Command Palette
Search for a command to run...
ACL-Verbatim:面向研究的可信问答
ACL-Verbatim:面向研究的可信问答
Gábor Recski Szilveszter Tóth Nadia Verdha István Boros Ádám Kovács
摘要
学术研究者需要高效且可靠的方法来从可信来源收集高质量信息,但当前用于辅助 AI 研究的主流工具仍受限于大型语言模型(LLMs)倾向于产生事实性错误或无意义输出的问题,这种现象通常被称为“幻觉”(hallucinations)。我们将提取式问答系统 VerbatimRAG(Kovacs et al., 2025)应用于 ACL Anthology 中的研究论文,直接将用户查询映射到检索文档中的逐字文本片段。我们为“将用户查询映射至研究论文中相关文本片段”这一任务贡献了一个新颖的地面真实(ground truth)数据集,并利用该数据集训练和评估了多种提取式模型。人工标注工作由 NLP 研究人员完成,基于使用自定义管道生成的合成用户查询,该管道基于 ScIRGen 方法(Lin et al., 2025),并与由 VerbatimRAG 检索到的研究论文片段(chunks)配对。在该基准测试中,在银标签监督(silver supervision)数据上训练的 150M 参数 ModernBERT token 分类器取得了最佳的词级 F1 分数(53.6),优于表现最强的已评估 LLM 提取器(48.7)。
一句话总结
ACL-Verbatim 通过将对 ACL Anthology 论文的提取式 VerbatimRAG 系统应用于问答任务,实现了无幻觉问答,并贡献了一个新颖的真实数据集用于将查询映射到文本片段,其中在银监督上训练的 150M 参数 ModernBERT token 分类器实现了 53.6 的单词级 F1 分数,优于最强的评估 LLM 提取器(48.7)。
核心贡献
- 贡献了一个新颖的真实数据集,用于将用户查询映射到 ACL Anthology 研究论文中的相关文本片段。该数据集用于训练和评估各种提取式模型。
- 人类标注由 NLP 研究人员执行,使用基于 ScIRGen 方法的自定义管道生成的合成用户查询。这些查询与 VerbatimRAG 检索到的研究论文块配对。
- 在管道银监督上训练的 150M 参数 ModernBERT token 分类器在基准测试中实现了 53.6 的最佳单词级 F1 分数。此性能超过了最强的评估 LLM 提取器,后者得分为 48.7。
引言
研究人员依赖科学文献获取可信信息,但大型语言模型在透明度和可靠性方面带来了重大风险。即使是检索增强生成系统也难以应对幻觉问题,模型会用先验知识覆盖检索到的证据,使得验证过程繁琐且常被省略。ACL-Verbatim 通过一种提取式问答系统解决了这些挑战,该系统仅返回源文档中的原文文本片段以消除幻觉。此外,还为此任务贡献了一个基准数据集,并证明在生成数据上微调紧凑提取模型的性能优于参数更少的大型 LLM 提取器。
数据集
-
数据集组成与来源
- 作者基于截至 2026 年 2 月的 ACL Anthology 状态构建语料库。
- 从 120,034 个条目开始,但丢弃了 5,000 篇由第三方托管的论文以确保许可宽松。
- 剩余的 114,567 篇论文使用 docling 库转换为 markdown,生成 114,475 个可用文件。
- 元数据和全文在 CC-BY 4.0 许可下分发。
-
每个子集的关键细节
- 索引语料库: 包含 114,475 个 markdown 文档,分段为 500 到 5,000 字符的块。
- 查询生成样本: 包括 333 篇随机选择的至少有一位作者的英文论文。
- 黄金标注集: 包含由 NLP 研究人员标注的 20 个查询和 100 个块的人类标签。
- 银数据: 生成的查询和检索到的块构成了提取式模型的训练数据。
-
模型训练与评估
- 使用银监督管道训练 150M 参数 ModernBERT token 分类器。
- 在人工标注的基准上评估模型以测量单词级 F1 分数。
- 系统通过将查询映射到原文文本片段执行提取式问答。
-
处理与标注策略
- 分块策略: 管道解析章节结构并为块添加标题前缀,同时防止在表格或代码块内分割。
- 查询合成: 合成查询遵循 ScIRGen 方法,将长问题转换为更短、碎片化的用户查询。
- 索引: 使用 granite-embedding-english-r2 模型对块进行全文和稠密向量搜索索引。
- 标注工作流: 标注者为相关块分配二元相关性标签并高亮显示特定文本片段或图片标题。
方法
作者利用管道生成银监督以训练自包含的学生模型。此过程涉及从 ACL Anthology 语料库创建合成查询并检索相关块。如下图所示,查询生成工作流始于论文块输入,该输入经过问题类型选择(例如,比较、因果后果、目标导向)。此步骤指导后续的问题生成阶段,根据选定的类型制定具体问题。最后,这些问题被重写为优化查询(例如,“矩阵分解 vs Dirichlet 层次主题建模”)以促进检索。
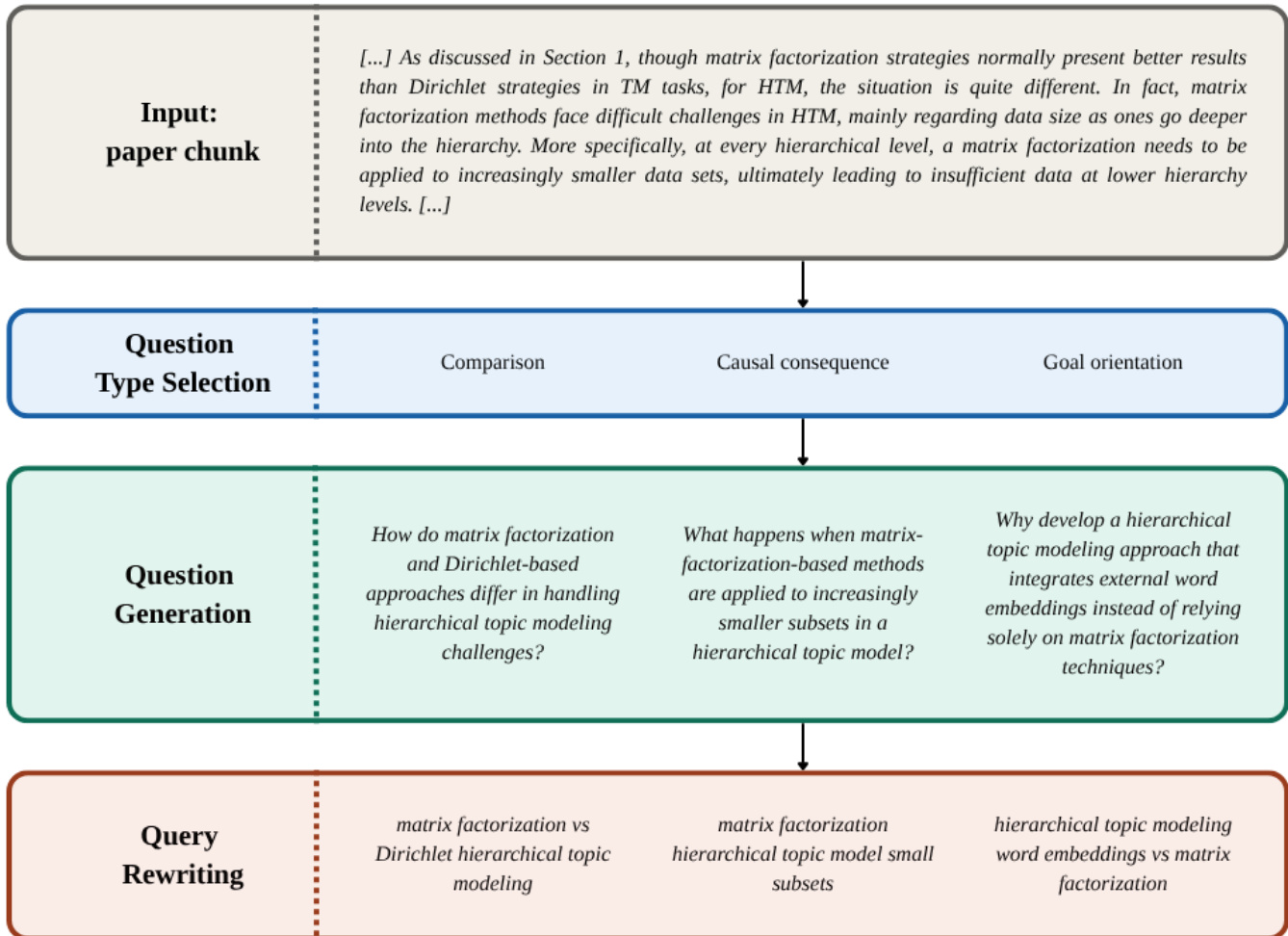
一旦建立合成查询和块,大型语言模型(Qwen 3.6 35B)充当银教师,使用特定提示(例如,verbatim 或段落式提取)提取证据片段或段落。生成的数据集由具有指示证据存在的二元 token 标签的查询 - 块对组成。
学生架构设计为基于 8192-token ModernBERT 骨干网络的查询条件 token 分类器。输入由问题和文档块的连接组成,而输出预测每个 token 的二元证据标签,随后解码为字符片段。作者比较了两种骨干配置:vanilla ModernBERT-base 掩码语言建模检查点和在查询 - 段落相关性上后训练的交叉编码器重排序模型。训练进行 5 个 epoch,批量大小为 8,学习率为 2×10−5,根据 silver-dev token F1 选择最佳检查点。在推理期间,应用两个后处理步骤以细化输出:丢弃短于 10 个字符的片段,并将最多相隔 20 个字符的相邻片段合并以防止 token 级碎片化。
实验
评估利用人工标注的基准来比较基于 LLM 的提取器、现有的剪枝基线和在合成数据上训练的紧凑学生模型。结果表明,专门的学生模型通过有效地在不相关块上弃权实现了更高的精度,而 LLM 尽管召回率更高,却倾向于提取误报。总体而言,实验表明,使用面向任务的数据训练的较小定制架构在证据提取方面优于零样本大型语言模型,同时仅占用一小部分计算成本。
作者在 100 个查询 - 块对的基准上评估提取式模型,比较基于 LLM 的提取器、剪枝基线和他们自己的紧凑学生模型。结果表明,作者的专业学生模型实现了最高的单词级精度和 F1 分数,优于更大的 LLM 提取器和标准基线,同时以显著更低的延迟运行。虽然 LLM 提取器通常实现更高的召回率,但它们往往通过从不相关块中提取证据而具有较低的精度,而学生模型表现出更强的在不相关内容上弃权的能力。专业学生模型在单词级精度和 F1 分数上优于 LLM 提取器和基线。LLM 提取器通常实现更高的召回率,但精度较低,经常从不相关块中提取片段。学生模型与更大的 LLM 提取器相比,运行延迟显著更低。
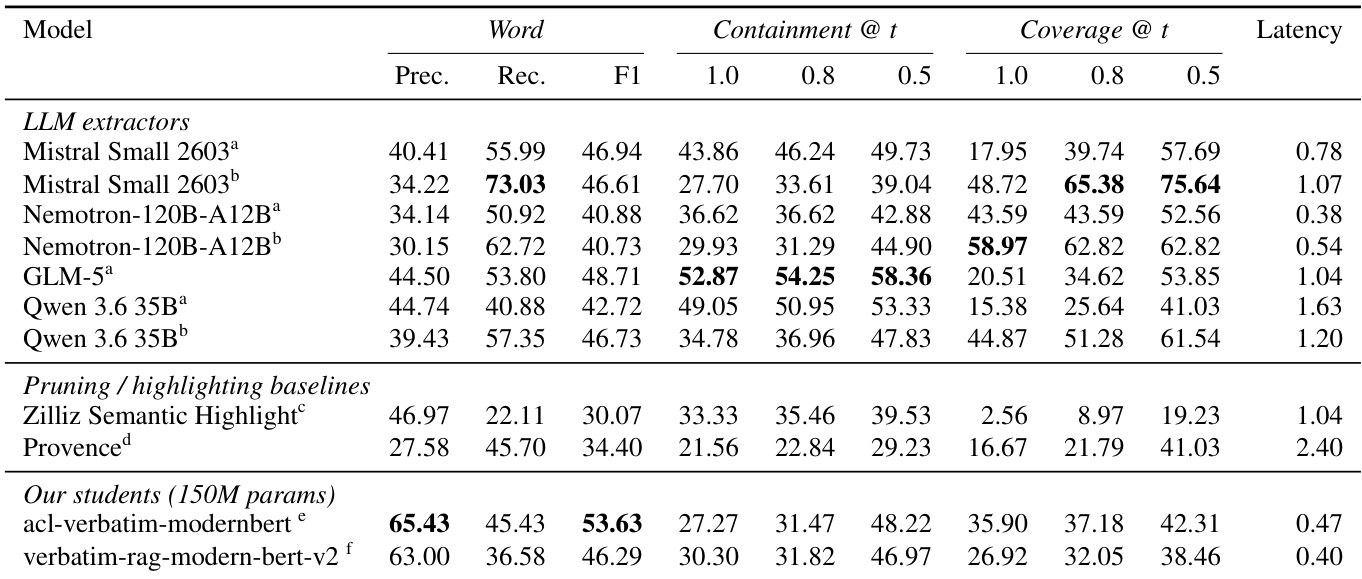
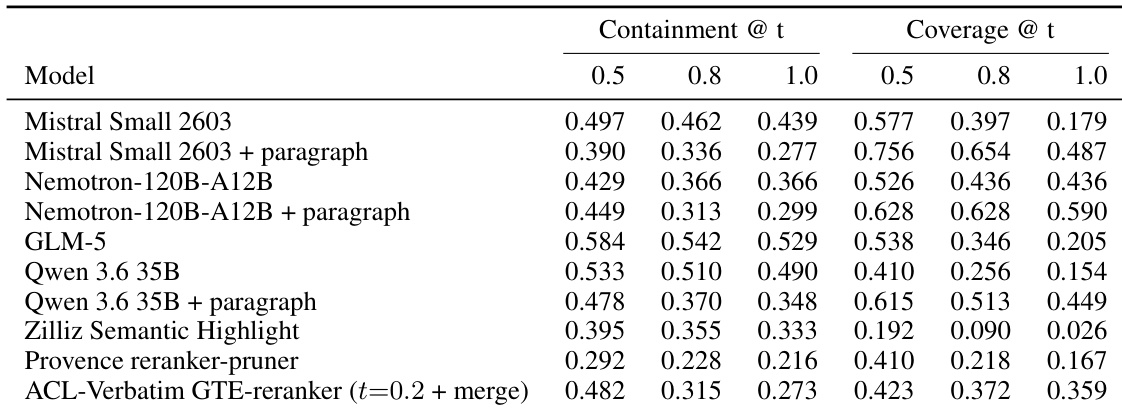
该表比较了各种提取模型(包括具有不同提示策略的 LLM 和专门基线)的包含率和覆盖率分数。结果表明,虽然标准 LLM 配置通常优先考虑包含率,但利用面向段落的提示可显著提高覆盖率,但会降低包含率。基于 LLM 的提取器在包含率和覆盖率指标上通常比 Zilliz 和 Provence 基线获得更高的分数。与默认配置相比,对 LLM 应用面向段落的提示一致地增加覆盖率同时降低包含率。ACL-Verbatim GTE-reranker 实现了中等性能水平,平衡了段落提示模型的高覆盖率和标准 LLM 的高包含率。
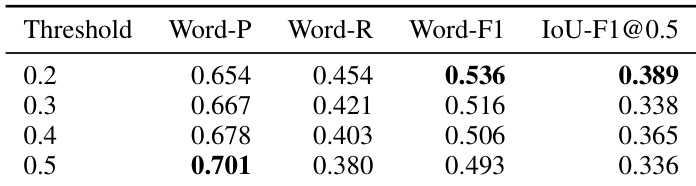
作者评估学生模型在各种概率阈值下的表现以确定最佳推理设置。结果表明,最低阈值设置产生最高的 Word-F1 分数。增加阈值值导致更高的精度但更低的召回率,这对整体 F1 指标产生负面影响。最低阈值设置产生最高的 Word-F1 分数。随着概率阈值增加,精度提高。随着概率阈值增加,召回率下降。
作者在查询 - 块对的基准上评估提取式模型,以比较基于 LLM 的提取器、基线和紧凑学生模型。结果表明,专业学生模型在避免不相关内容方面实现了更高的精度和效率,而标准 LLM 提取器以精度为代价优先考虑召回率。关于包含率和覆盖率的额外实验表明,提示策略显著影响检索平衡,阈值调整证实较低的概率设置优化了模型的整体性能。