Command Palette
Search for a command to run...
模态强制用于可扩展的空间生成
模态强制用于可扩展的空间生成
Bardienus Pieter Duisterhof Deva Ramanan Jeffrey Ichnowski Justin Johnson Keunhong Park
摘要
文本到图像(Text-to-image, T2I)模型蕴含丰富的空间先验信息。合成具有高真实感且场景杂乱的图像,需要理解几何结构,包括透视关系和相对尺度。现有研究利用 T2I 模型来挖掘这一先验信息以进行深度预测,但这些方法通常依赖密集的深度数据,且涉及复杂的训练策略。为此,我们提出了“模态强制”(Modality Forcing)方法,这是一种简单且可扩展的后训练(post-training)策略,旨在利用仅在稀疏深度数据上训练的单一 DiT 模型实现图像与深度的联合生成。通过为每种模态分配独立的噪声水平,Modality Forcing 使得图像和深度能够以任何排列顺序进行条件生成或联合生成。借助基于模态的解码器(Per-modality decoders),我们能够在真实的稀疏深度数据上进行训练,并实现了具有强泛化能力的深度预测。我们进一步表明,Modality Forcing 继承了 T2I 预训练的可扩展性:通过从头训练一组参数量从 3.7 亿到 33 亿不等的 T2I 模型,我们发现,使用更多图像数据训练的大规模模型能够产生更准确的深度预测。我们性能最强的模型可与当前的单目深度估计最先进方法(state-of-the-art monocular depth estimators)相媲美,且其绝对相对误差(AbsRel)相较于现有的图像-深度联合生成模型降低了 57%。这些结果有力地证明,图像生成可作为空间感知任务中一种可扩展的预训练目标。
一句话总结
作者提出 Modality Forcing,这是一种用于条件联合图像 - 深度生成的可扩展后训练方案,使用单个在稀疏深度数据上训练的 DiT,为每种模态分配独立的噪声级别。通过在 370M 到 3.3B 参数范围内从头训练 T2I 模型进行演示,表明更大的模型能产生更准确的深度,且最强模型相对于现有的联合图像 - 深度生成模型将 AbsRel 降低了 57%,提供了有力证据表明图像生成是空间感知的可扩展预训练目标。
核心贡献
- 这项工作引入了 Modality Forcing,一种后训练方案,将单目深度估计、深度到图像以及联合图像 - 深度生成统一在单个 DiT 模型中。该方法通过为每种模态分配独立的噪声级别并利用在稀疏深度数据上训练的每模态解码器,实现了任意排列的条件和联合生成。
- 受控扩展研究揭示,随着 T2I 模型参数从 370M 增长到 3.3B 且训练数据扩展到 1.92B 图像,深度预测精度随之提高。这些发现提供了证据,表明图像生成可作为空间感知的可扩展预训练目标。
- 最强模型与最先进的单目深度估计器竞争,并相对于现有的联合图像 - 深度生成模型将 AbsRel 误差降低了 57%。在 FLUX.2-klein-9B 上的性能基准测试表明,无需密集监督即可显著优于先前的基线。
引言
文本到图像模型拥有合成逼真场景的丰富空间先验,但将其适配到几何任务仍然困难。先前的方法通常依赖复杂的适配器或密集合成深度数据,限制了可扩展性并排除了稀疏的真实世界标注。作者引入了 Modality Forcing,一种简化的后训练方案,在单个 Diffusion Transformer 内统一图像和深度生成。通过为每种模态分配独立的噪声级别,该方法利用稀疏数据实现了灵活的条件和联合生成。他们的受控扩展研究进一步揭示,深度预测精度随着更大的 T2I 模型而提高,证实了图像生成作为空间感知的可扩展目标。
方法
作者引入了 Modality Forcing,这是一个旨在统一单个模型内的联合 RGB 和深度生成、图像到深度以及深度到图像任务的框架。核心方法涉及对预训练的文本到图像 Diffusion Transformer (DiT) 进行后训练,以建模联合分布 pθ(x,d∣c)。该方法为每种模态分配独立的噪声级别,允许模型通过在推理期间固定特定噪声级别来支持各种生成排列。
参考框架图以获取训练和推理流程的视觉概览:
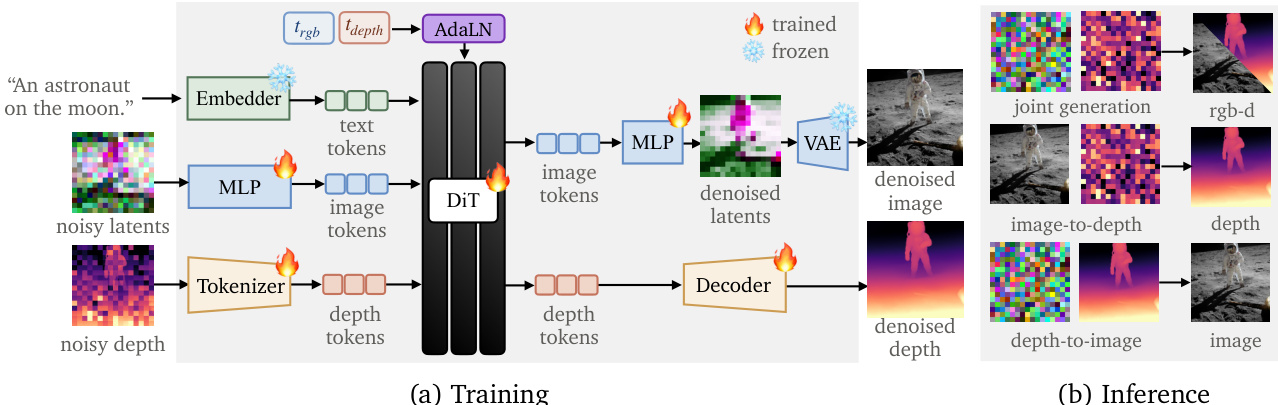
该架构处理三个不同的输入流。文本提示通过冻结的文本嵌入器编码为 text tokens。对于视觉模态,模型接受 RGB 流的噪声潜变量和深度流的噪声深度图。一个关键的设计选择是分词策略。RGB 流利用预训练的 VAE 潜空间,其中噪声潜变量通过 MLP 投影为 image tokens。相比之下,深度流直接在像素空间操作以适应稀疏的真实世界标注。噪声深度图由专用的深度分词器进行分词,缺失的像素填充各向同性高斯噪声以信号不可用性。
这些 token 流被连接并输入到 DiT 骨干网络。为了处理独立的噪声级别,模型采用具有每模态时间步条件的自适应层归一化 (AdaLN)。RGB 流和深度流使用单独的时间步嵌入器。RGB 流重用预训练的时间步嵌入器,而深度流使用新初始化的嵌入器。此外,一个轻量级的跨流混合模块允许每个流观察另一种模态的时间步,使模型能够学习 RGB 和深度噪声调度之间的耦合。
输出头也是模态特定的。RGB 分支使用 MLP 预测去噪潜变量,然后由冻结的 VAE 解码器解码为最终图像。深度分支利用深度 detokenizer,由自注意力层和最终线性投影组成,将 depth tokens 映射回像素空间。
训练通过从 [0,1] 采样每模态噪声级别 trgb 和 tdepth 进行。对于联合生成,两者均自由采样。对于图像到深度,trgb 固定为 0,而 tdepth 被采样。相反,对于深度到图像,tdepth 固定为 0。为了防止对初始文本到图像预训练期间学习的丰富先验发生灾难性遗忘,作者采用自蒸馏损失。该损失惩罚学生模型偏离原始冻结 T2I 模型预测的速度,惩罚强度根据深度噪声级别加权,以考虑深度条件的信息价值。
实验
这项工作通过从头训练 T2I 模型并将该技术应用到 FLUX.2-klein-9B 来评估 Modality Forcing,以基准测试与专业深度模型的性能。受控扩展实验验证,随着 T2I 模型容量和预训练数据的增加,深度生成质量可靠地提高,突出了图像生成中空间先验的迁移。定性比较表明,该方法产生鲁棒的深度图和一致的点云,优于现有的联合生成器,同时与顶级深度估计模型保持竞争力。
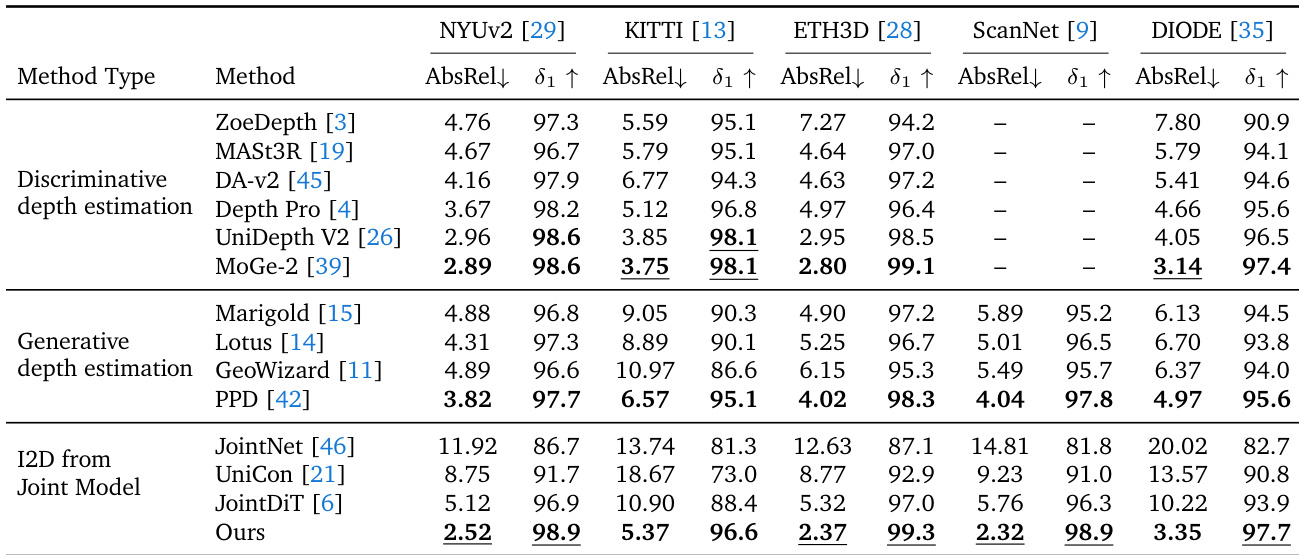
作者针对五个基准测试评估了他们的 Modality Forcing 方法,与判别式、生成式和联合深度估计模型进行比较。结果表明,他们的方法在多个数据集上实现了最先进的性能,优于现有的联合和生成基线,同时与专业判别式模型保持竞争力。所提出的方法在 NYUv2、ETH3D 和 ScanNet 基准测试上取得了最佳结果。它显著优于其他联合图像 - 深度生成模型和生成式深度估计器。性能与顶级判别式模型如 MoGe-2 相当,尽管在 KITTI 和 DIODE 上略低。
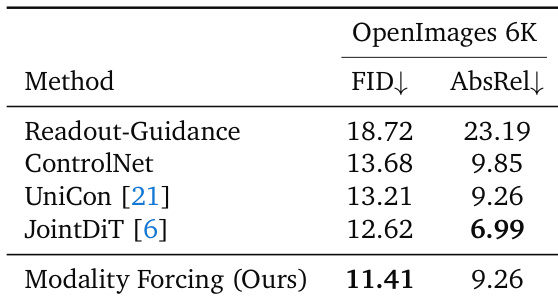
该表评估了 OpenImages 6K 数据集上的深度到图像生成能力,将所提出的方法与现有基线进行比较。结果表明,所提出的方法在所有方法中实现了最高的图像质量和最低的 FID 分数。虽然它在图像保真度上优于其他方法,但与最强基线 JointDiT 相比,深度一致性略低。所提出的方法实现了最佳的图像质量分数,在 FID 上优于所有基线。JointDiT 表现出更优越的深度一致性,在绝对相对深度估计中实现了最低的误差率。所提出的方法匹配 UniCon 的深度精度,同时提供了显著更好的图像生成质量。
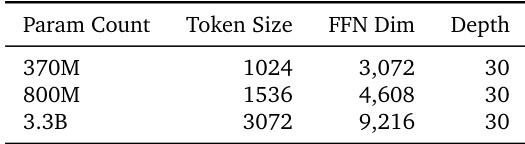
作者使用一系列 T2I 模型执行扩展实验,以调查深度生成质量是否随模型大小而提高。该表显示,网络深度保持恒定,而 token 大小和前馈维度随参数数量增加。结果表明,深度性能随这些模型能力和训练数据的增加而可靠地扩展。该研究比较了一系列参数数量的模型以分析扩展趋势。架构深度保持固定,而内部维度如 token 大小和 FFN 维度扩展。该系列中的较大模型对应于增加的 token 大小和前馈维度。
作者针对五个基准测试评估了他们的 Modality Forcing 方法,展示了最先进的深度估计性能,优于联合和生成基线,同时与专业判别式模型保持竞争力。在 OpenImages 数据集上进行的深度到图像生成的额外实验揭示了优越的图像保真度,扩展研究证实深度生成质量随模型参数和训练数据的增加而可靠地提高。虽然深度一致性略低于最强基线,但该方法有效地平衡了高质量图像合成与准确的深度估计。