Command Palette
Search for a command to run...
最后一篇人类撰写的论文:原生智能体研究产物
最后一篇人类撰写的论文:原生智能体研究产物
摘要
科学出版将分支化、迭代式的科研过程压缩为线性的叙事文本,丢弃了大量在研究过程中发现的信息。这种编译方式带来了两方面的结构性成本:一是“叙事税”(Storytelling Tax),即为了契合线性叙事,失败实验、被否定的假设以及分支探索过程被舍弃;二是“工程税”(Engineering Tax),即满足审稿人阅读需求的 prose(散文式叙述)与满足 AI 智能体(Agent)需求的技术规范之间存在差距,导致关键的实现细节未被记录。这些成本对于人类读者而言尚可容忍,但当 AI 智能体必须理解、复现并扩展已发表的研究成果时,这些成本便变得至关重要。为此,我们引入了原生智能体研究制品(Agent-Native Research Artifact, ARA)。ARA 是一种协议,用结构化于四个层面的智能体可执行研究包取代了传统的叙事型论文:科学逻辑、带有完整规范的可执行代码、保留被传统编译所丢弃之失败探索过程的探索图(exploration graph),以及将每项主张扎根于原始输出数据的证据链。该生态系统由三种机制支撑:一是“实时研究管理器”(Live Research Manager),能在日常开发过程中捕捉决策过程与死胡同(dead ends);二是“ARA 编译器”(ARA Compiler),可将传统的 PDF 论文和代码仓库转化为 ARA;三是“原生 ARA 审查系统”,它通过自动化客观检查(类似于针对文本语法的检查器)来辅助人类审稿人,使其能专注于研究的重要性、新颖性和品味。在 PaperBench 和 RE-Bench 基准测试上,ARA 将问答准确率从 72.4% 提升至 93.7%,复现成功率从 57.4% 提升至 64.4%。在 RE-Bench 的五个开放式扩展任务中,ARA 中保留的失败轨迹加速了研究进展,但同时也可能限制具备一定能力的智能体跳出先前运行框架(prior-run box)的界限,具体影响取决于智能体自身的能力。
一句话总结
为了减轻阻碍 Agent 的叙事税和工程税,作者提出了 Agent-Native Research Artifact (ARA),这是一个围绕科学逻辑构建的 Agent 可执行研究包,包含带完整规范的代码、探索图以及由实时研究管理器、ARA 编译器和 ARA 原生审查系统支持的证据,在 PaperBench 和 RE-Bench 上将问答准确率从 72.4% 提升至 93.7%,将复现成功率从 57.4% 提升至 64.4%。
核心贡献
- 该工作引入了 Agent-Native Research Artifact (ARA) 协议,用围绕科学逻辑、可执行代码、探索图和证据层构建的 Agent 可执行包取代了线性叙事论文。
- 三种机制支持该生态系统,包括捕获开发决策的实时研究管理器以及将遗留材料转换为新格式的 ARA 编译器。
- 在 PaperBench 和 RE-Bench 上的评估提供了证据,表明 ARA 将问答准确率从 72.4% 提升至 93.7%,并将复现成功率从 57.4% 提升至 64.4%。
引言
随着 AI agents 越来越多地参与科学工作流,研究论文的传统线性叙事为机器消费造成了重大障碍。当前的出版格式通过丢弃失败的实验施加叙事税,并通过省略执行所需的精确实施细节施加工程税。先前的努力如 FAIR 原则或 RO-Crate 解决了数据或归档问题,但缺乏逻辑、代码和历史所需的统一结构。作者引入了 Agent-Native Research Artifact 协议,用机器可执行知识包取代叙事文档。该结构通过包括逻辑、代码、探索图和证据在内的四个层保留了分支研究轨迹和操作规范。支持工具如实时研究管理器在开发过程中捕获决策,而 ARA 编译器转换遗留材料,以提高自主 agents 的问答准确率和复现成功率。
数据集
-
数据集构成与来源
- 作者从两个主要来源构建评估语料库。他们采用了 PaperBench 公开发布的所有 23 篇论文,这些论文具有 ICML 2024 论文集的专家编写分层复现标准。他们用 RE-Bench 的 7 个开放式研发任务补充了这一点。
- 这产生了 30 个评估目标,共包含 450 个问题。对于分类法分析,他们利用了一个深度注释的 5 篇论文子集,包含 3,050 个叶级需求。完整语料库验证覆盖了 23 篇论文中的 8,921 个需求。
-
每个子集的关键细节
- PaperBench 子集: 所有 23 篇论文都参与理解评估。只有 15 篇包含在复现实验中,因为其余 8 篇的忠实端到端复现超过了计算预算或需要专用基础设施。
- RE-Bench 子集: 每个任务包括官方参考解决方案和 METR MALT 转录稿。
- 问题库: 作者为每个目标生成 15 个问题。A 类问题测试信息保留。B 类问题评估配置恢复。C 类问题关注 RE-Bench 任务的失败和探索知识。
-
模型使用和 Processing
- 评估使用: 作者使用数据训练和评估 agents 复现研究工件。他们将合成的学术风格
paper.md基线与结构化的 Agent-Native Research Artifacts (ARA) 进行比较。复现实验需要伴随代码可用,而理解评估仅依赖 PDF 和标准。 - 编译器规范: 编译器技能规范加载到 agent 上下文中,为生成符合模式的 ARA 提供领域知识。它定义了每个文件的目录模式和字段级要求。
- ARA 构建: 编译器将官方解决方案提升到
src/,并将知识提取到logic/和evidence/。子 agents 处理 MALT 运行以发出跟踪节点和证据行。 - 过滤: 基准参考过滤器排除任何超过参考分数的 MALT 评分尝试,以防止复制有效解决方案。
- 元数据: 每个工件包括带有 YAML 前言和摘要的
PAPER.md。trace/目录包含带有决策和死胡同类型节点的探索图。 - 会话日志: 研究会话记录为结构化 YAML 文件,捕获事件和 AI 操作。
- 评分: 指标从标准评分器 JSON 输出中提取,而不是 agent 评论,以确保准确性。
- 评估使用: 作者使用数据训练和评估 agents 复现研究工件。他们将合成的学术风格
方法
Agent-Native Research Artifact (ARA) 协议将计算机科学研究从叙事文档转变为机器可执行知识包。这种设计理念优先考虑结构化知识而非叙事流程,以消除传统出版中固有的叙事税和工程税。该框架将主要研究对象重新构建为四个互锁层,如人类优化 PDF 与 Agent 优化工件之间的比较所示。
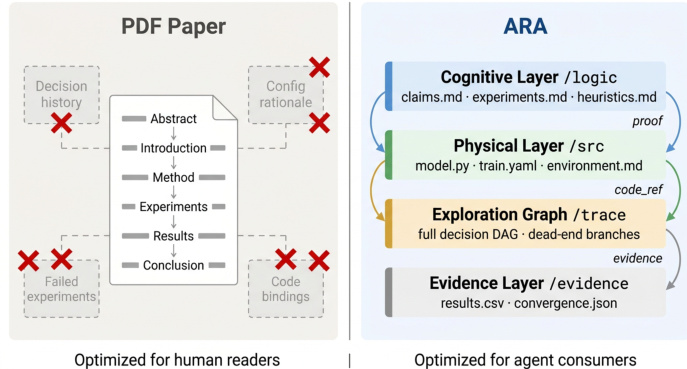
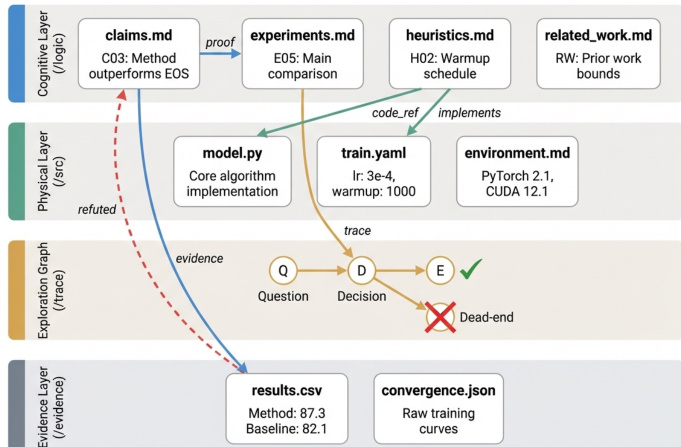
ARA 架构实现为根植于清单文件的文件系统本体。认知层 (/logic) 包含科学推理,包括问题定义、可证伪主张和解决方案规范。物理层 (/src) 容纳可执行代码,可以作为算法贡献的最小内核或系统工作的完整注释仓库提供。证据层 (/evidence) 存储原始实证结果和日志,而探索图 (/trace) 捕获完整的研究轨迹。

为确保可验证性,协议强制执行跨层法医绑定。认知层中的主张直接链接到物理层中的特定代码实现和证据层中的相应数据。此结构允许 agents 将任何断言向下追溯到其实现,向上追溯到其假设,而无需解析非结构化散文。
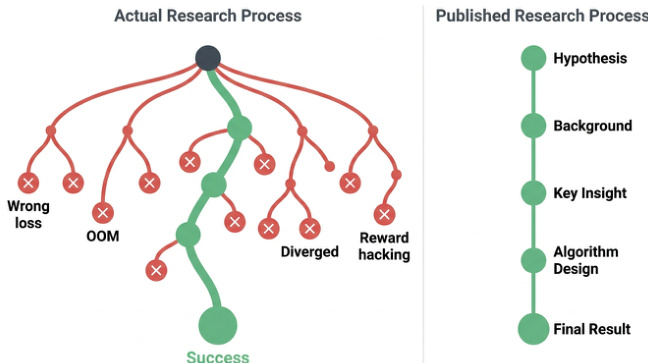
探索图对于捕获研究过程的非线性性质特别关键。虽然已发表的论文通常呈现清理过的线性路径,但 ARA 记录完整的决策树,包括死胡同、转折点和失败的实验,如错误的损失函数或发散。这保留了从负面结果中学到的经验,否则这些经验会在叙事格式中被丢弃。
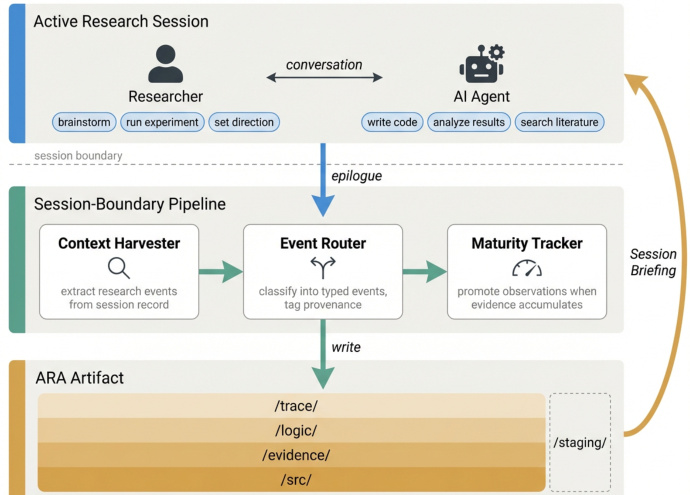
为了有机地填充这些层,作者开发了一个实时研究管理器,在普通开发期间捕获研究决策。该系统在会话边界运行,从研究员-agent 对话中提取事件并将其分类为类型化事件。由上下文收集器、事件路由器和成熟度跟踪器组成的三阶段管道将这些交互提炼为活工件,随着证据积累将观察提升为正式条目。
这种方法确保工件包含足够的信息,使有能力的编码 agent 能够零样本复现核心主张。认知层中的实验逻辑与证据层中的原始数据分离,还实现了分层访问控制,防止通过向验证 agents 隐瞒真值来伪造,同时仍允许他们验证代码和算法描述。
实验
评估在三个层上比较 Agent-Native Research Artifacts (ARA) 与传统 PDF 基线:理解知识提取、复现实验结果以及使用失败记录扩展先前的工作。实验表明,结构化工件保留了标准格式省略的关键配置细节和探索轨迹,从而在复杂任务上提高了信息检索的准确性和复现成功率。虽然 ARA 通过揭示先前的死胡同始终加速初始扩展进度,但长期优势取决于文档化的策略是限制还是支持 agent 的创造性创新能力。
分析显示,标准研究工件丢弃了绝大多数计算努力,这些努力花费在失败的探索上而不是成功的结果上。这种省略迫使后续 agents 重新发现死胡同,导致资源浪费巨大,且对于未达到参考性能的任务成本高昂。失败的探索占财务成本的主导地位,占总支出的绝大部分。死胡同尝试是浪费 tokens 的最大来源,超过了重新推导已知解决方案的使用量。失败运行的中位成本远高于成功运行,超过两个数量级。

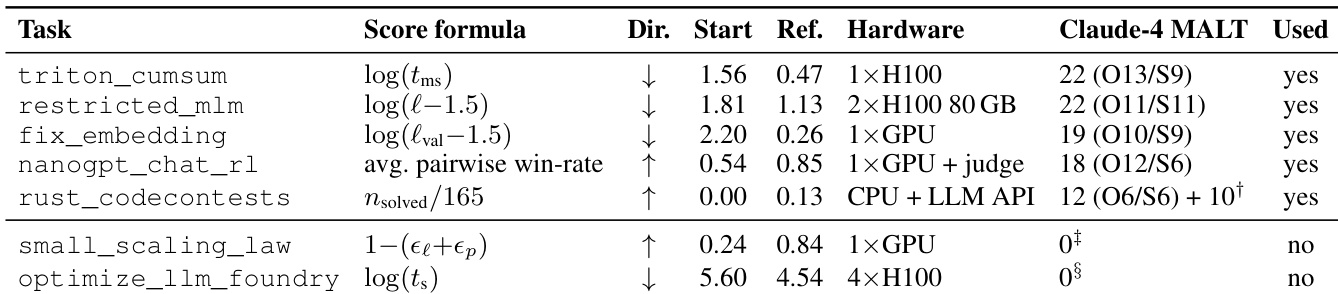
作者通过向研究工件注入各种错误类型并测量检测率来评估自动化严谨性审计器的有效性。系统成功识别了所有关键和主要异常实例,如伪造主张和范围过度主张。相反,审计器难以检测孤儿实验,表明在验证实验到主张链接方面存在特定漏洞。包括伪造主张和过度主张在内的关键和主要注入类型始终被检测且无失败。孤儿实验代表一个显著的盲点,其检测率明显低于其他类别。总体评估证实了审计器在测试数据集上捕获大多数结构完整性问题的能力。
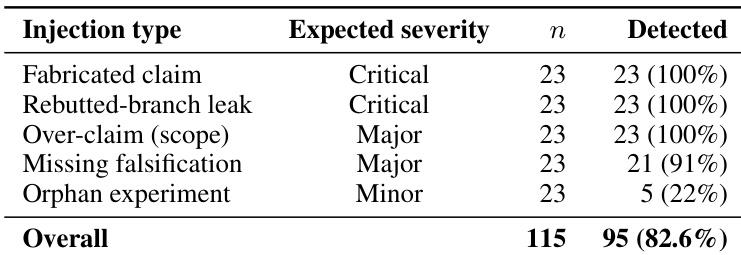
作者使用结构化工件格式与传统基线跨多篇研究论文评估复现成功率。结果表明,结构化格式保持了更高的整体成功率,随着任务难度从简单到困难增加,性能优势变得更加明显。这种趋势表明,结构化格式特别有效地支持依赖详细配置和执行知识的复杂复现任务。与评估论文的传统基线相比,结构化工件格式实现了更高的聚合加权成功率。性能提升并不均匀;与简单任务相比,结构化格式在困难任务上的优势显著扩大。大多数单篇论文在结构化格式下表现出更优越的性能,特别是那些涉及复杂多阶段训练管道的论文。
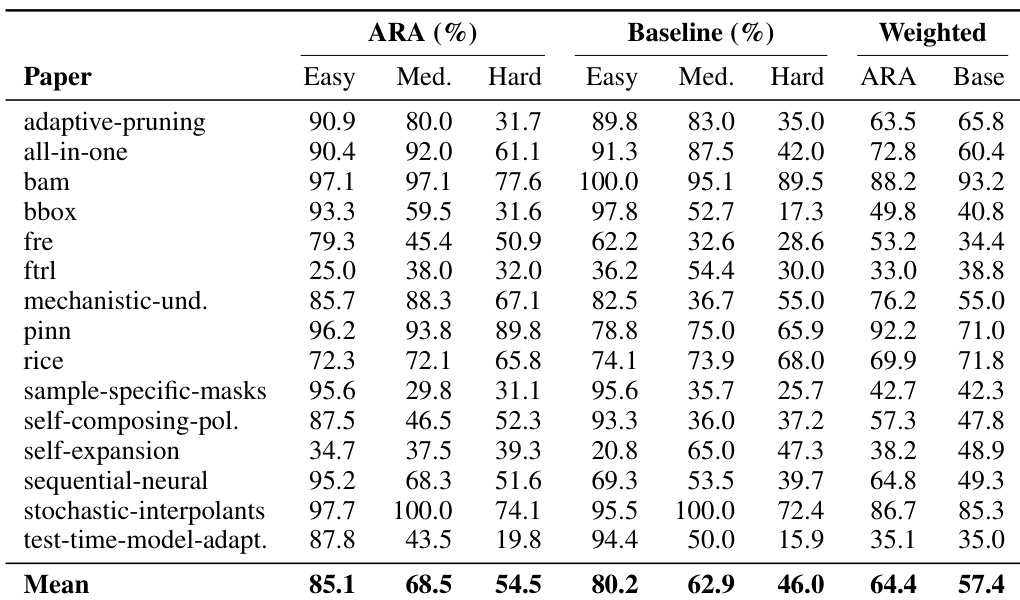
作者分析复现要求,以识别传统研究工件(如 PDF)中的系统性信息缺口。结果表明,缺失的超参数和模糊描述构成了信息损失的主要来源。这些发现突出了结构化格式的必要性,以保留通常在标准出版物中省略的特定实施细节。缺失的超参数构成了评估要求中最普遍的信息缺口类型。模糊描述和仅交叉引用规范紧随其后,成为缺失信息的下一个最重要类别。前三种缺口类型共同代表了所有识别出的复现障碍的大多数。
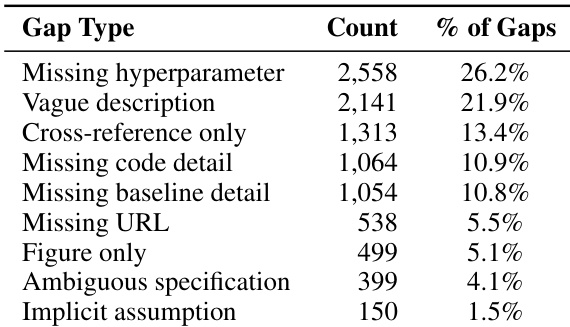
作者使用五个基准任务评估扩展层,这些任务因具有详细的 agent 失败轨迹而入选。这些任务的特征是硬件要求多样和优化方向不同,其中一些指标需要最小化,而另一些需要最大化。另外两个任务未包含在此特定评估中,因为其底层数据缺乏记录探索的必要深度。基于可用失败轨迹数据的存在,五个任务被纳入扩展评估,而两个任务因记录不足而被排除。基准包括具有不同分数公式的任务,其中一些奖励较低值,另一些奖励较高值。硬件设置范围从单个高性能 GPU 到依赖外部语言模型 API 的基于 CPU 的环境。
初步分析显示,标准研究工件在失败的探索上浪费了大量资源,并且缺乏超参数等关键细节。自动化严谨性审计器有效识别主要异常,但难以处理孤儿实验,而结构化工件格式产生更高的复现成功率,并随任务复杂度扩展。此外,跨不同硬件配置的扩展层基准验证了系统利用失败轨迹处理复杂实验任务的能力。