Command Palette
Search for a command to run...
SearchSwarm:迈向智能体大语言模型中的委托智能,用于长周期深度研究
SearchSwarm:迈向智能体大语言模型中的委托智能,用于长周期深度研究
Pu Ning Quan Chen Kun Tao Xinyu Tang Tianshu Wang Qianggang Cao Xinyu Kong Zujie Wen Zhiqiang Zhang Jun Zhou
摘要
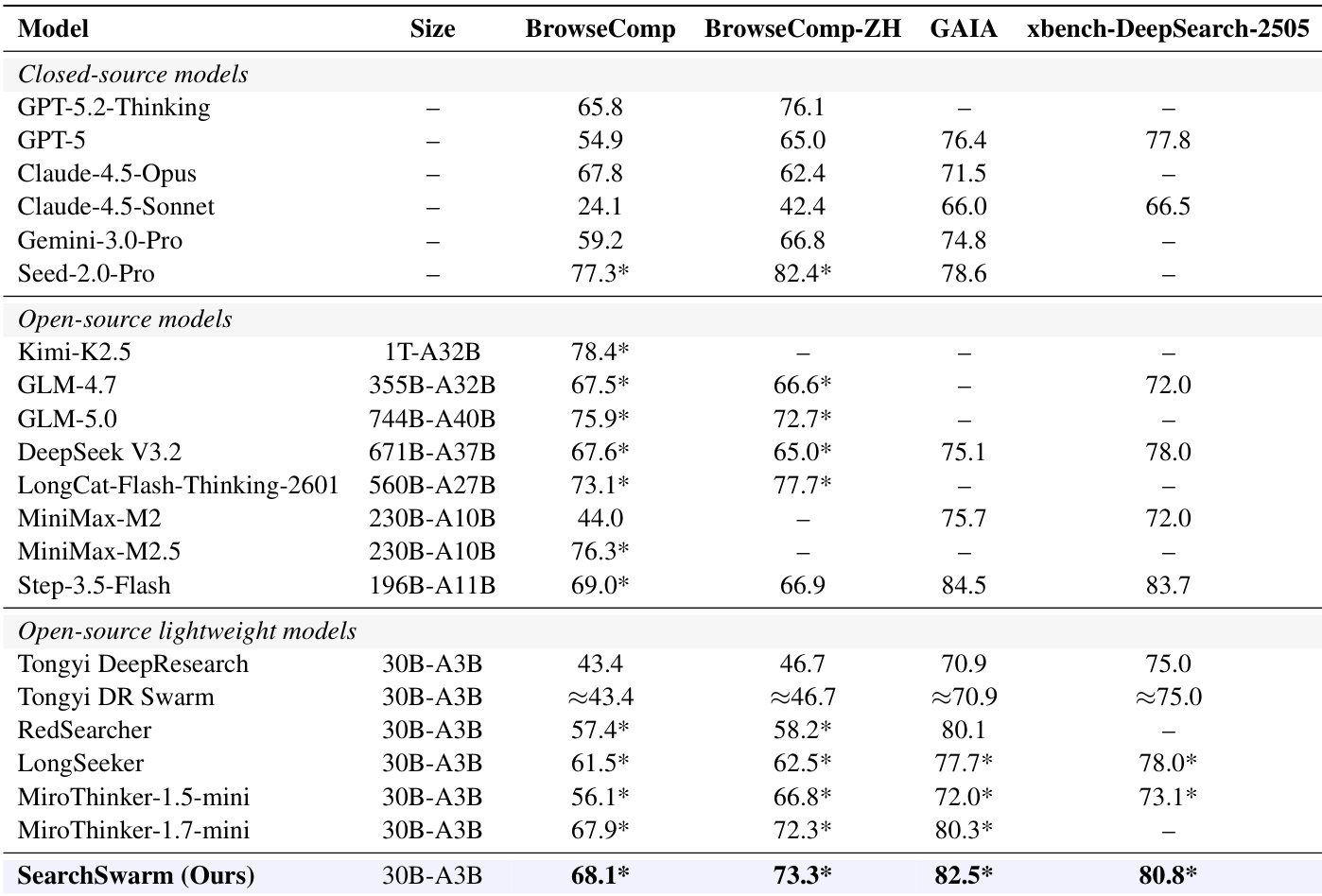
大型语言模型日益被期望处理复杂的、长周期的现实世界任务,此类任务的上下文需求可能无限增长,但模型的上下文窗口本质上仍是有限的。近期研究探索了一种范式,其中主 agent 将任务分解并将子任务分派给 subagents,后者仅执行并返回摘要结果,从而节省主 agent 的上下文预算。然而,要有效执行该过程需要具备委派智能:即分解复杂任务、判断何时及何事进行委派,并将返回结果整合至当前工作流的能力。此类能力的训练数据在自然文本中极为稀缺,据我们所知,如何合成此类数据并训练模型以习得该能力,在开源社区中仍鲜有探索。为弥补这一空白,我们开展了一项针对深度研究的初步探索,该任务是一种具有代表性的长周期 agent 任务。具体而言,我们设计了一套引导框架,用于引导模型进行高质量的任务分解与委派,同时约束 subagents 规范地返回结果,以支持主 agent 的工作流。由引导框架生成的轨迹自然地编码了正确的委派决策,我们将其作为监督微调数据,以将委派智能内化至模型权重中。我们最终得到的模型 SearchSwarm-30B-A3B 在 BrowseComp 上得分 68.1,在 BrowseComp-ZH 上得分 73.3,取得了同等规模模型中的最佳成绩。我们将开源我们的引导框架、模型权重及训练数据,以促进后续研究。
一句话总结
SearchSwarm-30B-A3B 是一款基于 harness 生成的轨迹进行监督微调训练的大模型,旨在将委派智能内化于长周期深度研究中,在 BrowseComp 上取得 68.1 分,在 BrowseComp-ZH 上取得 73.3 分,均为同规模模型中的最佳成绩。
核心贡献
- 专用的执行 harness 通过引导任务分解、subagent 简报以及基于引用的结果整合,构建了 multi-agent 工作流,同时限制 subagent 仅返回总结性输出。该架构将 main agent 与原始工具响应隔离,有效保护了有限的上下文容量,使其专注于迭代探索。
- harness 生成的轨迹被提取并格式化为监督微调数据,从而将委派智能直接内化至模型权重中。该数据合成流程解决了开源训练语料库中自然委派示例稀缺的问题。
- 最终生成的 SearchSwarm-30B-A3B 模型在 BrowseComp 和 BrowseComp-ZH 上均取得了同规模模型中的领先性能。评估结果进一步表明,训练所得的委派模式能够有效泛化至 single-agent 设置与开放式研究任务。
引言
大型语言模型正日益被部署为自主 agent,用于执行深度研究等复杂且长周期的任务,在此类任务中,信息需求迅速超出有限的上下文窗口限制。这一瓶颈使得高效的上下文管理成为维持模型性能与可扩展性的关键。尽管主动委派架构为被动摘要技术提供了一种极具潜力的替代方案,但开源社区仍缺乏完整的训练方案,且自然文本中极少包含教授委派智能所需的显式 multi-agent 协调数据。为弥补这一空白,作者利用自定义推理 harness 引导 main agent 完成结构化任务分解与详细的 subagent 简报,随后将这些成功轨迹转化为监督微调数据。该过程将委派智能直接内化至模型权重中,最终产出 SearchSwarm-30B-A3B。该模型在同等规模模型中取得了领先结果,同时作者完全开源了 harness、训练数据与模型权重,以供后续研究使用。
数据集

- 数据集构成与来源: 作者通过在开源 RedSearcher 和 OpenSeeker 数据集中选取查询词,执行深度研究任务来构建训练语料库。系统记录了完整的执行轨迹,涵盖 chain-of-thought 推理、工具调用及环境反馈。
- 子集详情与过滤规则: 数据收集遵循两种配置。第一种配置运行单一模型同时担任 main agent 与 subagent,保留来自两个角色的路径。第二种配置将较强的 main agent 与较弱的 subagent 配对,仅保留 main agent 轨迹,以促进更紧密的任务分解与验证。过滤规则仅在 main agent 路径得出正确最终答案时予以保留,且 subagent 路径仅在与其配对的主轨迹正确时才被保留。作者还对过短的 subagent 片段进行了下采样,并丢弃包含重复工具调用、幻觉引用或通过 Python 解释器进行网页抓取等工具误用的样本。
- 训练用途与处理: 两种配置下的轨迹被混合为单一训练集。作者采用严格的环境掩码机制,基于下一个 token 预测对基础模型进行微调。损失函数仅针对模型生成的输出进行计算,所有环境返回结果均被掩码处理,以防止模型记忆外部反馈。
- 上下文管理与裁剪策略: main agent 的上下文窗口上限设定为 128K tokens,subagent 窗口上限为 64K tokens。当轨迹接近这些限制时,系统会提示模型立即生成最终答案。作者并未丢弃这些序列,而是予以保留,使模型在推理阶段的强制作答条件下仍能保持良好性能。此外,subagent 的调度指令经过精心设计,仅包含已确立的上下文信息,确保其专注于特定子问题,避免重复已解决的内容。
方法
SearchSwarm 框架遵循“主分发、子执行”范式,由中央 main agent 通过向独立 subagent 委派子任务来协调复杂的研究任务。该架构旨在通过结构化委派实现高效的上下文管理与高质量推理。main agent 配备了包含搜索、访问、Python 解释器与 Google Scholar 在内的完整工具集,遵循 ReAct 框架,通过一系列思考、行动与观测与环境交互。在每一步中,agent 对当前状态进行推理,选择动作,并处理产生的观测结果。当识别出子任务时,main agent 会调用 call_sub_agent 工具,向 subagent 发送简报。该简报包含子任务描述及相关上下文信息(如任务相关性、前期发现与未解决问题),确保 subagent 具备充分的背景知识以提供有效贡献。
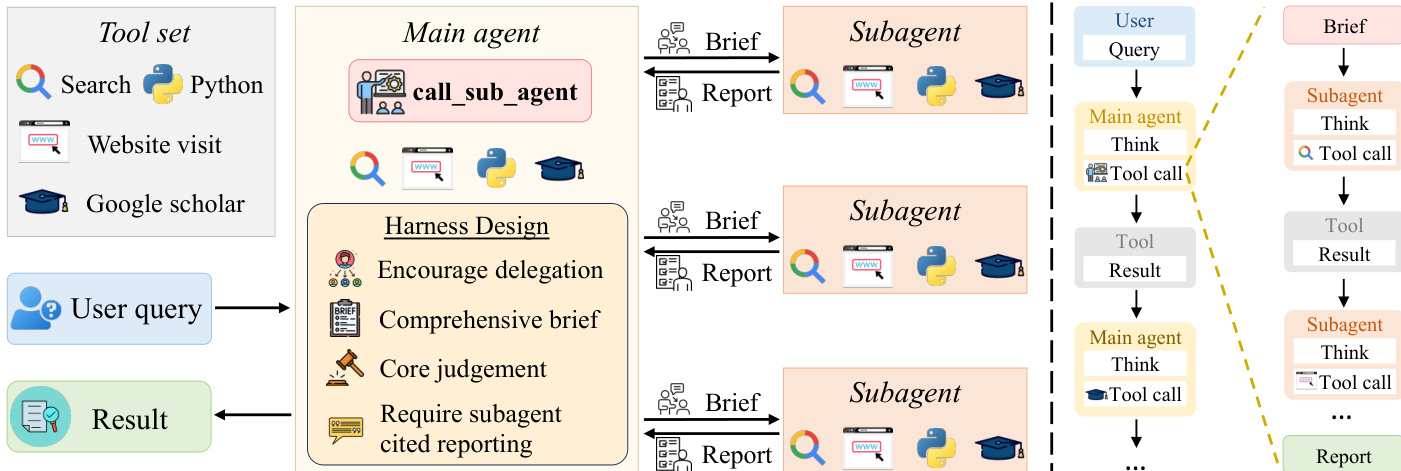
如图所示,main agent 与 subagent 在独立的上下文中运行,subagent 仅接收简报并返回精简报告。这种隔离机制确保 main agent 的上下文保持清晰,保留其进行高层协调与判断的能力。subagent 配备与 main agent 相同的工具集,开展多轮交互以收集证据并生成报告。报告要求对每项重要声明均添加行内引用,使 main agent 能够在不接触 subagent 中间步骤的情况下验证研究结果的可靠性。随后,main agent 将报告整合至自身的推理过程中,持续进行思考与行动的迭代循环,直至生成最终答案。该方法通过将子任务执行有效压缩为单一报告,使系统能够处理长周期任务,从而在保持可追溯性与连贯性的同时控制上下文增长。
实验
实验在多项长周期与开放式研究基准上评估了双 agent 委派框架,并将其与主流闭源、开源及轻量级模型进行对比。结果表明,所提出的 harness 与训练数据显著提升了委派智能,使紧凑模型能够媲美甚至超越规模大得多的前沿系统。消融实验与跨架构测试证实,该框架能有效激发结构化信息收集与综合能力,同时验证了底层训练数据的高质量。此外,所习得的能力能够稳健地泛化至 single-agent 配置与开放式研究任务,凸显了该方法的通用性及模型内化的问题分解技能。
作者提出了一款模型,该模型在长周期研究任务中于轻量级模型中取得领先性能,并对大规模模型展现出强劲的竞争力。模型的委派机制实现了高效的上下文管理,推动多项基准测试成绩提升,且训练数据与 harness 设计有助于在委派场景之外实现泛化。SearchSwarm 在多项基准测试中优于同规模其他模型,并取得了与更大规模模型相竞争的结果。模型的委派机制实现了高效的上下文管理,main agent 主要负责协调 subagent 调用以收集信息。训练数据与 harness 设计带来了泛化优势,即使在缺乏委派工具的场景下也能提升性能。
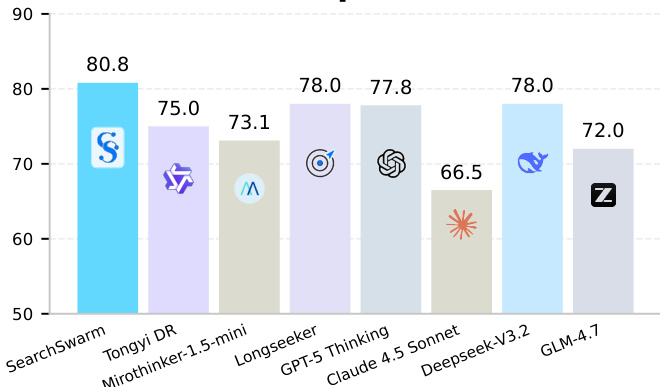
作者在多项基准测试中将 SearchSwarm 与多种闭源、开源及轻量级开源模型进行对比。结果显示,SearchSwarm 在同规模模型中取得领先性能,并对更大规模模型展现出强劲竞争力,尤其在长周期研究任务中表现突出。该模型在开放式深度研究场景中亦表现出良好的泛化能力,在未进行显式训练的情况下即超越基础模型并取得优异成绩。SearchSwarm 在轻量级模型中位列前茅,并在关键基准测试中超越多款更大规模模型。该模型对开放式研究任务展现出强大的泛化能力,较基础模型实现显著提升。main agent 高度依赖委派,利用 subagent 工具收集信息,同时直接处理验证与计算任务。
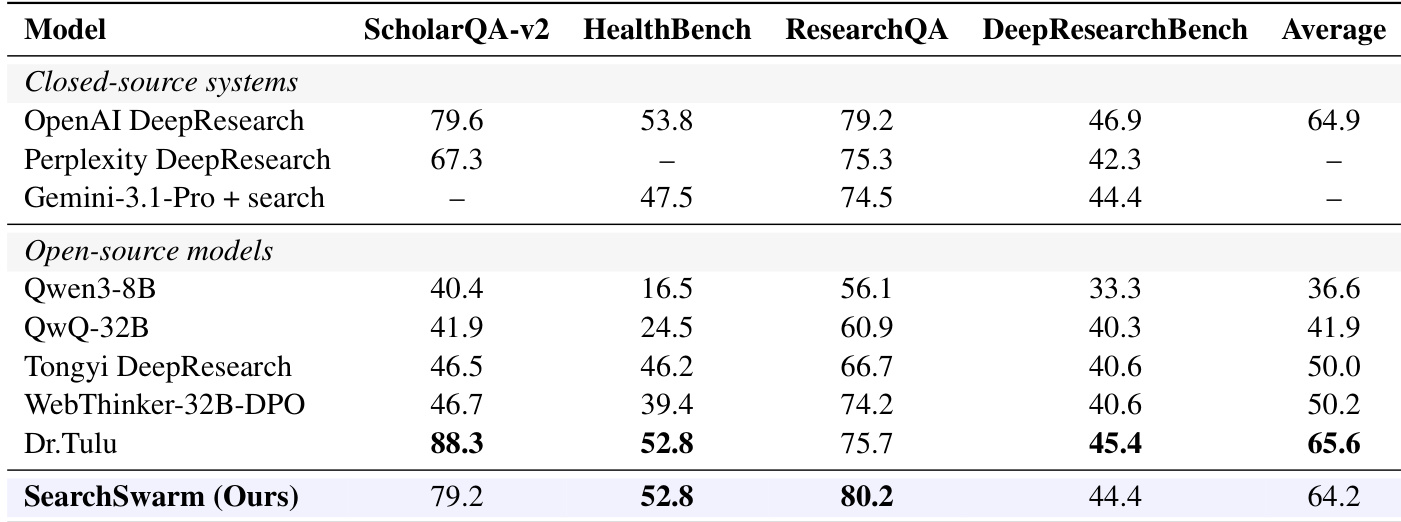
作者在开放式深度研究基准上评估了 SearchSwarm,并将其性能与闭源及开源系统进行对比。结果表明,SearchSwarm 取得了具有竞争力的性能,尤其在 ResearchQA 与 ScholarQA-v2 上表现优异,在开源模型中平均性能排名第二。该模型在所有基准测试中均优于基础模型,展现出对长文本综合任务的强大泛化能力。SearchSwarm 在开放式深度研究基准的开源模型中平均性能位列第二。SearchSwarm 在所有评估基准上均显著超越基础模型,表现出对长文本综合任务的强泛化能力。SearchSwarm 在 ResearchQA 与 ScholarQA-v2 上取得顶尖性能,超越多款强劲的开源模型。
作者在多项基准测试中评估了 SearchSwarm,并将其与各类开源及闭源模型进行对比。结果表明,SearchSwarm 在 30B-A3B 规模模型中取得顶尖性能,并能与规模大得多的模型相抗衡,表明有效的委派智能能够支撑长周期研究任务中的优异表现。模型的训练数据与 harness 设计在促进智能委派以及将能力泛化至 single-agent 与开放式研究场景方面效果显著。SearchSwarm 在所有基准测试中均取得 30B-A3B 规模模型的领先性能。SearchSwarm 能与规模显著更大的模型竞争,证明委派智能可克服模型体积限制以维持强劲性能。训练数据与 harness 设计促进了高效委派,并成功泛化至 single-agent 与开放式研究场景。
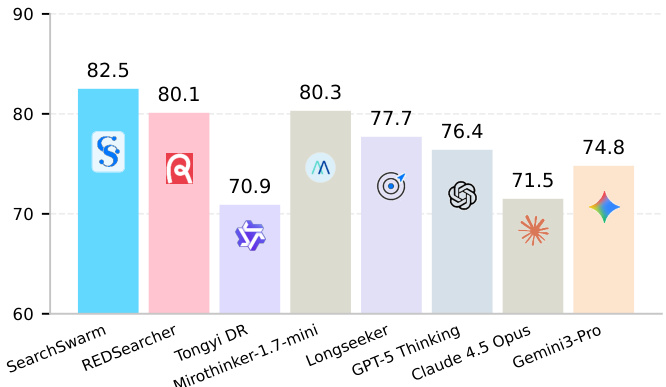
作者在多项长周期与开放式研究基准上评估 SearchSwarm,将其与闭源、开源及同规模模型进行对比,以验证其竞争效率与泛化能力。结果表明,该模型在自身参数量级内取得领先性能,同时与规模大得多的系统保持高度竞争力,证明有效的委派智能可弥补体积限制。实验进一步验证,委派机制通过协调 subagent 的信息检索成功管理上下文,持续推动性能超越基础架构。此外,定制化的训练数据与 harness 设计在促进智能委派方面效果显著,无需针对特定任务的显式训练,即可实现向 single-agent 与开放式研究场景的稳健泛化。