Command Palette
Search for a command to run...
Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型
Flex4DHuman:面向4D人体重建的灵活多视角视频扩散模型
Jen-Hao Cheng Yipeng Wang Hao Zhang Gengshan Yang Jenq-Neng Hwang
摘要
我们提出 Flex4DHuman,这是一种多视角视频扩散模型,仅利用相对相机位姿条件,即可将单目或稀疏多视角的动态主体视频转化为同步的密集多视角视频。与以往依赖骨架、深度图、法线图或渲染的目标视角几何的人体中心方法不同,Flex4DHuman 无需显式的几何先验,而是通过相对相机位姿的位置编码来引导生成过程。生成的视频可直接输入下游重建管线,以构建动态的 4D 高斯泼溅(4D Gaussian splats)。Flex4DHuman 基于 Wan 2.1 的 13 亿参数(1.3B)文生视频模型构建,保留了其骨干架构,并通过一种五轴位置编码将相机和视角信息嵌入其中。该编码在时空旋转位置编码(RoPE)的基础上引入了视角索引以及连续的 SE(3) 相对相机几何信息。我们采用三阶段课程学习策略,逐步训练模型实现位姿跟随、灵活的参考视角到目标视角生成以及时间推移(temporal rollout)。为了支持时间推移,我们在训练中使用了干净的历史目标视角 token。此外,我们还引入了多视角文本描述(multi-view captions),以实现测试时的文本控制。结合现成的 4D 高斯泼溅模块,我们的框架能够将单目静态摄像机视频升级为动态的 4D 高斯泼溅表示。在 DNA-Rendering 和 ActorsHQ 数据集上的实验表明,Flex4DHuman 优于此前最先进的方法;此外,在混合人类与动物数据训练后,相同的模型架构可泛化至动物类别。这些能力使 Flex4DHuman 成为从日常单目视频中高效创建 4D 内容的一个实用步骤,为仿真、游戏、增强/虚拟现实(AR/VR)以及视频重拍提供了重要支持。
一句话总结
基于 Wan 2.1 的 1.3B 文生视频模型,Flex4DHuman 是一个多视图视频扩散模型,它利用相对相机姿态条件,无需显式几何先验,将单目或稀疏多视图视频转换为同步的密集多视图视频,利用五轴位置编码支持下游动态 4D 高斯泼溅的创建,同时在 DNA-Rendering 和 ActorsHQ 上超越了最先进方法。
核心贡献
- 本工作引入 Flex4DHuman,这是一个源自 Wan 2.1 适配的多视图视频扩散模型,其生成条件基于相对相机姿态位置编码,而非骨架或深度图等显式几何先验。该架构采用五轴位置编码方案,通过视图索引和连续 SE(3) 相对相机几何扩展了时空 RoPE。
- 该框架支持灵活同步生成,具备单目或可变稀疏视图输入、任意目标视点以及时序展开能力。三阶段课程训练过程确保了在不同参考视图下稳健的跨视图一致性和稳定的时序性能。
- 生成的同步多视图视频具有足够的一致性,可用于下游动态 4D 高斯泼溅重建,从而从单静态相机记录中创建动态 3D 资产。在 DNA-Rendering 和 ActorsHQ 基准测试上的评估表明,该方法超越了之前的最先进方法,并在混合训练后泛化到动物类别。
引言
生成同步多视图视频对于重建用于模拟和 AR 的动态 4D 资产至关重要。现有方法通常依赖骨架或深度图等显式几何先验来条件化扩散模型。这些要求会传播估计误差,并限制模型泛化到特定人类模型或固定相机配置。该研究引入 Flex4DHuman,这是一种灵活的多视图视频扩散框架,消除了训练或推理期间对显式几何的需求。相反,该模型基于相对相机姿态编码进行条件生成,从单目或稀疏输入合成一致的新视图。这种方法实现了从单相机记录到动态 4D 高斯泼溅的直接流程,同时泛化到非人类主体。
数据集
-
数据集组成与来源
- 该研究利用三个多视图视频数据集:DNA-Rendering、ActorsHQ 和动态毛茸茸动物 (DFA) 数据集。
- DNA-Rendering 贡献了来自 548 个身份、由 48 相机阵列捕获的 1,038 个人类表演序列。
- ActorsHQ 提供 14 个序列,包含 8 名演员,由 160 台相机录制。
- DFA 数据集包含 23 个序列,涵盖 9 种动物物种,渲染自 36 到 72 个相机视点。
-
描述生成与元数据
- 使用 Gemini 3 Flash 为每个序列生成密集的自然语言描述。
- 该工作流生成了 25,031 个描述,平均长度为 268 个单词。
- 人类描述优先关注外观属性以确保可靠性,而动物描述保留高级行为描述,如步态和尾巴运动。
-
图像处理与裁剪
- 序列分别被划分为 DNA-Rendering、ActorsHQ 和 DFA 的 10、20 或 60 帧不重叠时间窗口。
- 在每个窗口内均匀采样帧,构建由四个大致正交视点组成的 2x2 图像网格,以前景主体为中心。
- 在将网格帧序列提交给描述生成之前,背景会被掩蔽。
-
训练用途
- 每个采样片段与包含其起始帧的时间窗口对应的描述配对。
- 同一序列的不同片段随时间暴露于不同的文本描述,以增加描述多样性并减少过拟合。
方法
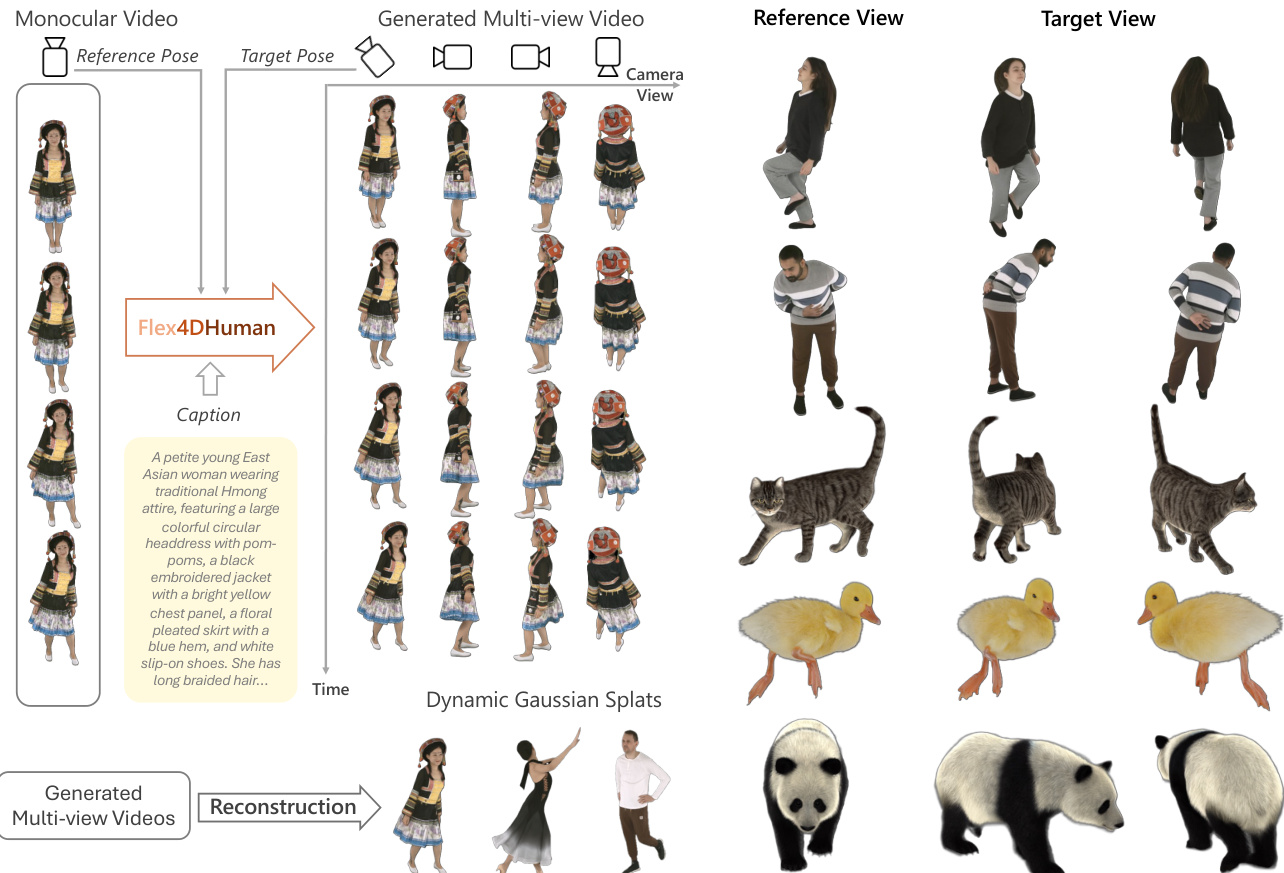
所提出的框架 Flex4DHuman 将单目视频或稀疏参考视图转换为同步多视图视频生成,随后可重建为动态 3D 资产。整体工作流程始于单目输入或参考姿态,Flex4DHuman 模型与文本描述一起处理这些输入以生成多视图序列。生成的视频随后被分割并重建为 4D 高斯泼溅,用于下游应用。
核心架构基于 Wan 2.1 文生视频扩散 Transformer (DiT) 骨干网络。主要修改在于输入表示和位置编码方案,以适应多视图几何。参考视图和目标视图共享统一的 36 通道输入布局。这包括 16 个通道的噪声潜变量,16 个通道的条件潜变量(干净潜变量),以及 4 通道的二值掩码。对于参考视图,条件通道填充有编码潜变量和全一掩码,而目标视图在条件通道中使用零。这种设计使模型能够区分观察和未观察区域,在训练期间实现双向信息传播,并在推理期间实现干净历史条件化。
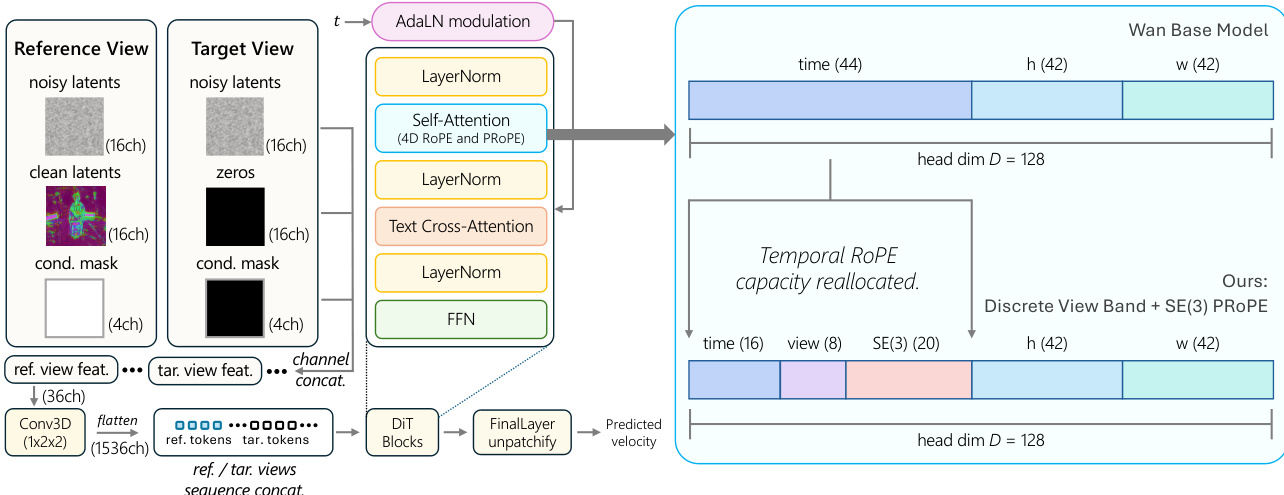
为了在不使用可学习嵌入的情况下编码相机几何结构,该研究用投影位置编码替换了原始的时空旋转位置编码 (RoPE),该编码结合了空间坐标、离散帧索引、离散视图槽索引和连续 SE(3) 相机几何结构。原始时序 RoPE 容量被重新分配以支持这些新维度。具体来说,头维度 D=128 从 (Dt,Dh,Dw)=(44,42,42) 重新划分为 (Dtime,Dview,DSE(3),Dh,Dw)=(16,8,20,42,42)。SE(3) 分量直接在注意力机制内编码相对相机变换。对于每个 token i,分配给 SE(3) 频带的查询和键子向量根据相机姿态 Ti 进行变换:
QiSE(3)←Ti⊤QiSE(3),KiSE(3)←Ti−1KiSE(3),其中 Ti∈SE(3) 表示相机姿态。这种公式确保注意力取决于 token 之间的相对相机变换,使模型对相机的数量和空间排列具有不变性。
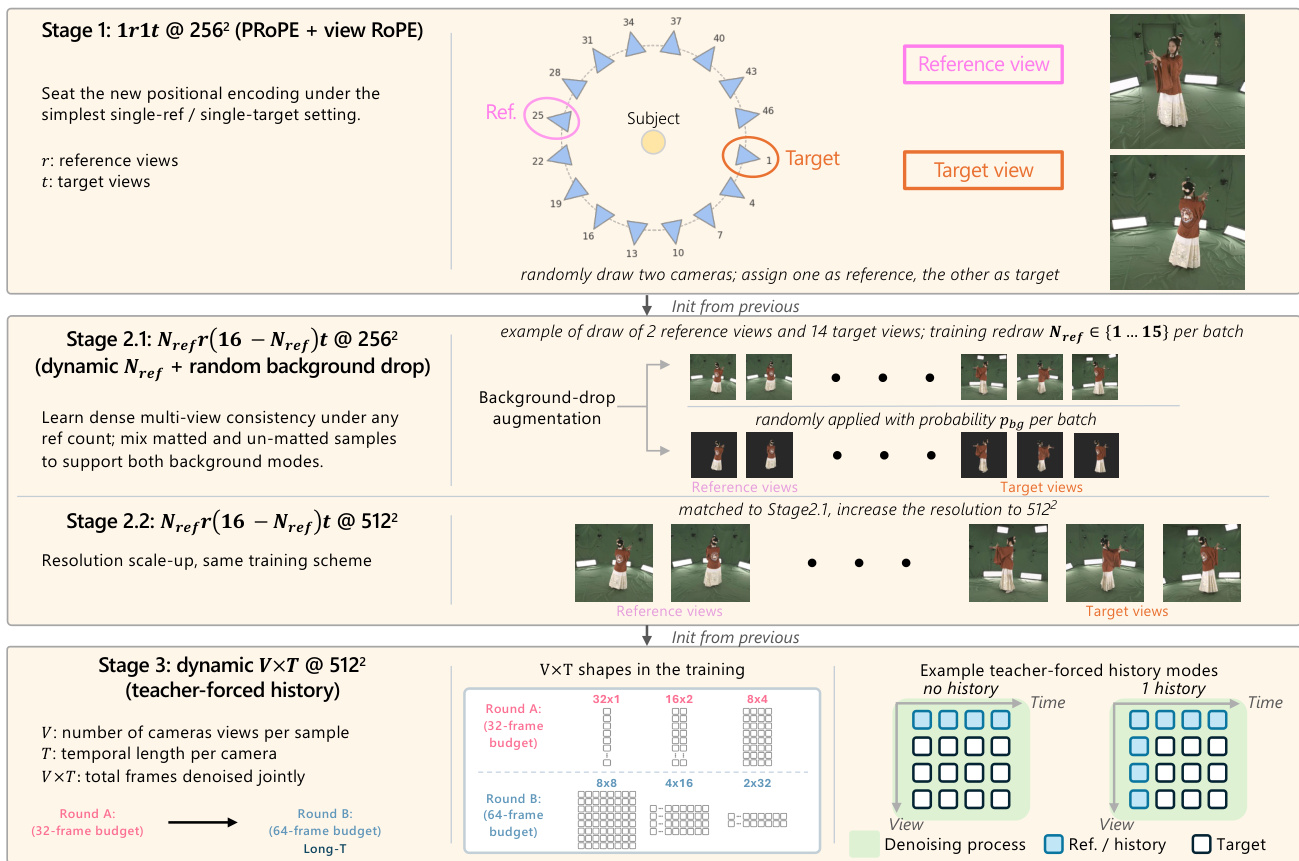
该模型使用三阶段课程进行训练,旨在逐步增加复杂性。第一阶段使用单参考单目标设置将预训练骨干网络适配到新的位置编码。第二阶段引入动态参考视图采样,具有可变数量的参考视图,并应用随机背景丢弃增强,以支持仅前景和全背景生成。该阶段在 2562 分辨率下训练,然后扩展到 5122。最终阶段将训练扩展到动态时间窗口,采用教师强制历史条件化,使模型能够在共享的 token 预算下泛化到不同的视图 - 时间配置。
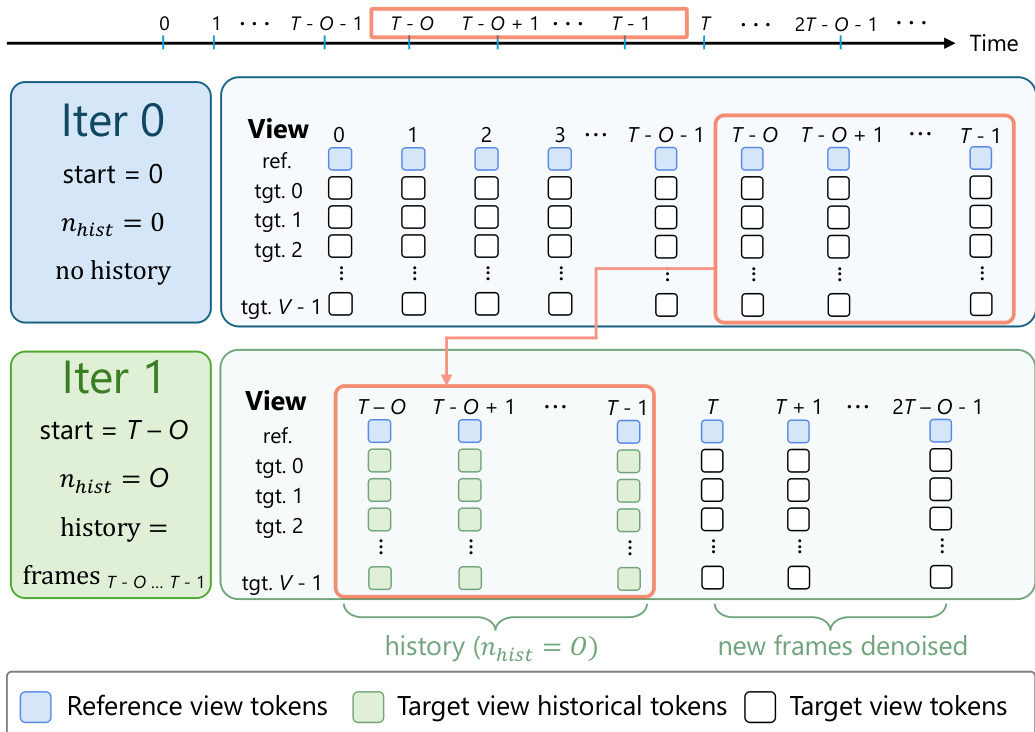
对于推理,系统采用分块展开策略来生成长于训练视野的视频。如下所示,生成过程分为迭代。在第一次迭代中,只有参考视图 token 充当干净条件。在随后的迭代中,模型推进 T−O 帧,并将前一个块中的 O 个重叠预测重用为所有目标视图的干净历史 tokens。这种机制通过在块之间保持时序一致性,实现了长视野同步多视图生成。
最后,生成的多视图视频可以通过重建流程转换为 4D 资产。这涉及使用 MatAnyone2 进行前景分割以隔离演员,随后使用 FreeTimeGS 拟合动态高斯泼溅。此过程将 2D 生成视频提升为适合交互式渲染和组合到虚拟场景的 3D 表示。
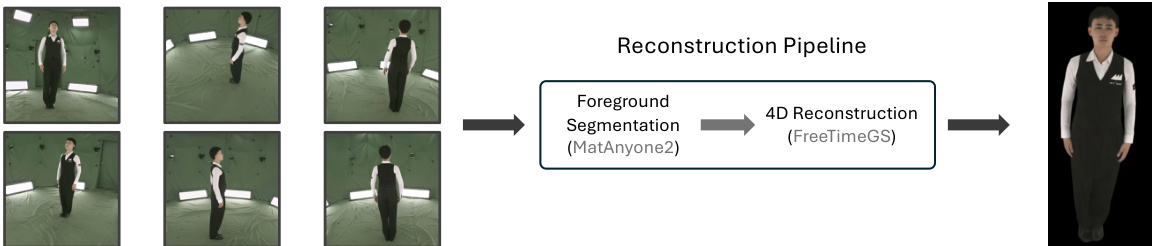
实验
Flex4DHuman 在涉及直接新视图合成和 4D 高斯泼溅重建的三个基准测试上进行了评估,这些测试在保留的相机阵列上进行。在 DNA-Rendering 上的实验表明,该方法优于强基线,同时无论参考视图的选择或数量如何都保持质量一致。此外,在 ActorsHQ 和动物数据集上的零样本泛化测试验证了该模型有效地转移到未见过的主体和相机配置,而无需依赖显式人类几何先验。
该研究在动态毛茸茸动物数据集上评估模型,以测试其泛化到人类主体之外的能力。他们比较了内部动物设置(训练期间看到物种)和跨动物设置(未见过的物种)。结果表明,虽然模型在已知物种上表现最佳,但它对新动物类型保留了强大的生成能力。内部动物设置在所有报告的指标上实现了更好的重建质量。当泛化到训练集中未包含的动物物种时,性能保持稳健。该方法成功转移到非人类主体,而无需依赖特定人类几何结构。

该表格概述了实验中所使用的三个基准测试的统计信息:DNA-Rendering、ActorsHQ 和 DFA。DNA-Rendering 是最大的数据集,优势显著,提供了大部分主体和序列。其余数据集贡献了具有不同技术配置的人类和动物数据。与其他基准测试相比,DNA-Rendering 包含绝大多数主体和序列。数据集包括人类和动物主体,以评估对人类数据之外的泛化。基准测试在分辨率、帧率和时间窗口持续时间等技术属性上有所不同。

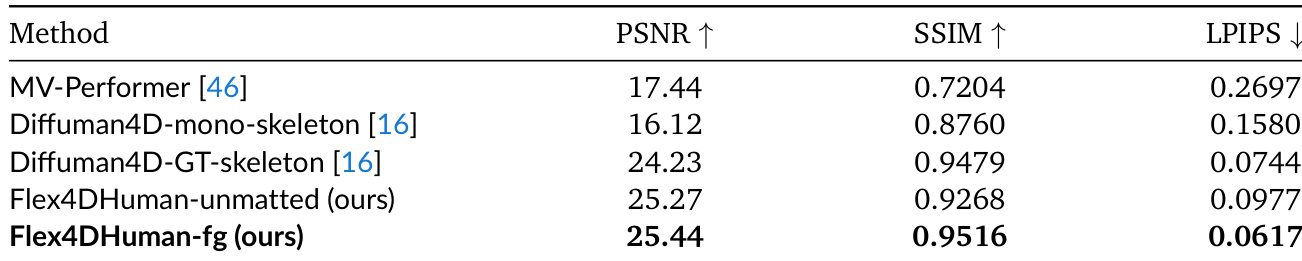
该研究在 DNA-Rendering 基准测试上评估了提出的 Flex4DHuman-fg 方法与 Diffuman4D-mono-skeleton 基线。结果表明,所提出的方法在所有报告的指标上实现了卓越的性能,包括 PSNR、SSIM 和 LPIPS。Flex4DHuman-fg 实现了比 Diffuman4D-mono-skeleton 基线更高的 PSNR 和 SSIM 分数。所提出的方法产生了更低的 LPIPS 分数,表明具有更优越的感知相似性。结果证实了仅前景方法在新视图合成中的有效性。

该研究在 DNA-Rendering 数据集上使用 PSNR、SSIM 和 LPIPS 指标评估 Flex4DHuman 与多视图人类扩散基线。结果表明,其方法的仅前景版本与单参考基线和真实骨架基线相比,实现了更优越的重建质量。Flex4DHuman-fg 在所列方法的所有评估指标上实现了最高分数。所提出的方法显著优于 MV-Performer 和 Diffuman4D-mono-skeleton 等单参考基线。Flex4DHuman-fg 超越了强大的 Diffuman4D-GT-skeleton 基线,尽管在推理时依赖较少的几何信息。
该研究在 DNA-Rendering、ActorsHQ 和动态毛茸茸动物数据集上评估模型,以评估对人类主体之外的泛化。在人类数据上的实验表明,所提出的仅前景方法与多视图扩散基线和真实骨架基线相比,实现了更优越的重建质量。此外,动态毛茸茸动物数据集上的结果证实,该方法成功转移到非人类主体,而无需依赖特定人类几何结构,同时为未见过的物种保持稳健的生成能力。