Command Palette
Search for a command to run...
Kwai Keye-VL-2.0 技术报告
Kwai Keye-VL-2.0 技术报告
摘要
我们推出了 Kwai Keye-VL-2.0-30B-A3B,这是一款开源的混合专家(MoE)多模态基础模型,旨在推动长视频理解与 agent 智能的发展。为了解决小时级视频固有的超长上下文、信息冗余以及高昂计算成本等挑战,Keye-VL-2.0 首次将 DeepSeek 稀疏注意力(DSA)适配到基于 GQA 的多模态架构中,在捕获关键帧和长程时间依赖关系的同时,实现了无损的 256K 上下文处理。该架构由高度优化的训练与推理基础设施支撑,包括可扩展的视频 I/O、异构 ViT-LM 并行计算以及定制的 DSA 内核,这些组件显著提升了吞吐量并最小化了计算开销。此外,为了克服多任务对齐过程中的灾难性遗忘算法困境,我们引入了跨模态多教师在线策略蒸馏(MOPD),并结合 Context-RL 与 Video-RL。通过将在线策略 rollout 中密集的 token 级教师反馈蒸馏回仅激活 3B 参数的 MoE 主干网络,Keye-VL-2.0 原生赋能了代码、工具与搜索场景下的高级 agent 协作,并具备多模态自纠错能力。在视频理解、时间定位、推理、STEM 以及 agent 基准上的广泛评估表明,Keye-VL-2.0-30B-A3B 在同等规模模型中达到了最先进性能,尤其在 TimeLens 上的细粒度时间定位以及 Video-MME-v2 和 LongVideoBench 上的长视频理解方面表现卓越。我们开源了模型检查点,以加速社区向可扩展且稳健的多模态 agent 应用迈进。
一句话总结
Keye 团队推出了 Kwai Keye-VL-2.0-30B-A3B,这是一款开源的专家混合(Mixture-of-Experts)多模态模型。该模型将 DeepSeek 稀疏注意力机制适配至基于 GQA 的架构中,实现了无损的 256K 上下文处理,能够高效应对小时级长视频;同时采用结合 Context-RL 与 Video-RL 的跨模态多教师在线策略蒸馏技术,以缓解灾难性遗忘。这使得模型能够在代码、工具与搜索场景中实现高级多模态 agent 协作,并在同等规模模型中取得最先进性能,尤其在 TimeLens 上的细粒度时间定位以及 Video-MME-v2 和 LongVideoBench 上的长视频理解方面表现突出。
核心贡献
- 本文介绍了 Keye-VL-2.0-30B-A3B,这是一款开源的专家混合多模态基础模型,将 DeepSeek 稀疏注意力机制集成到基于 GQA 的架构中。该架构设计支持无损处理 256K token 上下文,在有效管理超长视频输入的同时,保留关键帧与长程时间依赖关系。
- 为缓解多任务对齐过程中的灾难性遗忘,该研究开发了结合 Context-RL 与 Video-RL 的跨模态多教师在线策略蒸馏方法。该训练框架将密集的 token 级反馈蒸馏至仅激活 3B 参数的稀疏 MoE 骨干网络中,并借助定制的 DSA 内核与异构并行技术进一步加速,以最大化计算吞吐量。
- 在视频理解、时间定位、推理、STEM 及 agent 基准测试上的广泛评估表明,该模型在同等规模模型中展现出最先进性能。系统在 TimeLens 上的细粒度时间定位以及 Video-MME-v2 和 LongVideoBench 上的长视频理解方面取得了尤为突出的成果。
引言
当前提供的源文本为空,暂无法提取技术背景、先前局限性或核心贡献。待补充完整研究内容后,将生成简明且技术精准的摘要,重点阐明该应用的价值、现有方法的技术空白以及核心贡献。该处理方式可确保最终内容保持高可读性,严格规避破折号,并维持面向技术解释的客观视角。
数据集

-
数据集构成与来源
- 构建了一个跨越预训练、监督微调与强化学习阶段的多阶段语料库,总量约 1.5 万亿 token。主要来源包括 LAION、DataComp、COYO 和 CC12M 等大规模开源图像语料,并补充了快手专有电商数据、真实截图及算法生成的合成数据集。
-
子集细节与过滤规则
- 利用 8B 专家模型优化图像与视频字幕,在保留原始语义的前提下重新生成高质量描述或修正语法错误。
- 将真实场景 OCR 捕获数据与 XML 结构的合成样本相结合,施加模糊、光照变化、褶皱及几何畸变等增强,以提升字段提取与图表阅读的鲁棒性。
- 通过基于 LLM 的验证机制过滤数学与 STEM 示例,剔除低质量样本,聚焦于几何图形、公式及科学图表。
- 合成定位与计数数据,将 COCO 与 OpenImages 目标对象粘贴至背景中并控制位置,随后使用 MLLM 进行验证,以确保边界框与计数标注的精确性。
- 将 GUI 屏幕捕获数据与控制元数据及交互语义配对,以支持元素定位、导航与状态变化理解。
- 使用强教师模型生成合成思维链轨迹,随后通过查询、响应及过程级质量检查进行过滤,针对数学任务额外进行 Doubt2Clean 二次审查。
- 在微调数据配比中预留约 40% 给纯文本语料,涵盖数学、代码仓库、Hermes 风格工具使用轨迹及搜索/RAG 示例,以防止语言模型退化。
-
训练用途与混合比例
- 第一阶段对所有参数进行训练,处理约一万亿 token,序列长度限制为 32K,混合图像字幕、图文交错、视频交错、纯文本问答及 OCR 数据,以建立跨模态对齐。
- 第二阶段转向监督微调,处理约 5000 亿 token,在平衡模态覆盖的同时保留重文本样本,以巩固指令遵循与推理能力。
- 第三阶段将上下文窗口扩展至 256K,通过一比一混合长上下文与短上下文样本,针对超长文档、多图对话及扩展的 agent 轨迹进行优化。
- 在视频强化学习阶段冻结视觉编码器与投影层,使用 GSPO 在约 3.1 万样本上进行训练,以优化时间定位、密集字幕生成及帧级验证。
-
裁剪策略、元数据与处理流程
- 将视频分割为 15 秒片段用于第一阶段训练,更长序列则采用带时间戳与全局概述的场景级密集字幕。
- 实施统一的清洗流程,剔除低质量文本、无效格式、不安全内容及不可靠的跨模态配对。
- 采用联合哈希与 CLIP 相似度策略,对跨模态的精确重复与语义相似样本进行去重。
- 针对时间定位任务强制输出格式化为坐标对的区间结构,以促使模型进行显式证据定位而非全局总结。
- 部署双队列异步架构,将 CPU 预处理与 GPU 推理解耦,使字幕生成、翻译与质量评估达到标准吞吐量的三至五倍。
方法
Keye-VL-2.0-30B-A3B 的模型架构基于标准多模态大语言模型(MLLM)框架构建,包含四个核心组件:视觉编码器(ViT)、语言解码器(LLM)、MLP 投影层以及稀疏注意力模块。该骨干网络通过三项关键架构创新进行增强,以支持原生分辨率处理、统一视觉编码及基于 DeepSeek 稀疏注意力(DSA)的长上下文多模态建模。视觉编码器继承自 Keye-VL-1.5,采用原生分辨率 Vision Transformer(ViT),在原始分辨率下处理图像与视频帧,保留文本与布局等关键细节。为支持可变输入尺寸,模型采用自适应位置编码与 2D 旋转位置嵌入(2D RoPE),并结合 Patch n' Pack 机制与 FlashAttention,实现无填充的高效序列打包。视觉编码器在包含 500B token 的多样化语料上进行预训练,以对齐下游 MLLM 的数据分布。
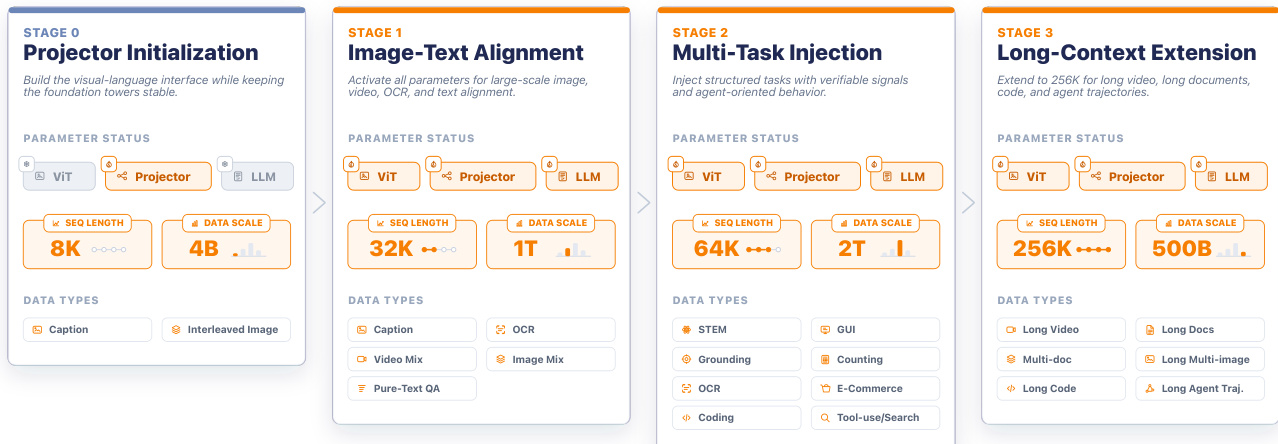
语言解码器基于 Qwen3-30B-A3B-Thinking-2507 模型,提供强大的通用知识与指令遵循能力。MLP 投影层采用随机初始化,在 Stage 0 阶段进行训练,以对齐 ViT 提取的视觉特征与 LLM 的表示空间。处理长上下文多模态输入的核心创新在于将 DSA 集成至解码器的注意力路径中。该设计采用兼容 GQA 的 DSA 架构,结合基于全局 MQA 的索引与分组 GQA 聚合。Lightning Indexer 使用共享键计算查询 token ht 与每个前置 token hs 之间的全局得分 It,s,并选取 top-k token 形成稀疏索引集 Ωt。该索引集随后应用于 GQA 骨干网络中的所有查询组,为每个组生成稀疏注意力输出 νt,g,拼接后构成最终注意力表示。此设计将核心注意力计算复杂度从 O(L2) 降至 O(Lk),实现高效的长程时空与语义聚合。DSA 模块采用两阶段训练流程:密集预热阶段初始化索引器以对齐密集注意力分布,随后进入稀疏适应阶段,引导模型依赖动态选取的证据,同时最小化梯度干扰。
实验
在涵盖视频理解、代码 agent、智能体工具使用及通用视觉语言基准的广泛评估中,与主流基线模型对比的实验验证了该模型在长上下文理解、算法推理、多轮函数调用及感知可靠性方面的表现。定性评估与典型案例分析表明,该架构能够有效融合密集视觉上下文以支持细粒度时间定位,同时在复杂推理任务中保持强大的抗幻觉能力。最终,模型展现出卓越的跨模态能力,尤其在长视频分析、视觉数学及多领域智能体工作流编排方面表现突出,具备可靠的状态跟踪与自动化错误恢复机制。
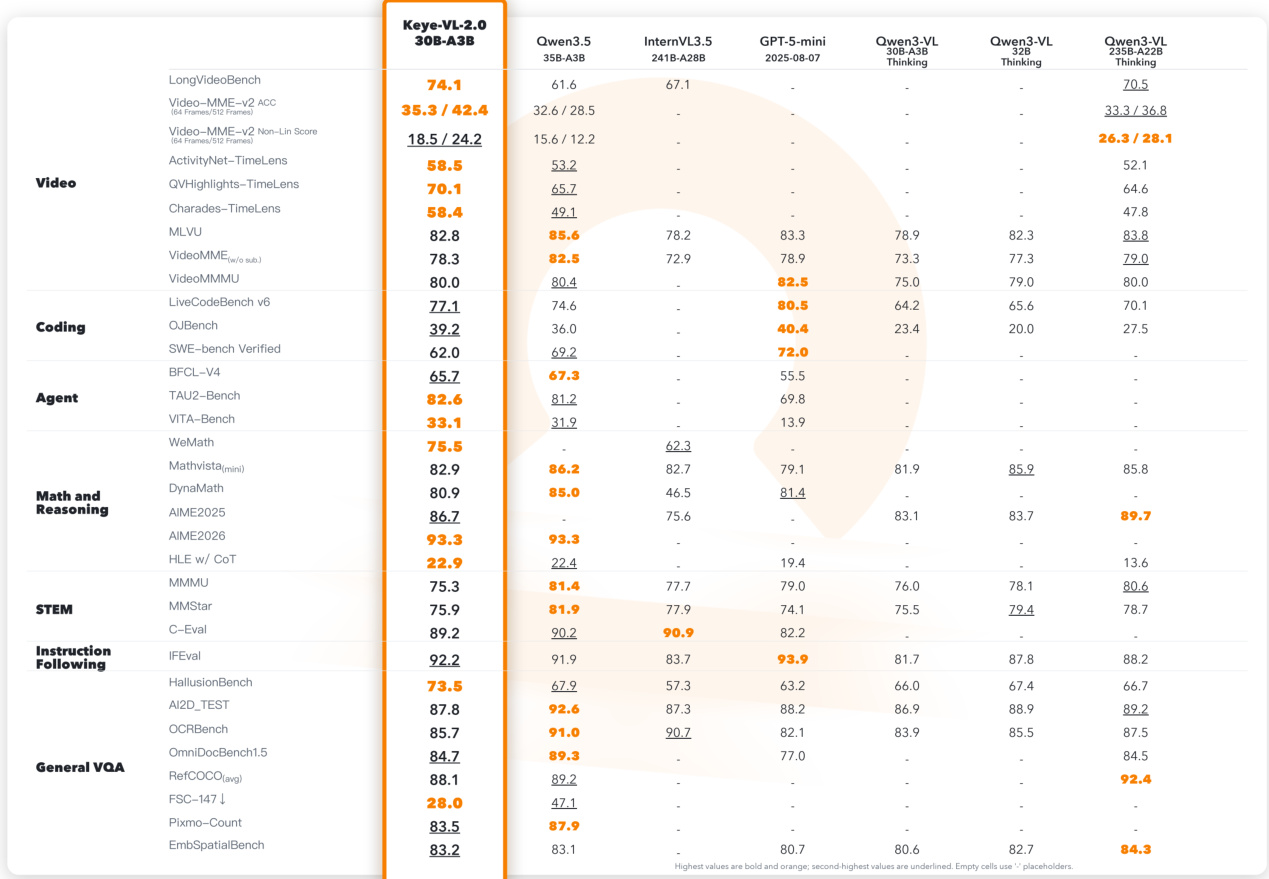
在视频理解、编程、工具使用及通用视觉语言任务等多个领域对 Keye-VL-2.0-30B-A3B 进行评估。该模型在多项基准测试中取得领先性能,尤其在长视频理解与时间定位方面表现优异,其他任务同样具备竞争力。模型在推理、工具交互及多轮服务编排方面展现出强大能力。Keye-VL-2.0 在长视频理解基准上取得最佳结果,并在不同帧密度下的时间定位任务中表现突出。在视频知识获取与通用视觉语言任务中,模型表现稳健,推理与抗幻觉能力较强。Keye-VL-2.0 展现出稳健的工具使用与多轮交互能力,成功协调多领域复杂服务场景。
在工具使用与函数调用基准测试中,将 Keye-VL-2.0-30B-A3B 与多款开源及闭源模型进行对比。结果显示,Keye-VL-2.0 在两项基准中取得最佳性能,另一项位列第二,表明其在多轮工具交互与状态跟踪方面具备强大能力。模型在各类工具使用场景中表现稳健,尤其在复杂生活服务任务与双控状态交互中优势明显。Keye-VL-2.0 在三项工具使用基准中的两项取得最佳结果。在 BFCL-V4 基准中位列第二,单轮函数调用表现强劲。Keye-VL-2.0 在多轮交互与复杂生活服务场景中展现出稳健性能。

在编程与软件工程基准测试中,评估 Keye-VL-2.0-30B-A3B 的性能并与多款开源及闭源模型对比。结果显示,Keye-VL-2.0 在 LiveCodeBench v6 与 OJBench 上取得最高分,在 SWE-bench Verified 上表现稳健,表明其具备强大的算法推理与基于执行的自纠错能力。在对比模型中,Keye-VL-2.0 于 LiveCodeBench v6 和 OJBench 上性能最佳。在 SWE-bench Verified 上表现稳健,展现出将编程能力有效迁移至仓库级软件工程的实力。Keye-VL-2.0 在 LiveCodeBench v6 和 OJBench 上超越所有列出基线,与第二名模型相比存在显著性能差距。

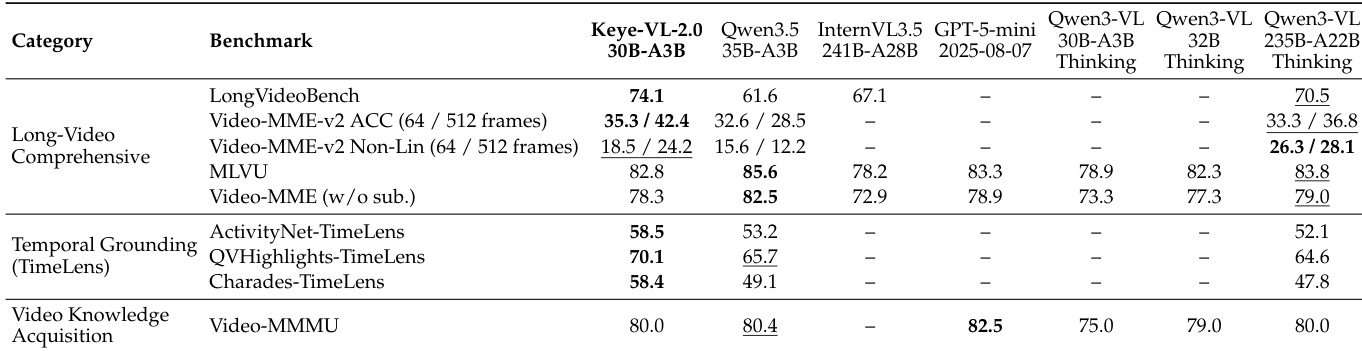
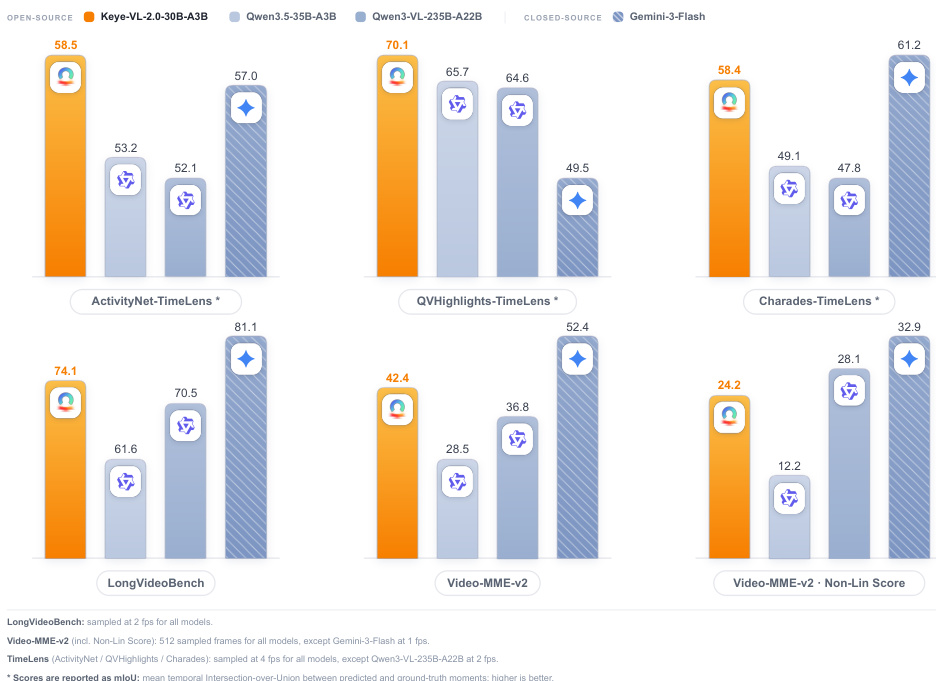
在视频理解基准测试中,将 Keye-VL-2.0-30B-A3B 与开源及闭源基线模型进行对比。结果显示,该模型在 LongVideoBench 与 Video-MME-v2 上取得领先性能,在不同设置下均保持高准确率,并在时间定位任务中表现卓越。模型在成熟基准测试中同样具备竞争力,在 TimeLens 子集上取得最佳 mIoU,表明其对密集视觉上下文与长程聚合的有效处理。Keye-VL-2.0 在 LongVideoBench 和 Video-MME-v2 上取得最佳结果,展现出色的长视频理解能力及不同帧采样设置下的高准确率。模型在全部三个 TimeLens 子集上获得最高 mIoU,表明其在场景级密集字幕生成与时间定位方面表现高效。Keye-VL-2.0 在 MLVU 与 Video-MME 等成熟基准上保持竞争力,展现出跨不同评估条件的鲁棒性。
在涵盖视频理解、编程、agent 能力及通用视觉语言推理的多个领域对 Keye-VL-2.0-30B-A3B 进行评估。该模型在多项基准测试中取得领先或稳健结果,尤其在长视频理解、时间定位与数学推理方面表现突出,同时在工具使用与多领域服务编排中展现强大实力。Keye-VL-2.0 在 LongVideoBench 和 Video-MME-v2 上取得最佳结果,长视频理解与时间定位能力强劲。模型在 WeMath 与 AIME2026 等多项推理基准中位列第一,在编程与工具使用任务中表现稳健。Keye-VL-2.0 在抗幻觉与通用视觉语言理解方面表现优异,尤其在 OCR 与空间推理任务中优势明显。
通过将 Keye-VL-2.0-30B-A3B 与成熟的开源及闭源基线模型对比,评估其在视频理解、编程、工具使用及通用视觉语言任务中的表现。实验验证了该模型在长视频理解、精确时间定位及复杂服务编排所需的多轮稳健工具交互方面的卓越能力。结果进一步凸显了其优越的算法推理能力、高效的仓库级代码生成能力,以及在数学逻辑、抗幻觉与空间理解方面的强大实力。总体而言,研究结果证实该模型在多样化模态中持续提供顶级性能,为其成为高级多 agent 系统与视觉语言应用的高度通用基础奠定了坚实基础。