Command Palette
Search for a command to run...
MemDreamer:通过分层图记忆与智能体检索机制解耦感知与推理用于长视频理解
MemDreamer:通过分层图记忆与智能体检索机制解耦感知与推理用于长视频理解
Cong Chen Guo Gan Kaixiang Ji ChaoYang Zhang Zhen Yang Guangming Yao Hao Chen Jingdong Chen Yi Yuan Chunhua Shen
摘要
当前的视觉语言模型在处理长达数小时的视频时面临困难,因为处理完整长度的视觉序列会引发难以承受的token爆炸与注意力稀释。为克服这一挑战,我们提出MemDreamer以解耦感知与推理,将长视频理解转化为智能体探索过程。作为一种即插即用框架,它通过增量流式传输视频来构建层次图记忆,这是一种用于语义抽象的自上而下三层架构,以捕捉时空与因果关系的底层图作为基础锚点。在推理阶段,推理模型采用智能体工具增强检索,通过观察-推理-行动循环在层级间导航、搜索节点并遍历逻辑边。实验表明,MemDreamer在四个主流基准测试中均取得了SOTA结果,将与人专家的差距缩小至仅3.7分。该方法将推理上下文窗口限制为完整上下文输入的仅2%,同时实现了12.5分的绝对准确率提升。此外,统计分析揭示出VLM在逻辑推理与长视频理解基准测试上的表现之间存在强烈的正线性相关,确立了智能体能力扩展作为多模态理解的新范式。
一句话总结
MEMDREAMER 通过增量构建分层图记忆,并采用工具增强型 Agent 检索机制,将推理上下文限制在全量上下文摄入的 2%,同时实现 12.5 个绝对准确率点的提升,并在四个基准测试中取得最先进结果,从而将 Agent 能力扩展确立为多模态理解的新范式,以此解耦了长视频理解中的感知与推理过程。
核心贡献
- 本文提出 MEMDREAMER,这是一个通过分层图记忆解耦感知与推理的框架,旨在缓解长视频处理中的 token 爆炸问题。该三层架构逐步将视频语义抽象为底层图结构,在保留长程时空与因果依赖关系的同时抑制无关细节。
- 该方法以被动上下文摄入为替代,采用工具增强型 Agent 检索机制,通过迭代式的“观察-推理-行动”循环运行。通过利用专用的导航、搜索和遍历工具,推理模型主动探索记忆层级以定位逻辑相关信息。
- 实验表明,该方法在四个主流长视频基准测试中达到最先进水平,将人类专家差距缩小至 3.7 个点。该框架将推理上下文窗口限制在全长视频数据的 2%,同时实现 12.5 个绝对准确率点的提升,并将 Agent 能力扩展确立为多模态理解的新范式。
引言
作者致力于解决长视频理解这一基础能力,该能力是扩展视觉语言模型以实现具身智能和复杂现实世界交互的必要条件。现有方法通常将视觉感知与逻辑推理耦合在单一上下文窗口中,这会导致在处理长达数小时的视频时引发严重的 token 爆炸、注意力稀释以及“迷失在中间”现象。即使是将视频数据存储在扁平或分块记忆库中的解耦系统,也难以保留全局上下文和时序因果关系,检索过程往往退化为低效的试错。为突破这些瓶颈,作者引入 MEMDREAMER,该框架通过将视频内容流式传输至三层分层图记忆来分离感知与推理。随后,他们利用工具增强型 Agent 检索机制,通过迭代式“观察-推理-行动”循环主动导航该拓扑结构,在仅消耗标准上下文窗口极小部分的情况下,实现精确的多步信息提取。
数据集
-
数据集构成与来源:作者将原始视频内容组织为结构化的多粒度图记忆。该层级结构包含合成完整视频的根节点、分组相关片段的中间层超级事件(Super Events),以及捕捉特定动作或时刻的细粒度宏观事件(Macro Events)。
-
子集细节与聚类规则:超级事件基于时间连续性、共享场景或主题以及共同的上层目标,对相邻的宏观事件进行聚类形成。每当任一条件不满足时即触发边界划分。聚类过程利用重叠关键实体、事件类型连续性以及记分牌递增等 OCR 文本提示等信号。每个超级事件通常包含三到八个宏观事件,但允许为自包含片段保留孤立的单个事件。
-
模型使用与处理流程:作者将该图部署为 Agent 推理模型的主动检索空间,而非传统的训练语料库。系统运行在“观察-推理-行动”循环中,模型使用包含三层导航、精确语义搜索和局部图遍历的三部分工具库按顺序查询图结构。为防止上下文稀释,该流程在将原始工具输出追加至 Agent 工作记忆之前,会将其提炼为与任务相关的证据提示。
-
元数据构建与格式规范:作者强制执行严格的格式指南以保持图结构的一致性。超级事件标签控制在十个词以内,并在适用时包含核心实体,描述部分跨度为一百至两百词。关键实体在每个超级事件内去重,并在全球范围内进行规范化,将名称变体折叠为单一标识符。根节点元数据包括简洁标题、所有超级事件的多句摘要、三到五个主题标签、五到十个规范实体以及两到三个情感基调描述符。
方法
MEMDREAMER 将长视频理解构建为一个解耦过程,包含两个独立阶段:持久记忆构建与工具增强型 Agent 检索。该框架首先通过感知模型 P 处理视频流 V,该模型以流式方式运行,构建结构化的纯文本分层图记忆,记为 G。该记忆是一种由粗到细的三层语义拓扑结构,旨在高效抽象和组织视频内容。架构由位于顶层的视频根节点(Video Root)组成,代表整体叙事;随后是封装更广泛叙事弧线的超级事件层;以及作为主要语义锚点的底层宏观事件层。每个宏观事件下方构建一个局部子图以捕捉细粒度细节。
记忆构建过程分为三个阶段。首先,采用流式自适应分割机制将视频划分为语义自包含的宏观事件。该方法通过语义边界避免了固定长度分块中常见的任意截断问题,确保每个片段连贯,并将感知模型的最大输入长度控制在定义的时间范围 τ 内。这种自适应划分产生一系列宏观事件,构成层级结构的叶节点。
其次,针对每个分割后的宏观事件,向下子图提取过程构建局部时空子图 gi=(Vi,Ei)。该子图基于新型视频中心图本体构建,顶点由标准实体(ViE)和微事件(ViM)组成。这些顶点通过异构边集 Ei 相互连接,其中包括用于布局和物理属性的空间属性边、用于动作角色绑定的主客体边,以及用于建模微事件时序与因果流向的有向时序因果边。该设计使模型能够捕捉事件内的动态演变与因果链,这是较简单的三元组图表示所不具备的能力。
最后,向上层级聚合过程将宏观事件层的详细信息提炼为全局导航骨干。所有宏观事件的文本描述被输入感知模型 P,该模型基于时间邻接性和语义亲和度对其进行聚类和聚合。这种自底向上的过程形成超级事件,并最终收敛于单一的视频根节点,创建出支持高效全局导航与精确检索定位的由粗到细层级结构。
接收文本查询 Q 后,配备工具库 T 的推理模型 R 主动探索预构建的分层图记忆。该模型完全基于此文本记忆运行,从不访问原始视频数据。探索过程由“观察-推理-行动”循环引导,推理模型首先观察当前状态,推理下一步所需操作,随后通过调用可用工具之一来执行动作。工具包分为三类:用于遍历层级的导航工具(例如获取摘要、列出事件)、用于查找特定节点的搜索工具(例如语义搜索、基于时间的搜索),以及用于探索局部邻域的图遍历工具(例如检索节点间关系)。这种 Agent 检索机制使模型能够迭代优化搜索路径,深入相关子图,并综合生成一组与任务相关的简洁线索 C,以生成最终答案 A=R(Q,C)。
实验
在四个多样化的长视频基准测试中,该方法与原始视觉语言模型及基于记忆的基线模型进行对比。主要实验验证了解耦架构范式的广泛优越性与即插即用兼容性。上下文缩减分析进一步证实,与直接端到端摄入相比,将感知与推理分离能有效缓解注意力稀释和 token 冗余问题。最后,定性案例研究证实,显式的文本图导航成功捕获了原始视觉处理通常遗漏的复杂多步因果关系,确立了结构化 Agent 推理作为暴力上下文扩展的稳健替代方案。
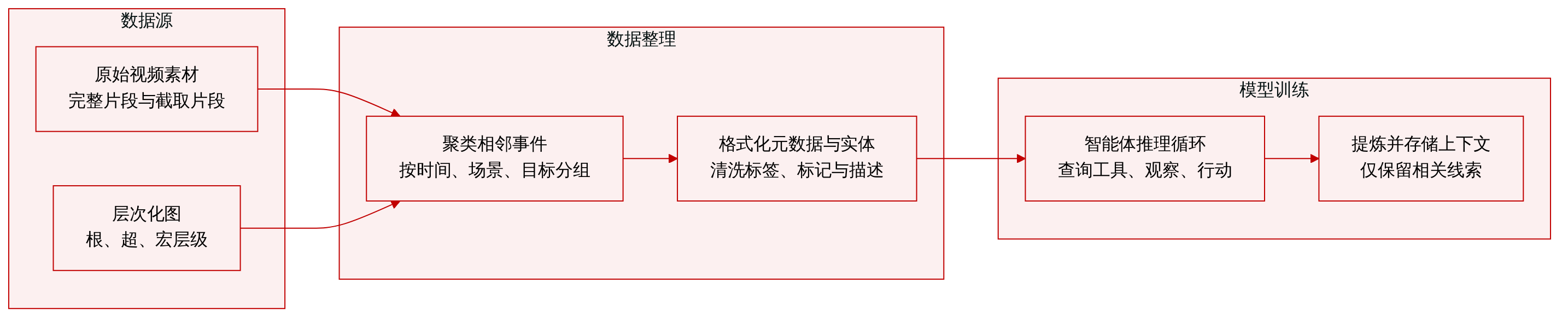
作者在不同感知模型下于 LVBench 基准上对比了不同的推理模型,结果表明感知模型的选择对性能有显著影响。结果显示,Gemini-3.1-Pro 在所有推理模型下均稳定优于 Gemini-2.5-Pro,且 Qwen3-VL-235B-A22B-Thinking 模型在搭配更强的感知模型时取得具有竞争力的结果。在 LVBench 上,Gemini-3.1-Pro 在所有推理模型下均稳定获得比 Gemini-2.5-Pro 更高的分数。当与 Gemini-3.1-Pro 感知模型配合使用时,Qwen3-VL-235B-A22B-Thinking 模型的表现与 Gemini 模型相当。与 Gemini-3.1-Pro 搭配时,推理模型间的性能差异不如搭配 Gemini-2.5-Pro 时明显。
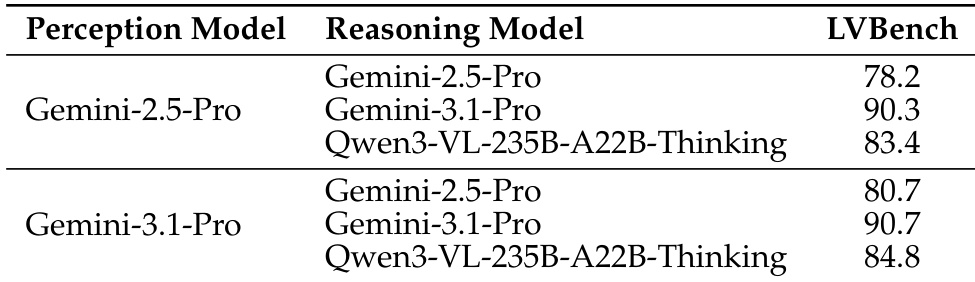
作者将框架 MemDreamer 与端到端模型在多个基准上进行对比,展示了在显著更短上下文长度下的更优准确率。结果表明,MemDreamer 以更少的输入 token 需求实现更高性能,表明解耦感知与推理提升了效率与效果。该框架在不同推理引擎下的 LVBench 基准上均优于基线模型,在准确率与上下文缩减方面取得显著增益。MemDreamer 在显著更短的上下文长度下实现了比端到端模型更高的准确率。该框架将上下文规模缩减至全视频摄入方法的 43 倍。MemDreamer 在不同推理引擎下保持强劲性能,展现出其通用性与有效性。
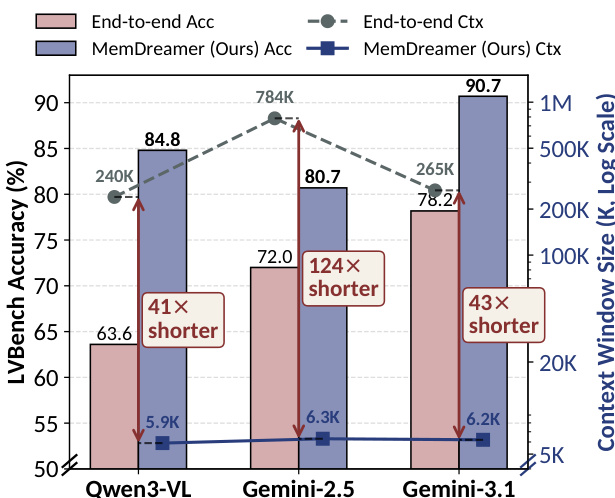
作者在一项长视频基准上评估了所提出的 MEMDREAMER 框架,对比了不同的记忆架构。结果表明,结合层级与基于图的记忆组件取得最高性能,证明了其结构化方法的有效性。该框架显著优于其他配置,表明记忆组织与图表示对长视频理解均至关重要。结合层级与图记忆组件在基准测试中取得最佳性能。所提框架优于仅使用扁平或层级记忆的配置。结果验证了结构化记忆设计在长视频推理任务中的重要性。
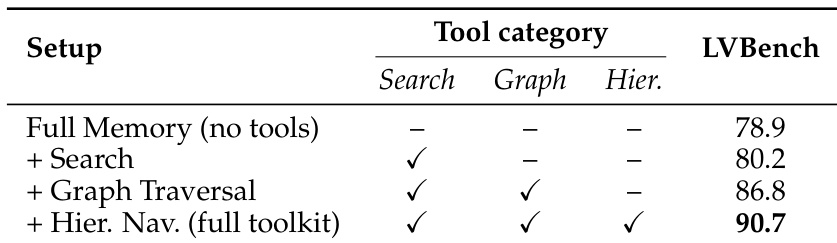
作者评估了一个通过集成搜索、图遍历与层级导航工具来增强长视频理解的基于记忆的系统。结果表明,逐步添加这些组件可提升基准性能,完整工具包取得最高分数,表明结构化、工具增强的推理优于直接全上下文处理。添加搜索能力使性能优于无工具的基线。引入图遍历进一步提升了超越仅搜索的性能。包含层级导航的完整工具包取得最高分,证明了多步结构化推理方法的有效性。
作者研究了不同最大上下文长度对基准性能的影响,观察到性能随上下文长度增加而提升,达到一定阈值后趋于稳定。结果表明,增加上下文长度会带来更高的分数与更多的推理轮次,最高分在上下文长度为 12 时取得,此后性能进入平台期。每轮 token 数量也随上下文长度增加而上升,反映了输入规模的扩大。性能随上下文长度增加而提升直至阈值,随后保持稳定。最高分在上下文长度为 12 时取得,表明输入规模与推理效果之间达到了最优平衡。更高的上下文长度需要每轮消耗更多 token,反映了计算负载的增加。

实验在长视频理解基准上评估了 MEMDREAMER 框架,证明解耦感知与推理在大幅提升准确率的同时显著降低了上下文需求。对比与消融实验验证,将更强的感知模型与先进推理架构配对可获得最大性能增益,而结合层级与基于图的记忆结构及顺序工具增强推理,显著优于扁平基线与直接上下文处理。最后,上下文长度分析揭示了一个性能趋于稳定的最优阈值,证实了结构化、记忆驱动的推理能有效平衡计算效率与持续的分析质量。