Command Palette
Search for a command to run...
潜在技能:从上下文文本技能到权重内潜在技能,用于大语言模型 Agents
潜在技能:从上下文文本技能到权重内潜在技能,用于大语言模型 Agents
摘要
Agent系统日益采用文本技能来编码可重用的任务流程,但将此类技能在每一步注入提示词中会导致显著的上下文开销,并使技能内容以明文形式暴露。我们提出了LatentSkill,该框架通过预训练超网络将文本技能转换为即插即用的LoRA适配器。LatentSkill将技能知识存储在权重空间而非上下文空间中,在移除每步skill tokens的同时,保留了模块化加载、缩放与组合能力。在ALFWorld和Search-QA上,LatentSkill在显著减少prefill tokens用量的同时,优于相应的上下文技能基线:在seen和unseen划分上,其ALFWorld成功率分别提升了21.4和13.4分,且prefill tokens减少了64.1%;Search-QA精确匹配率提升了3.0分,skill-token开销降低了72.2%。进一步分析表明,生成的技能LoRA构成了一种结构化的语义几何,可通过LoRA缩放系数进行精确控制,并且在技能组件对齐时,能够通过参数空间算术进行组合。这些发现表明,权重空间技能为扩展LLM agents提供了一种高效、模块化且暴露风险更低的载体。
一句话总结
LatentSkill 通过预训练的超网络将上下文中的文本技能转换为即插即用的 LoRA 适配器,将知识存储在权重空间而非上下文空间,从而消除每一步的 token 开销,同时支持模块化扩展和参数空间组合,在 ALFWorld 和 Search-QA 上以高达 72.2% 的更低 token 开销超越上下文基线方法。
核心贡献
- 本文提出 LatentSkill,一个通过预训练超网络将文本 agent 技能转换为模块化 LoRA 适配器的框架。该方法将程序性知识从上下文窗口转移到权重空间,在保留即插即用模块化特性的同时,消除了每一步的 token 开销。
- 在 ALFWorld 和 Search-QA 基准上的评估表明,这种权重空间表示法优于上下文技能基线。该框架提升了任务成功率和精确匹配分数,同时将 prefill token 使用量分别降低了 64.1% 和 72.2%。
- 对生成适配器的分析显示,技能权重形成了一种结构化的语义几何结构,并通过 LoRA 缩放系数实现精确的行为控制。当技能组件在语义上对齐时,这些适配器进一步支持参数空间中的算术运算。
引言
LLM agent 越来越多地依赖可重用的文本流程来应对复杂且长周期的任务,但直接将技能注入提示词的标准方法会产生巨大的上下文开销,并将专有逻辑以可读的纯文本形式暴露。微调等参数化替代方案避免了提示词膨胀,但会将技能永久融合到模型权重中,导致难以动态更新、移除或组合。本文作者通过提出 LatentSkill 解决了这一长期存在的三元悖论。该框架利用预训练超网络将文本技能描述转换为模块化 LoRA 适配器。通过将程序性知识直接编码到权重空间而非上下文窗口,该方法消除了重复的 prompt token,同时保留了动态加载、缩放和组合技能的能力。实验结果表明,该方法显著降低了 prefill 开销,在标准 agent 基准测试中优于传统的上下文基线方法,同时揭示了基于权重的技能保持了结构化、可控且具备数学可组合性的几何特性。
数据集
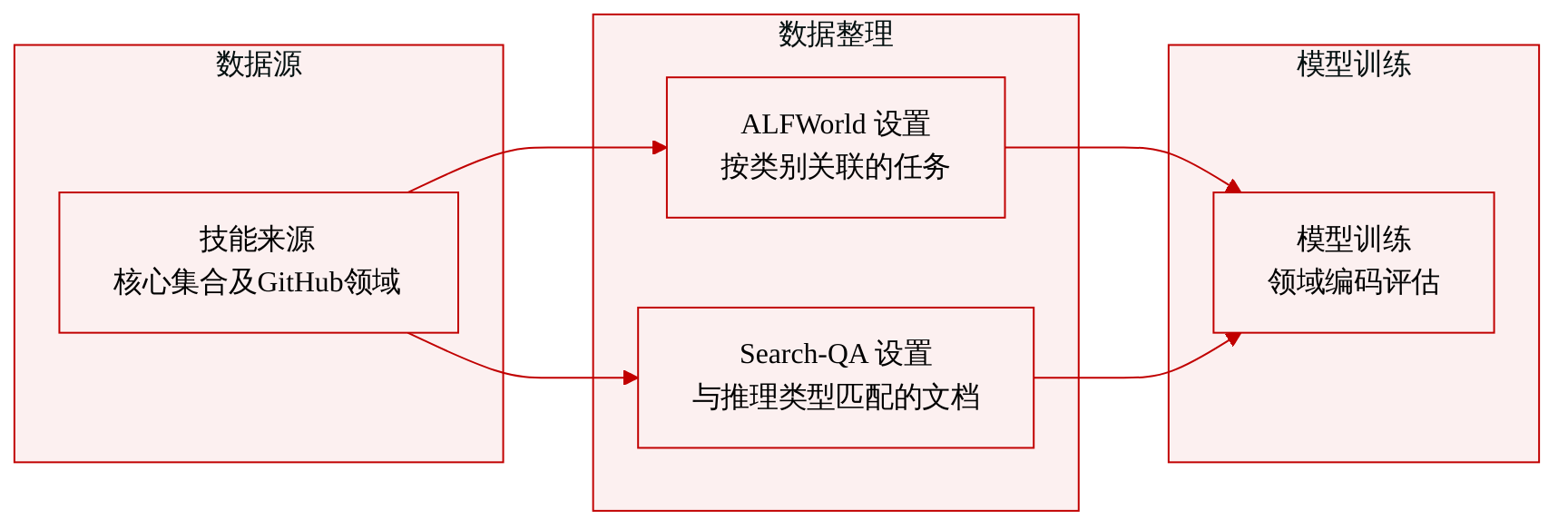
- 数据集构成与来源: 作者以 Xia 等人(2026)发布的技能库为核心构建数据集,并补充了从公共 GitHub 仓库收集的非领域内技能文本。
- 关键子集详情:
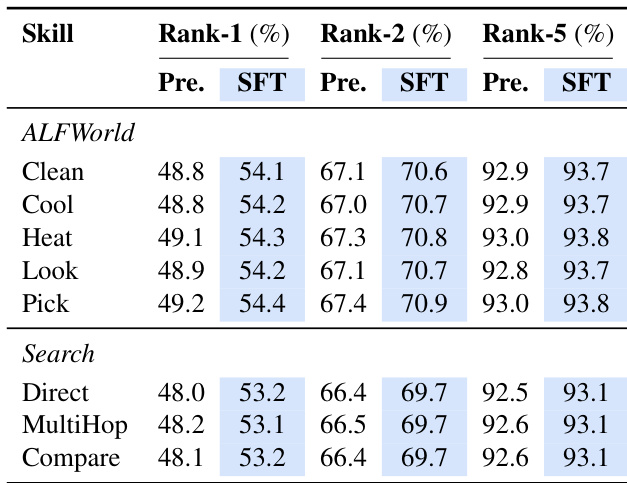
- ALFWorld:技能按类别分配给任务,而非通过检索获取。Pick 和 Pick2 任务类型共享同一份技能文档。
- Search-QA:三份技能文档分别对应三种不同的推理类型,直接根据数据集条目进行匹配。
- 分布外数据(Out-of-Distribution):包含来自公共 GitHub 仓库的 18 项 Code 技能、13 项 Finance 技能和 11 项 Writing 技能。
- 数据用途: 作者使用该数据集评估超网络在领域级别的编码能力,重点测试其向未见领域泛化的能力。提供的文本未指定训练集划分或混合比例。
- 处理与元数据: 元数据通过技能文档到预定义任务类别或推理类型的映射构建。作者明确避免基于检索的匹配,转而依赖类别对齐。未应用任何裁剪策略。
方法
作者提出了 LatentSkill,一个基于超网络的方法,将文本 agent 技能转换为模块化、基于权重的 LoRA 适配器,从而将可重用的程序性知识从上下文空间转移到参数空间。整体架构如图下图所示,包含一个技能编译器,该编译器从技能文本生成低秩适配器权重,随后将其挂载到冻结的骨干 LLM 上,以条件化其输出行为,且无需在输入 prompt 中保留技能文档。该设计通过消除重复的上下文注入需求来支持高效推理,同时保留模块化特性并实现组合控制。
如图下图所示,该框架主要运行于两个阶段:文档级预训练阶段和轨迹监督微调阶段。在预训练期间,技能编译器在文本技能文档语料库上进行训练,以学习从自然语言到可用 LoRA 权重更新的映射。编译器通过重建或补全技能文档进行训练,冻结骨干网络的适配过程作为监督信号。此阶段初始化编译器,使其在应用时能够重建原始技能文本。训练目标设计为仅更新编译器参数,从而确保骨干网络保持冻结,并将知识编码至适配器权重中。
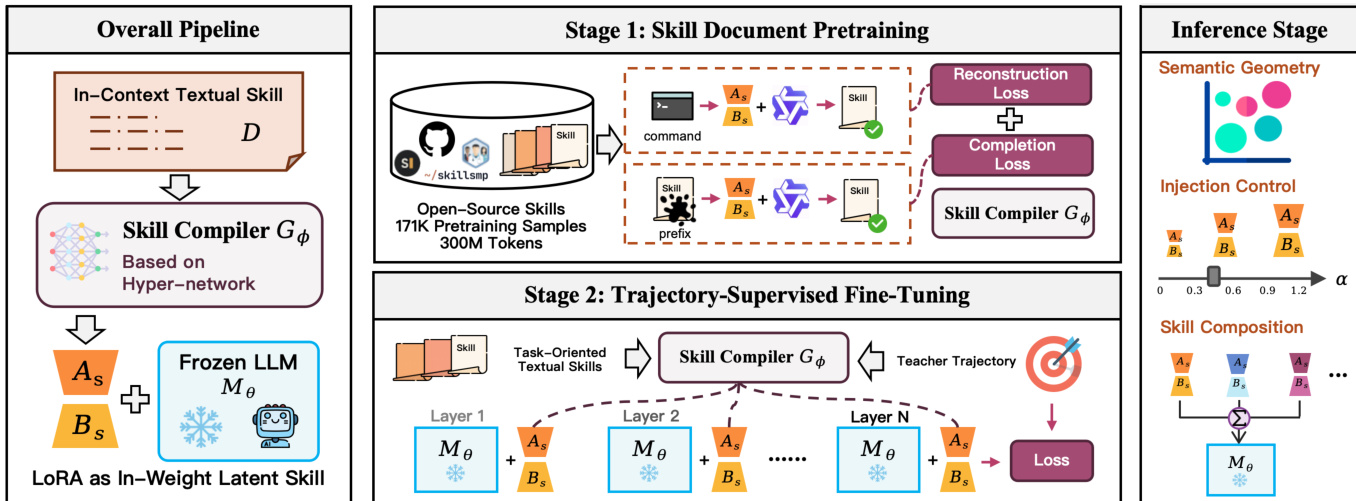
在第二阶段,预训练的技能编译器使用 teacher agent 轨迹进行微调。每个训练样本将技能文档与完整的交互轨迹配对,编译器生成一个潜在技能,并应用于整个轨迹。微调目标鼓励编译器生成捕获一致性、技能级策略信息的适配器权重,而非针对每一步的适配,从而确保多步交互中的行为稳定性。该过程使用相同的冻结骨干网络,仅更新编译器参数,使生成的适配器与期望的任务性能对齐。
在推理阶段,技能编译器与 agent 执行循环解耦。技能选择器从库中选择一项或多项相关技能,对应的适配器仅编译一次并存储于缓存中。对于选定的技能,其缓存适配器以可配置的注入强度 α 挂载到骨干网络上,该强度控制潜在技能的影响范围。当选择多项技能时,其适配器通过简单相加在参数空间中进行组合,实现灵活高效的技能融合。该框架还支持组件级组合,技能可分解为语义组件,独立编译与组合,从而对最终行为实现更精细的控制。这种模块化与可组合的设计使 LLM agent 能够高效、可控且可扩展地部署技能。
实验
在具身家庭任务和搜索增强型问答基准上的评估表明,主要实验验证了将文本技能编码为 LoRA 权重空间表示,在有效性与效率上均显著优于显式 prompt 注入。结构与可组合性分析进一步证明,潜在参数形成了具有语义组织的几何结构,能够跨领域泛化,并在组件正确对齐时支持灵活的技能组合。最后,鲁棒性评估与架构消融实验证实了其对文本扰动和对抗攻击的一致抵抗力,同时揭示了技能知识如何被高效压缩至集中于特定模型输出模块的低秩权重中。
作者提出了一种将技能知识编码为低秩适配器权重而非作为文本注入 prompt 的方法,并在 ALFWorld 和 Search-QA 两个基准上进行评估。结果表明,该方法在两项任务上均提升了性能,在多步任务和未见任务上的增益尤为显著,同时降低了推理阶段的 token 使用量和交互轨迹长度。学习到的技能表示在参数空间中呈现出结构化、语义化的组织特性,并通过文本分解与权重相加的对齐实现可控组合。在 ALFWorld 和 Search-QA 上,LatentSkill 的性能均优于基于文本的技能注入方法,且在未见任务和多步任务上提升幅度更大。该方法减少了推理期间的 token 开销并缩短了交互轨迹,表明其效率与有效性得到提升。潜在空间中的技能表示形成结构化聚类,可通过语义对齐的权重相加进行有效组合,展现出良好的可控性与可组合性。
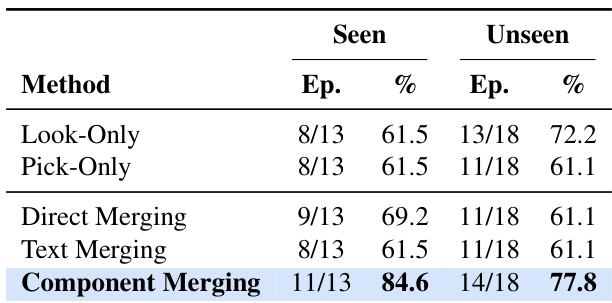
作者在参数空间中对技能组合方法进行评估,比较了不同的技能合并策略。结果表明,组件合并(Component Merging)在已见和未见任务划分上均取得最高性能,在保留原始技能能力的同时优于其他配置。该方法通过将文本分解与权重相加对齐,实现了有效的组合,并避免了共享组件的干扰。组件合并(Component Merging)在已见和未见任务划分上均取得最高性能。组件合并(Component Merging)在保留原始技能能力的同时增加了互补行为。该方法通过将文本分解与权重相加对齐来避免干扰。
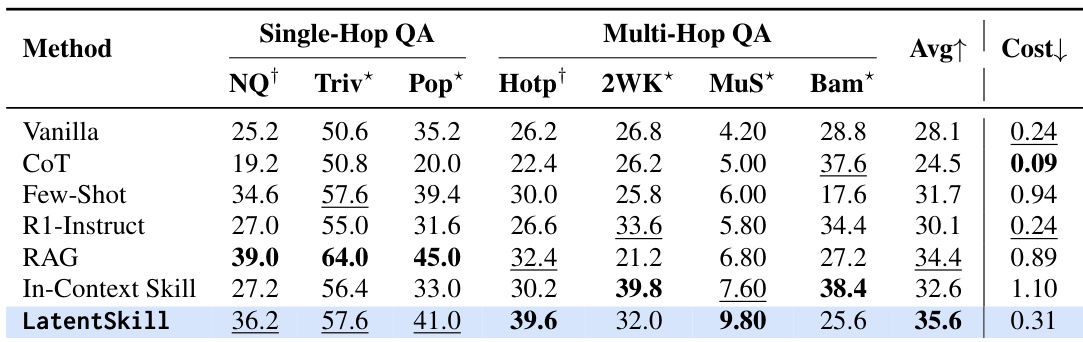
作者在一个搜索增强型问答基准上评估 LatentSkill,并将其与包括 In-Context Skill 在内的多种基线进行比较。结果表明,LatentSkill 在单跳和多跳数据集上均取得了最高的平均性能,并在特定任务上表现出显著提升。该方法相较于其他方案展现出更低的推理成本,表明效率有所提高。LatentSkill 在单跳和多跳问答基准上均取得最佳平均性能。与其他方法相比,LatentSkill 在关键多跳任务上表现出显著改进。LatentSkill 在保持或提升性能的同时降低了推理成本。
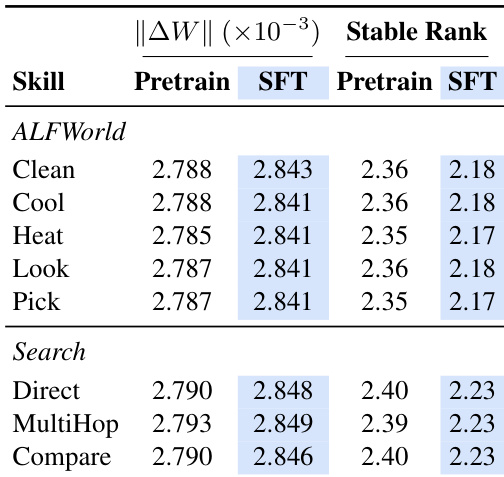
该表格展示了预训练和微调阶段各项技能的 LoRA 权重增量的 Frobenius 范数与稳定秩。数值显示各项技能的权重更新幅度一致,预训练与 SFT 之间的变化极小,表明编码稳定且紧凑。稳定秩显著低于随机初始化的 LoRA,证实技能知识被压缩至少数主导的奇异方向上,且微调进一步强化了这一低秩结构。权重增量的 Frobenius 范数在各项技能和训练阶段保持一致,表明学习到的技能表示幅度稳定。稳定秩远低于随机初始化,表明技能知识被编码于低秩子空间中。微调降低了稳定秩并提高了顶部奇异方向上的能量集中度,从而提升了编码效率。
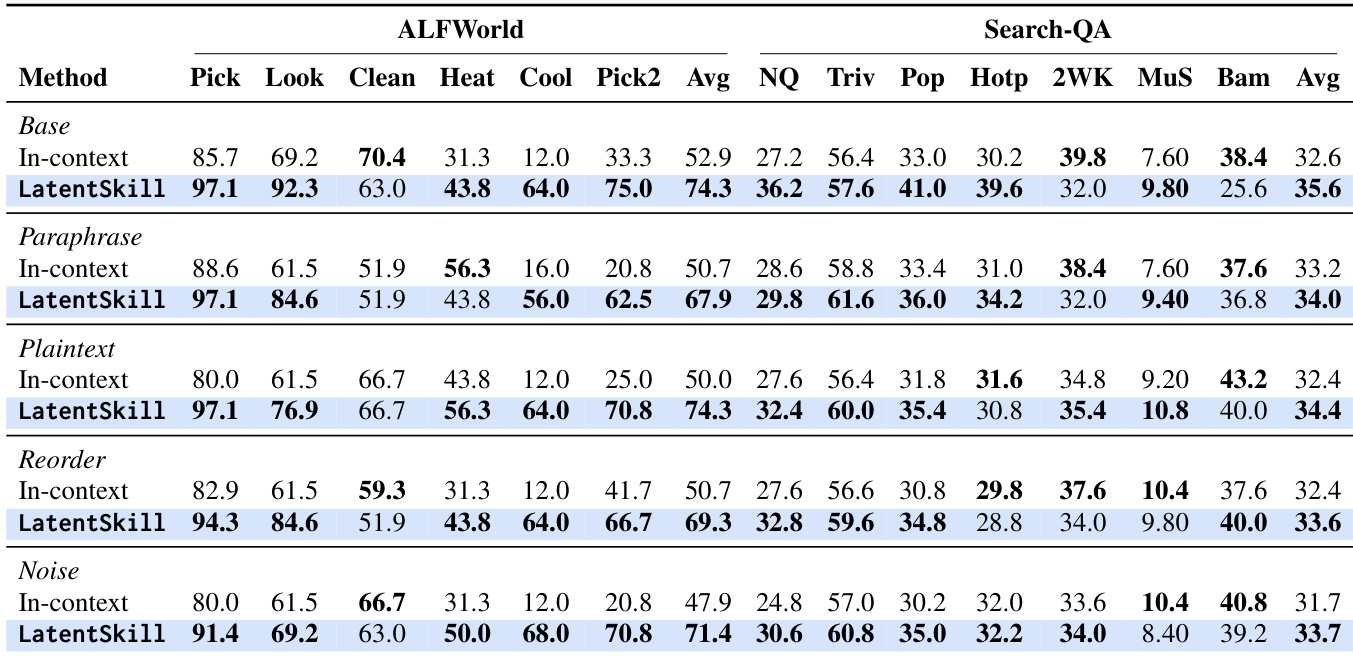
作者在 ALFWorld 和 Search-QA 两个基准上评估 LatentSkill,并与通过文本 prompt 注入技能的方法进行比较。结果表明,与上下文方法相比,LatentSkill 在两项基准上均取得了更高的性能,且在多步任务上的提升尤为明显。该方法还降低了推理阶段的 token 使用量,并缩短了交互轨迹,表明效率更高。此外,LatentSkill 对技能文本扰动和 prompt 攻击表现出鲁棒性,在各种条件下均保持相对于上下文方法的优势。LatentSkill 在 ALFWorld 和 Search-QA 上均优于上下文方法,在多步任务和未见划分上取得显著增益。与基线方法相比,LatentSkill 降低了推理期间的 token 开销并缩短了交互轨迹。LatentSkill 在各种文本扰动和 prompt 级攻击下保持稳定的性能提升,展现出比上下文方法更强的鲁棒性。
作者评估了一种将技能知识编码为低秩适配器权重而非作为文本注入的方法,在 ALFWorld 和 Search-QA 基准上将其与上下文基线进行对比。结果表明,潜在技能集成方法 consistently 优于基于文本的方案,尤其在多步任务和未见任务上,同时降低了推理 token 开销并缩短了交互轨迹。额外实验验证了这些表示在参数空间中形成结构化语义聚类,并可通过对齐的权重合并进行有效组合,且互不干扰。此外,低秩稳定性分析证实知识被紧凑地编码于主导奇异方向内,且该方法对文本扰动和 prompt 攻击展现出强鲁棒性。