显局限。为此,我们推出了 ChartNet,这是一个高质量、百万级规模的 multimodal dataset(多模态数据集),旨在推动图表解读与推理技术的发展。ChartNet 采用了一种新颖的代码引导合成流程(code-guided synthesis pipeline),生成了涵盖 24 种图表类型和 6 种绘图库的 150 万种多样化的图表样本。每个样本包含五个对齐的组件:绘图代码、渲染后的图表图像、数据表、自然语言摘要以及带有推理过程的问答内容,从而提供细粒度的跨模态对齐。为了捕捉图表理解的各个层面,ChartNet 还包含了专门的数据子集,涵盖人工标注数据、真实世界数据、安全性测试以及 grounding(指代消解或定位对齐)任务。此外,严格的质控流水线确保了图表表示在视觉保真度、语义准确性以及多样性方面的高标准。在 ChartNet 上进行微调 consistently(持续)提升了各项 benchmark(基准测试)上的表现,证明了其作为大规模多模态模型监督信号的有效性。作为同类中最大的开源数据集,ChartNet 旨在支持开发具备稳健且可泛化的数据可视化理解能力的 foundation models(基础模型)。
一句话总结
ChartNet 是一个百万规模、高质量的多模态数据集,旨在通过一种新颖的代码引导合成管道来推进图表解读,该管道生成 150 万个涵盖 24 种图表类型和 6 种绘图库的多样化样本,包含五个对齐组件,包括绘图代码、渲染后的图表图像、数据表、自然语言摘要以及带有推理的问答,同时严格的质量过滤确保视觉保真度和语义准确性,从而在微调后持续提高视觉语言模型在各项基准测试中的性能。
核心贡献
- 这项工作引入了 ChartNet,一个高质量、百万规模的多模态数据集,旨在通过新颖的代码引导合成管道推进图表解读和推理。该数据集生成了涵盖 24 种图表类型和 6 种绘图库的 150 万个多样化图表样本。
- 每个样本由五个对齐组件组成,提供细粒度的跨模态对齐,而专门子集涵盖人工标注数据和安全性。严格的质量过滤管道确保这些多样化图表表示的视觉保真度和语义准确性。
- 在 ChartNet 上微调持续改进各项基准测试结果,证明其作为多模态模型大规模监督的实用性。实验显示在不同模型规模和架构上均取得一致增益,通常超越更大的开源系统甚至专有前沿模型如 GPT-4o。
引言
视觉语言模型需要高保真度的监督来准确解读数据可视化,然而当前的合成数据集通常在图表类型和模态的多样性方面存在局限。现有方法通常依赖图像空间生成,或未能完全将视觉输出与底层结构化数据和推理轨迹对齐。为了解决这一瓶颈,作者提出了 ChartNet,一个通过代码引导管道生成的百万规模多模态数据集,确保视觉保真度和语义正确性。通过发布超过 150 万个包含图像、绘图代码和 CSV 数据的对齐元组,他们使视觉语言模型能够从仅仅描述图表转变为理解其编码的结构化信息。
数据集
ChartNet 数据集描述
- 数据集组成: 作者介绍了 ChartNet,一个包含 150 万个合成样本的高质量多模态数据集。每个实例对齐五个组件:图表图像、绘图代码、数据表、自然语言摘要和基于推理的问答对。
- 关键子集:
- 核心合成数据: 源自 TinyChart 的 150,000 张种子图像,通过代码引导增强扩展以覆盖 24 种图表类型和 6 种绘图库。
- 人工标注数据: 包含 96,643 张由领域专家验证的合成图表,以确保语义准确性和高质量标注。
- 真实世界图表: 包括来自世界银行和皮尤研究中心等来源的 30,000 张图表,经过可解释性和版权合规性过滤。
- 定位数据: 提供几何感知标注,边界框从绘图代码中提取,并通过基于熵的方法进行过滤。
- 安全数据: 由 7,000 个训练样本和 600 个测试样本组成,包含针对敏感主题的对抗性提示,以提高模型鲁棒性。
- 处理管道:
- 合成: 视觉语言模型从图像中重构代码,随后由 LLM 迭代重写以生成多样化变体。
- 质量控制: 执行的脚本与渲染后的图像配对,同时 VLM 过滤掉具有视觉缺陷的样本,如文本重叠或标签裁剪。
- 元数据构建: 表格数据和定位描述使用代码上下文生成,而思维链推理轨迹使用 Vision-R1 框架生成。
- 模型训练中的使用:
- 该数据集用于微调多模态模型,以增强图表解读和推理能力。
- 在 ChartNet 上微调展示了跨基准测试的一致改进,使模型能够超越更大的专有系统。
方法
这种方法的核心方法论见解是,可执行的绘图代码充当数据可视化的结构化中间表示。作者引入了一个用于代码引导合成图表生成的自动化管道,该管道在两个主要阶段运行:图表重构和迭代增强。
如下面的框架图所示,该过程始于有限的种子图表图像数据集。视觉语言模型 (VLM) 分析种子图表和特定提示,以生成近似重构原始可视化的 Python 代码。此代码包括数据定义和使用 pandas 和 plotly 等库的绘图指令。

一旦初始代码生成并验证,该管道利用代码大型语言模型执行迭代增强。通过提供指定多样化修改的新提示,如更改图表类型或数据分布,模型生成增强代码。然后执行此代码以生成新的、视觉上独特的图表。作者使用 pixtral-large-instruct-2411 进行图表到代码的重构和质量过滤阶段,而 gpt-oss-120b 用于代码引导的图表增强阶段。此设置允许以高吞吐量生成超过一百万个注释数据点。
此迭代过程的输出是从单个种子派生的多样化合成图表集合。如下面的合成图表可视化所示,该管道成功生成了各种图表类型,包括条形图、箱线图、热力图、雷达图和树状图。这种多样性确保生成的数据集涵盖广泛的视觉编码和数据分布。
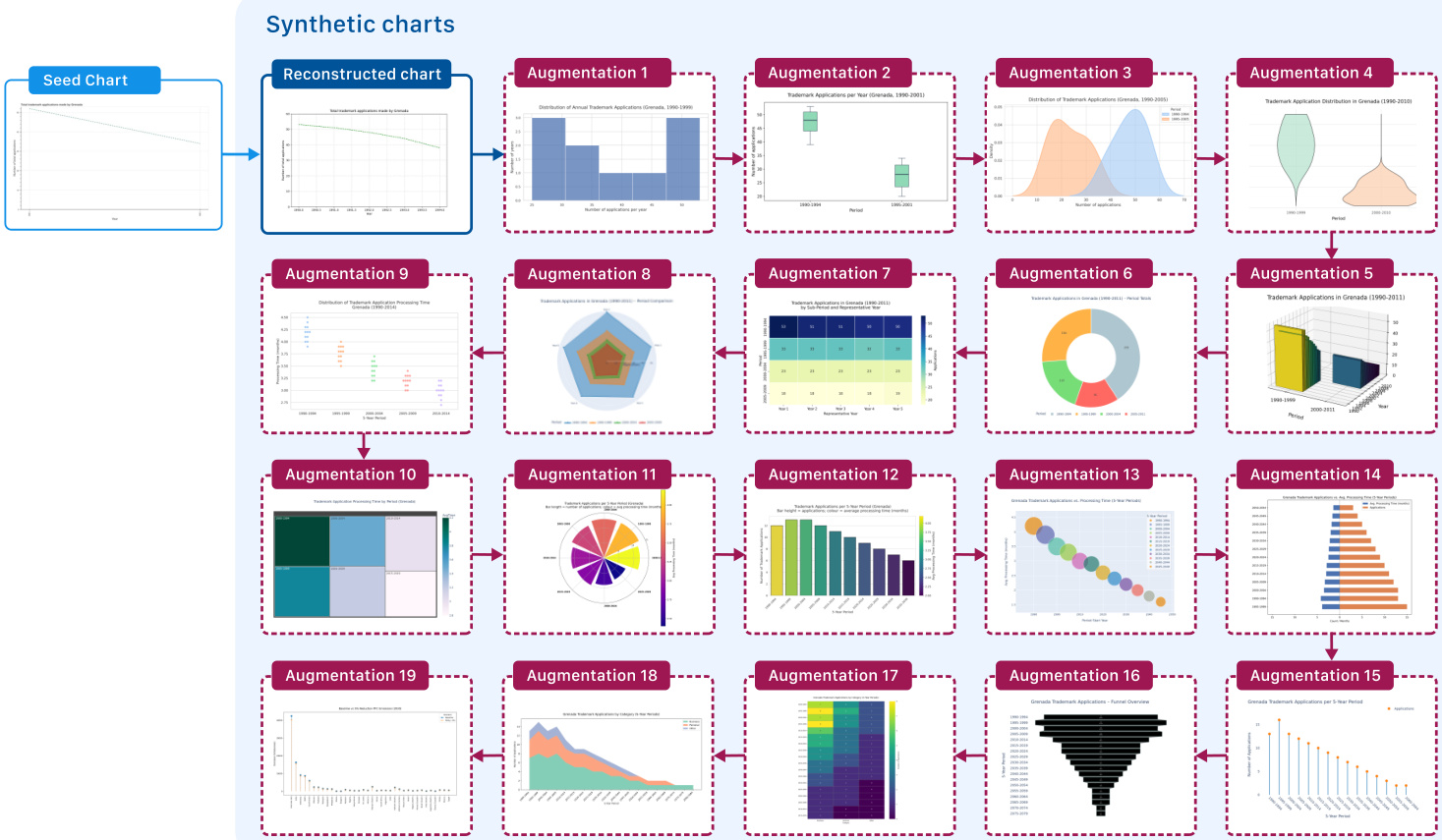
除了视觉生成外,该框架还包括一个多阶段提示管道以生成长篇幅思维链推理轨迹。此过程涉及提出复杂问题、创建结构化计划和标题,以及推导明确的推理步骤。应用模态桥接步骤以使推理可供仅语言模型使用,随后使用 GPT-OSS 生成详细的 CoT 轨迹。这种全面的方法将视觉内容与逻辑推理对齐,为训练和评估提供丰富的监督。
实验
该研究在 ChartNet 数据集上训练了不同规模的视觉语言模型,以评估在图表重构、数据提取、摘要和推理任务方面的改进。微调带来了一致的性能提升,使较小的模型能够超越更大的现成对应模型和 GPT-4o,突显了高质量多模态监督相对于单纯模型扩展的价值。此外,该研究通过展示 GPT-4o 判断与复杂数据提取任务上人工标注之间的强一致性,验证了自动化评估的可靠性。
作者评估了 ChartNet 训练在真实世界公开基准测试上的泛化性,用于图表摘要和代码生成。结果表明,与基础版本相比,在 ChartNet 上微调持续导致所有模型规模的性能大幅提升。在 ChartNet 上微调在所有测试的模型规模上带来一致的性能改进,从超紧凑到中型模型。Granite-Vision 模型在微调后在摘要和代码生成任务中均显示出显著改进。即使是经过 ChartNet 数据集训练的最小模型变体,在真实世界基准测试上也获得了实质性的能力。
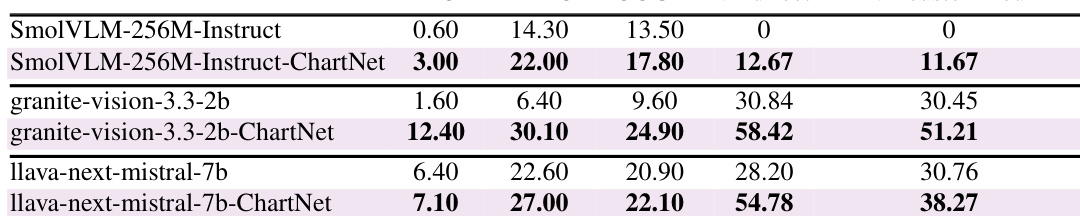
该表比较了开源、专用和专有模型在图表理解任务上的基线性能,包括重构、数据提取、摘要和问答。专有模型在代码执行和视觉重构方面表现出强大的能力,而较小的开源模型显示出竞争性的数据保真度。专用图表模型在复杂推理任务方面表现出优于通用大型语言模型的性能。专有模型在图表重构中实现最高的执行率和视觉相似度。开源模型在代码生成和数据提取方面显示出优于专有基线的数据保真度。专用图表模型在复杂推理任务如带有 CoT 的图表问答中领先。
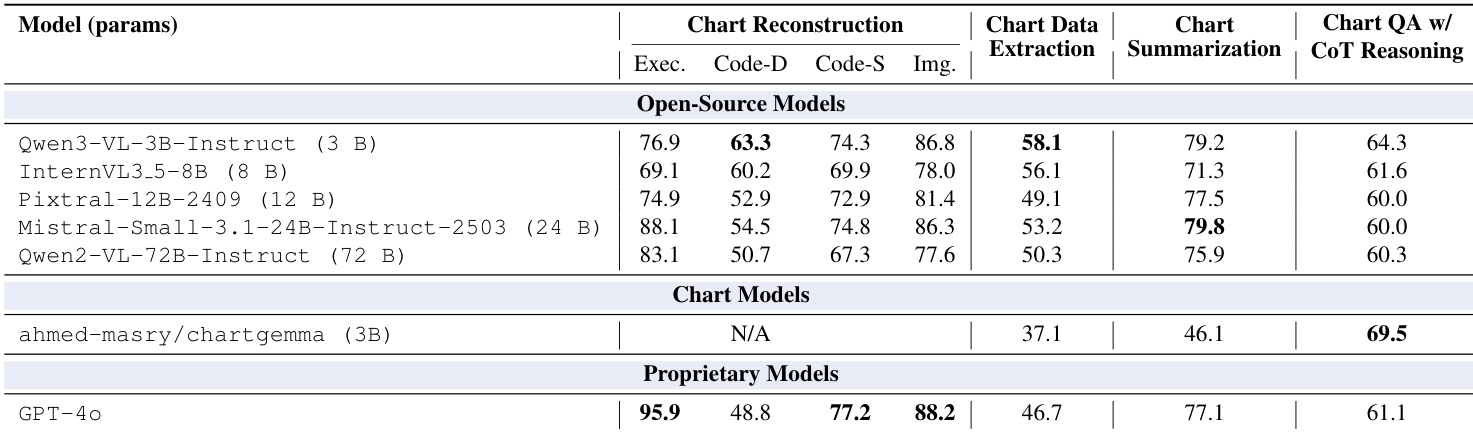
作者评估了各种视觉语言模型,以证明 ChartNet 数据集在增强图表理解能力方面的有效性。结果表明,无论模型规模如何,监督微调在所有图表理解任务上均产生大幅且一致的性能提升。即使最初缺乏重构能力的超紧凑模型也获得了功能性技能,而较大的模型在数据提取和摘要方面实现了显著更高的准确性。在 ChartNet 上微调持续改进模型在图表重构、数据提取、摘要和推理任务上的性能。超紧凑模型在训练后获得功能性图表重构能力,而较大的模型在视觉对齐和代码生成方面达到高准确性水平。改进幅度与规模无关,表明对于图表解读,高质量多模态监督比模型规模更为关键。
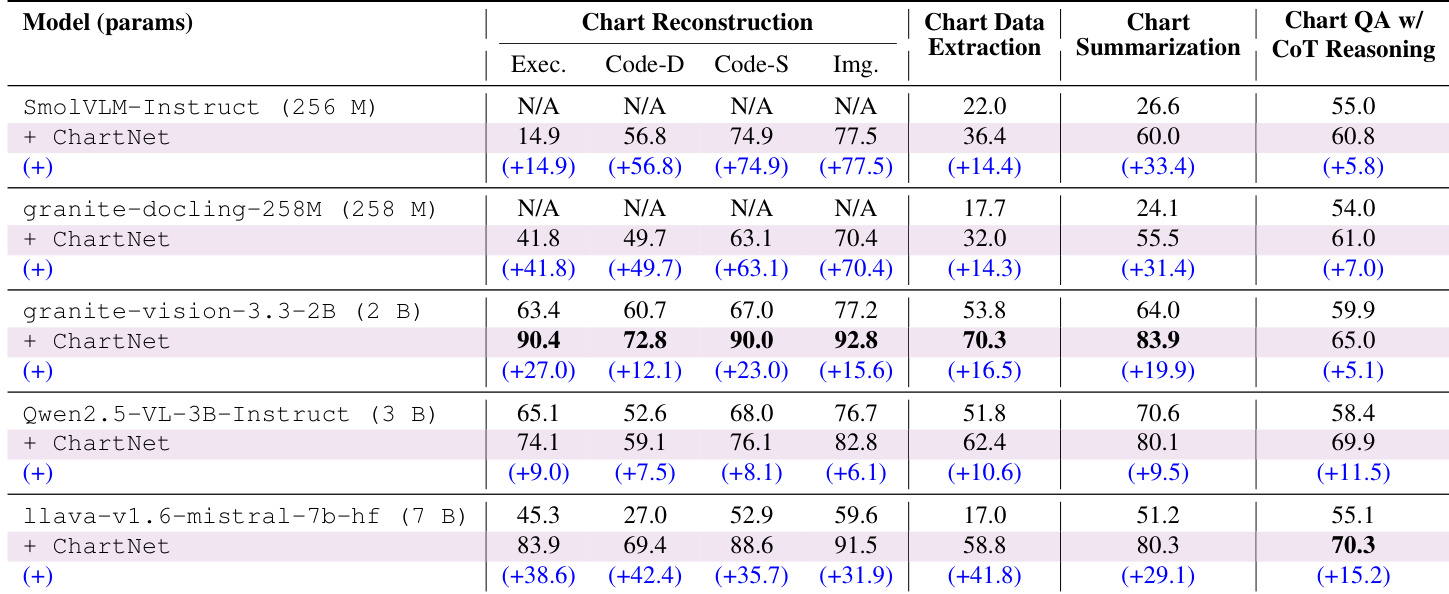
作者评估了 ChartNet 训练在真实世界基准测试上的泛化性,同时比较了专有、开源和专用模型之间的基线性能。在该数据集上的监督微调在所有模型规模上产生一致的性能改进,使即使是超紧凑变体也能获得功能性图表重构能力。虽然专有模型在视觉重构方面表现出色,专用模型在复杂推理方面优于通用模型,但研究结果最终表明,对于图表解读,高质量多模态监督比模型规模更为关键。