Command Palette
Search for a command to run...
VoxCPM2 技术报告
VoxCPM2 技术报告
VoxCPM Team
摘要
我们推出了 VoxCPM2,这是一个完全开源的多语言、可控制语音生成基础模型,它扩展了 VoxCPM 的分层扩散-自回归建模范式。VoxCPM2 在三个关键维度上提升了该框架:(i) 能力方面,在单个骨干网络中统一了 30 种语言、9 种中文方言、自然语言语音设计、风格可控语音克隆以及高保真延续克隆;(ii) 质量方面,通过使用非对称 AudioVAE(以 16 kHz 编码,以 48 kHz 重构),实现了具有高效编码能力的隐式超分辨率;(iii) 规模方面,将模型参数规模扩展至 20 亿(2B),并将训练数据规模扩展至超过 200 万小时的多语言语音。为了在一个模型中支持这些多样化的能力,我们引入了一种统一的序列组织结构,通过不同排列相同的输入构建块来表达所有生成模式,从而允许在单一参数集和目标函数下进行联合训练。VoxCPM2 在公开的零样本(zero-shot)和指令跟随型 TTS 基准测试中达到了最先进或具有竞争力的性能。在我们的内部 30 语言评估集中,其平均词错误率(WER)仅为 1.68%。这些结果表明,分层连续潜在建模(hierarchical continuous-latent modeling)在不依赖任何外部离散语音 tokenizer 的情况下,为大规模多语言和可控制语音生成提供了一个可行且强大的基础。为促进社区的研究与开发,该模型权重、微调代码以及推理工具均已按照 Apache 2.0 许可证公开发布。
一句话总结
VoxCPM2 是一个完全开源的多语言可控语音生成基础模型,扩展了 VoxCPM 的分层扩散 - 自回归范式,统一了 30 种语言、9 种中文方言和风格可控的语音克隆,基于在超过 200 万小时多语言语音上训练的 2B 参数骨干网络,利用非对称 AudioVAE 实现隐式超分辨率和统一序列组织,无需任何外部离散语音 tokenizer 即可运行,并在公共零样本和指令遵循 TTS 基准测试中实现最先进或具有竞争力的性能,在内部 30 语言评估集上的平均 WER 为 1.68%,模型权重、微调代码和推理工具在 Apache 2.0 许可下发布。
核心贡献
- 本文介绍了 VoxCPM2,这是一个完全开源的基础模型,在单一的分层连续潜变量骨干网络中统一了 30 种语言、9 种中文方言和多种生成模式。统一的序列组织通过不同排列相同的输入构建块来表达所有生成模式,以允许在单一参数集下进行联合训练。
- 通过非对称 AudioVAE 提升质量,该编码器以 16 kHz 编码并以 48 kHz 重建,从而以高编码效率实现隐式超分辨率。该架构支持分层连续潜变量建模,无需依赖任何外部离散语音 tokenizer。
- 模型联合扩展至 2B 参数,并在超过 200 万小时多语言语音上进行训练,以支持多种能力。性能评估显示,在公共零样本和指令遵循 TTS 基准测试中取得最先进或具有竞争力的结果,包括在内部 30 语言集上平均词错误率为 1.68%。
引言
现代文本转语音应用需要高保真度和对说话人身份的精确控制,用于配音和数字角色等用途。当前方法往往难以平衡这些需求,因为离散 token 模型会丢弃精细的声学细节,而连续潜变量替代方案在联合建模结构和纹理时面临优化挑战。本文介绍 VoxCPM2 以解决这些限制,利用具有可微半离散瓶颈的分层骨干网络。该架构支持在连续潜变量上进行端到端训练,无需外部 tokenizer,以促进语义规划和声学渲染的联合优化,同时将自然语言语音描述视为普通文本前缀以实现统一可控性。
数据集
- 数据集构成: 总训练语料库包含超过 200 万小时的多语言语音,其中中文和英文占多数。其余 28 种语言根据可用性和质量,每种语言范围从约 1K 到 50K 小时不等。
- 可控数据源: 对于可控生成,作者结合了数万小时开源表达性语音和数千小时内部策划的数据。开源部分提供了广泛的情感和说话人覆盖,而内部子集强调更高的标注精度。
- 处理和标注: 基础 TTS 数据遵循标准流程,包括源分离、语音活动检测和基于 ASR 的转录对齐。他们使用轻量级情感分类器预筛选未标注语料库,并使用音频理解模型为语音设计和风格属性生成自然语言描述。
- 训练策略: 为了将风格与内容解耦,团队将语音和风格克隆到语义无关的转录文本上,并在第 2 阶段主要混合此合成数据。参考片段来自同一录音会话,说话人嵌入余弦相似度高于 0.7,而第 3 阶段退火将混合限制为原生录制的高质量语音。
方法
VoxCPM2 采用分层扩散 - 自回归框架,其中语音完全在非对称 AudioVAE 的连续潜变量空间中进行建模。该架构包含四个主要组件,它们相互作用以逐步预测下一个潜变量块:局部编码器(LocEnc)、文本语义语言模型(TSLM)、残差声学语言模型(RALM)和局部扩散 Transformer(LocDiT)。
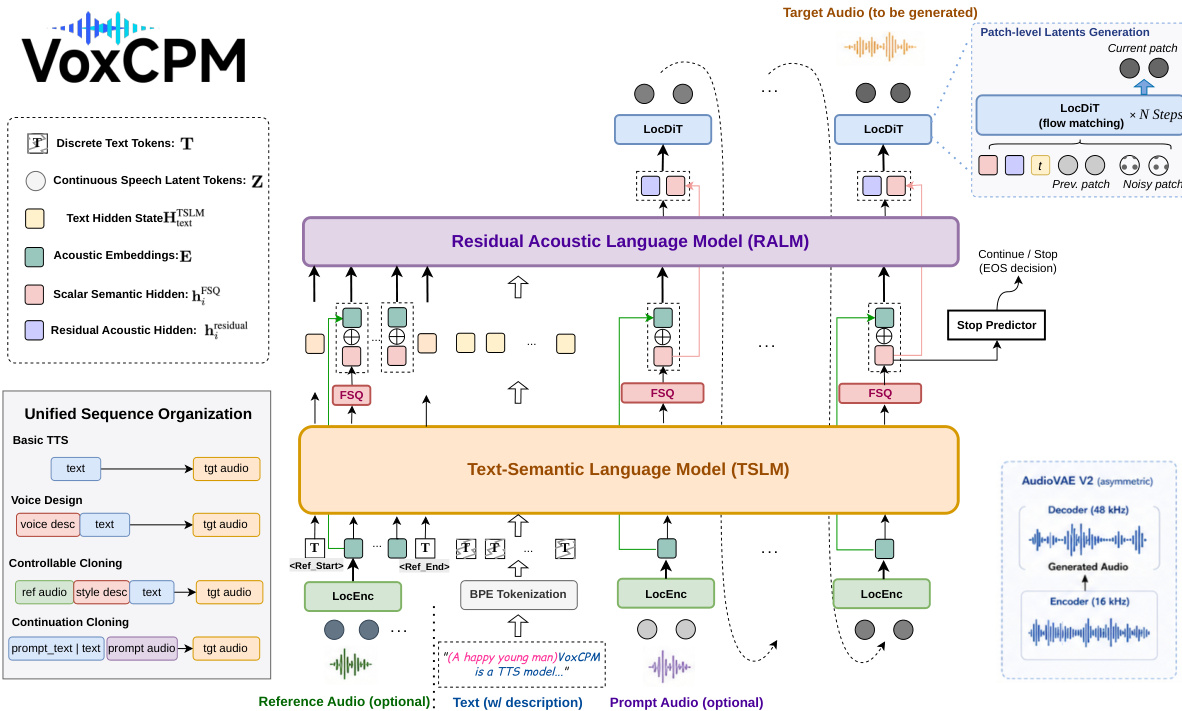
第 i 个块的生成过程被公式化为根据先前的历史和文本输入预测潜变量 zi:
zi∼LocDiT(hiFSQ, hiresidual, zi−1; t)TSLM 首先处理输入文本 tokens T 和由 LocEnc 产生的声学历史嵌入 E<i。来自 TSLM 的隐藏状态通过有限标量量化(FSQ)层以创建半离散语义骨架 hiFSQ。同时,RALM 恢复细粒度声学细节。它基于 TSLM 文本侧隐藏状态以及 FSQ 量化音频历史和 LocEnc 嵌入的融合进行条件化。在 VoxCPM2 中,此融合通过可学习的连接投影实现,而不是简单的求和:
hires_in=Wfuse[ hiFSQ∥Ei]此设计保留了来自两个流更丰富的信息。生成的残差隐藏状态 hiresidual 随后被送入 LocDiT。与之前的迭代不同,LocDiT 接收 hiFSQ 和 hiresidual 作为单独的条件 tokens,alongside 扩散时间步 t 和先前的潜变量块 zi−1。此多 token 条件前缀防止早期信息崩溃,并为扩散解码器提供更高带宽的指导。
底层表示由 AudioVAE V2 处理,这是一个非对称编解码器,将 16 kHz 波形编码为 25 Hz 的 64 维潜变量帧,并在 48 kHz 重建。骨干网络将每 P=4 帧分组为单个块,resulting in 紧凑的 6.25 Hz 自回归序列。这种非对称设计在保持低 token 率以实现高效生成的同时实现了隐式超分辨率。
为了支持基本 TTS、语音设计和可控克隆等多种能力,VoxCPM2 采用统一的序列组织。所有生成模式通过相同输入构建块的不同排列来表达:文本 tokens、参考音频片段(由 REF_START/REF_END 括起)和目标音频片段。在训练期间,只有目标音频对损失有贡献,而其他块作为条件上下文。模型使用两项目标进行端到端训练,包括目标潜变量块上的块级条件流匹配损失和 TSLM-FSQ 隐藏状态上的二元停止预测损失。采用三阶段渐进式课程,从多语言 TTS 预训练开始,接着与可控数据联合训练,最后在策划的子集上进行高质量退火。
实验
VoxCPM2 在多种公共和内部基准测试上进行了评估,以评估零样本语音克隆、多语言合成和自然语言可控性。实验表明,统一模型在多种语言上实现了具有竞争力的说话人相似度和可懂度,而主观测试确认了高自然度和指令遵循性,同时在消费级硬件上实现了高效推理。这些发现验证了分层连续潜变量范式在单一基础模型内平衡可扩展性、语音保真度和可控性的有效性。
提供的表格显示了可控生成的主观听力测试结果,评估系统的自然度和指令遵循性。VoxCPM2 在指令遵循方面获得最高分,同时保持与领先系统具有竞争力的自然度评级。这些结果表明 VoxCPM2 在遵循基于文本的语音设计指令和产生自然语音之间提供了强有力的平衡。VoxCPM2 在比较的系统中获得了最高的指令遵循分数。该模型保持了具有竞争力的自然度,排名仅次于最佳表现者。VoxCPM2 在两项指标上均优于 VoiceSculptor 和 MOSS-VoiceGenerator 等其他开源基线。

该表格比较了 Audio VAE 组件在 VCTK 和 Song Descriptor 数据集上三个模型版本的重建质量。它强调,虽然 VoxCPM1.5 通过原生在高采样率下运行实现了最佳全带 mel 距离,但 VoxCPM2 尽管利用更具挑战性的超分辨率架构,在低带和全带指标上均提供了具有竞争力的性能。VoxCPM2 尽管采用超分辨率设置,但在低带和全带指标上均展示了具有竞争力的重建质量。VoxCPM1.5 实现了最强的全带 mel 距离性能,这归因于其在更高采样率下的原生操作。VoxCPM 在 16 kHz 带语音指标(如 mel 距离和感知质量)上保持了高度具有竞争力的结果。

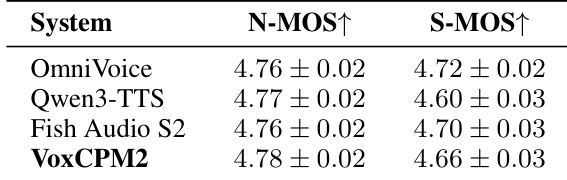
作者展示了主观听力测试结果,比较 VoxCPM2 与其他最先进系统的自然度和说话人相似度。数据表明,VoxCPM2 实现了最高的感知自然度,同时保持了与领先基线具有竞争力的说话人相似度分数。VoxCPM2 在比较的系统中获得了自然度评级的首位。OmniVoice 展示了最高的说话人相似度分数。Qwen3-TTS 在此评估中记录了最低的说话人相似度评级。
该表格显示了 CV3-Eval 基准测试上的多语言零样本语音克隆结果,将 VoxCPM2 与 CosyVoice 变体和 Fish Audio S2 进行比较。虽然 Fish Audio S2 通常在大多数标准语言子集上实现最低的错误率,但 VoxCPM2 在具有挑战性的中文困难子集上优于所有模型。此外,与缺乏几种欧洲语言数据的 CosyVoice 模型相比,VoxCPM2 报告了更多种类的语言结果。VoxCPM2 在具有挑战性的中文困难子集上实现了最佳性能。Fish Audio S2 通常在标准语言子集和英文困难子集上优于其他模型。VoxCPM2 提供了比 CosyVoice 变体更广泛的语言覆盖,包括德语、西班牙语和俄语的结果。

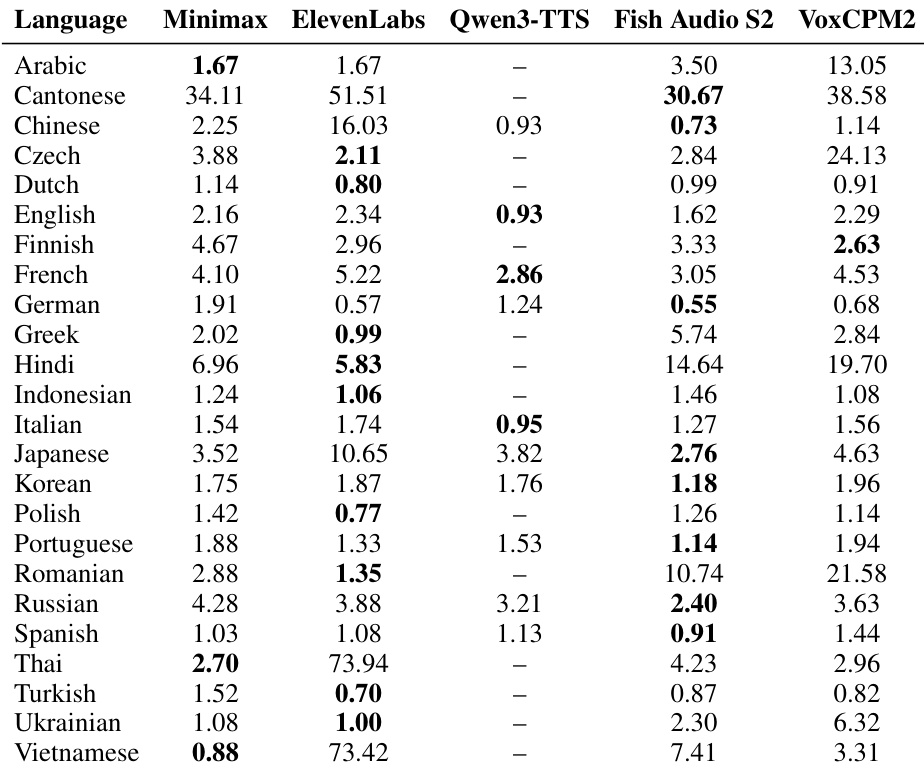
该表格比较了 24 种语言的可懂度性能,显示 Fish Audio S2 和 ElevenLabs 通常实现了最低的错误率。VoxCPM2 展示了具有竞争力的结果,特别是取得了芬兰语上的最佳分数,尽管在阿拉伯语和印地语上落后。VoxCPM2 在芬兰语上实现了最佳可懂度,优于所有其他比较系统。Fish Audio S2 和 ElevenLabs 在大多数测试语言上确保了最低的错误率。与在其他语言上的表现相比,VoxCPM2 在阿拉伯语和印地语上表现出更高的错误率。
主观听力测试显示,VoxCPM2 实现了最高的指令遵循和自然度评级,同时在与顶级表现基线相比时保持了具有竞争力的说话人相似度。音频重建评估表明,尽管利用具有挑战性的超分辨率架构,该模型在频带上保持了高质量。此外,多语言评估突出了系统在特定挑战性子集(如中文和芬兰语)上的优势,同时提供了比可比模型更广泛的语言覆盖。