Command Palette
Search for a command to run...
轨迹精炼蒸馏
轨迹精炼蒸馏
Li Jiang Haoran Xu Yichuan Ding Amy Zhang
摘要
基于策略蒸馏(On-policy distillation, OPD)已成为大语言模型(LLMs)后训练阶段的核心工具,它通过在学生的自身轨迹(rollouts)上提供密集的逐 token 教师监督信号来发挥作用。在本研究中,我们识别出 OPD 背后一个常见的结构性成因,将其称为“前缀失败”(prefix failure)。在前缀失败的情境下,密集的逐 token 监督会导致教师混合分布呈现双峰特性,并产生碎片化的梯度,而现有的基于 token 层面的损失截断或重加权技术均无法有效解决这一问题。这一发现促使我们将干预重点从 token 层面的损失调整转向轨迹层面的输出校正。为此,我们提出了轨迹 refined 蒸馏(Trajectory-Refined Distillation, TRD),这是一种轨迹层面的校正方法。该方法在遵循 on-policy 支持域的前提下,依据教师指导对学生的 rollout 进行修正。TRD 通过在蒸馏前校正有问题的前缀,从源头上缓解了前缀失败问题。此外,即使原始轨迹本身是正确的,TRD 仍能通过让学生模型在教师指导下接触其他有效的推导路径,从而提升探索能力。TRD 同样可应用于基于策略的自蒸馏(On-policy self-distillation, OPSD),这是一种参数共享变体,其利用以特权信息(privileged informations)为条件的学生模型作为教师。
一句话总结
这项工作提出了轨迹细化蒸馏(TRD),这是一种针对大型语言模型的轨迹级校正方法,通过在教师指导下修订学生 rollout 以减轻前缀失败,解决梯度碎片化问题并改善超越 token 级干预的探索,适用于在线策略蒸馏和在线策略自蒸馏设置。
核心贡献
- 该工作识别并形式化了前缀失败作为在线策略蒸馏中的结构性原因,其中密集监督创建了双峰教师混合,而 token 级损失干预无法解决这一问题。这一诊断见解确立了轨迹级校正相对于每 token 损失重加权的必要性。
- 该论文引入了轨迹细化蒸馏(TRD),这是一种轨迹级校正方法,在保留在线策略支持的同时,在教师指导下修订学生 rollout。TRD 从源头减轻已识别的失败模式,并通过在细化过程中向学生暴露替代有效推导来增强探索。
- 在五个竞赛数学基准和代码生成任务上的实验表明,TRD 在使用 Qwen3 模型时实现了相对于基线的最佳平均性能。该方法在 AMOBench 数据集上显示出显著增益,在在线策略自蒸馏设置下,Qwen3-8B 的 Pass@16 相对提升约为 50%。
引言
在线策略蒸馏作为大型语言模型的关键后训练机制,通过在学生 rollout 期间提供密集的 per-token 教师监督发挥作用。尽管其被广泛采用,基础方法通常会遇到前缀失败,其中错误推理路径创建了碎片化梯度,而 token 级损失重加权无法解决。作者提出了轨迹细化蒸馏(TRD)来解决这一结构性限制,通过将 per-token 调整转变为轨迹级输出校正。TRD 在教师指导下修订学生 rollout,以在源头减轻前缀失败,同时在标准和自蒸馏设置中的各种数学和代码基准上增强探索。
方法
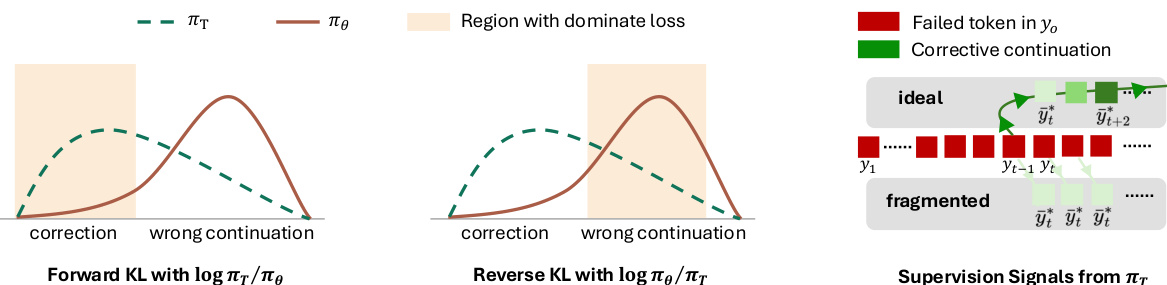
标准在线策略蒸馏(OPD)和在线策略自蒸馏(OPSD) suffer 于一种称为前缀失败的结构性限制。当学生模型生成错误推理路径时,教师分布变为混合模式:一种为了连续性继续错误,另一种转向正确解决方案。这创建了一个嘈杂的监督信号。如下方图所示,KL 散度的选择与此混合不对称地相互作用。前向 KL 具有覆盖模式特性,主导了对学生而言分布外的校正区域,可能导致不稳定。相比之下,反向 KL 具有寻求模式特性,专注于学生已经放置高概率质量的错误延续区域,实际上忽略了校正信号。此外,标准蒸馏生成分碎片化梯度,因为教师在每一步都基于冻结的失败前缀而不是展开的校正路径进行条件化。
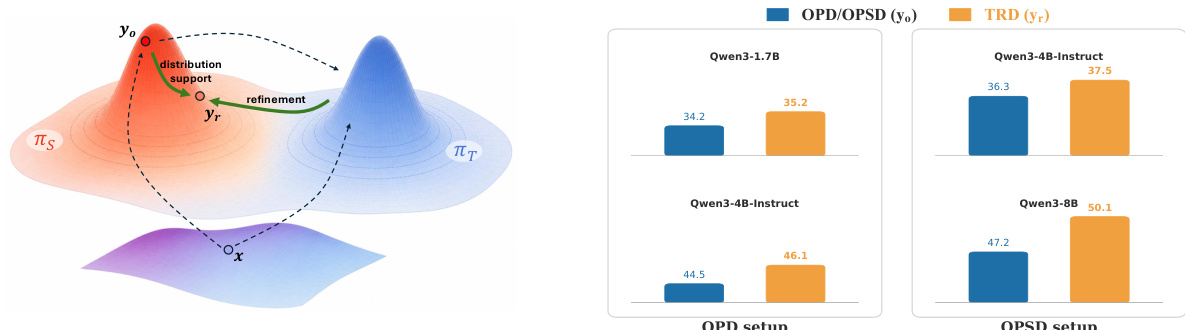
为了克服这些问题,作者引入了轨迹细化蒸馏(TRD)。该方法在轨迹级运行,以优化预期验证器通过率,同时尊重在线策略支持约束。参考框架图以可视化细化过程,其中教师从学生的初始 rollout yo 开始构建校正轨迹 yr。训练过程涉及三个主要步骤。首先,学生采样原始 rollout yo∼πθ(⋅∣x)。其次,教师生成细化轨迹 yr∼πT(⋅∣x,yo)。在 OPSD 设置中,教师共享学生参数,但基于特权信息进行条件化,例如参考解决方案 y∗。第三,学生更新以匹配细化轨迹 yr 的分布。
蒸馏目标使用前向 KL 散度和全词汇匹配以提供稳定的覆盖模式监督。损失函数定义如下:
L(θ)=Ex∼Dyo∼πθ(⋅∣x)yr∼πT(⋅∣x,yo)∣yr∣1t=1∑∣yr∣D(sg[πT(⋅∣x,yo,yr,<t)]πθ(⋅∣x,yr,<t))通过沿细化轨迹 yr 而不是原始 rollout yo 进行监督,TRD 恢复了理想的梯度结构。监督上下文沿校正路径本身增长,而不是锚定在失败前缀上。这允许学生学习校正的多步展开,而不是接收碎片化信号。此外,这种方法通过揭示教师建议的学生可能无法独立采样的替代有效推导来增强探索。
实验
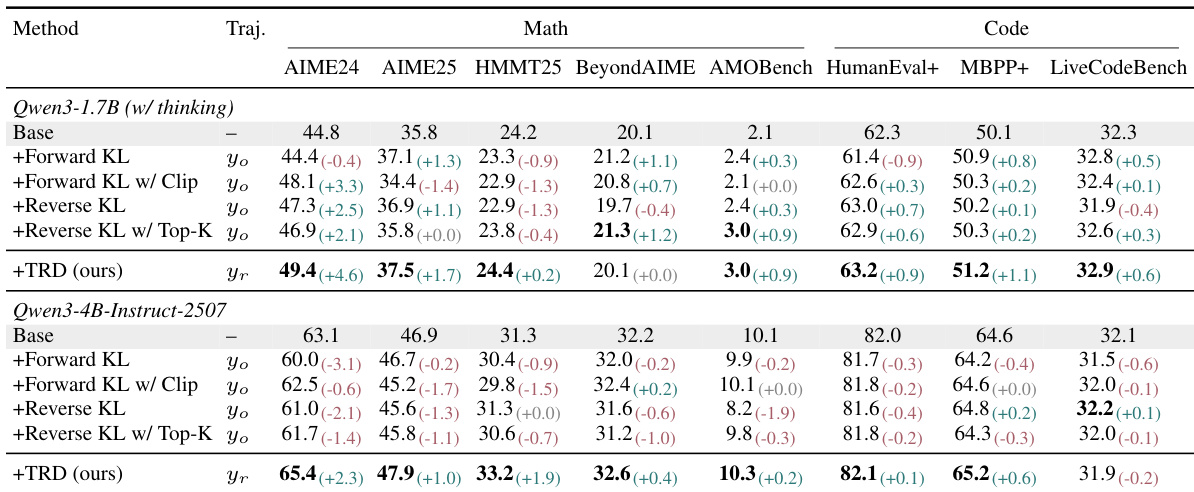
该研究在数学和代码基准上使用 Qwen3 模型,在 OPD 和 OPSD 设置下评估了所提出的 TRD 方法与标准密集 KL 基线。实验通过证明标准 KL 监督在错误 rollout 上提供递减信号,而 TRD 成功细化轨迹以校正死胡同前缀而不破坏现有能力,验证了前缀失败机制。定性分析显示,TRD 生成显著更短且更准确的推理路径,通过在难题上扩展可达解空间同时保持训练稳定性,始终优于基线。
作者在数学和代码基准上使用 Qwen3 模型评估 TRD 与四个密集 KL 基线。结果显示,TRD 在大多数指标上始终优于基础模型和其他方法,而标准基线相对于基础模型经常降低性能。TRD 在两个模型规模的大部分数学和代码基准上实现了最高性能。基线方法经常显示出相对于基础模型的负改进,特别是在数学任务上。TRD 成功提高了 HumanEval+ 和 MBPP+ 代码基准的性能,而其他方法在这些基准上挣扎。
该表详细说明了研究中评估的所提出 TRD 方法和四个密集 KL 基线的超参数配置。基线设置用于使用基础提示和较短序列限制在原始学生 rollout 上训练,而所提出方法使用细化轨迹和细化提示以及更长的上下文窗口。这一设置支持实验发现,即所提出方法通过避免前缀失败和提供更好的监督信号优于基线。基线利用原始在线策略 rollout 进行训练,而所提出方法采用细化轨迹。所提出方法配置了细化教师提示,不同于基线使用的基础提示。所提出方法支持比基线配置更长的最大训练序列长度。

该表比较了 OPD 和 OPSD 训练设置与 Teacher 模型在五个数学基准上的性能,使用 Avg@16 和 Pass@16 指标。结果表明,虽然 Teacher 模型通常保持最高性能,但 OPSD 设置倾向于在大多数基准上实现更高的 Pass@16 分数,而 OPD 在特定数据集上显示出更强的 Avg@16 性能。OPSD 在大多数基准上实现了比 OPD 更高的 Pass@16 分数。OPD 在 AIME24 和 HMMT25 上记录了比 OPSD 更好的 Avg@16 结果。Teacher 模型在所有报告的指标上始终优于两个学生设置。

作者通过在 OPSD 设置下比较完整细化训练语料库与按轨迹结果过滤的消融子集来评估 TRD 方法。结果显示,完整数据集在多个数学基准上始终优于受限子集和基础模型。这表明利用细化轨迹的完整广度对于最大化性能至关重要,特别是在 Pass@16 指标上。完整 TRD 方法在所有基准上实现了最高性能,优于基础模型和过滤变体。将训练语料库限制为特定轨迹结果会导致与使用完整细化数据集相比的性能显著下降。实验证实,来自完整语料库的多样化训练信号对于提高模型能力比特权子集更有效。

作者在 OPSD 设置下使用 Qwen3 模型评估 TRD 与四个密集 KL 基线。结果表明,TRD 在所有数学基准上始终匹配或超过基础模型的性能,而标准 KL 基线经常降低性能或显示混合结果。具体而言,TRD 为较大模型在更难基准上带来显著增益,同时不牺牲饱和任务上的性能。TRD 在饱和基准上保留基础模型的性能,同时在两个模型规模上更难的任务上实现一致改进。标准密集 KL 基线经常回退到低于基础模型性能,特别是在较小学生模型上,而 TRD 保留基础能力。带有 TRD 的较大模型与基础和其他细化方法相比在困难基准上显示出显著增益。
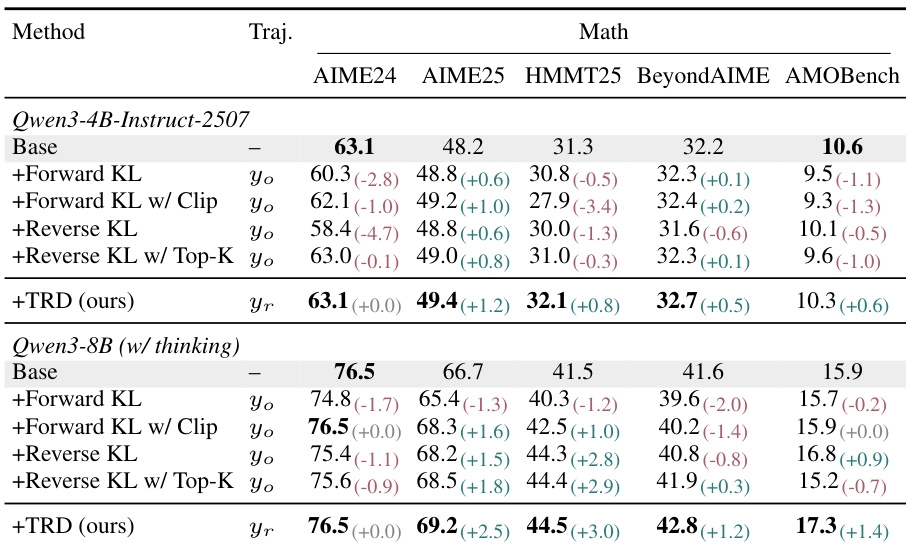
作者在 OPSD 设置下使用 Qwen3 模型在数学和代码基准上评估 TRD 与密集 KL 基线和 Teacher 模型,采用细化轨迹和更长上下文窗口。结果表明,TRD 始终优于基础模型和其他方法,而基线方法经常降低性能,特别是在数学任务上。此外,消融研究证实完整细化训练语料库对于最大化能力至关重要,允许 TRD 在困难基准上改进而不牺牲饱和任务上的性能。