Command Palette
Search for a command to run...
软件工程的终结:AI智能体如何从根本上重构软件范式
软件工程的终结:AI智能体如何从根本上重构软件范式
Zhenfeng Cao
摘要
半个多世纪以来,软件工程一直基于一个基本前提:人类工程师负责分解问题,将决策逻辑编码为静态代码,并在需求演变时手动调整这些代码。本文认为,AI 智能体(AI agents)的出现——即以大型语言模型(LLM)作为主要推理引擎、动态生成并废弃代码作为工具性资源的系统——并非渐进式改进,而是软件范式的根本性重构。基于对复杂度扩展(complexity scaling)的第一性原理分析,我们形式化了传统软件与智能体系统之间的区别:在传统软件中,代码是决策逻辑的载体;而在智能体系统中,代码仅是服务于 LLM 驱动推理循环的临时性工具。我们追溯了从许可软件到软件即服务(SaaS),再到本文所称的“智能体即服务”(Agent-as-a-Service, AaaS)的历史演变,指出每一次范式转移都将更多的复杂性从最终用户处剥离。我们提出了“智能体工程”(Agentic Engineering)这一新兴学科的概念,指出其在核心研究对象、控制模型以及人类角色方面均与传统软件工程截然不同。通过对包括 SWE-bench Verified、EvoClaw 以及 LangChain 的多智能体协调研究在内的近期 benchmark 证据进行分析,我们展示了智能体范式的变革潜力及其当前的局限性。
一句话总结
本文认为,AI agents 通过将代码视为 LLM 驱动的推理循环中的临时工具而非决策逻辑的载体,从根本上重构了软件范式,并通过复杂度扩展的第一性原理分析将 Agentic Engineering 和 Agent-as-a-Service (AaaS) 形式化,同时通过 SWE-bench Verified、EvoClaw 和 LangChain 的 multi-agent 协调研究展示了其变革潜力和局限性。
核心贡献
- 这项工作通过复杂度扩展的第一性原理分析,形式化了传统软件与 agent 系统之间的区别,将代码定义为逻辑载体或临时工具。
- 本文提出了 Agentic Engineering 作为一个独立的新兴学科,并提出了 Agent-as-a-Service 这一术语,以描述从授权软件到 SaaS 的历史转变。
- 对 SWE-bench Verified 和 EvoClaw 等近期基准测试证据的分析,展示了 agent 范式的变革潜力及其在持续自主开发方面的当前局限性。
引言
传统软件工程依赖于人类工程师将决策逻辑编码到静态代码中,但随着系统交互呈组合式增长,该模型在指数级复杂度扩展方面面临困难。当前的 AI 增强开发方法未能从设计决策中消除人类瓶颈,并保持了传统软件生命周期的延迟。作者认为,AI agents 构成了软件范式的根本性重构,其中代码作为 LLM 驱动的推理循环的临时工具,而非系统本身。本文将这一转变形式化为 Agent-as-a-Service,并引入 Agentic Engineering 作为一个专注于意图架构和 multi-agent 协调的独立学科。
方法
所提出的 agent 系统在动态架构上运行,其中决策逻辑在运行时生成,而非静态预编程。如形式化模型所定义,AI agent 系统 A 由元组 A=(M,T,M,Π) 表征,其中 M 代表作为推理引擎的大型语言模型,T 表示可执行工具集,M 是记忆子系统,Π 是规划机制。
整体框架如下图所示,描绘了 LLM 推理核心在协调与外部环境交互中的核心作用。
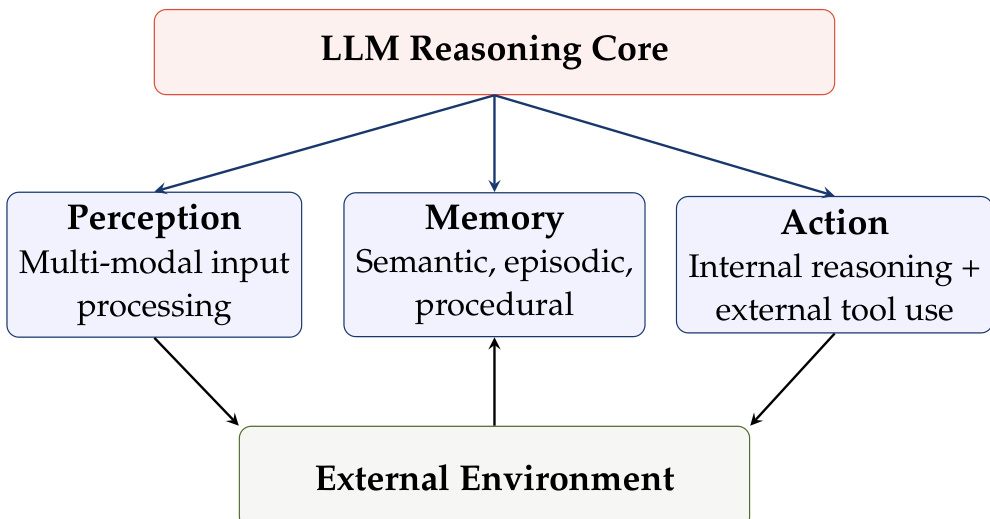
该架构由从核心分支出的三个主要功能模块组成。感知模块处理多模态输入,将原始环境数据转换为推理引擎可利用的格式。记忆模块管理语义、情景和程序性信息,允许系统保持上下文并从过去的交互中学习。行动模块涵盖内部推理过程和外部工具调用,使 agent 能够执行代码、查询数据库或调用 APIs。
系统通过迭代执行循环运行。在每个时间步 t,模型 M 根据当前状态 st 和记忆子系统 M 选择动作 at,形式化为 at←M(st,M)。然后系统通过执行所选动作更新状态,表示为 st+1←exec(at)。与传统软件中决策规则 D 固定不同,这种 agent 方法允许 LLM 根据中间结果动态生成代码并调整行为。这种范式将重点从交付软件制品转移到交付结果,其中 agent 自主规划、执行和验证任务以满足用户意图。
实验
利用 SWE-bench Verified 和企业调试工作流等基准测试的实证评估表明,通过以流程为中心的训练和 multi-agent 编排,agentic engineering 优于传统范式。这些研究验证了协调的 agents 可以减少调试时间并自主进化技能,但 EvoClaw 基准测试揭示了在持续软件进化方面的显著局限性。因此,虽然当前系统在软件生命周期中具有泛化能力,但在长期维护任务期间仍面临上下文漂移和错误传播的持续挑战。