Command Palette
Search for a command to run...
超越静态对话:基准测试真实、异构且不断演变的长期记忆
超越静态对话:基准测试真实、异构且不断演变的长期记忆
摘要
在现有的大语言模型(LLM)记忆基准测试中,所评估的对话会话往往缺乏长期语义一致性,且底层人物画像倾向于扁平化和静态化。此外,在真实世界场景中,用户与助手之间的交互涉及更多样化、异构的数据流,例如文档和电子邮件。这些缺陷严重限制了当前评估的真实性和有效性。为了解决这些局限性,我们引入了 RHELM(Realistic, Heterogeneous, and Evolving Long-term Memory,即真实、异构且演化的长期记忆)。通过精心设计的用户画像以及新颖的 LOOP(pLan-rQlloutevQlve-Prune,即计划-查询-演化-修剪)模块,我们构建了跨多种交互场景的真实对话,这些对话表现出动态的时间演化和长期连贯性。关键在于,这些对话与外部异构源深度整合,并与用户的时间事件轨迹保持同步。由此生成的基准测试包含涵盖七种查询类型的挑战性问答对,每个问题映射到至少一项我们确定为关键但当前研究尚待深入探索的 27 项核心记忆特征。
一句话总结
作者提出了 RHELM,这是一个用于评估大语言模型长期记忆的基准,它利用新颖的 LOOP(pLan-rQlloutevQlve-Prune)模块和精心制作的用户画像来构建现实、异构且演变的对话,这些对话集成了与用户时间事件轨迹同步的异构外部来源,涵盖七种查询类型和 27 个关键记忆特征,以解决现有评估中的语义不一致和静态角色问题。
核心贡献
- RHELM 被引入作为一个基准,旨在评估大语言模型中现实、异构且演变的长期记忆。该基准构建了跨多样化交互场景的对话,这些对话表现出动态的时间演变和长期连贯性。
- 逼真的对话构建由基于精心制作的用户画像的新颖 LOOP(pLan-rQlloutevQlve-Prune)模块驱动。这些对话与与用户时间事件轨迹同步的异构外部来源深度集成。
- 生成的基准包含具有挑战性的问答对,涵盖映射到 27 个关键记忆特征的七种查询类型。每个问题至少映射到这些已识别的特征之一,这些特征对于当前研究至关重要但尚未得到充分探索。
引言
大语言模型的最近进展扩展了上下文窗口和记忆机制,以更好地管理复杂任务和历史信息。虽然现有基准已转向对话框架,但它们通常未能集成异构数据源或模拟现实动态用户轨迹。作者通过引入一个旨在评估对话系统中现实、异构且演变的长期记忆能力的基准来解决这些限制。
数据集
-
数据集构成与来源
- 作者介绍了 RHELM,这是一个旨在评估个人 AI 助手中长期记忆的基准。
- 该数据集基于 10 个在一年期内模拟的不同角色轨迹构建。
- 来源包括对话对话以及异构外部文档,如电子邮件、日记和专业报告。
- 初始角色种子来自 PersonaHub 数据集,涵盖金融、医疗和法律等职业。
-
每个子集的关键细节
- 对话子集包含 11,764 个回合,每个角色的上下文长度从 500k 到 1M tokens 不等。
- 外部源子集由 2,180 个文件组成,格式包括 HTML、Markdown 和文本。
- 评估套件包含 1,305 个问答对,分为七种查询类型。
- 每个问题至少映射到 27 个已识别的记忆特征之一,以确保复杂性。
-
数据使用与处理
- 该论文仅将数据用作评估基准,而非用于模型训练。
- 实验比较了全上下文模型、检索增强生成方法和记忆框架。
- 新颖的 LOOP 模块处理规划、展开、演变和剪枝,以确保动态时间连贯性。
- 角色通过存储在严格 JSON schema 中的六维分类法进行维护。
- 问题生成提示强制进行多跳推理和逻辑推导,而非直接提取。
-
元数据与构建策略
- 角色属性涵盖身份、个性、特征、关系、物品和当前状态。
- 外部来源通过 Deep Research 方法合成,以匹配用户事件轨迹。
- 包含误导性查询以测试隐式状态约束和冲突检测。
- 数据集排除了视频或音频等非文本模态,以专注于文本记忆推理。
方法
作者提出了一个综合框架,用于生成现实的全生命周期用户轨迹,以评估 AI 助手中的长期记忆。该方法的核心是 LOOP(pLan-rOllout-evOlvE-Prune)模块,它模拟现实事件的随机性质及其对用户角色随时间的影响。整体架构遵循一个四阶段管道,旨在产生异构数据流,包括对话对话和外部文档。
参考框架图以可视化完整的工作流程,该流程集成了角色初始化、轨迹模拟、数据提取和对话合成。
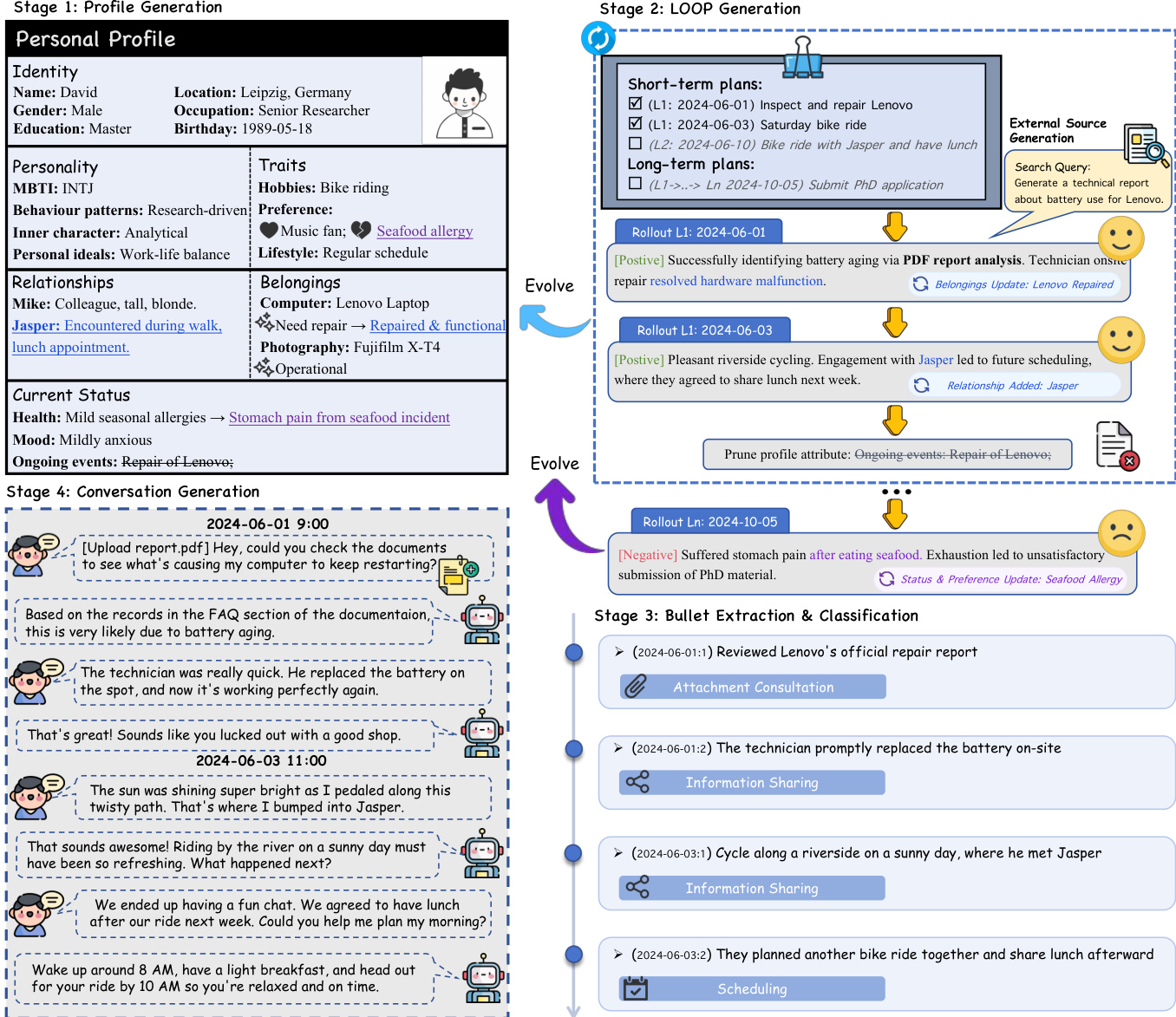
该过程从角色生成开始,在此建立丰富的初始角色。此角色作为 LOOP 模块的基础。在 LOOP 模块内,系统通过循环过程生成事件时间线。首先,Plan组件根据当前角色状态生成短期安排(例如社交互动、常规)和长期预测(例如职业里程碑)。随后,Rollout机制模拟这些计划事件的结果。为了捕捉现实生活的不可预测性,概率 p 控制结果的效价,产生正面或负面的叙述。这些结果作为后续数据生成的基础事实。
为了确保角色与演变中的叙述保持一致,Evolve组件动态更新用户角色。此更新过程通过功能方法实现,强制执行严格的 schema 约束。正如角色更新系统提示中详述的那样,模型分析事件结果以识别身份、关系和物品方面的必要变化。它生成一个 Python 函数来修改现有的角色字典,在添加新项、更新现有属性或移除过时实体的同时确保结构完整性。

此外,采用Prune模块来减轻扩展时间范围内的累积语义漂移。该模块定期通过移除过时实体来重新校准用户角色,确保长期一致性。与角色演变并行,系统合成外部来源。基于每日结果叙述,模型创建多样化的产物,如电子邮件、个人日记和专业报告。这些文档使用 Deep Research 方法生成,以确保它们反映现实的格式和复杂性。
在轨迹模拟之后,要点提取与分类阶段将结果叙述分解为原子要点。这些要点被分类为特定的对话类别,如信息共享、寻求建议、状态更新、调度和附件咨询。此分类反映了现实世界的沟通意图,并指导后续的对话生成。
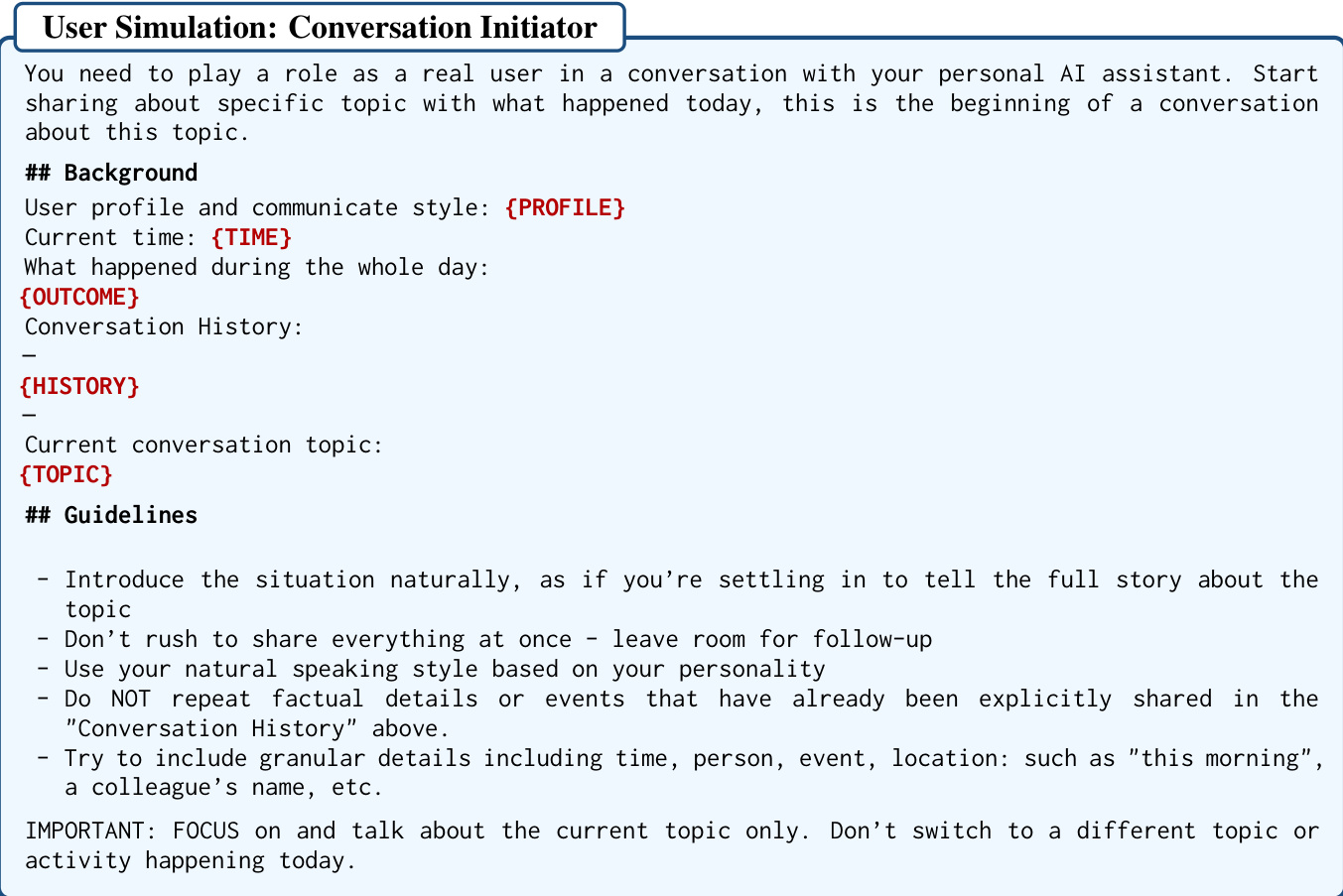
对话生成阶段利用两阶段管道来模拟真实的用户 - 助手交互。在第一阶段,用户模拟器充当对话发起者,根据提取的要点引入新主题。此过程由特定提示引导,鼓励自然叙事和包含细节。
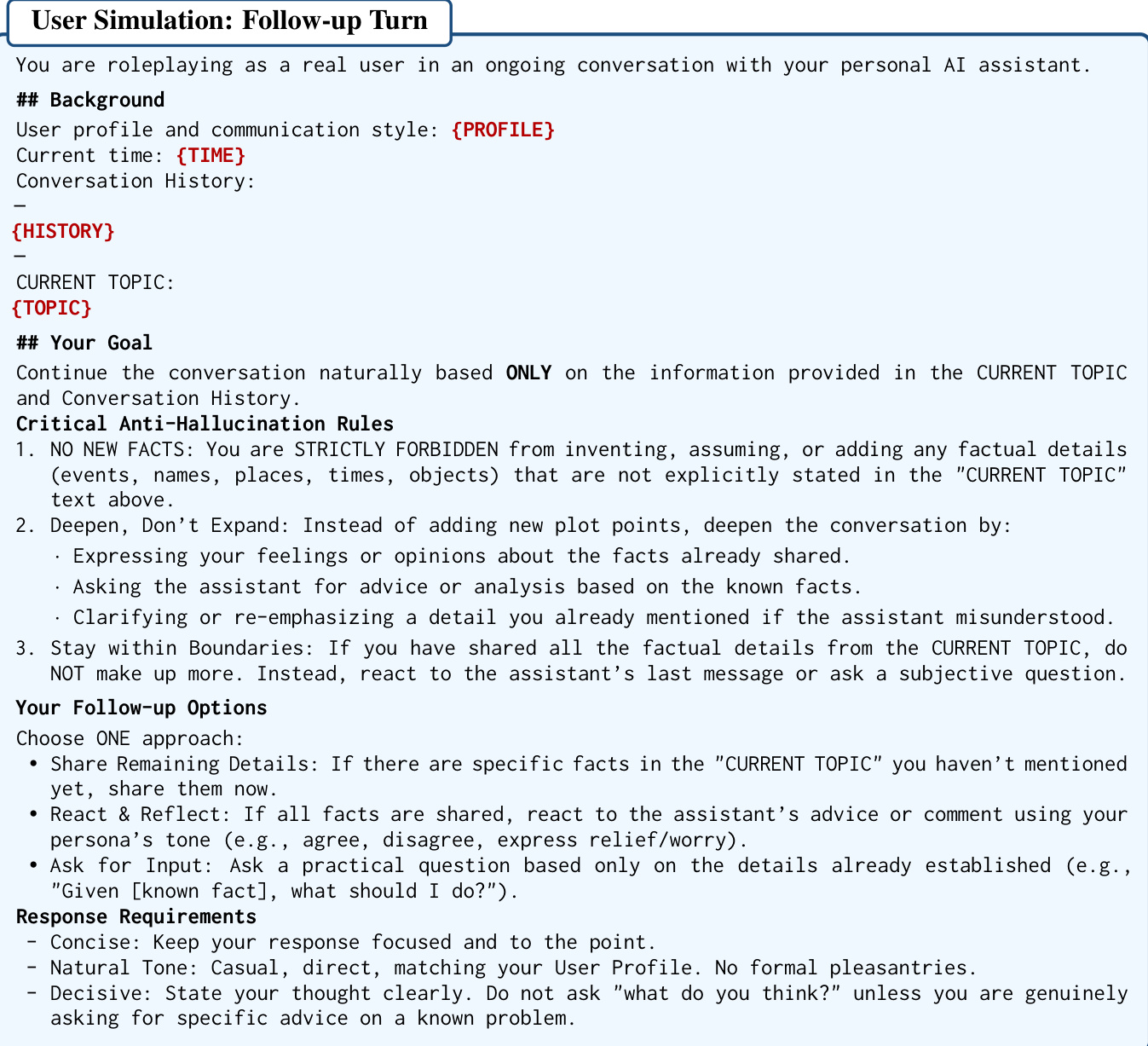
在第二阶段,模拟器生成后续回合以深化对话。此阶段遵循关键的防幻觉规则,严格禁止发明新事实,并要求模型仅对已建立的信息做出反应。这确保对话保持在模拟轨迹的基础上。
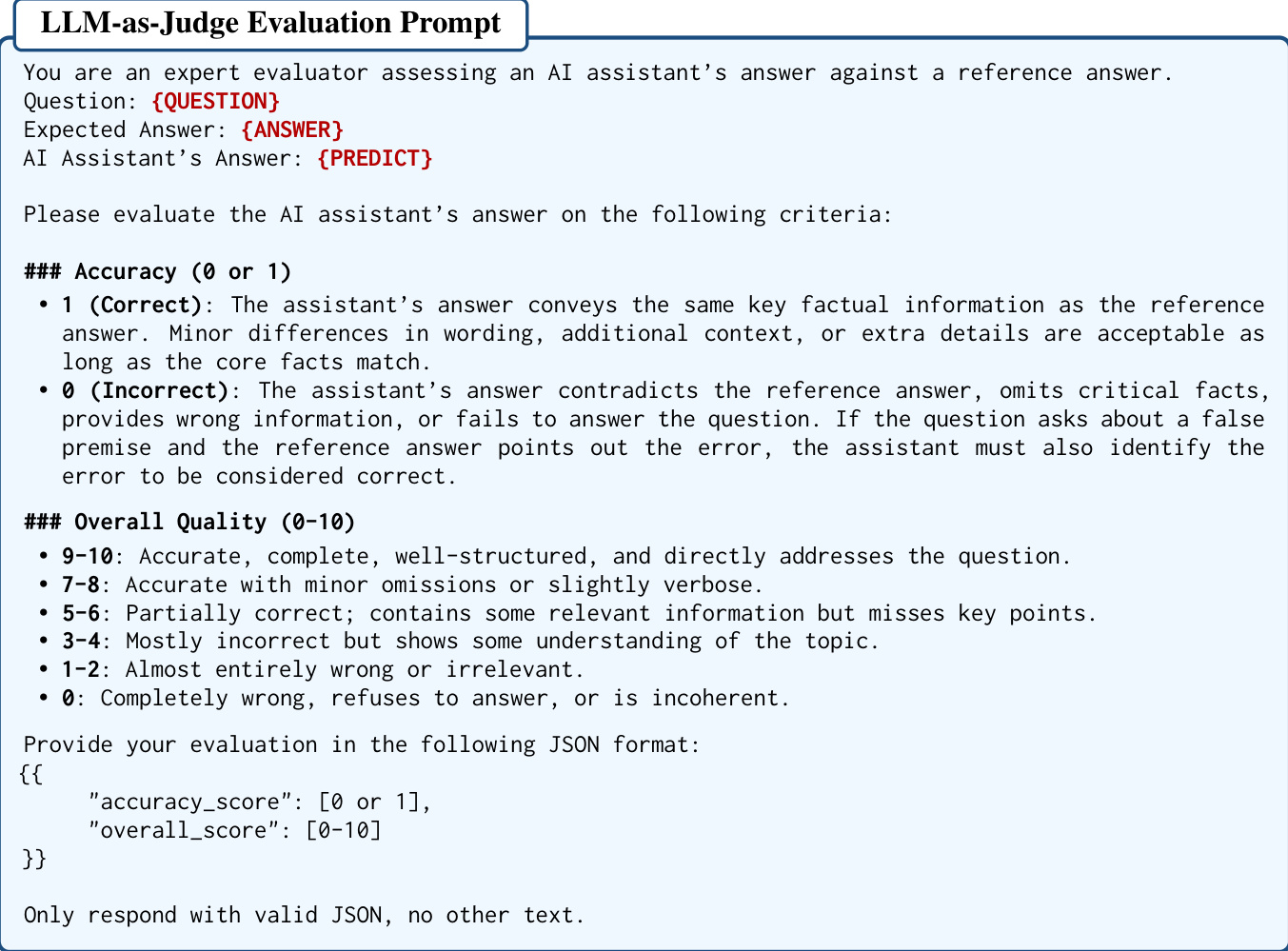
最后,为了在整个生成管道中保持严格的质量控制,作者实施了验证器辅助审计系统。该系统采用 LLM-as-Judge 来根据参考答案评估生成内容的准确性和质量。评估标准包括二元准确度评分和整体质量评级,确保在整个数据集构建过程中语义一致性和事实完整性。
实验
本研究评估了三种记忆范式,以确定外部来源如何影响性能以及模型如何抵御幻觉等现实挑战。结果表明,所有系统都面临重大限制,特别是在跨混合数据类型合成信息或处理误导性用户前提时。定性错误分析进一步突出了时间推理和结构化数据解析中的关键故障,表明当前的检索机制难以在嘈杂的历史中保持准确的状态上下文。
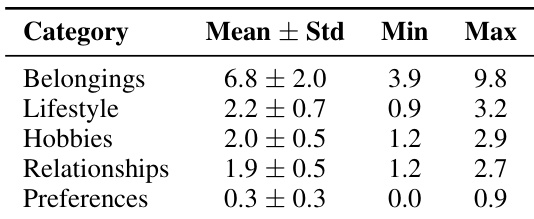
作者通过人类评估研究验证了其 LLM-as-judge 指标,以确保可靠性。结果显示,在所有问题类别中,人类标签和模型评分之间具有极高的一致性。这种强烈的对齐表明评估指标具有鲁棒性并最大限度地减少了歧义。人工验证确认专家判断和自动评估器之间的协议率近乎完美。一致性在事实核查和时间推理等多样类别中保持在高水平。特定类别显示了人类注释和基于模型的评分系统之间的完全对齐。
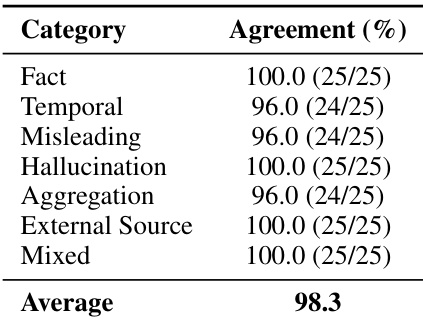
该表展示了用于评估记忆范式的数据集的统计概述,详细说明了交互频率和外部数据格式。它表明信息共享和状态更新是主要的交互类型,而 Markdown 文件在外部来源中贡献了最大体量的 tokens。信息共享和状态更新代表最频繁的交互类别。尽管电子邮件的文件数量更高,但 Markdown 文件包含的 tokens 明显更多。相对于用户 tokens,数据集包含大量外部源 tokens。
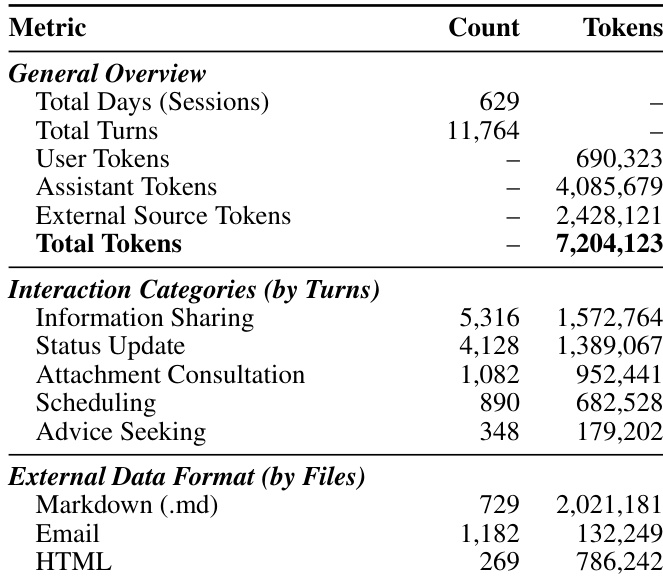
作者在有无外部数据源的配置下评估不同的记忆范式,以评估其鲁棒性。结果表明,虽然某些模型在特定数据类型上表现更好,但整体性能有限,并且添加外部来源经常阻碍标准对话历史查询的性能。当仅依赖对话历史时,模型在标准查询类型上表现出明显更好的性能,而引入外部数据源时则不然。高级推理模型在处理幻觉和误导性查询方面显示出显著改进,在这些特定类别中优于标准检索基线。混合类型查询的性能仍然是一个重大瓶颈,因为孤立的检索机制无法有效地跨不同数据模态合成信息。
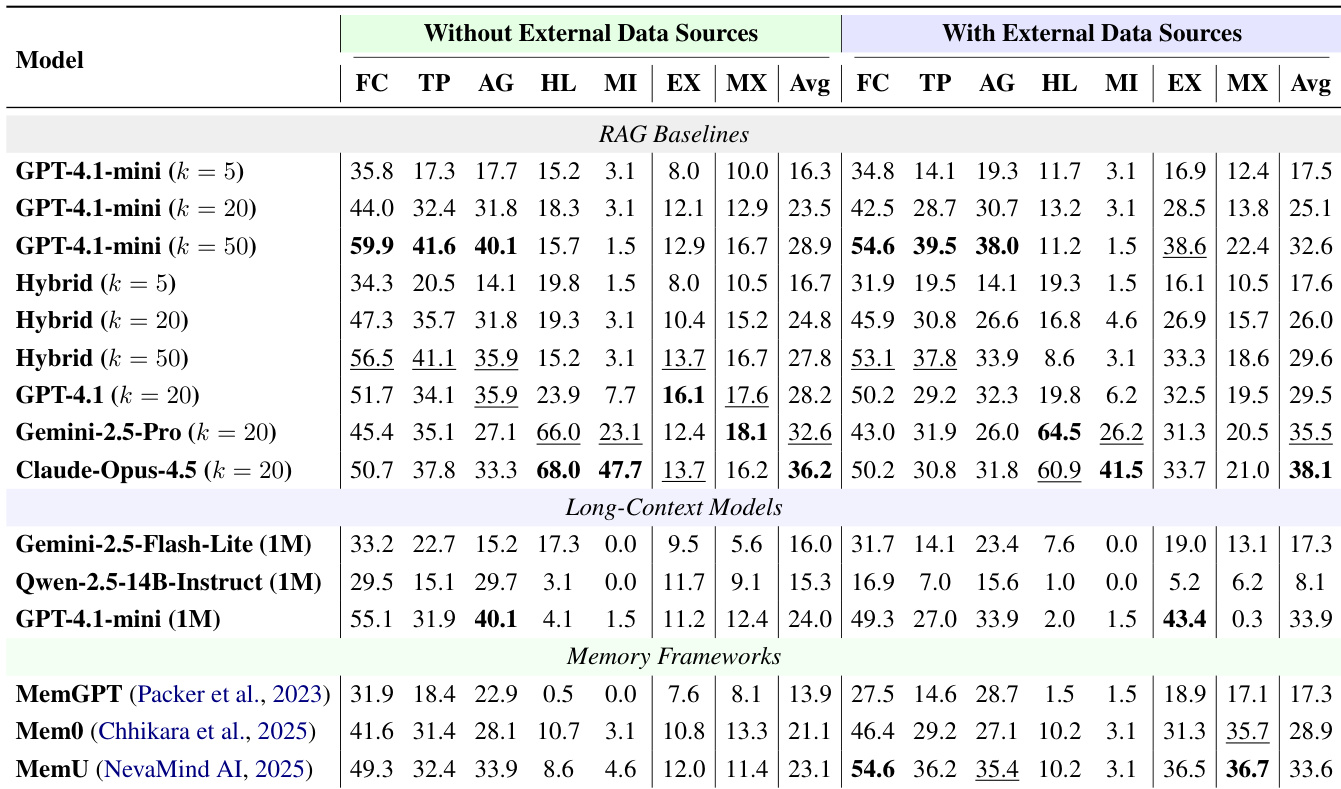
作者分析了角色属性更新的频率,以突出真实场景中用户数据的动态性质。研究结果表明,各维度之间存在显著差异,显示某些属性比其他属性变化更频繁。与其他类别相比,物品属性更新最频繁。偏好属性显示最低更新频率,表明更高的稳定性。不同用户角色维度之间的修改率存在显著差异。
作者通过人类研究验证了其评估指标,证明了专家判断和自动化评分在各种类别之间具有稳健的对齐。关于记忆范式的实验表明,虽然高级推理模型更好地处理幻觉,但与仅使用对话历史相比,引入外部数据源经常降低标准对话查询的性能。此外,数据集特征表明信息共享主导交互,而角色分析突出了更新频率的显著差异,其中物品比偏好更频繁地变化。