Command Palette
Search for a command to run...
为何大模型学得更多:容量、干扰与罕见任务保留的影响
为何大模型学得更多:容量、干扰与罕见任务保留的影响
Jing Huang Daniel Wurgaft Rachit Bansal Laura Ruis Naomi Saphra David Alvarez-Melis Andrew Lampinen Christopher Potts Ekdeep Singh Lubana
摘要
大型模型能够掌握小型模型无法学习的任务。这一现象背后的驱动力是什么?我们提出了一种简单的现象学论证,指出幂律缩放(power-law scaling)本身即暗示:即使拥有无限训练数据,较大模型仍能够学习小型模型无法覆盖的数据分布的一部分。为验证这一主张并识别其成因,我们在一个由多个呈现单调缩放曲线的任务组成的合成设置中,研究了模型缩放的影响。结果表明,数据引发的资源(神经元)竞争是导致这一现象的关键。具体而言,小型模型倾向于将神经元资源分配给高频或低复杂度任务,因此它们学到的解决方案在罕见且复杂的任务上表现较差。值得注意的是,即使存在能够表达目标任务的解,这一现象依然存在。随后,我们评估了较大模型如何绕过这一以数据为中心的瓶颈,发现其根源在于一种降低干扰的机制:较大模型能够为常见任务分配足够的资源,使得针对这些任务的梯度更新变得微弱,从而避免在缓慢积累罕见任务特征时覆盖已有的相关知识。最后,为进一步验证上述观点,我们在频率和复杂度各不相同的新型任务上,对 OLMo 模型(参数量从 4M 至 4B)进行了预训练。
一句话总结
本研究提出了一种现象学论证,并通过合成任务混合体以及参数范围从 4M 到 4B 的预训练 OLMo 模型进行了验证,表明数据诱导的神经元竞争迫使较小的模型优先处理高频或低复杂度任务,而较大的模型则通过减少干扰来规避这一瓶颈,从而在梯度更新期间保留稀有任务特征。
核心贡献
- 本研究提出了一种现象学论证,表明幂律缩放允许较大的模型学习较小模型无法访问的数据分布部分,即使给定无限训练数据也是如此。该理论框架假设,缩放本质上提供了对数据分布低阶模式的访问。
- 一个由任务混合体组成的合成设置揭示了较小的模型将神经元分配给高频任务,导致由于数据诱导的资源竞争而在稀有和复杂任务上表现不佳。结果表明,较大的模型通过减少干扰机制规避了这一瓶颈,其中常见任务的梯度更新不会覆盖稀有任务特征。
- 该研究通过在参数范围从 4M 到 4B 的 OLMo 模型上预训练具有不同频率和复杂度的新任务来验证这些主张。这些实验实证支持了关于缩放如何通过减少干扰实现稀有任务学习的说法。
引言
现代机器学习依赖于大规模通用模型,尽管训练和推理成本高昂,但缩放参数的具体优势仍存在争议。先前的工作通常将性能差距归因于样本效率或表达能力,暗示较小的模型只要有足够的数据就能与较大的模型相匹配。研究认为,较小的模型面临根本性限制,即使有无限训练数据,它们也无法从数据混合体中学习稀有和复杂任务。研究利用合成回归设置并预训练 OLMo 模型,以验证较大的架构减少了任务间的梯度干扰。这种机制允许较大的模型保留来自低频数据的特征,而较小的模型由于资源竞争会覆盖这些特征。这种以数据为中心的解释说明了缩放的边际效益,并为模型大小和训练数据混合体的实际决策提供了信息。
数据集
数据集组成与来源
- 研究利用 Dolma v1.7 作为预训练语料库,具体选择了前 50K 批次,总计 210B tokens。
- 此数据遵循 OLMo-7B-0424 和 OLMo-7B-0724 训练运行所使用的确切 token 顺序。
- 两个特殊任务被注入语料库以控制任务频率:Comparison (TCMP) 和 Modular Addition (TADD)。
每个子集的关键细节
- 每个任务由 10K 个实例组成,编码为三 token 序列(TOK1, TOK2, LABEL)。
- TOK1 和 TOK2 从词汇表中随机采样的 100 个 tokens 集合中抽取。
- 双射映射将 0 到 99 的整数值分配给每个 token。
- Comparison 标签指示第一个 token 值是否小于第二个。
- Modular Addition 标签代表两个 token 值之和模 100。
- 实例按 50/50 分为训练和测试。
模型使用与训练混合体
- 参数范围从 4M 到 4B 的 OLMo 模型在具有不同注入频率的数据混合体上进行训练。
- 任务频率控制在 7.8×10−3 和 2.4×10−8 之间,模拟从每批次 1K 个实例到每 10 个批次 1 个实例的范围。
- 参考任务(Rcmp 和 Radd)从预训练数据中采样,以确保注入频率与自然任务频率匹配。
- 通过训练损失和测试准确率来衡量性能,以区分学习任务分布和记忆。
处理与注入策略
- 注入过程用任务序列加上文档结束 token 替换训练序列的前四个 tokens。
- 此替换确保注入的任务频率与标准预训练期间学习的任务相当。
- 分析特征几何结构和任务相关特征,以验证关于模型宽度和任务频率的缩放定律。
方法
研究建立了一个多任务学习框架,以调查模型容量如何决定学习不同频率和复杂度任务的能力。研究考虑了 K 个线性回归任务的混合体,其中第 kth 个任务出现的频率为 πk,并具有特定的协方差结构 Ck。学生模型采用共享宽度-N 编码器 U∈Rd×N,具有正交列,并配对特定任务的线性解码器 Dk。任务 k 的预测由 y^k=DkU⊤x 给出,总损失是所有任务的均方误差的加权和。
参考缩放机制图
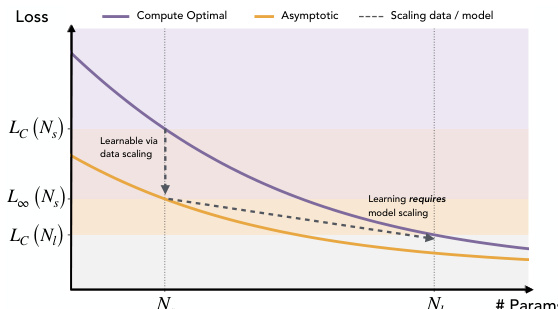
模型大小与损失之间的关系以不同的缩放机制为特征。如缩放机制图所示,在“计算最优”机制下运行的小模型可能通过数据缩放实现低损失,而较大的模型则过渡到“学习需要模型缩放”的机制。这一转变强调,增加参数数量(N)对于捕获与较小模型无法学习的稀有任务相关的低效用特征是必要的。
理论上,研究推导出特征是按其效用顺序学习的,效用定义为任务频率和特征特征值的乘积:
νk,j=πkλk,j宽度-N 模型的最优编码器跨越混合协方差矩阵 M=∑k=1KπkCk 的前-N 特征空间。因此,较大的模型保留效用较低的特征,有效地使其能够学习被较小模型忽略的更稀有或更复杂的任务。
参考对齐机制可视化
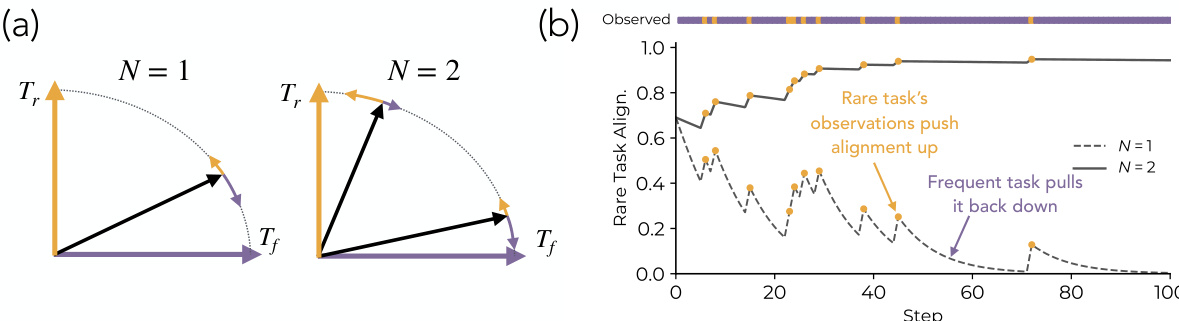
此选择过程可以通过梯度干扰和特征对齐的视角来理解。在几何表示中,编码器尝试与任务方向 Tf(频繁)和 Tr(稀有)对齐。对于窄模型(N=1),编码器被强烈拉向频繁任务方向,导致与稀有任务的对齐退化。随着宽度增加到 N=2,模型获得了同时跨越两个方向的能力。训练动态图证实了这一行为,表明虽然频繁任务观察将稀有任务对齐向下拉,但稀有任务观察将其向上推。较大的模型稳定了这一对齐,防止稀有任务被主导的频繁任务覆盖。
实验
合成回归和现实 OLMo 预训练管道上的实验表明,缩放模型宽度减少了频繁任务和稀有任务之间的干扰。较大的模型在观察间隙中保留稀有任务信号,而较小的模型表现出更新和遗忘的动态,其中频繁更新覆盖稀有特征。表示和梯度分析证实,增加容量能够在不损害常见任务性能的情况下实现低频任务的稳定学习。