Command Palette
Search for a command to run...
无需循环机制进行循环网络的预训练
无需循环机制进行循环网络的预训练
Akarsh Kumar
摘要
训练循环神经网络(RNN)需要在漫长的计算序列中完成信用分配。传统的通过时间反向传播(BPTT)算法在此问题上表现不佳:其计算过程在时间上是串行的,限制了并行度,且容易遭遇梯度消失或梯度爆炸问题,导致模型难以学习长距离关联。为此,我们提出了监督记忆训练(Supervised Memory Training, SMT),这是一种用于训练非线性 RNN 的方法。SMT 通过将 RNN 训练转化为对单步记忆转换标签 (mt,xt+1)→mt+1 的监督学习,从而完全规避了循环信用传播的过程。SMT 通过训练一个基于 Transformer 的编码器来实现预测状态目标,从而获取这些记忆标签——该目标仅保留预测未来所必需的过去信息。通过将“记忆什么”与“如何更新记忆”解耦,SMT 实现了 RNN 训练的时间并行化,并在任意两个 token 之间建立了稳定且长度为 O(1) 的梯度路径,而无需对 RNN 进行展开(unrolling)。实验结果表明,在语言建模和像素序列建模等任务的预训练阶段,SMT 的性能优于 BPTT。SMT 使非线性 RNN 能够更好地捕捉长距离依赖关系并实现并行训练,有望解锁那些对过往经验构建时间抽象的模型的扩展潜力。
一句话总结
作者提出了监督记忆训练(SMT),这是一种训练非线性 RNN 的方法,它通过将通过基于 Transformer 的编码器获取的单步记忆转换标签上的监督学习来简化训练,从而规避循环信用传播,将记忆内容与记忆更新方式解耦,以实现时间并行训练,具有稳定的 O(1) 梯度路径且无需展开,同时在语言建模和像素序列建模任务上优于 BPTT。
核心贡献
- 监督记忆训练(SMT)将 RNN 训练简化为在单步记忆转换标签 (mt,xt+1)→mt+1 上的监督学习。这种方法通过使用基于 Transformer 的编码器获取记忆标签来规避循环信用传播,实现了无需展开 RNN 的时间并行训练。
- 将记忆内容与记忆更新方式解耦,使得任意两个 token 之间具有稳定的 O(1) 长度梯度路径。这种能力使非线性 RNN 比标准的时间反向传播能更有效地捕捉长距离依赖。
- 在语言建模和像素序列建模等任务上预训练各种 RNN 架构时,SMT 优于时间反向传播。这些发现支持了扩展构建过去经验时间抽象的模型的潜力。
引言
循环神经网络提供固定大小的内存,理想适用于无界序列,但通过时间反向传播训练它们仍然存在顺序处理和梯度不稳定等问题。虽然 Transformer 实现了并行训练,但其内存需求随序列长度增长,而线性 RNN 变体缺乏复杂任务所需的表达能力。作者提出了监督记忆训练,通过利用 Transformer 编码器并行生成最优记忆状态,将记忆表示与动态解耦。这使得 RNN 无需展开即可学习单步更新,实现稳定的 O(1) 信用分配和时间并行训练,同时保持非线性表达能力和固定的推理内存。
数据集
作者使用由合成算法任务和自然数据建模数据集组成的基准来评估其模型。
合成算法任务
- 检索: 通过要求预测指定标识符后的 token 并偶尔损坏标签来测试梯度稳定性。
- 字符串复制: 通过要求模型在分隔符后以相反顺序重现序列来测量记忆容量。
- 栈操作: 通过一系列压栈和出栈操作评估状态跟踪能力。
- 键值对: 通过存储和检索键值对来评估关联回忆。
- 模运算: 通过从上下文示例中推断线性规则来探测上下文学习。
- 配置: 任务中的序列长度和难度参数各不相同,以测试稳定性和容量。
自然数据建模任务
- TinyStories: 由 GPT-4 生成的短篇故事精选集。作者使用 ASCII 字符级 tokenization,产生 256-token 词汇表。训练集和测试集分别包含 19 亿和 1920 万个 token。
- MNIST: 手写数字图像展平为长度为 784 的 1D 像素序列。原始灰度像素强度产生 256-token 词汇表。训练集和测试集分别包含 4700 万和 780 万个 token。
- Sketchy: 人类绘制的草图调整为 64x64 并二值化。不重叠的 2x2 补丁形成长度为 1024 的序列的 16-token 词汇表。训练集和测试集分别包含 6950 万和 770 万个 token。
方法
作者提出了监督记忆训练(SMT)来解决时间反向传播(BPTT)的局限性,例如顺序计算和梯度消失。核心方法将记忆表示的学习与记忆动态解耦,实现了具有稳定梯度路径的时间并行训练。
框架概述
标准 BPTT 按顺序展开循环计算图,要求梯度传播整个序列历史。相比之下,SMT 通过将 RNN 训练简化为单步记忆转换标签上的监督学习来规避循环信用传播。
参考框架图,该图对比了 BPTT 的顺序性质与 SMT 的并行结构。在 BPTT 方法(左侧)中,记忆状态循环更新,梯度必须流过每个时间步。在 SMT 方法(右侧)中,基于 Transformer 的编码器从过去上下文生成记忆标签,RNN 被训练为从当前状态和输入预测下一个记忆状态。这在任意两个 token 之间创建了稳定的 O(1) 梯度路径,因为长距离信用分配由并行编码器 - 解码器对处理,而不是循环回路。
模型架构
系统由三个主要组件组成:双向编码器、因果解码器和 RNN 更新器。
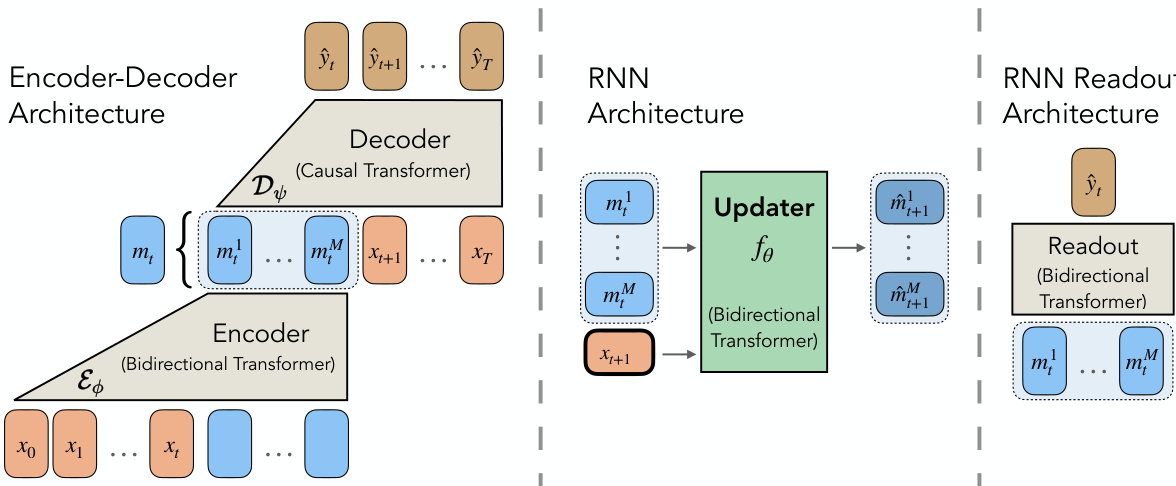
编码器 - 解码器架构在中间图中详细说明。编码器 Eϕ 处理过去上下文 xtctx 以产生压缩记忆表示 mt。该记忆随后传递给解码器 Dψ,后者根据记忆和未来输入 xtfut 预测未来输出序列 ytfut。此设置迫使编码器仅保留预测未来所需的信息。
RNN 架构显示在中心块中,利用更新器模块 fθ(实现为双向 Transformer)将当前记忆 token 和下一个输入 token 映射到下一个记忆状态 m^t+1。最后,读出架构(右侧块)通过双向 Transformer 处理记忆 token 以生成输出预测 y^t。
训练目标
训练过程涉及优化三个不同的损失函数。首先,解码损失 Ldec 确保记忆表示足以让解码器预测未来 token。其次,动态损失 Ldyn 使用均方误差训练 RNN 模仿编码器的记忆转换:
Ltdyn=MSE(m^t+1,mt+1)这明确地将编码器记忆表示塑造为马尔可夫,意味着 mt+1 仅可从 (mt,xt+1) 预测。第三,添加均匀性损失 Lunif 以防止记忆空间坍缩为单点。
DAgger 记忆训练 (DMT)
虽然 SMT 在编码器生成的标签上训练 RNN,但评估需要 RNN 使用其自身预测的记忆自回归展开。这造成了训练 - 测试不匹配,其中小预测误差随时间累积,导致 RNN 轨迹偏离最优编码器轨迹。
为了纠正这一点,作者引入了 DAgger 记忆训练(DMT)作为微调阶段。SMT 与 DMT 轨迹的可视化阐释了这一概念。在 SMT 中,RNN 在训练期间遵循编码器轨迹(绿色实线)。在 DMT 中,RNN 被展开以生成其自身轨迹(绿色虚线),并计算损失以将这些预测状态拉回编码器状态,有效地执行在线策略模仿学习以减少漂移 δt。
记忆空间属性
该方法使 RNN 能够学习能够处理复杂依赖的结构化记忆空间。检索任务的记忆空间可视化展示了模型如何组织信息。
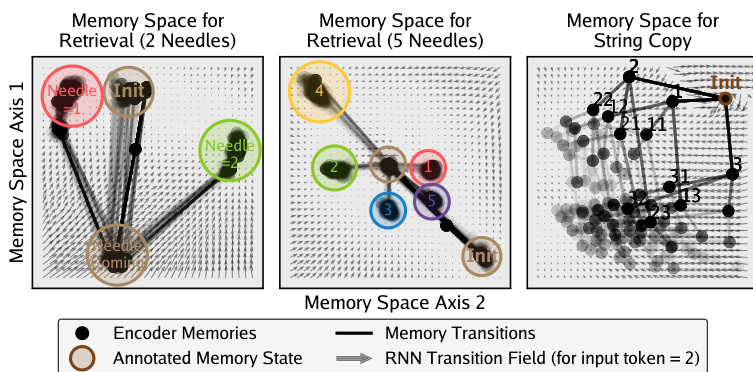
这些图显示记忆状态围绕特定信息“针”聚类,或遵循字符串复制任务的转换路径。矢量场指示 RNN 转换动态,显示模型如何学习导航记忆空间以检索相关过去信息或在长序列上维持状态。
实验
该研究评估了监督记忆训练(SMT)结合动态记忆训练(DMT)与标准时间反向传播(BPTT)在合成基准、自然语言建模和像素序列建模任务上的表现。定性结果表明,SMT 通过保持恒定信用路径长度来稳定梯度,使 RNN 比受近期偏差影响的 BPTT 更有效地捕捉长距离依赖和执行状态跟踪。此外,该方法实现了更高的顺序计算效率和平滑的扩展行为,同时允许 RNN 比 Transformer 基线更好地泛化到超出训练范围的序列长度。
作者分析了其提出的 SMT 和 DMT 方法与标准 BPTT 和 Transformer 基线的计算复杂度。数据显示,SMT 在训练期间实现了恒定信用路径长度和顺序操作,而 BPTT 随序列长度线性扩展。此外,循环方法保持恒定的推理成本,与推理复杂度随序列长度增长的 Transformer 形成对比。SMT 训练涉及恒定信用路径长度和顺序操作,不同于线性扩展的 BPTT。循环方法在推理期间保持恒定的内存和计算成本,不同于线性扩展的 Transformer。SMT 允许完全时间并行训练,与 BPTT 所需的顺序处理相比显著减少了顺序操作。

作者分析了其提出的 SMT 和 DMT 方法与标准 BPTT 和 Transformer 基线的计算复杂度。数据显示,SMT 实现了恒定信用路径长度和推理成本,而 BPTT 和 Transformer 随序列长度线性扩展。此外,SMT 允许完全时间并行训练,与 BPTT 所需的顺序处理相比显著减少了顺序操作。