Command Palette
Search for a command to run...
CoVEBench:视频编辑模型能否处理复杂指令?
CoVEBench:视频编辑模型能否处理复杂指令?
Jiangtao Wu Jiaming Wang Yiwen He Yuanxing Zhang Shihao Li Dunyuan Liu Xuedong Zhao Jialu Chen Zekun Moore Wang Jiaheng Liu
摘要
尽管近期的文本引导视频编辑模型在基础任务(如风格迁移、物体插入)方面表现出色,但实际用户需求具有高度的组合性。单个提示词往往需要执行多个相互关联的编辑操作,例如修改主体、动作和摄像机视角,同时严格保留无关的时空内容。现有基准测试严重受限于孤立编辑与粗糙的全局指标,无法有效诊断模型处理此类复杂工作流的能力。为弥补这一空白,我们提出了CoVEBench,这是一个组合式视频编辑基准测试,包含416个精心筛选的源视频、626条多点编辑指令以及9,990项细粒度检查清单条目。该基准测试涵盖多种编辑维度,通过多模态大语言模型(MLLM)判定的指令遵循度与视频保真度,结合视频质量的自动化指标对模型进行评估。大量实验表明,组合式编辑仍是一项严峻挑战:当前模型在处理多项操作时,常出现遗漏编辑、违反内容保留约束或引入伪影等问题。CoVEBench提供了一个具有挑战性且具备诊断功能的测试平台,旨在推动视频编辑技术向符合真实用户需求的工作流迈进。
一句话总结
针对先前基准测试受限于孤立编辑和粗糙指标的问题,作者提出了 CoVEBench,这是一个诊断性测试平台,包含 416 个精心策划的源视频、626 条多点编辑指令以及 9,990 项细粒度检查清单条目。该平台通过大语言模型(MLLM)判定的指令遵循度与视频保真度,结合自动化质量指标,对组合式视频编辑进行评估。
核心贡献
- 该研究推出了 CoVEBench,这是一个组合式视频编辑基准测试,包含 416 个精选源视频、626 条多点编辑指令以及 9,990 项细粒度检查清单条目。
- 该基准测试建立了一套评估框架,结合 MLLM 判定的指令遵循度、视频保真度与自动化指标,用于衡量多操作遵循情况及物理真实性。
- 大量实验表明,当前的视频编辑模型在处理复杂的组合式工作流时存在困难,经常遗漏编辑内容、违反保留约束,或在并发操作中引入伪影。
引言
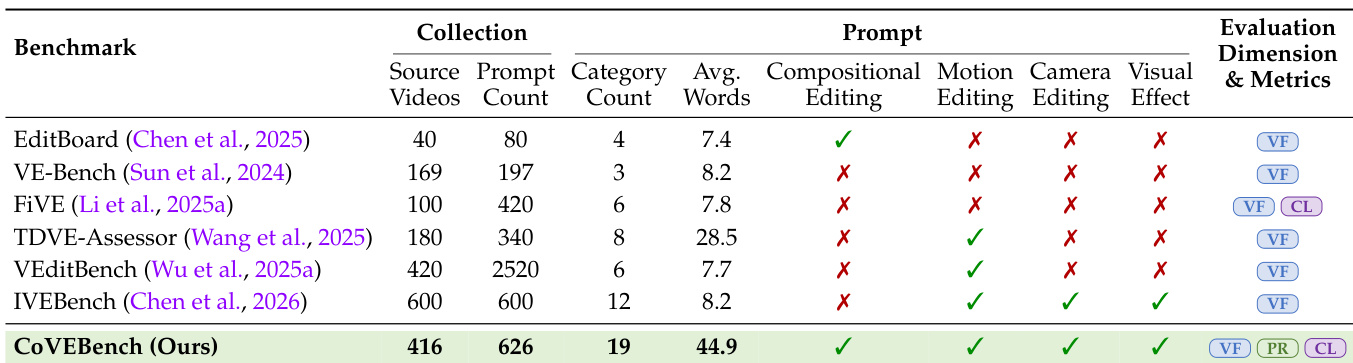
指令驱动的视频编辑模型发展迅速,但实际创作需要组合式工作流,即用户在发出多个并发编辑指令的同时,必须严格保持背景和主体的完整性。这一能力对于电影后期制作和广告本地化等专业流程至关重要,若在耦合操作中无法保持一致性,将导致输出结果无法使用。先前的基准测试在满足这些需求方面存在滞后,它们主要关注简单的孤立编辑,并依赖粗糙的全局指标,无法诊断具体的执行失败或验证物理真实性。为弥补这一差距,作者推出了 CoVEBench,该基准测试涵盖 416 个视频中的 626 条多点指令,涉及摄像机运动与结构修改等复杂操作。作者利用多模态大语言模型将这些指令分解为近 10,000 个可验证的检查清单条目,从而对指令遵循度、修改质量及语义保留情况进行细粒度诊断,以严格评估模型在真实任务中的表现。
数据集

-
数据集构成与来源
- 作者提出了 CoVEBench,这是一个用于组合式视频编辑的基准测试,包含 416 个精选源视频、626 条多点编辑指令以及 9,990 项细粒度检查清单条目。
- 源视频聚合自 Pexels 和 Mixkit 等素材平台,以及 Vript、UltraVideo、ViDiC 和 LMArena 等学术数据集。
-
子集详情与筛选
- 作者对视频池应用了严格的筛选标准,仅保留分辨率至少为 480p、时长在 3 至 21 秒之间且视觉质量较高的片段。
- 通过跨池近重复数据去除及人工可编辑性审核,最终将数据集缩减至 416 个视频。
- 编辑指令基于一个涵盖主体、背景、摄像机、风格、运动、位置和特效的七维分类体系构建。
- 作者定义了 83 种类别组合,并利用 MLLM 生成指令,确保每条提示词平均包含三个原子编辑操作。人工审核用于剔除不适当或重复的输出结果。
- 检查清单由大语言模型根据编辑指令和源视频描述合成。经过严格的人工筛选后,作者保留了约 67.2% 的初始输出结果。
-
数据使用与处理
- 作者明确指出,CoVEBench 仅作为评估基准使用,不提供配套的规模化训练数据集。
- 该数据不用于模型训练或微调,而是作为诊断性测试平台,用于评估组合式编辑工作流。
- 评估采用 MLLM 判定的指令遵循度与视频保真度,并辅以视频质量的自动化指标。
- 检查清单框架支持对执行准确性、修改真实性和语义保留情况进行诊断性评估。
-
元数据构建与结构细节
- 作者通过生成源视频的详细文本描述来构建元数据,这些描述与编辑指令一同输入大语言模型,以生成验证问题。
- 检查清单将复杂指令分解为针对执行准确性、物理逻辑和语义保留的评估组。
- 问题包含用于判断物体可见性的选择题、用于检查缺失情况与物理一致性的判断题,以及用于衡量属性保留和结构变形的评分标准。
- 结构化输出按编辑点组织评估组,从而能够分别评估原子编辑的执行情况、操作间的相互干扰以及无关内容的保留状况。
- 文中未描述任何裁剪策略;该数据集依赖于策展阶段应用的时长与分辨率约束条件。
方法
CoVEBench 评估视频编辑模型的框架围绕一个全面的分阶段流水线构建,该流水线始于将复杂编辑指令分解为原子操作,最终完成细粒度的诊断评估。流程从源视频和单点编辑指令开始,随后将其分解为组合式指令,明确详述每项所需更改,包括添加内容、属性修改、空间重定位以及保留约束。该组合式指令被输入视频编辑模型以生成编辑后的输出结果,随后将其与预期结果进行比对。评估工作划分为三个核心维度:指令遵循度、视频质量与视频保真度。指令遵循度用于评估特定编辑指令是否被正确应用,侧重于执行准确性。视频质量用于评估内部物理一致性,确保编辑后的视频遵循重力、动量和光照等物理定律,且独立于源视频。视频保真度用于衡量未修改元素的保留状况,包括语义一致性、结构保真度、运动保真度及静态区域一致性。这些维度均通过一套细粒度的检查清单问题进行评估,这些问题设计为可通过直接视觉检查进行验证。
评估流程利用多个大语言模型(LLM)来生成并优化这些检查清单。清单生成过程由七项核心编辑维度的分类体系指导:主体操作、背景修改、风格迁移、运动控制、空间重定位、摄像机编辑与视觉效果。该体系用于对编辑指令进行分类,并确保全面覆盖多样化的编辑场景。每条编辑指令均由独立的标注模型进行分类,以验证其是否符合目标类别,从而防止幻觉并确保审计准确。检查清单通过系统提示词生成,该提示词指示 LLM 扮演视频问答专家角色,以严格的 JSON 格式输出严谨的多格式评估清单。这些清单设计为高度具体且可验证,问题划分为三个维度:执行准确性、物理逻辑与语义保留,每个维度采用四种问题格式中的一种,与评估中使用的提示词格式保持一致。
评估工作由在严格原则与约束下运行的专用 AI 裁判执行。针对单视频判断题,裁判仅观察编辑后的视频,基于客观视觉证据回答“是”或“否”,并对物理定律的轻微偏差保持合理容错。针对双视频判断题与评分题,裁判会比对源视频与编辑后视频,确保未修改元素得到保留。语义保留问题仅采用 1-10 分制进行评分,并配备详细评分标准,将失败情况从目标完全缺失到部分残留进行分类。该框架还包含物理取证模块,用于评估编辑视频是否存在现实物理违规现象,如碰撞、重力、惯性、光照与材质动力学,并对严重与轻微违规进行扣分。这种全面的方法确保了对视频编辑模型在广泛编辑维度与场景下的彻底且可靠的评估。
实验
CoVEBench 评估框架利用自动化指标与广泛的 MLLM 检查清单,从指令遵循度、视觉质量与内容保留三个维度对视频编辑模型进行评估。实验在不同时间跨度、指令复杂度与计算约束条件下验证了模型能力,结果表明闭源模型通常在指令遵循方面表现更强,而开源变体在平衡编辑执行与内容保留方面面临挑战。进一步分析显示,在复杂的多约束场景下,模型性能持续下降,暴露出在物理真实性、空间控制及顺序编辑稳定性方面的关键局限。最终,这些发现凸显了组合式时空推理中存在的基础性瓶颈,必须加以解决才能实现可靠且真实的视频编辑。
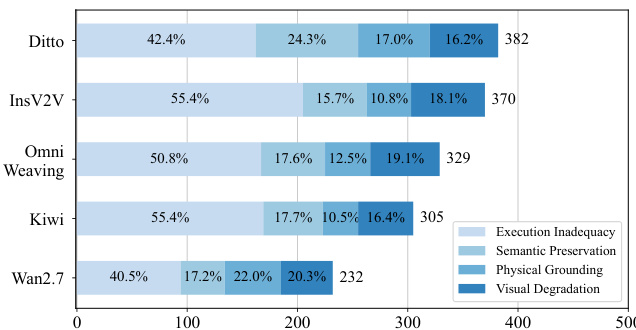
作者利用涵盖指令遵循度、视频质量与视频保真度的综合框架对视频编辑模型进行评估。结果表明,闭源模型在指令遵循方面整体表现更优,而开源模型在不同编辑类别中展现出不同的优势,部分模型在风格与背景编辑中表现突出,但在处理复杂多约束任务时存在困难。成功的编辑执行与保留未修改内容之间存在明显的权衡,且模型在推理效率及面对日益增加的时间与编辑复杂度时的鲁棒性方面存在显著差异。尽管样本量有限,闭源模型仍实现了比开源模型更高的指令遵循度。模型在成功执行编辑与保留未编辑内容之间表现出权衡关系,部分模型在某一领域表现优异,但以牺牲另一领域为代价。不同编辑类别中的模型性能差异显著,摄像机控制、运动编辑与主体替换方面仍存在挑战。
作者从指令遵循度、视频质量与视频保真度三个维度评估视频编辑模型,采用一套综合指标来衡量执行准确性、视觉自然度与内容保留情况。结果显示,闭源模型实现了更高的指令遵循度,而开源模型在不同编辑类别中展现出不同的优势,同时在维持编辑准确性与语义一致性方面面临挑战。评估揭示了成功编辑与保留未编辑内容之间的权衡关系,模型往往为了执行效果而牺牲保真度。在所有评估指标上,闭源模型均表现出比开源模型更高的指令遵循度。开源模型在不同编辑类别中的性能差异显著,在风格与背景编辑中表现较强,但在运动与主体操作等复杂任务中表现较弱。编辑执行与内容保留之间存在明确的权衡,遵循指令表现良好的模型通常在保留区域表现出较低的语义一致性。
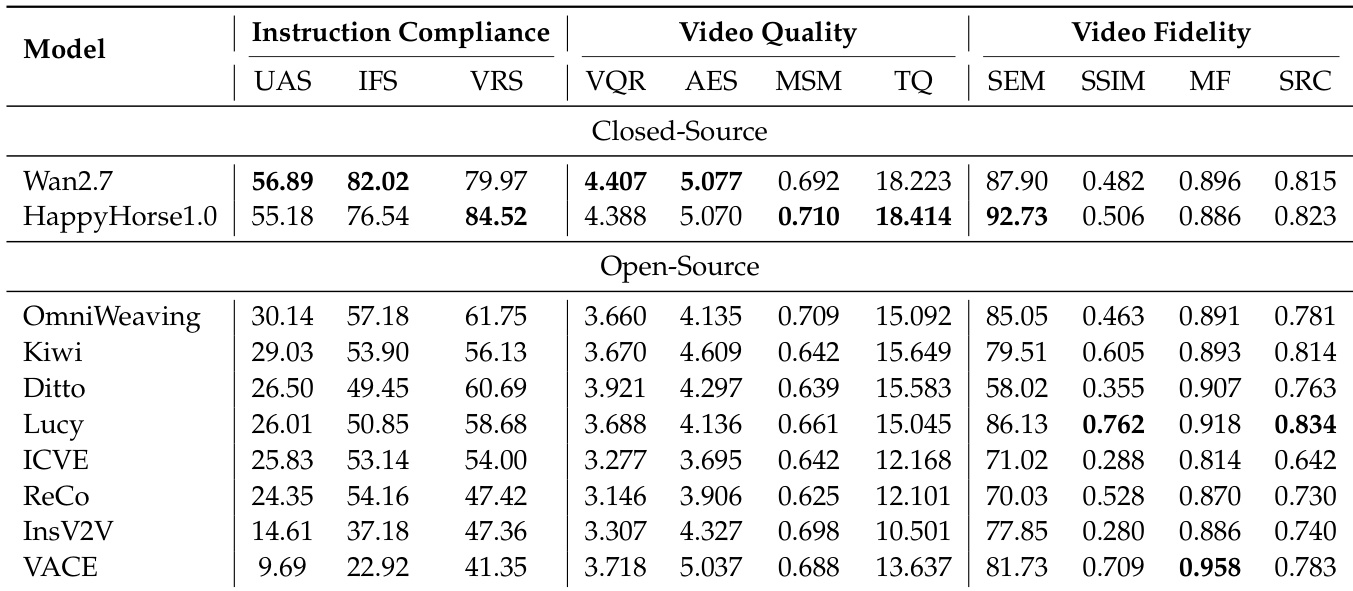
作者提出了一套视频编辑模型的综合评估框架,聚焦于多个基准测试中的指令遵循度、视频质量与视频保真度。分析表明,当前模型在处理复杂编辑时存在困难,特别是在执行指令的同时维持内容保留方面,且在不同编辑类别中展现出不同的优势。尽管基于有限样本,闭源模型仍显示出比开源模型更强的指令遵循能力。编辑执行与内容保留之间存在显著权衡,部分模型在某一领域表现优异,但在另一领域则表现不佳。当前模型在全局变换(如风格迁移与背景编辑)方面表现较好,但在精确的时空控制与细粒度物体操作方面存在困难。
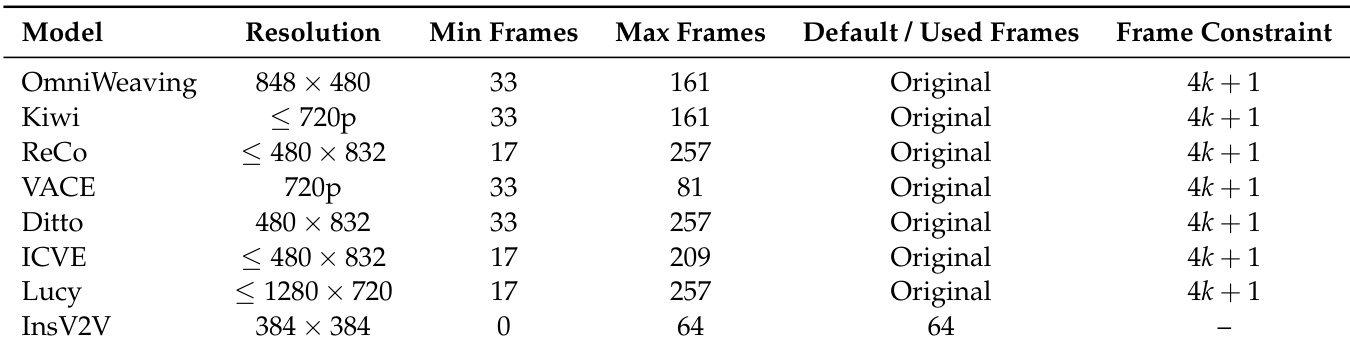
作者在不同条件下分析了视频编辑模型的性能,重点关注不同时间与复杂度因素下的准确性趋势。结果表明,随着任务复杂度增加,模型性能普遍下降,且不同模型在处理更长序列、更多编辑点及更长指令时表现出显著差异。与其他模型相比,Kiwi 在处理更长生成帧与更复杂指令时展现出更优的鲁棒性。随着生成帧数量、编辑点数量及指令长度的增加,模型准确性呈下降趋势。Kiwi 在长序列生成与复杂指令处理方面表现出比其他模型更好的鲁棒性。在处理更长源视频与更高编辑复杂度时,模型的性能下降更为明显。
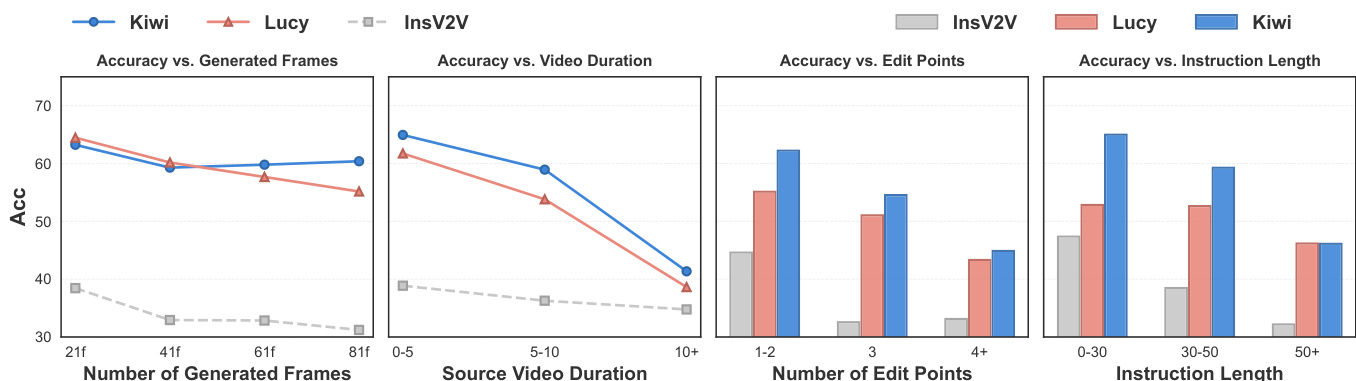
作者利用涵盖指令遵循度、视频质量与视频保真度的综合指标集对多个视频编辑模型进行评估。结果表明,模型性能差异显著,部分模型实现了较高的遵循度但在内容保留方面存在困难,另一些模型则在编辑执行与视觉质量之间表现出权衡。闭源模型展现出比开源模型更强的指令遵循能力。模型在正确执行编辑与保留未编辑内容之间面临权衡。随着编辑复杂度增加,性能出现下降,尤其是在指令更长与编辑点更多的情况下。

作者利用综合框架对视频编辑模型进行评估,该框架涵盖多样化编辑任务与复杂度级别下的指令遵循度、视觉质量与内容保留。这些实验验证了模型的核心能力与局限性,表明闭源系统在指令遵循方面整体领先,而开源模型表现出类别特定的优势,但在处理复杂操作时存在困难。分析一致指出,准确执行编辑与保留原始内容之间存在定性权衡,且随着时间长度与指令复杂度增加,性能呈现明显下降趋势。尽管面临这些挑战,部分模型在应对长序列与复杂编辑需求时仍展现出显著更优的鲁棒性。