Command Palette
Search for a command to run...
SWE-Explore:基准测试编码 Agents 如何探索代码库
SWE-Explore:基准测试编码 Agents 如何探索代码库
摘要
诸如 SWE-bench 之类的仓库级编程基准推动了 coding agents 能力的迅速提升。然而,它们通常将编程任务视为一个整体性的二元预测问题(例如已解决或未解决),从而忽视了诸如仓库理解、上下文检索、代码定位与缺陷诊断等细粒度的 agent 能力。在本文中,我们引入了 SWE-Explore,这是一个专门用于隔离评估仓库探索能力的基准,而仓库探索是 coding agents 的一项关键能力。给定一个仓库和一个问题,SWE-Explore 要求探索器在固定的行数预算下返回相关代码区域的排序列表。SWE-Explore 涵盖了 10 种编程语言和 203 个开源仓库中的 848 个问题。对于每个实例,我们从成功解决同一问题的独立 agent 轨迹中推导出行级真实标签,提炼出它们的解决路径实际查阅的具体代码区域。我们从覆盖率、排序与上下文效率三个维度对探索能力进行评估,结果表明这些指标与下游修复行为高度相关。在广泛的检索方法、通用 coding agents 以及专用定位器中,我们发现 agentic 探索器明显优于传统检索方法,形成清晰的层级差距。尽管现代方法在文件级定位方面已经表现强劲,但行级覆盖率与高效排序仍是区分最先进探索器的关键维度。
一句话总结
作者提出了 SWE-Explore,这是一个专注于代码仓库探索的基准测试。该基准通过评估 coding agents 在固定行数预算下检索和排序相关代码区域的能力来隔离仓库探索任务,并从成功的 agent 轨迹中提取行级真值,以衡量覆盖率和上下文效率。这些指标能够强有力地预测下游修复成功率,并证明 agentic explorers 的表现优于传统检索方法。
核心贡献
- 本文提出了 SWE-Explore,该基准通过将仓库探索作为独立的评估目标,测量 coding agents 在补丁生成前如何定位相关代码区域。
- 该评估框架从成功的 agent 解决方案轨迹中提取行级真值,并在固定行数预算下对排序后的区域列表进行评分,从而将探索指标与下游修复性能解耦。
- 该基准涵盖 203 个开源仓库和 10 种编程语言中的 848 个问题,并通过受控的下游验证证明,探索指标能够强有力地预测补丁成功率,且 agentic explorers 始终超越传统检索基线。
引言
仓库级代码基准测试已将仓库规模的问题解决转化为自动化 agent 的实用测试平台,但标准的评估协议将性能简化为二元通过或失败分数。这种整体性指标将定位失败与补丁合成错误混为一谈,掩盖了 agent 成功的内在机制,导致行级探索能力未被充分衡量,并阻碍了针对不同检索策略的严格比较。作者提出了 SWE-Explore,这是一个通过要求 agent 在固定行数预算内返回相关代码区域的排序列表来隔离仓库探索的基准测试。他们从成功的 agent 轨迹中推导真值,以评估覆盖率和排序效率,证明这些探索指标与下游修复行为高度相关,且 agentic explorers 显著优于传统检索方法。
数据集

-
数据集构成与来源
- 作者基于三个公开的仓库级基准测试构建 SWE-Explore:SWE-bench Verified、SWE-bench-Pro 和 SWE-bench Multilingual。
- 最终基准测试包含来自 203 个开源仓库和 10 种编程语言的 848 个实例,其中 Python 因在源数据集中广泛存在而占据最大比例。
-
关键细节与过滤规则
- 仅当至少两个强大的 LLM 使用源基准测试的可执行环境成功解决原始问题时,该实例才会被保留。
- 这种轨迹验证过滤器确保数据集专注于已验证的修复行为,排除了缺乏多条成功解决路径的实例。
-
数据使用与处理
- 作者仅将该数据集用作评估基准,以测量 coding agents 如何探索仓库并检索相关上下文。
- 作者未采用训练集划分或混合比例,而是使用完整的实例集,将探索器预测结果与精心筛选的真值目标进行评分,并运行受限上下文验证。
- 所有文件路径在评估前均被规范化为仓库相对格式,行区间被标准化为从 1 开始的闭区间。
-
上下文裁剪与元数据构建
- 真值上下文源自成功的 agent 轨迹,通过提取可观察的读取操作获得,包括编辑器视图调用、命令行读取和 grep 搜索命中。
- 作者通过计算所有成功轨迹中读取操作的逐文件行级交集来生成原始核心上下文,而可选上下文则捕获剩余的读取操作并集。
- 随后进行 LLM 辅助的优化步骤,将与核心证据相邻或被反复访问的支撑性可选区域提升为核心部分,之后进行严格的人工审核以移除缺乏支持的片段。
- 最终优化的核心部分作为主要评分目标,可选区域则保留用于诊断和上下文效率分析。每条记录包含结构化的元数据,如实例 ID、源仓库、问题描述、轨迹来源以及行级区域标注。
方法
作者利用全新的基准测试框架 SWE-Explore,旨在将仓库级探索作为独立任务进行评估,并将其与端到端代码修复流程解耦。核心设计集中于隔离探索阶段,在此阶段,agent 处理问题描述和仓库快照,生成相关代码区域的排序列表,记为 P=(r1,r2,…,rK),其中每个区域 ri 由文件路径和行区间 [si,ei] 定义。如图 2 所示,该公式化表示使得探索质量的评估能够独立于补丁生成或验证过程,专注于所选代码片段的准确性和排序。该框架的结构旨在提供基于轨迹的监督,其中真值行直接从成功的 agent 运行中自动推导得出,消除了人工标注的需求。 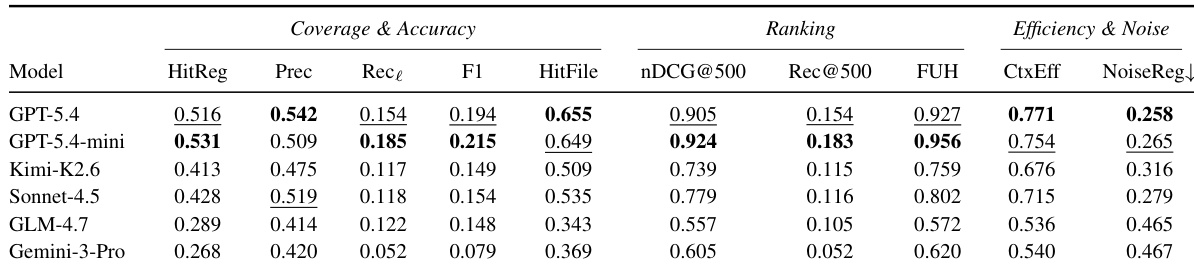
基准测试的构建过程始于收集来自不同 coding agents 的已解决问题轨迹,随后对这些轨迹进行分析以识别相关代码区域。这一步骤被称为“读取操作”,从 agent 的执行日志中提取行级交互信息。这些区域按仓库文件进行聚合,并整合为“仓库相对行区域”数据集。随后,作者应用共识聚合过程,根据区域在多个轨迹中的频率和一致性,确定高置信度区域(标记为 Ccore)和低置信度区域(Copt)。这构成了“基于轨迹的基准测试记录”,作为评估的基础。 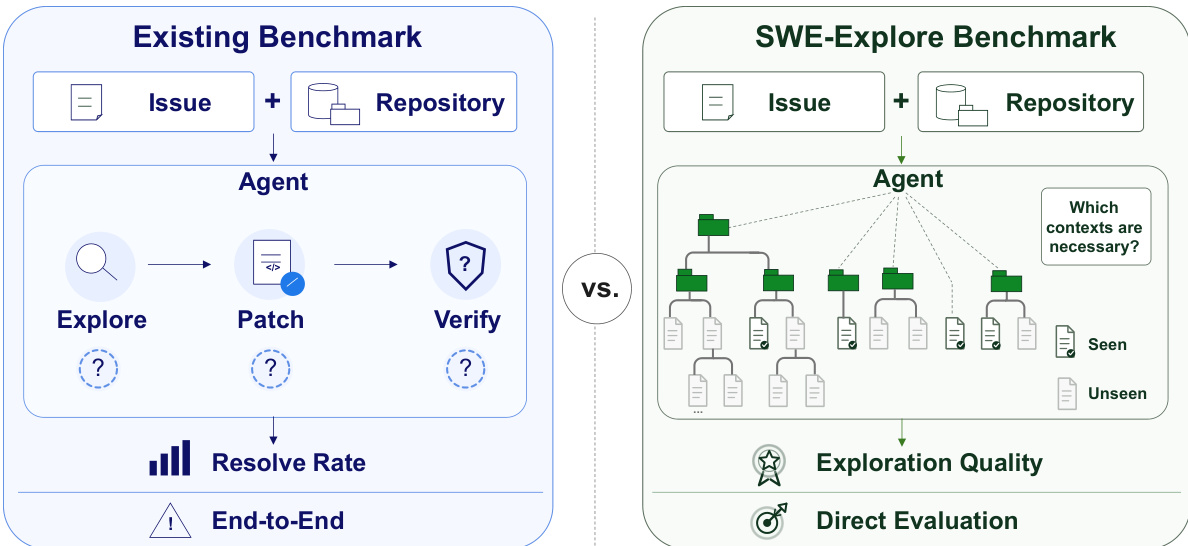
SWE-Explore 中的评估通过两个并行流进行。第一个流“上游评分”使用包括覆盖率、rank@k 和实用性在内的一系列指标,将探索器输出 P 与真值 Ccore 和 Copt 进行对比,以衡量排序区域列表的质量。第二个流“受限上下文验证”通过将探索器输出 P 作为固定 coding agent 尝试修复的唯一上下文,提供方法学验证,从而将探索质量直接与下游修复成功挂钩。这种双管齐下的方法确保评估指标能够预测实际的修复结果。 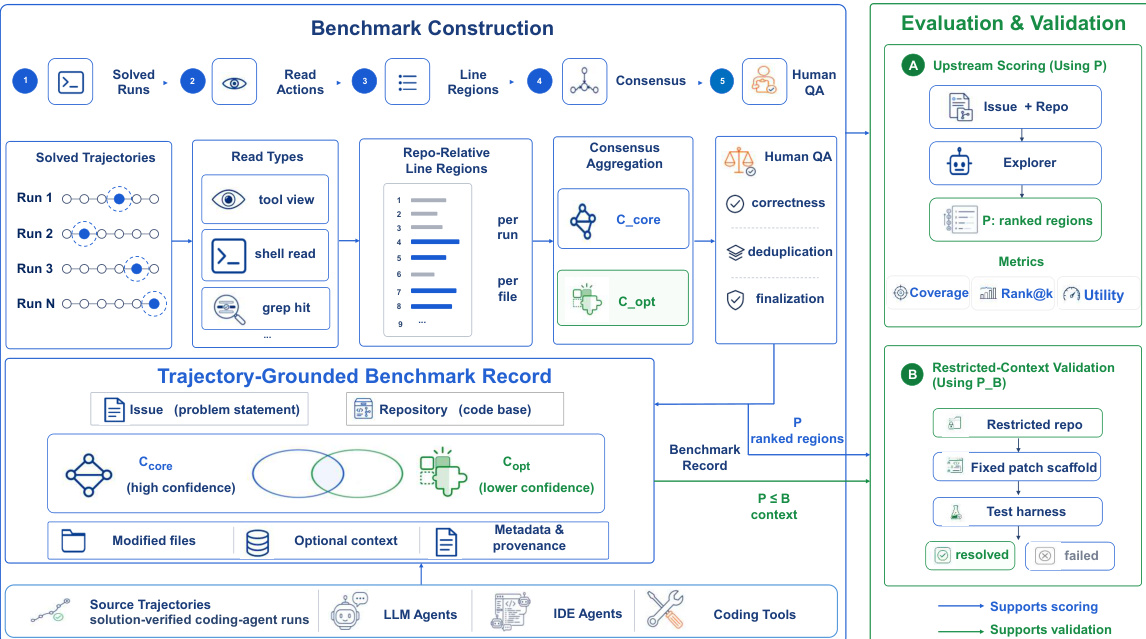
探索器的输入包括问题描述和仓库快照,涵盖文件树和代码视图。真值源自成功 agent 在解决问题过程中访问的行,每行被标注为核心或可选。探索器输出 P 为区域的排序列表,随后使用 precision at 1 和 500 归一化折扣累积增益(nDCG@500)等指标与真值进行评分。这一综合评估框架使得不同探索策略及其对代码修复性能影响的系统比较成为可能。 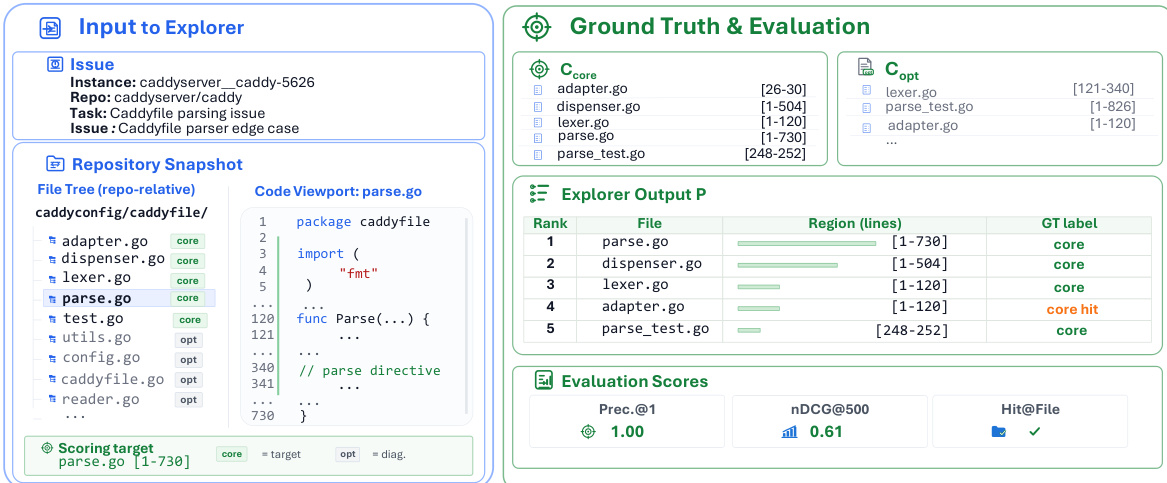
实验
该评估在行级仓库基准测试上对比了多种检索方法和 agentic explorers,并使用受限上下文修复环境来验证上游探索指标是否能可靠地预测下游补丁成功率。受控退化实验进一步通过隔离核心证据缺失与冗余噪声对修复结果的影响,测试系统鲁棒性。定性结果表明,尽管现代 coding agents 显著优于传统基线,但它们在文件级定位表现出色的同时,行级召回率却始终面临挑战。最终,结果证明广泛的覆盖率和早期证据呈现比严格的精确度更为关键,为改进仓库探索机制确立了清晰的路径。
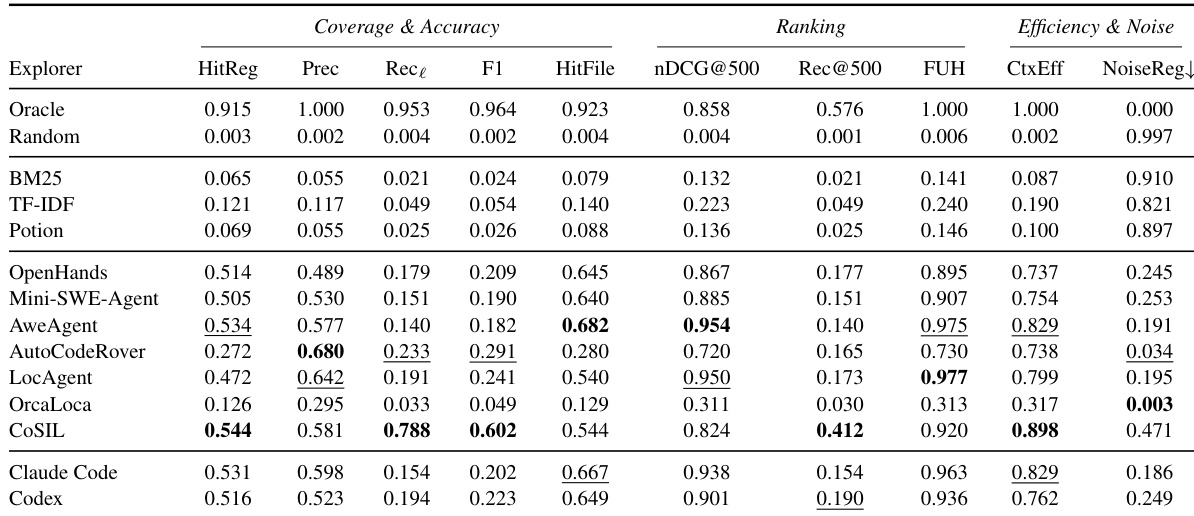
作者使用一组衡量覆盖率、排序和效率的指标,对不同模型在仓库探索任务上的表现进行评估。结果显示,GPT-5.4 和 GPT-5.4-mini 在大多数指标上取得最高性能,特别是在精确度、命中率和排序质量方面,而其他模型则表现出较低的覆盖率和效率。评估凸显了文件级和行级准确性的重要性,那些实现高文件命中率的模型往往在行级召回率上表现不佳。GPT-5.4 和 GPT-5.4-mini 在精确度、命中率和排序质量方面优于其他模型。不同模型在覆盖率和效率上存在显著差异,部分模型虽达到高精确度,但行级召回率较低。文件级命中率是性能的强大指示器,但行级指标揭示了证据覆盖的关键缺口。
作者分析了上游探索指标与下游修复性能之间的相关性,确定上下文效率(Context Efficiency)和 Rec@100 是解决率的最强预测因子。HitFile、HitRegion 和 FUH 等指标也显示出强相关性,而噪声率和更广泛的召回指标预测能力较弱。结果表明,对相关证据的高效且早期覆盖比精确度或广泛召回更为关键。上下文效率和 Rec@100 与下游修复成功的相关性最强。HitFile、HitRegion 和 FUH 在两种相关性度量中均保持强预测能力。噪声率和更广泛的召回指标预测能力较弱,更适合用作诊断指标而非主要成功衡量标准。
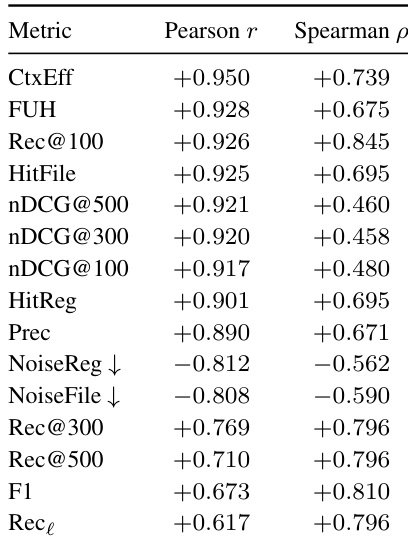
作者使用一组衡量覆盖率、准确性、排序和效率的指标,对各种探索器进行评估。结果显示,agentic explorers 优于非 agent 检索方法,通用型 coding agents 实现了高文件级命中率和早期有用证据检索,而专用定位器在覆盖相关行级证据方面的能力各不相同。表格强调上下文效率和首次有用命中是下游修复成功的重要指标,且核心证据缺失带来的负面影响大于冗余上下文。在覆盖率、排序和效率指标上,agentic explorers 显著优于非 agent 检索方法。通用型 coding agents 实现了高文件级命中率和早期有用证据检索,但在行级召回率上仍面临挑战。上下文效率和首次有用命中是下游修复成功的强预测因子,核心证据缺失的破坏性大于冗余上下文。
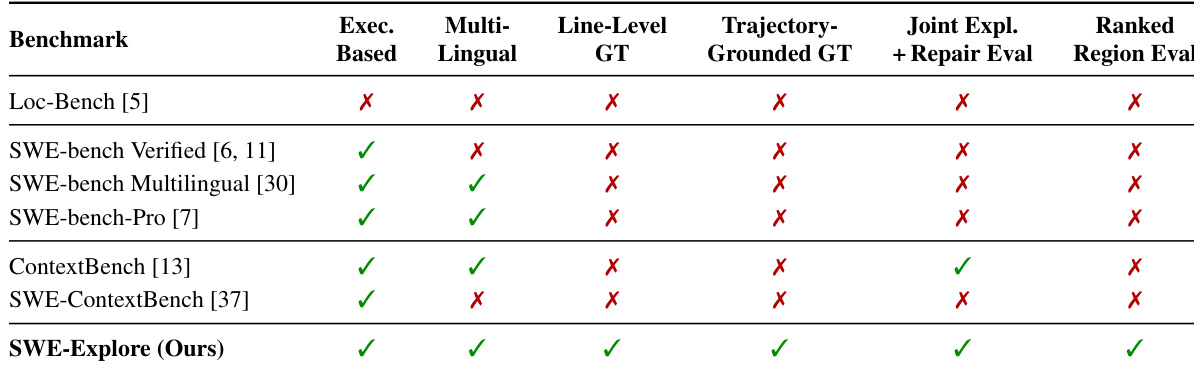
表格基于对不同评估维度的支持情况进行对比,包括基于执行、多语言、行级真值、基于轨迹的真值、联合探索与修复评估以及排序区域评估。SWE-Explore 是唯一支持全部五项评估维度的基准测试,使其与缺乏其中一项或多项能力的其他基准区分开来。SWE-Explore 是唯一支持全部五项评估维度的基准测试:基于执行、多语言、行级真值、基于轨迹的真值以及联合探索与修复评估。其他基准测试至少缺乏一项评估维度,大多数无法支持排序区域评估或基于轨迹的真值。SWE-Explore 通过结合基于执行、多语言、行级、基于轨迹以及联合探索与修复评估的能力,实现了独特的综合评估。
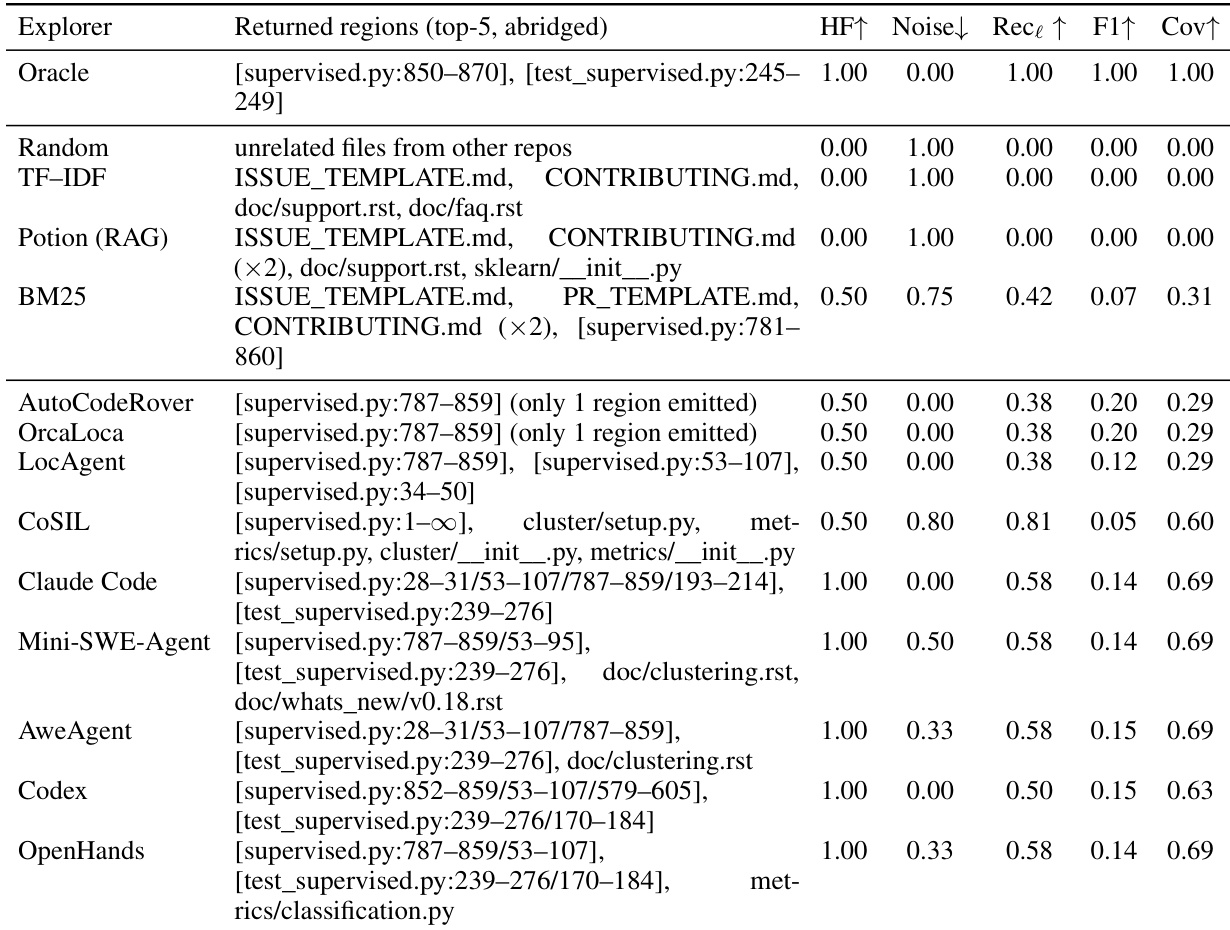
表格展示了不同探索器在返回相关代码区域能力方面的对比,指标包括文件级命中率、噪声、行级召回率、F1 分数和覆盖率。作者评估了来自不同类别的探索器,包括基于检索的方法、专用定位器和通用型 coding agents。结果显示,通用型 agent 始终实现高文件级命中率和覆盖率,而专用定位器即使对已找到的文件精确度很高,也常常遗漏相关文件。基于检索的方法表现较差,命中率低且噪声高。Oracle 在所有指标上均获得满分,作为理想性能的基准。通用型 coding agents 实现了高文件级命中率和覆盖率,表明其对相关文件和内容的定位有效。专用定位器表现出高精确度但低文件级命中率,在已识别的文件内预测准确,却遗漏了关键文件。TF-IDF 和 BM25 等基于检索的方法表现较差,命中率低且噪声高,凸显了词法搜索在代码探索任务中的局限性。
实验在覆盖率、排序和效率维度上评估了多种仓库探索方法,同时验证不同检索策略如何影响下游代码修复成功率。定性分析表明,通用型 coding agents 和顶尖模型通过提供强大的文件级覆盖率和早期证据检索,始终优于专用定位器和传统检索方法,尽管行级精确度在所有技术中仍是持续存在的挑战。最终,研究结果证明,上下文效率和核心证据的及时识别对修复成功远比广泛召回或高精确度更为关键,凸显了能够联合评估探索准确性和实用性的综合基准测试的必要性。