Command Palette
Search for a command to run...
角色-Agent:通过双角色演化自举LLM Agents
角色-Agent:通过双角色演化自举LLM Agents
Xucong Wang Ziyu Ma Shidong Yang Tongwen Huang Pengkun Wang Yong Wang Xiangxiang Chu
摘要
尽管大型语言模型(LLM)agents在复杂任务上展现了强大的性能,但其学习过程常受限于低效的交互反馈与静态的训练环境,这阻碍了更广泛的泛化能力。为了解决这些局限性,本文引入了Role-Agent,一个利用单个LLM同时充当agent与环境,从而实现自举协同演化的框架。Role-Agent由两个协同组件构成:World-In-Agent(WIA)与Agent-In-World(AIW)。在WIA中,LLM充当agent并在每次动作后预测未来状态;预测状态与实际状态之间的一致性随后被用作过程奖励,以鼓励具备环境感知能力的推理。在AIW中,LLM分析失败轨迹中的失败模式,并检索具有相似失败模式的任务,从而重塑训练数据分布以进行针对性训练。在多个基准测试上的实验表明,Role-Agent持续提升了性能,相较于强基线平均取得了超过4%的提升。
一句话总结
Role-Agent 通过利用单一模型同时充当 Agent 与环境,引导大语言模型 Agent 实现自举训练。该方法利用 World-In-Agent 通过状态预测对齐生成感知环境的进程奖励,并利用 Agent-In-World 通过失败模式分析重塑训练数据,从而突破静态训练限制,在多个基准测试中相较于强基线模型取得平均超过 4% 的性能提升。
核心贡献
- 本文提出 Role-Agent 框架,该框架部署单一大型语言模型同时充当自主 Agent 与交互环境,实现无需人工监督的自举协同进化。
- 该方法通过 World-In-Agent 与 Agent-In-World 两个协同模块运行,前者对齐预测状态与实际状态以生成进程奖励,后者基于顺序失败分析动态重新分配训练数据。
- 在多个文本基准测试中的广泛评估表明,该架构持续超越强基线模型,带来平均超过 4% 的性能提升。
引言
LLM Agent 通过支持多轮推理与工具使用,推动编程与具身导航等动态领域的发展,而 Agentic Reinforcement Learning 进一步通过交互式策略优化增强问题解决能力。现有的自进化方法大多将适应过程局限于 Agent 端,导致环境保持静态,无法诊断特定的失败模式或生成针对性挑战,而构建完全自适应的环境通常需要复杂的辅助模型。为突破这些限制,本文提出 Role-Agent,通过利用单一 LLM 同时承载 Agent 与环境角色,实现无需人工监督的无缝协同进化。该双角色架构利用 World-In-Agent 通过未来状态预测提升决策可靠性,并利用 Agent-In-World 基于失败分析动态重新分配训练数据,从而在多个基准测试中实现更优性能。
数据集

- 数据集构成与来源:本文构建了一个混合语料库,结合模拟电子商务环境与多个开放域问答及检索基准。数据来源涵盖真实商品目录、众包指令、Google 搜索日志、维基百科、新闻档案以及 SQuAD 和 TriviaQA 等成熟问答数据集。
- 子集详情:WebShop 提供超过 118 万件真实商品及 12,087 条自然语言指令,Agent 通过搜索与点击动作进行交互。Natural Questions 将 Google 查询与维基百科答案配对,用于单跳检索。TriviaQA 利用弱监督方法提供来自维基百科和新闻的问答证据三元组。PopQA 面向长尾知识,包含超过 1.4 万个关于冷门实体的问题。HotpotQA 与 2WikiMultihopQA 评估多跳推理能力,后者使用基于规则的模板强制预设逻辑路径。MuSiQue 通过编程方式由单跳数据集组合而成,以确保严格的推理连贯性,并包含不可回答的干扰项。Bamboogle 要求顺序多文档检索,专门设计为仅靠参数化记忆无法解决。
- 使用与处理:本文利用这些数据集训练结合内部知识与外部搜索的具身语言 Agent。WebShop 环境采用基于商品属性的自动可计算奖励函数,以衡量任务完成度及仿真到现实的迁移潜力。训练数据组合强调检索增强推理,要求 Agent 分解复杂查询、过滤无关信息,并在不依赖固定混合比例或传统裁剪策略的情况下,跨非结构化来源综合事实。
- 元数据构建与分析:本文实施结构化元数据框架以进行系统性失败分析。每次 Agent 交互均标注主导失败类型、详细步骤分解、关键动作节点、核心经验教训及针对性检索查询。该结构化日志机制取代了手动裁剪方法,实现精准错误追踪,从而指导 Agent 推理流程的迭代优化。
方法
本文利用单一大型语言模型(LLM)同时充当 Agent 与环境,通过 World-In-Agent (WIA) 与 Agent-In-World (AIW) 两个协同组件实现自举协同进化过程。整体框架在闭环中运行,LLM 动态切换角色,从而实现增强的 Agent 感知与自适应环境反馈。参见框架示意图 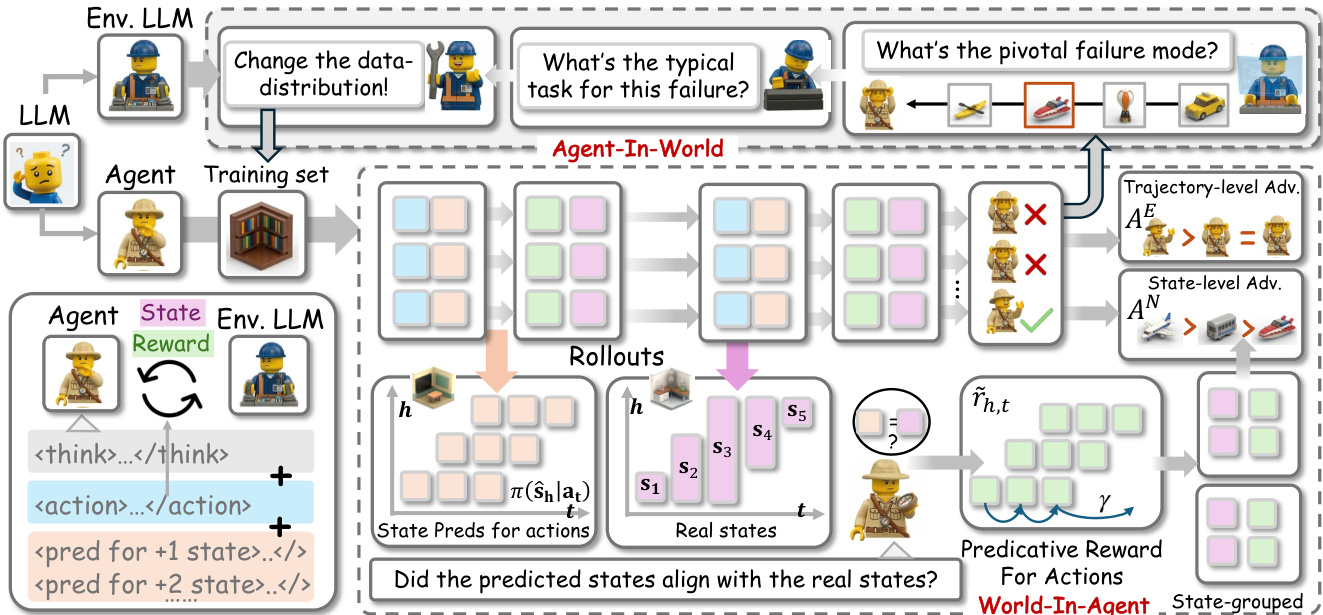 。
。
在 World-In-Agent (WIA) 模块中,LLM 承担 Agent 角色,负责预测每次动作后的未来状态。在每次交互步骤 t,生成动作 at 后,系统提示 Agent 预测未来时间步 t+h(视界为 H)的状态,得到预测集 Epre,t。这些预测通过最长匹配子序列(LMS)指标与实际真实状态 st+h 进行比较,生成预测奖励矩阵 r~。该预测奖励与任务奖励结合,形成可靠性感知的调制奖励 Rt=Rtask(at)(1+Rpre(at)),旨在放大既有效又可预测动作的信用值,同时削弱仅靠运气成功动作的信用值。随后,框架通过将相同状态下发生的状态-动作对进行分组来计算状态级优势,从而实现独立于时间顺序的更精准奖励归因。这些状态级优势与轨迹级优势整合,计算用于策略优化的最终优势值。
如图所示,Agent-In-World (AIW) 组件使环境能够根据 Agent 的表现进行自适应调整。 充当环境的 LLM 分析 Agent 的失败轨迹以识别底层失败模式。该分析包括识别主要失败类型、失败变得不可逆的关键步骤以及可泛化的核心经验。识别出的失败模式连同检索查询将存储至数据库中。当 Agent 遇到新任务时,环境 LLM 检索具有相似失败模式的历史任务,从而重塑训练数据分布,以针对 Agent 的特定弱点进行定向练习。该过程在下图中展示,包含失败轨迹、其失败模式分析及后续用于重训的相似任务检索。
充当环境的 LLM 分析 Agent 的失败轨迹以识别底层失败模式。该分析包括识别主要失败类型、失败变得不可逆的关键步骤以及可泛化的核心经验。识别出的失败模式连同检索查询将存储至数据库中。当 Agent 遇到新任务时,环境 LLM 检索具有相似失败模式的历史任务,从而重塑训练数据分布,以针对 Agent 的特定弱点进行定向练习。该过程在下图中展示,包含失败轨迹、其失败模式分析及后续用于重训的相似任务检索。
实验
评估涵盖家庭导航、模拟电子商务及搜索增强问答任务,将所提方法与闭源模型、提示工程技术及强化学习基线进行基准对比。实验结果表明该方法在所有领域均表现持续领先,且在复杂多步推理与多跳检索场景中性能提升尤为显著。消融实验与训练动态分析证实,定向环境反馈与预测奖励对捕捉系统性失败模式至关重要,从而加速收敛、降低训练与推理差异并增强泛化能力。最终,Agent-环境协同进化框架在构建强大推理能力的同时,被证明具有极高的有效性且计算开销极小。
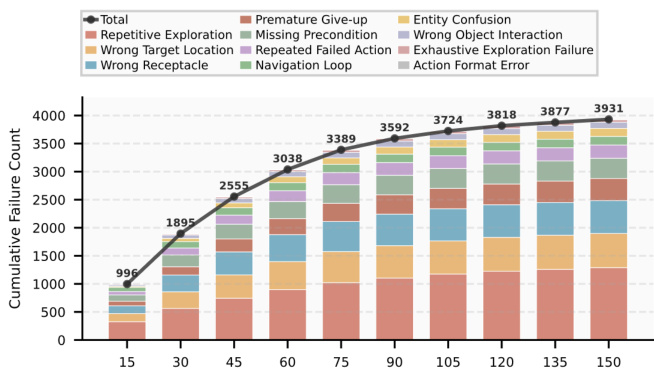
本文分析训练过程中失败模式的累积情况,显示记录到的失败总数在早期阶段迅速增加,随后趋于稳定。图表表明,重复探索与目标位置错误是最常见的失败类型,其他类别则构成多样化的错误集,表明环境提供了针对性任务以应对各类弱点。失败模式在初期快速累积,随后随训练步数增加而稳定。重复探索与目标位置错误最为普遍。失败模式的多样性表明环境提供了针对性任务以解决不同弱点。
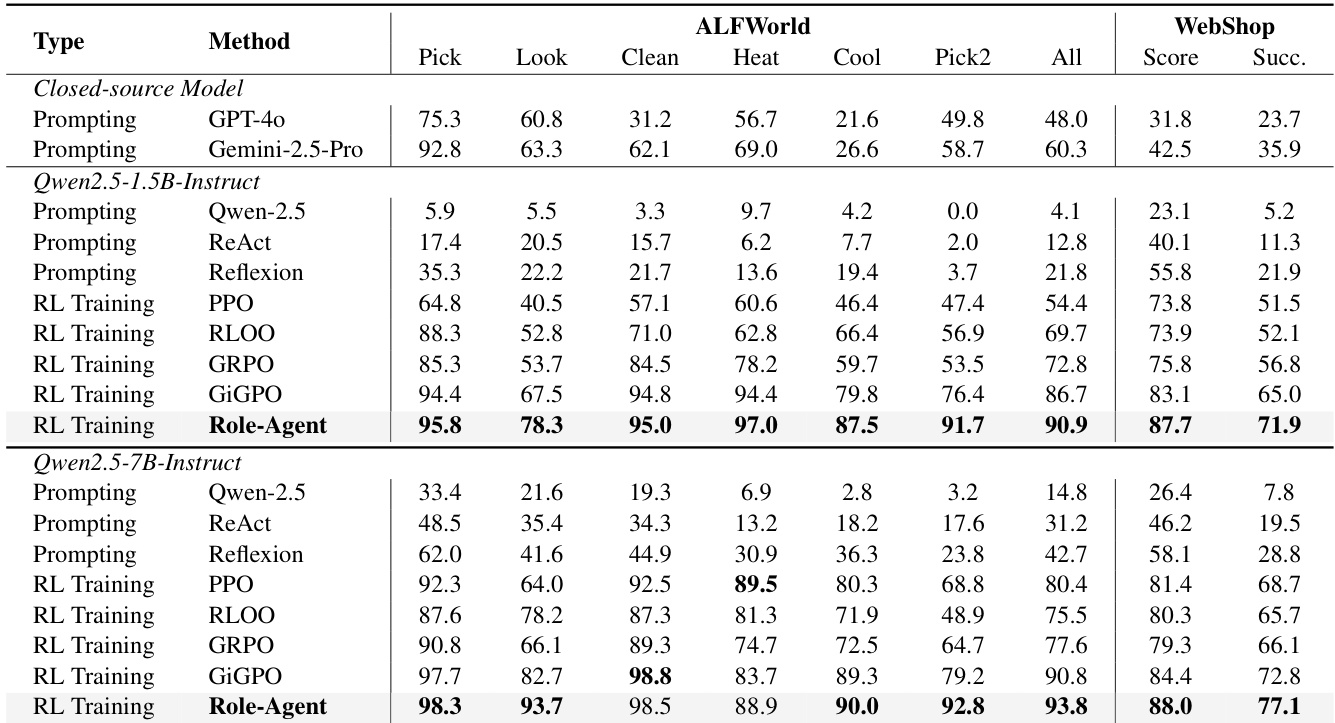
本文在 ALFWorld、WebShop 及搜索增强问答等多个基准上评估 Role-Agent 方法,并与闭源模型、提示工程方法及强化学习方法等基线进行对比。结果显示,Role-Agent 持续优于现有方法,尤其在复杂多步任务中表现突出,并在不同模型规模下展现出鲁棒性与泛化能力。该方法通过 Agent 与环境的协同进化实现性能提升,消融实验证实环境反馈与预测推理等关键组件的重要性。Role-Agent 在不同基准与模型规模上均稳定超越各类基线,尤其在复杂多步任务中优势明显。Agent 与环境的协同进化增强了泛化能力,在需要稳定记忆与多步规划的任务中取得显著收益。环境反馈与预测推理等关键组件对性能至关重要,且该方法在保持极小计算开销的同时维持了高效性。
本文在不同模型规模下,将 Role-Agent 与多项基线在 ALFWorld 和 WebShop 任务上进行对比。结果表明,Role-Agent 在两个基准与模型规模上均稳定优于其他方法,取得更高成功率并展现改进的泛化能力。在需要稳定记忆与规划复杂多步任务中,性能提升尤为显著。Role-Agent 在 ALFWorld 和 WebShop 任务上均超越所有基线方法。该方法在不同模型规模下表现持续优化,更大模型带来更高成功率。Role-Agent 在需要多步规划与稳定记忆的复杂任务中展现显著收益,表明其泛化能力得到增强。
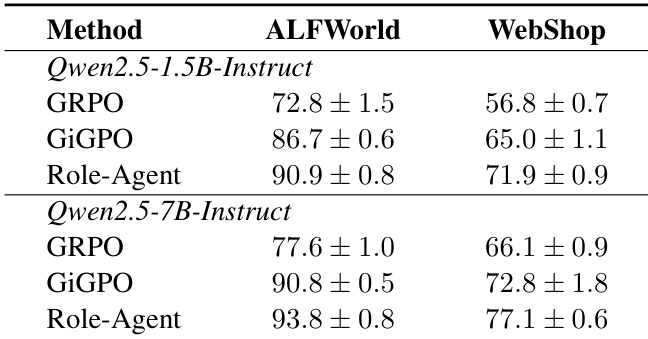
本文以 Qwen2.5 模型为骨干,在 ALFWorld 和 WebShop 任务中将 Role-Agent 与各类基线进行对比。结果表明,Role-Agent 持续优于其他方法,尤其在复杂多步任务中,其成功率高于基于提示与强化学习方法。该方法展现出强大的泛化性与稳定性,在不同模型规模与任务类型上均实现性能提升。相较于所有基线,Role-Agent 在 ALFWorld 和 WebShop 上均取得最高成功率。Role-Agent 优于提示方法与 RL 训练方法,在不同骨干模型上表现持续增益。该方法在需要多步规划与记忆的复杂任务中改善显著,表明泛化能力得到提升。
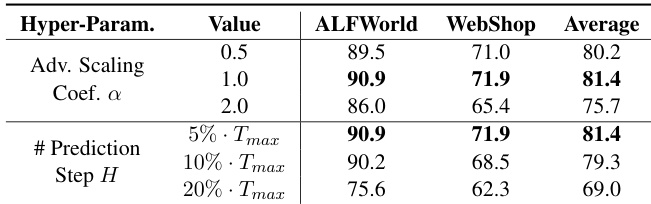
本文开展实验评估 Role-Agent 在 ALFWorld、WebShop 及搜索增强问答等多个基准上的性能,并与各类基线对比。结果表明,得益于 Agent-环境协同进化框架,Role-Agent 持续优于其他方法,尤其在多步与复杂任务中。敏感性分析显示,超参数设置(尤其是优势缩放系数与预测步长)对性能影响显著。该方法在保持极小额外计算开销的同时维持高效。Role-Agent 在不同任务与模型规模下均稳定超越各类基线。超参数调优表明,平衡的优势缩放系数与最优预测步长对最大化性能至关重要。该方法引入的计算开销极小,同时显著提升训练稳定性与收敛速度。
本文在多个基准上,使用不同模型规模将 Role-Agent 方法与多样基线进行对比,以评估整体性能与泛化能力。独立分析通过追踪失败模式累积验证训练动态,而消融与敏感性研究证实环境反馈、预测推理及最优超参数设置的关键作用。定性而言,协同进化框架持续优于现有方法,尤其在需要稳定记忆与规划的复杂多步任务中。这些实验共同表明,定向环境设计能有效应对多样化行为弱点,同时保持计算效率与稳健收敛。