HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

验证视界:编程 Agent 奖励没有银弹

Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距


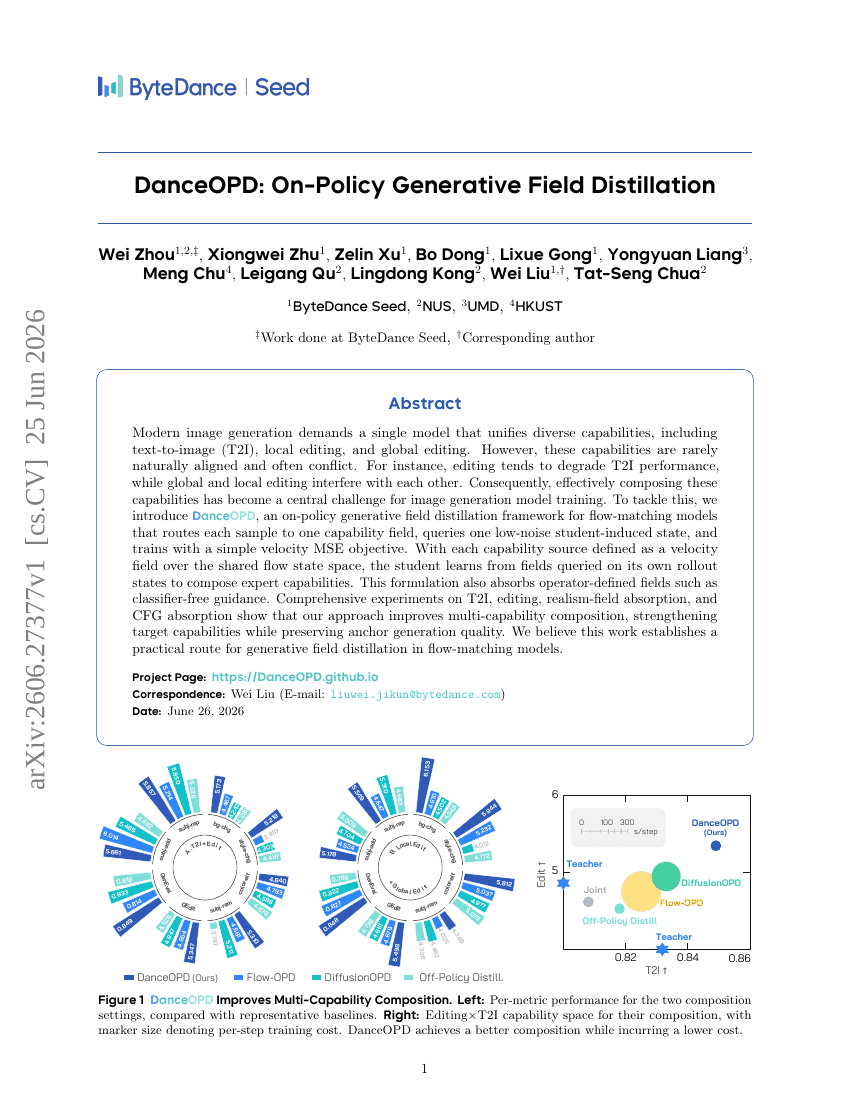









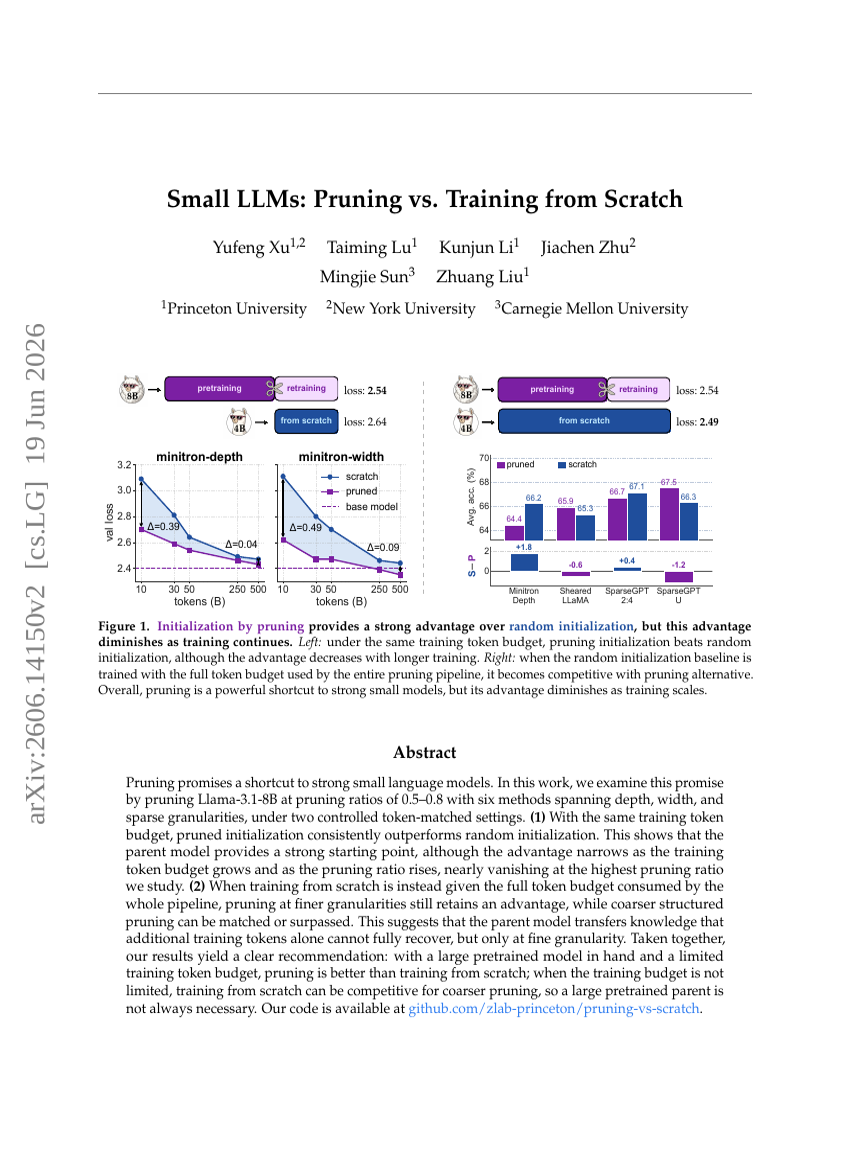



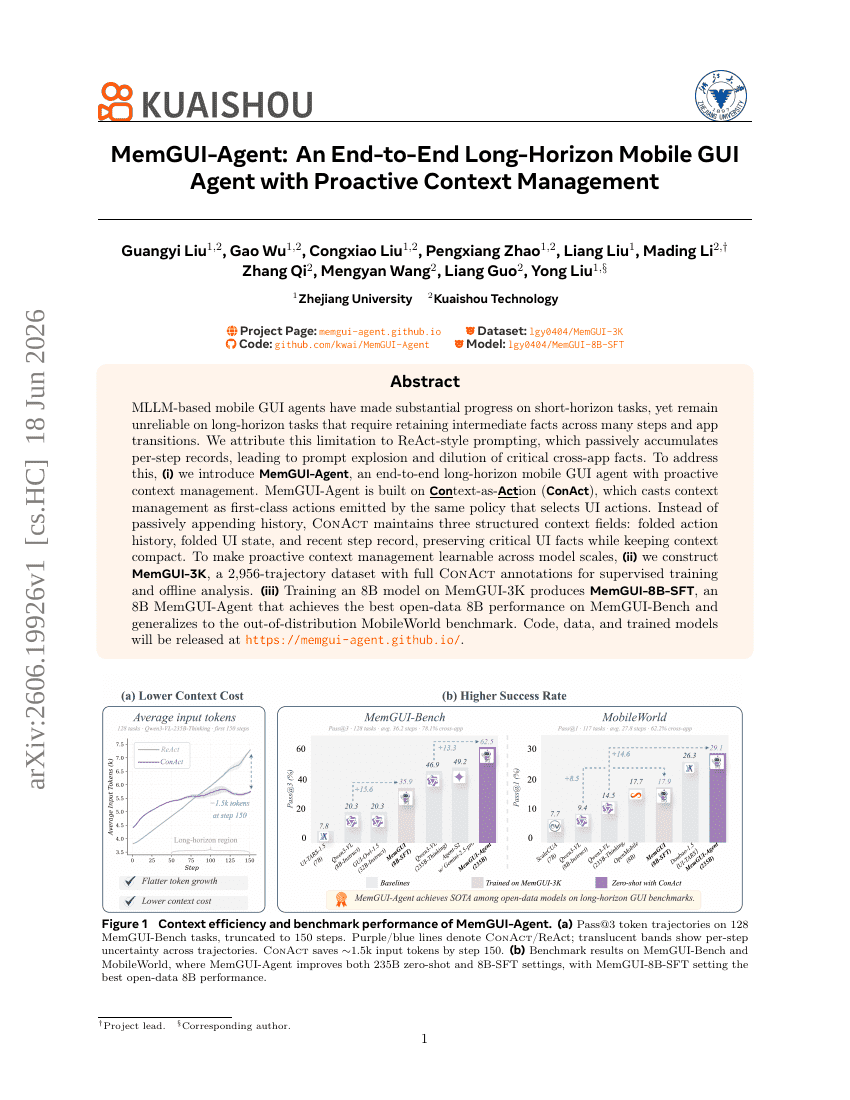
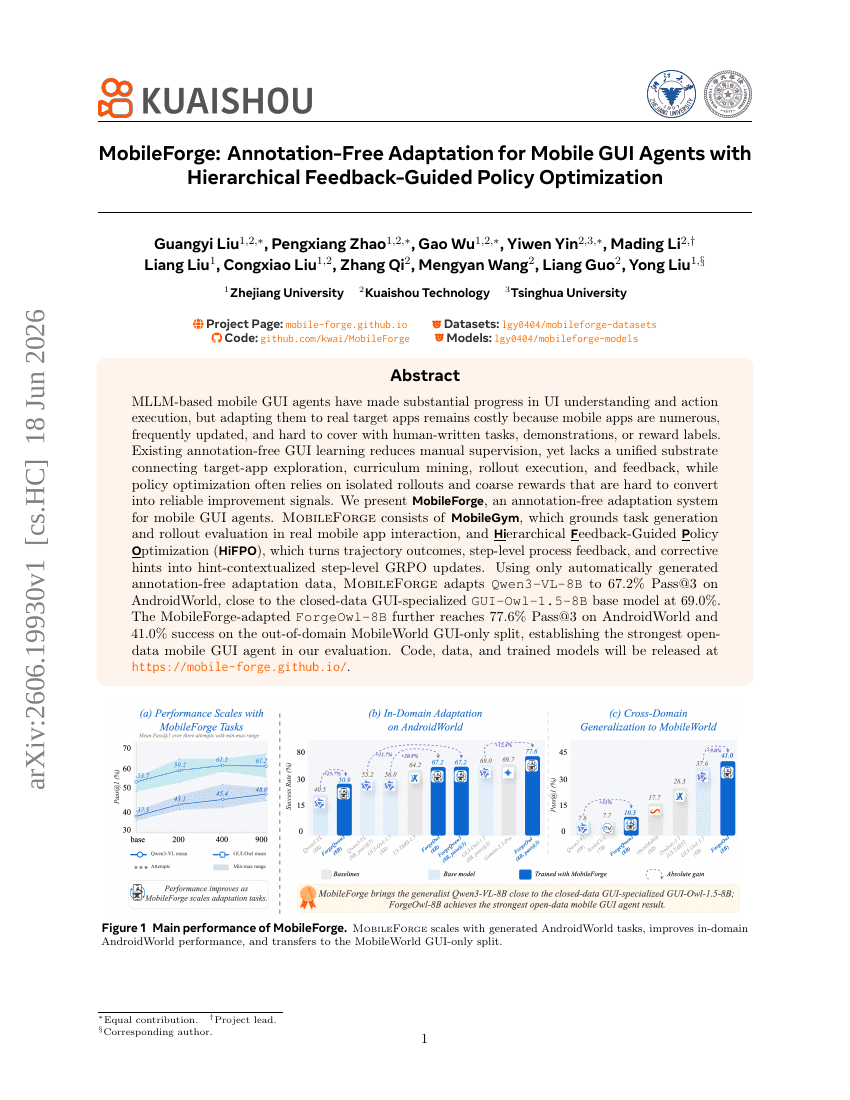









验证视界:编程 Agent 奖励没有银弹
Qwen-Image-Agent:弥合真实世界图像生成中的上下文差距
OPID:面向智能体强化学习的同策略技能蒸馏
用于机器人控制的上下文内世界建模
DanceOPD:同策略生成场蒸馏
Autodata:一种用于生成高质量合成数据的智能体数据科学家
改进的大型语言扩散模型
OCR推理的鲁棒性如何?评估视觉语言模型在视觉扰动下的OCR推理鲁棒性
RoboAtlas:上下文主动SLAM
基于意图感知场景表示的人群中机器人视觉导航学习
用于三维线缆驱动软机械臂的深度强化学习增强事件触发数据驱动预测控制
自然非格化:预训练期间哪些规则得以保留的非对称控制
每一个非负整数都是一个三角形数、一个五边形数和一个七边形数之和
Loop Engineering:Anthropic 设计智能体提示系统的方法论
小型大语言模型:剪枝与从头训练
OpenThoughts-Agent:面向智能体模型的数据配方
LingxiDiagBench:一种用于在中文精神科咨询与诊断中基准测试大语言模型的多 Agent 框架
AOHP:面向个性化、高效与安全交互的开源操作系统级 Agent 框架
MemGUI-Agent:一种具有主动上下文管理的端到端长程移动 GUI Agent
MobileForge:面向移动GUI Agents的无标注适配与基于分层反馈引导的策略优化
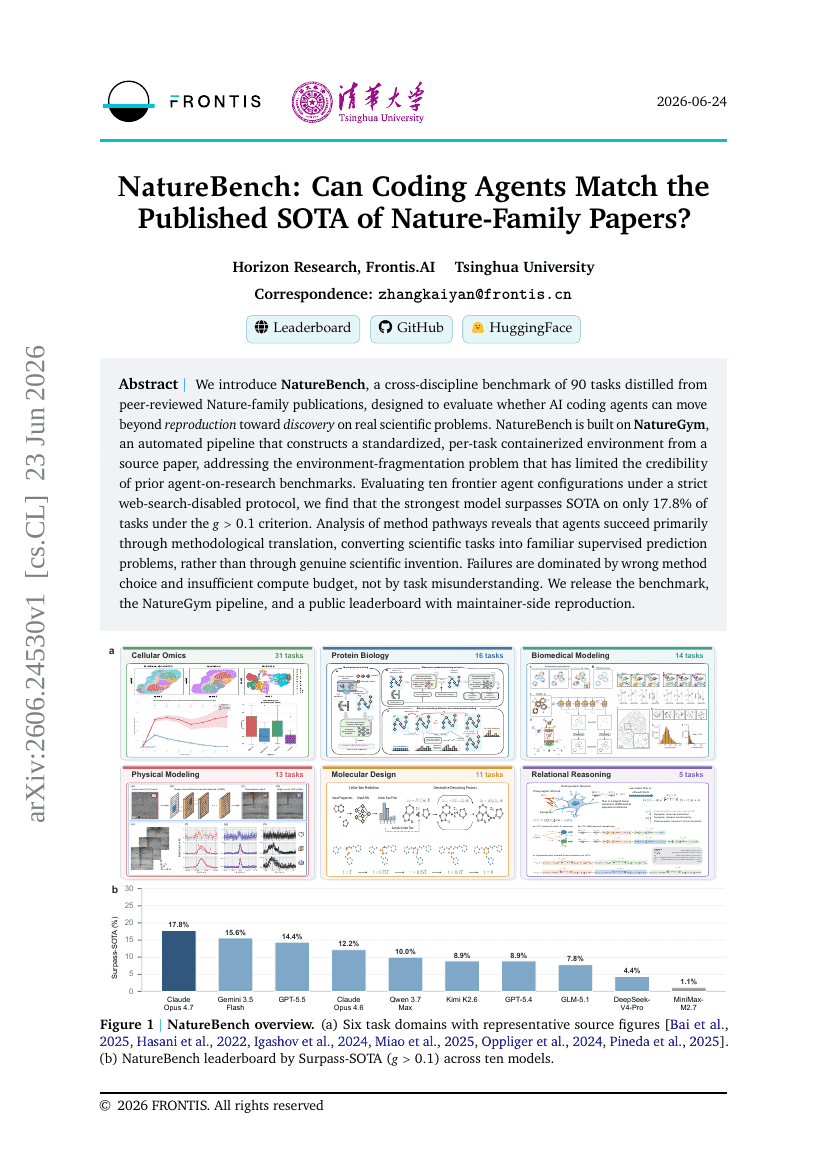
NatureBench:编程 Agent 能否匹敌已发表的 Nature 系列论文的最先进水平?
Qwen-AgentWorld:面向通用 Agent 的语言世界模型
重新思考通用语音增强的训练目标、架构和数据质量
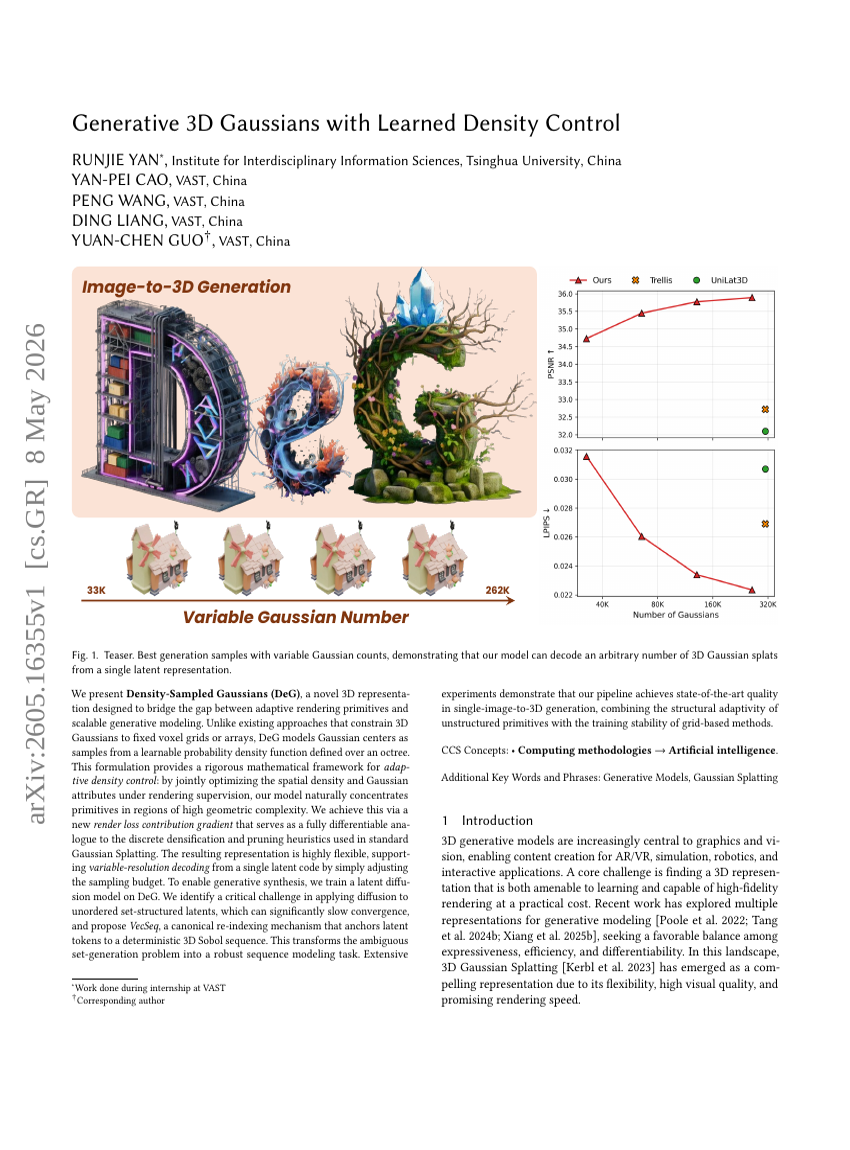
具有学习密度控制的生成式 3D 高斯模型
TADA:一种通过文本-声学双对齐实现语音建模的生成式框架
超越孤立词汇:用于手写文本行生成的扩散笔刷
gsplat:高斯泼溅开源库
OmniVideo-100K:一种基于结构化脚本与证据链的音视频推理数据集
OPEN-SWE-TRACES:推动软件工程智能体的双模式多语言蒸馏技术进展
语言模型推理中的带重置的信用分配
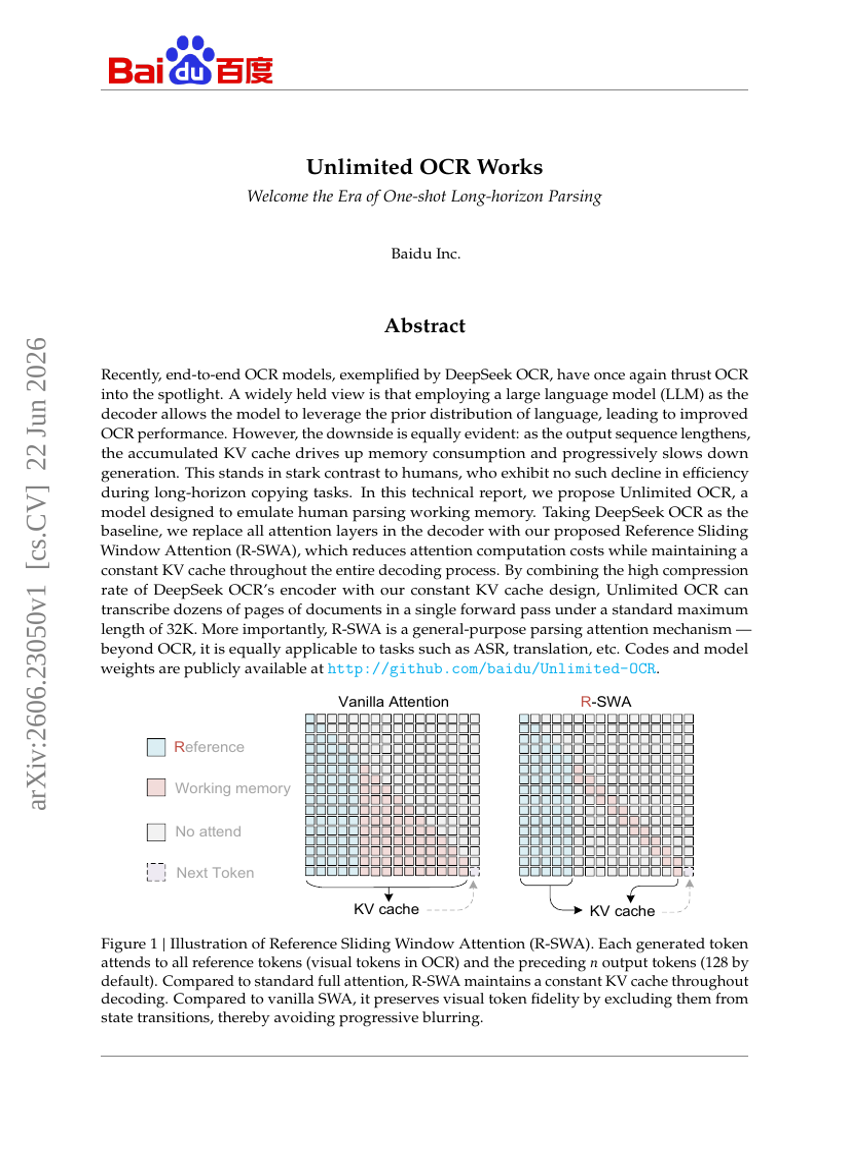
Unlimited OCR:欢迎一次性长期解析的时代
PlanBench-XL:评估大语言模型工具使用智能体在大规模工具生态系统中的长程规划
OPID:面向智能体强化学习的同策略技能蒸馏
用于机器人控制的上下文内世界建模
DanceOPD:同策略生成场蒸馏
Autodata:一种用于生成高质量合成数据的智能体数据科学家
改进的大型语言扩散模型
OCR推理的鲁棒性如何?评估视觉语言模型在视觉扰动下的OCR推理鲁棒性
RoboAtlas:上下文主动SLAM
基于意图感知场景表示的人群中机器人视觉导航学习
用于三维线缆驱动软机械臂的深度强化学习增强事件触发数据驱动预测控制
自然非格化:预训练期间哪些规则得以保留的非对称控制
每一个非负整数都是一个三角形数、一个五边形数和一个七边形数之和
Loop Engineering:Anthropic 设计智能体提示系统的方法论
小型大语言模型:剪枝与从头训练
OpenThoughts-Agent:面向智能体模型的数据配方
LingxiDiagBench:一种用于在中文精神科咨询与诊断中基准测试大语言模型的多 Agent 框架
AOHP:面向个性化、高效与安全交互的开源操作系统级 Agent 框架
MemGUI-Agent:一种具有主动上下文管理的端到端长程移动 GUI Agent
MobileForge:面向移动GUI Agents的无标注适配与基于分层反馈引导的策略优化
NatureBench:编程 Agent 能否匹敌已发表的 Nature 系列论文的最先进水平?
Qwen-AgentWorld:面向通用 Agent 的语言世界模型
重新思考通用语音增强的训练目标、架构和数据质量
具有学习密度控制的生成式 3D 高斯模型
TADA:一种通过文本-声学双对齐实现语音建模的生成式框架
超越孤立词汇:用于手写文本行生成的扩散笔刷
gsplat:高斯泼溅开源库
OmniVideo-100K:一种基于结构化脚本与证据链的音视频推理数据集
OPEN-SWE-TRACES:推动软件工程智能体的双模式多语言蒸馏技术进展
语言模型推理中的带重置的信用分配
Unlimited OCR:欢迎一次性长期解析的时代
PlanBench-XL:评估大语言模型工具使用智能体在大规模工具生态系统中的长程规划