Command Palette
Search for a command to run...
TESSERA:用于地球表示与分析的表面光谱时间嵌入
TESSERA:用于地球表示与分析的表面光谱时间嵌入
摘要
光学与微波波段的卫星地球观测(EO)时间序列,由于轨道运行规律及云层遮挡的影响,通常呈现不规则分布。影像合成(Compositing)虽能缓解这一问题,但会损失对许多下游任务至关重要的植被物候信息。为此,我们提出了 TESSERA,这是一款面向多模态(Sentinel-1/2)EO 时间序列的像素级基础模型,旨在学习鲁棒且具备高标签效率的嵌入表示(embeddings)。在模型训练阶段,TESSERA 采用 Barlow Twins 算法与稀疏随机时间采样,以强化对有效观测值选择变化的不变性。我们引入两项关键正则化策略:全局打乱(global shuffling)以解耦空间邻域的相关性,以及基于混合的策略(mix-based regulation)以提升在极端稀疏情况下的不变性。实验结果表明,在多样化的分类、分割及回归任务中,TESSERA 生成的嵌入表示在保持高标签效率的同时达到了最先进(state-of-the-art)的准确率,通常仅需配备小型任务头(task head)及极少的计算资源即可实现。为促进技术普及、遵循 FAIR(可发现、可访问、可互操作、可重用)原则并简化使用流程,我们发布了全球范围、年度更新、空间分辨率为 10 米的像素级 int8 嵌入数据,并公开了模型权重与代码以及轻量级适配头(adaptation heads),从而为行星规模的大规模检索与推理提供了实用的工具支持。所有代码与数据均可在 https://github.com/ucam-eo/tessera 获取。
一句话总结
TESSERA 是一种用于多模态 Sentinel-1/2 地球观测时间序列的像素级基础模型,它采用 Barlow Twins 和稀疏随机时间采样来学习能够保留植被物候的鲁棒嵌入,不同于合成方法,在分类、分割和回归任务中实现了最先进的准确率且具有高标签效率,并发布了全球年度 10m 像素级 int8 嵌入,开放权重和代码以支持行星级推理。
核心贡献
- TESSERA 是一种用于多模态 Sentinel-1/2 地球观测时间序列的像素级基础模型,利用 Barlow Twins 和稀疏随机时间采样学习鲁棒嵌入。
- TESSERA 嵌入在多样化的分类、分割和回归任务中提供了最先进的准确率,具有高标签效率和最小计算量。
- 全球年度 10m 像素级 int8 嵌入与开放权重和 GeoTessera 库一起发布,无需骨干微调即可实现分析就绪的使用。
引言
卫星地球观测时间序列由于云层覆盖和轨道限制经常不规则,但现有的基础模型通常依赖于丢弃有价值物候信息的预处理合成数据。这些先前的方法往往使表示偏向理想化条件,并需要计算密集的微调,为广泛采用造成了重大障碍。为解决这一问题,作者提出了 TESSERA,这是一种用于多模态 Sentinel-1 和 2 数据的像素级基础模型,利用 Barlow Twins 和稀疏随机采样强制对时间采样变异性保持不变性。他们引入了特定的正则化器来处理空间相关性和稀疏性,同时发布全球 10m 像素级嵌入和开放权重,以遵循 FAIR 原则,并实现高准确率和最小下游计算及强标签效率。
数据集
数据集组成与来源
- 作者使用从 2017 年至 2024 年 3,012 个全球分布的军事网格参考系统 (MGRS) 图块中提取的约 8 亿 d-pixels 对模型进行预训练。
- 图像数据来自 Sentinel-1(VV 和 VH 极化)和 Sentinel-2(10 个光谱波段)。
- 评估涵盖六个基准测试,包括 TreeSatAI-TS、PASTIS-R、Biomassters 和 Borneo Canopy Height。
- 为了解决数据稀缺问题,引入了两个新基准:用于地块级映射的 Austrian Crop 和用于森林结构的 Borneo Canopy Height。
每个子集的关键细节
- 预训练数据通过系统性地每隔 20 个像素取一个像素,在空间上以 400 倍因子进行下采样。
- Austrian Crop 数据集根据物候相似性将 154 种作物类型合并为 17 个更广泛的类别。
- BioMassters 包含芬兰近 11,500 个森林斑块,分辨率为 10 米,来自 LiDAR 的地上生物量值。
- 下游任务在 1%、30% 和 100% 标签比例下进行评估,以研究标签效率。
训练拆分与处理
- 预训练运行一个 epoch,使用全局洗牌策略以防止训练 batch 中的地理偏差。
- 时间序列通过稀疏时间采样固定为每个 d-pixel 40 个时间步。
- 如果特定位置可用的无云日期少于 40 个,则应用替换采样。
- 归一化的年日 (DoY) 值被编码为正弦和余弦特征,并与光谱测量值连接。
- 使用全局统计数据进行标准化以训练稳定性。
裁剪与元数据构建
- 为每个图块生成二值掩码,以标记特定空间坐标的云层覆盖或缺失数据。
- 对于 Austrian Crop 分割,该区域垂直分为五个部分,以提取 1,000 个测试 patch、1,000 个验证 patch 和 3,000 个训练 patch。
- 像素级分类拆分按面积百分比分配字段,以确保每个拆分中出现所有作物类别。
- 自定义管道管理超过 2 TB 初始 d-pixel 数据的洗牌和增强的高 I/O 需求。
方法
TESSERA 框架采用双分支编码器架构,旨在独立处理光学和雷达模态,然后将它们融合为统一表示。这种设计允许模型捕捉 Sentinel-2 多光谱图像和 Sentinel-1 合成孔径雷达 (SAR) 数据的独特物理特性。
模型架构
TESSERA 的核心由两个基于 Transformer 的并行编码器分支组成。每个分支接收掩码观测时间序列。有效观测首先通过线性投影 ϕ:RC→Rd 进行嵌入。为了保留时间上下文,可学习的年日 (DoY) 位置编码 ψ(⋅) 被添加到这些嵌入中:
et=ϕ(Pi.i(t))+ψ(DoY(t))生成的序列通过必要时替换采样填充到固定长度 L=40。然后,该序列由 4 层 Transformer 编码器处理,利用多头自注意力机制学习时间模式。基于 GRU 的池化层随后将时间序列聚合为固定大小向量 zmod∈R128。
光学嵌入 (zS2) 和雷达嵌入 (zS1) 被连接并通过 2 层 MLP 处理,以生成最终融合的 128 维嵌入 z。为了优化存储,应用感知量化训练 (QAT) 将 z 压缩为 8 位整数,实现约 4× 的存储减少,性能损失可忽略不计。在训练阶段,此融合嵌入使用深度投影 MLP 扩展到 16,384 维以进行损失计算,但该投影器在推理期间被丢弃。
参考下方的框架图,详细了解 TESSERA 处理管道,包括数据处理、双分支编码和损失计算阶段。
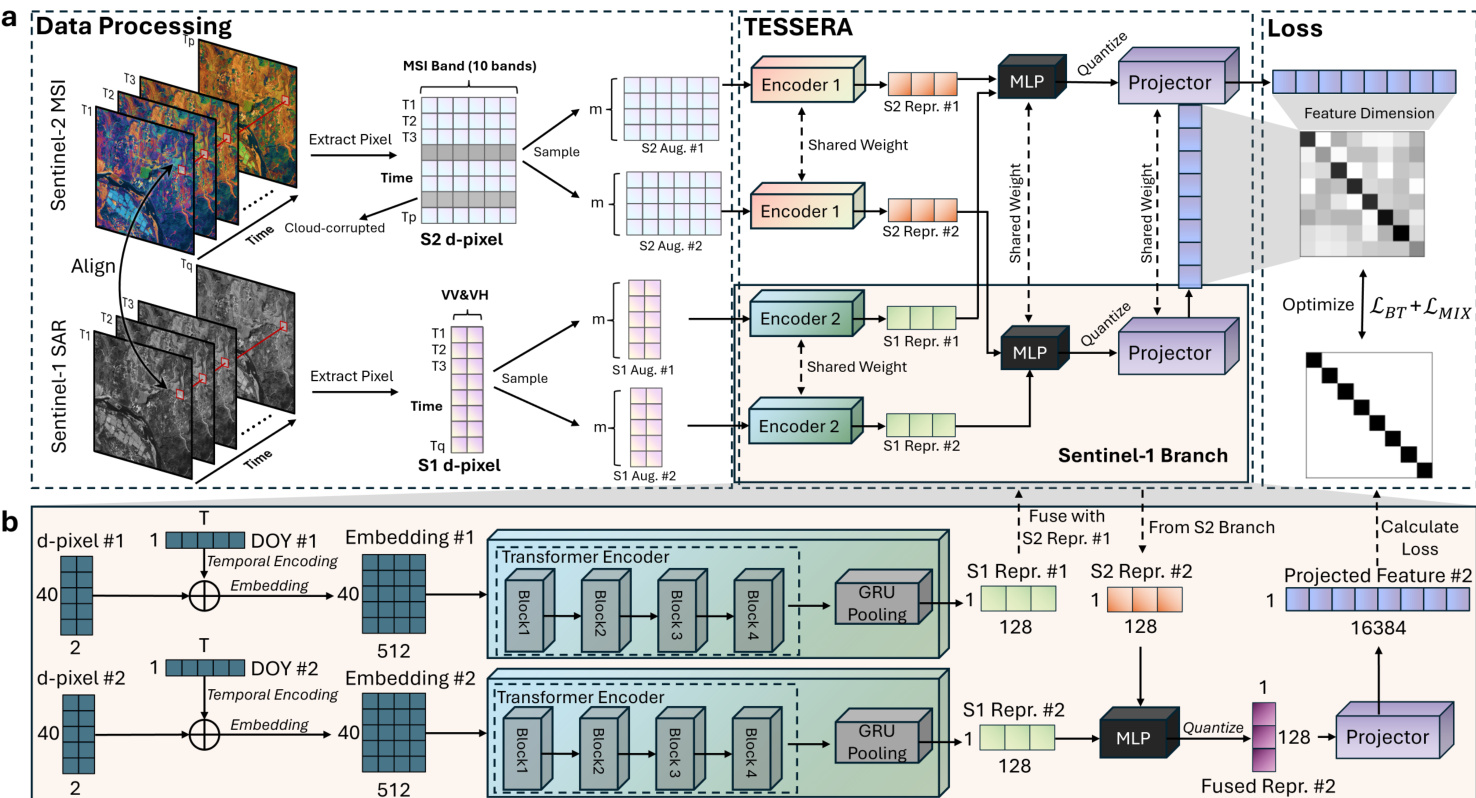
预训练与训练策略
TESSERA 在从 2017 年至 2024 年跨越的 3,012 个全球 MGRS 图块中采样的约 8 亿 d-pixels 上进行预训练。该模型利用基于 Barlow Twins 目标的自监督学习方法。对于每个 d-pixel,通过独立从 Sentinel-1 和 Sentinel-2 时间序列中采样 40 个有效时间步生成两个增强视图 (YA, YB)。
网络处理这些视图以生成批量归一化嵌入 ZA 和 ZB。标准 Barlow Twins 损失函数 LBT 最小化冗余维度之间的互相关,同时最大化不变特征的相关性:
LBT=i∑(1−Cii)2+λBTi∑j=i∑Cij2这里,C 表示 ZA 和 ZB 之间的互相关矩阵。为了进一步增强鲁棒性并减轻过拟合,结合了额外的混合正则化项 LMIX。这涉及通过在增强 batch 之间线性插值创建混合视图,并惩罚偏离输入空间线性插值对应于嵌入空间线性插值假设的偏差。
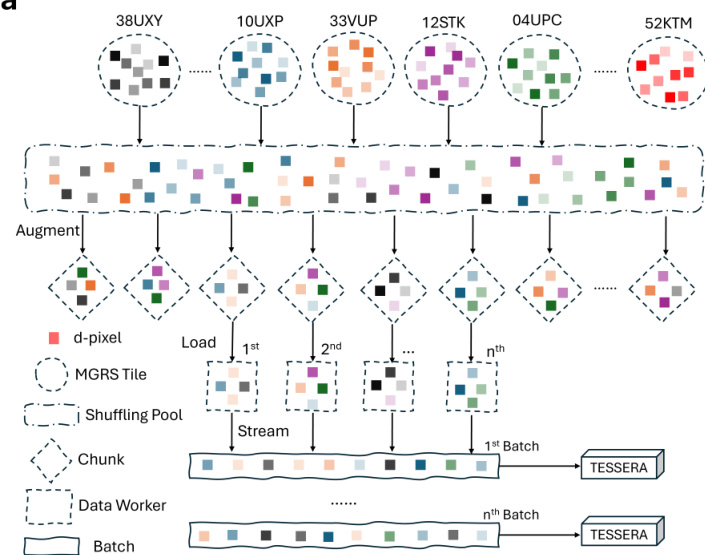
训练管道中的关键组件是全局洗牌策略。在 batching 之前,来自所有地理图块的 d-pixels 被全局随机化。这防止了空间自相关,并确保模型从每个 batch 内的多样地理和环境条件中学习。
如数据洗牌示意图所示,来自数千个 MGRS 图块的 d-pixels 被聚合到全局池中,洗牌,然后流式传输到充分多样化的训练 batch 中。
推理与嵌入即数据
预训练后,TESSERA 双编码器(权重冻结)用于为全球每个 10m 像素生成年度 128 维嵌入。这种“嵌入即数据”范式允许模型作为基础特征提取器,而不仅仅是特定任务的预测器。主要输出是一组分析就绪、无间隙的嵌入图。
对于下游任务,用户可以通过 GeoTessera Python 库直接访问这些嵌入。工作流涉及下载感兴趣区域的预计算嵌入,并训练轻量级特定任务头。对于像素级分类或回归,浅层多层感知机 (MLP) 通常足够。对于需要空间上下文的任务,如语义分割,卷积架构如 UNet 可以处理嵌入的 patch。
从数据请求到下游模型应用的整个生态系统如下方图所示,突出了冻结 TESSERA 嵌入生成与各种任务的灵活模型库之间的分离。

实验
实验在包括 TreeSatAI-TS 和 Austrian Crop 在内的基准测试上评估了模型在分类、分割和回归任务中的性能,以评估不同数据制度下的表现。TESSERA 通过利用像素级时间建模来捕捉物候变化,始终优于现有基础模型,在低标签场景中表现出特别强的优势。消融研究证实嵌入对云量和地理偏移具有鲁棒性,验证了单一全球模型足以用于不同区域而无需区域重新训练。此外,该框架遵循可预测的缩放定律并支持高效量化,以最小的计算和存储成本实现高分辨率全球分析。
作者通过比较其标准像素级模型与结合不同大小固定空间 patch 的变体来评估空间上下文的影响。结果表明,与空间变体相比,当前的像素级方法通常产生更优越的分类和回归性能。这一发现验证了保持像素级独立性并在预训练期间避免嵌入固定空间先验的设计选择。基线像素级模型在测试配置中实现了最高的 F1 分数和最低的回归误差。引入更大的空间 patch 略微提高了分割指标,但导致回归性能显著下降。具有 3x3 patch 的中间空间变体在所有报告的指标上均表现不如基线。

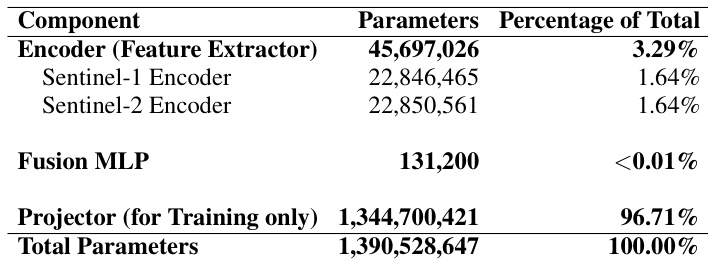
该表详细说明了模型的参数分布,显示用于训练的项目器网络主导了架构,占据了绝大多数参数。相比之下,卫星数据的实际特征提取编码器非常紧凑,仅占总模型大小的一小部分。连接不同卫星模态的融合机制极其轻量级,对总参数计数贡献可忽略不计。训练时项目器占据了模型总参数的绝大部分。特征提取编码器非常高效,仅占总参数的一小部分。融合 MLP 大小可忽略不计,表明多模态数据的集成非常轻量级。
作者在 Austrian Crop 数据集上评估了不同标签比例下的作物分类性能。TESSERA 在所有监督级别上始终优于 Presto 和 AlphaEarth 等基线模型。结果表明,在低数据制度中,所提出的模型保持了高准确率,而竞争对手显示出显著较低的性能,具有卓越的鲁棒性。TESSERA 在所有测试的标签比例下实现了最高的性能分数。该模型在少样本学习设置中表现出与竞争对手的显著性能差距。准确率随着监督的增加稳步提高,所提出的方法在所有数据水平上领先。

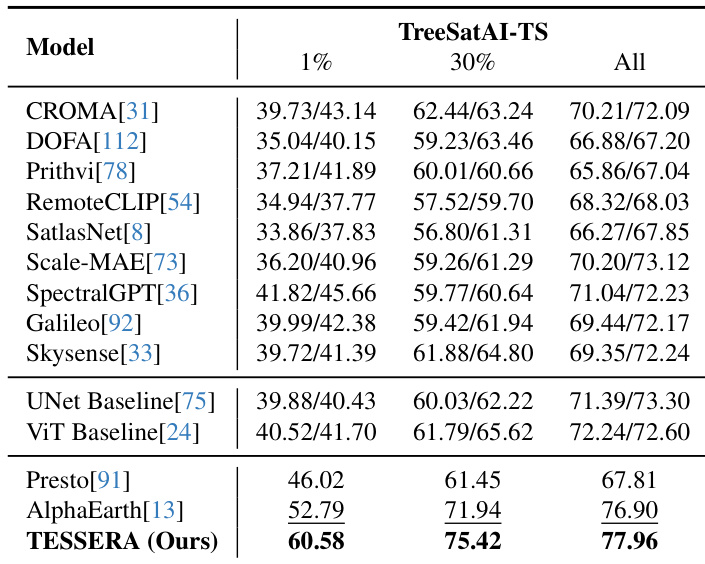
作者在 TreeSatAI-TS 基准测试上展示了分类结果,将其模型与各种基础模型和基线进行比较。结果表明,所提出的方法在从少样本到完全监督的所有数据制度中始终实现最高性能。这表明与现有方法相比,在捕捉物候变化和类别可分性方面具有更优越的能力。该模型在完全监督设置中稳居榜首,优于下一个最佳竞争对手。在少样本设置中观察到显著的性能提升,该模型以较大优势领先其他方法。在 30% 标签制度下,针对一系列既定基线,始终保持超额表现。
作者介绍了 TESSERA,这是一个能够处理多时间和多模态数据的模型。其参数计数与其他高效模型如 AlphaEarth 和 Presto 相当,同时显著小于 SpectralGPT 等更大架构。这种设计允许高效处理,同时在各种任务中保持竞争性性能。TESSERA 支持多时间和多模态输入,而几个基线缺乏一种或两种能力。该模型保持与 AlphaEarth 和 Presto 相似的紧凑参数大小。它明显小于 SpectralGPT 和 ViT-B/16 等更大架构。
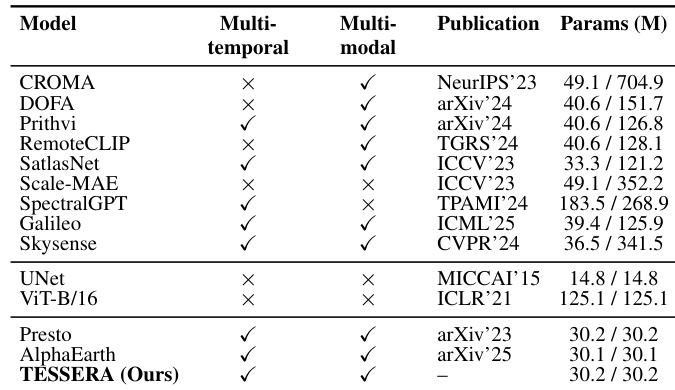
评估空间上下文和参数分布的实验证实,像素级方法和紧凑编码器设计产生了卓越的性能和效率。TESSERA 在不同监督级别上始终在 Austrian Crop 和 TreeSatAI-TS 基准测试上优于基线方法,在低数据制度中表现出特别强的鲁棒性。此外,该架构支持多时间和多模态输入,同时保持与现有高效模型相当的参数计数。