HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
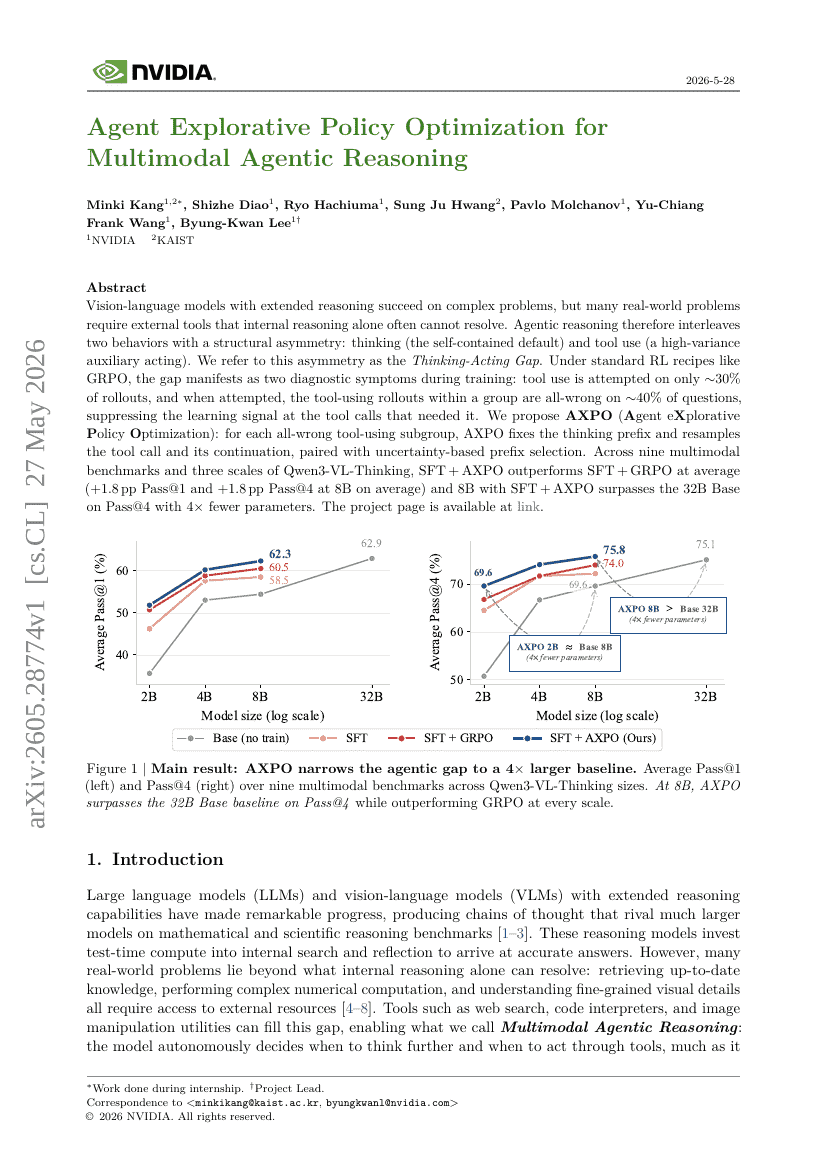
Agent探索性策略优化用于多模态Agent推理

ProRL:基于修正策略梯度估计的高效主动推荐强化学习
























Agent探索性策略优化用于多模态Agent推理
ProRL:基于修正策略梯度估计的高效主动推荐强化学习
Gamma-World:超越双玩家的生成式多 Agent 世界建模
AutoFigure:生成与优化可供出版的科学插图
AutoResearch AI:迈向人工智能驱动的科学发现研究自动化
Agent Harness 综述
D2-Monitor:基于犹豫感知路由的扩散语言模型动态安全监控
面向鲁棒多视图三维重建的几何感知表征去噪
EvalVerse:面向专业电影级视频生成的流水线感知与专家校准基准测试
MobileGym:一种用于移动 GUI Agent 研究的可验证且高度并行的仿真平台
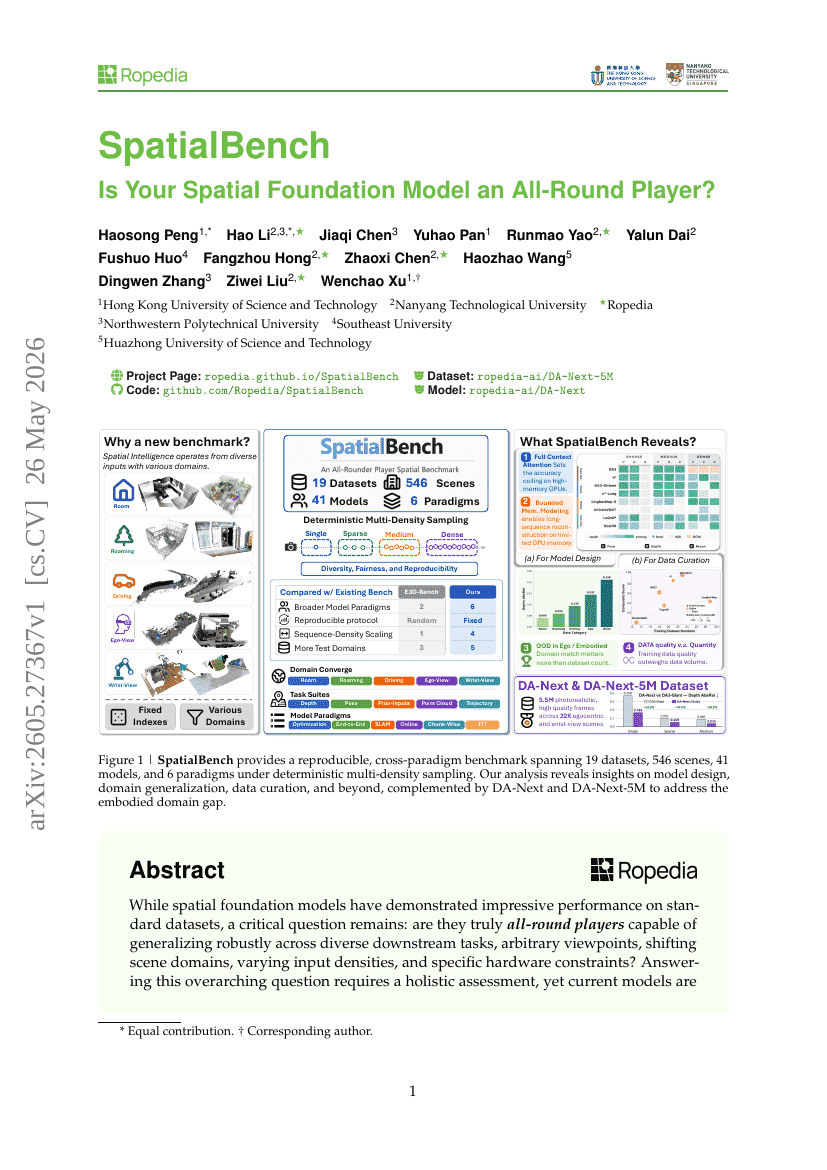
SpatialBench:你的空间基础模型是全能选手吗?
LocateAnything:基于并行框解码的快速且高质量视觉-语言定位
Gemini Embedding 2:来自 Gemini 的原生多模态 Embedding 模型
语言模型需要睡眠
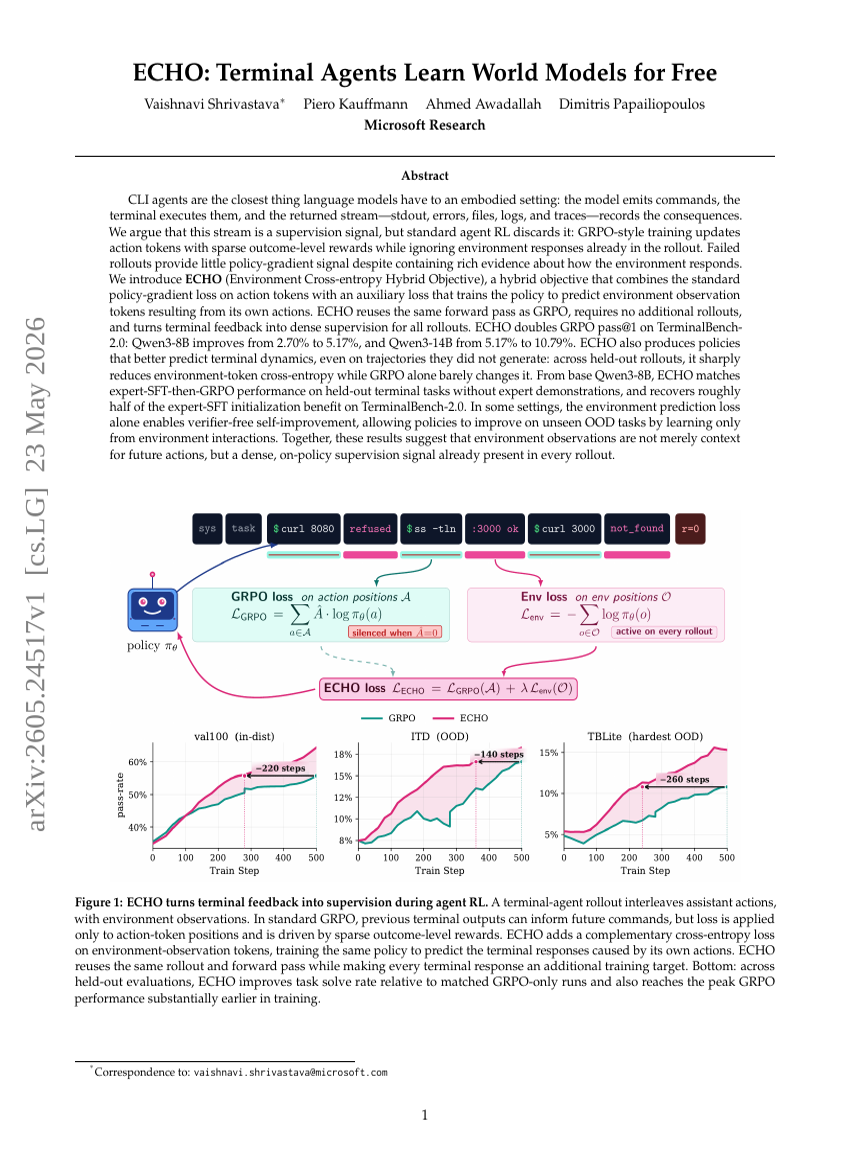
ECHO:终端代理免费学习世界模型
ParaVT:驯服代理视频强化学习中并行工具使用的工具先验悖论
TriSplat:仿真就绪的前馈式3D场景重建
基础协议:面向 Agent 社会的协调层
WBench:用于交互式视频世界模型评估的综合多轮基准
Macaron-A2UI:个人 Agent 中生成式 UI 的模型
DVAO:用于多奖励强化学习的动态方差自适应优势优化
ViMU:视频隐喻理解基准测试
SMOL:115种代表性不足语言的专业级平行翻译数据
Chi-Bench:AI 智能体能否自动化端到端、长周期、政策丰富的医疗工作流?
结合策略优化与蒸馏的大语言模型长上下文推理方法
通过对比的视角:视觉语言模型(VLMs)中自我改进的视觉推理
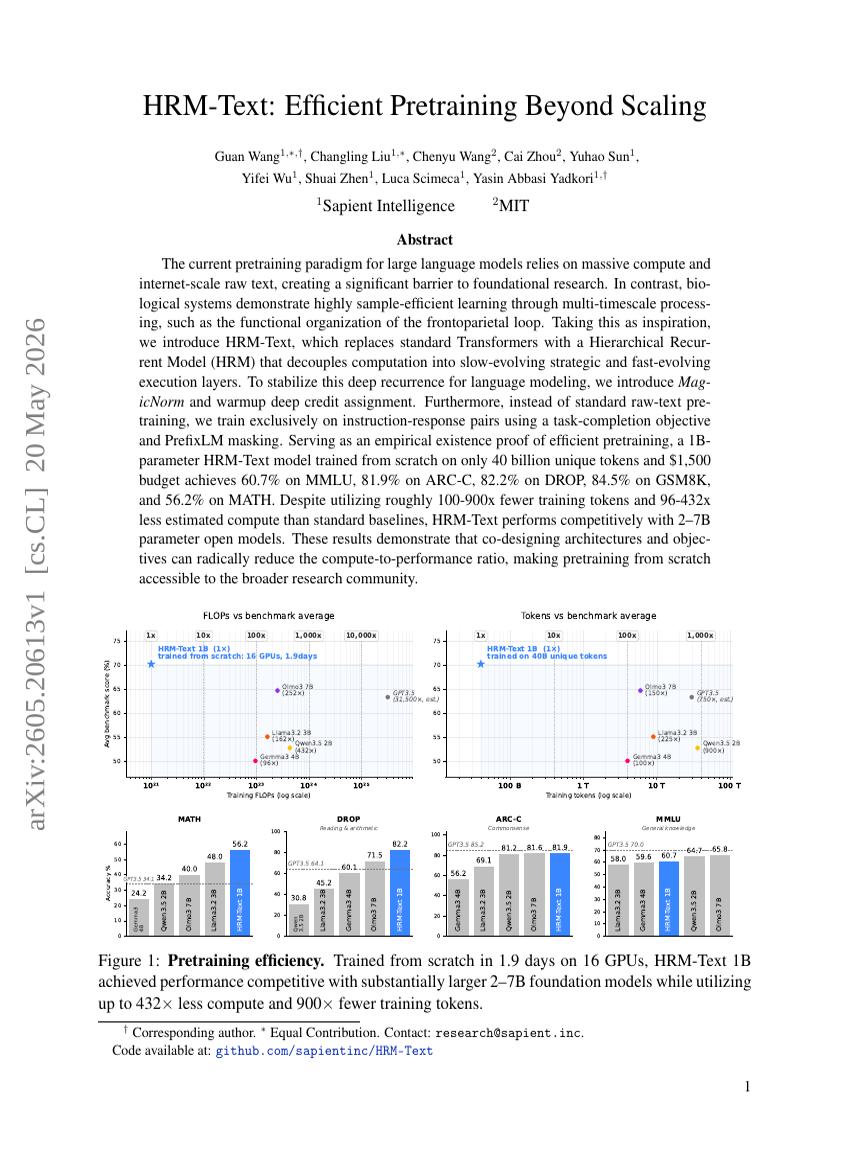
HRM-Text:在高效预训练中超越规模化
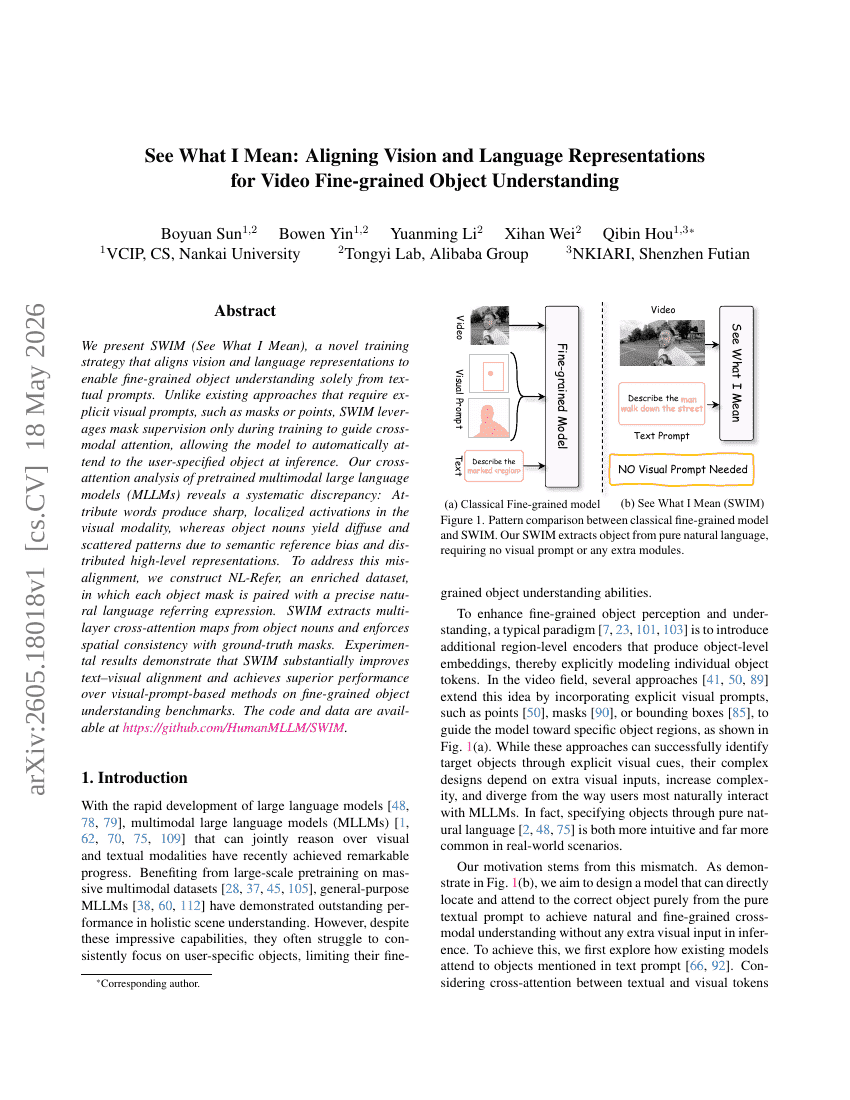
理解我的意思:对齐视觉和语言表示以实现视频细粒度对象理解
StepAudio 2.5 技术报告
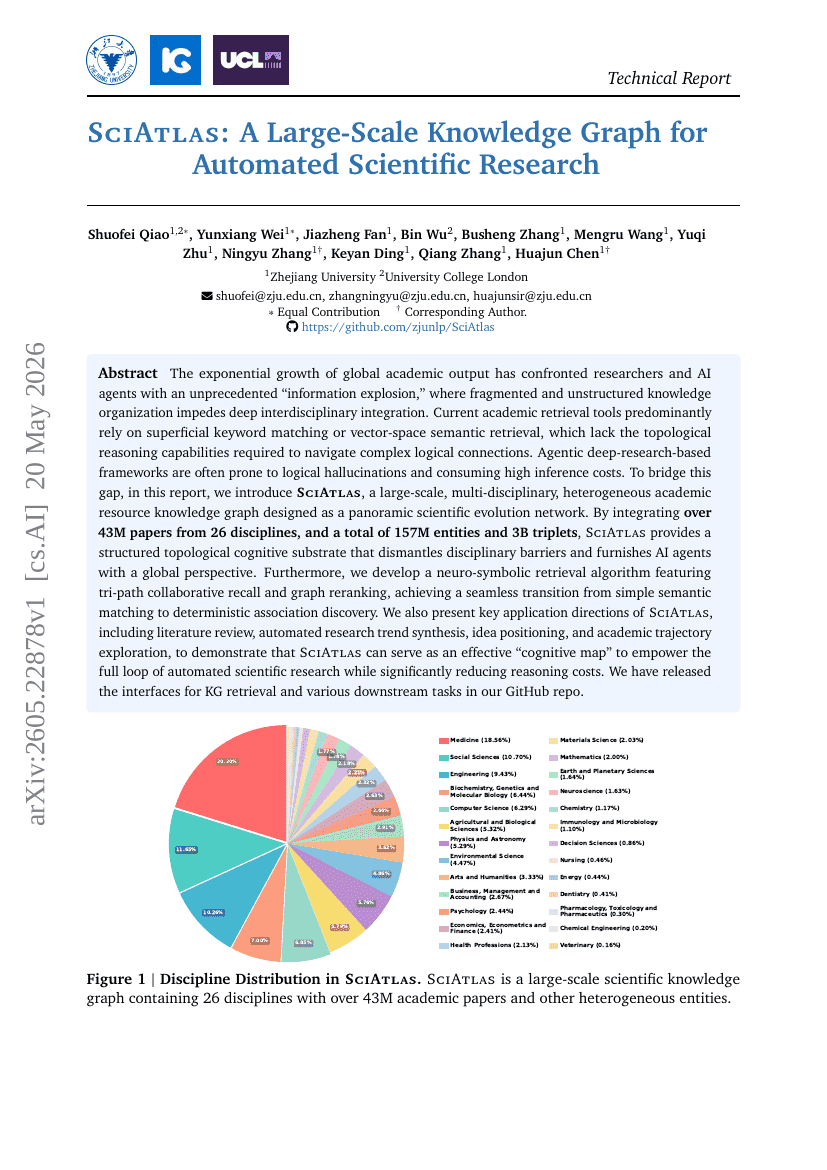
SciAtlas:用于自动化科学研究的大规模知识图谱
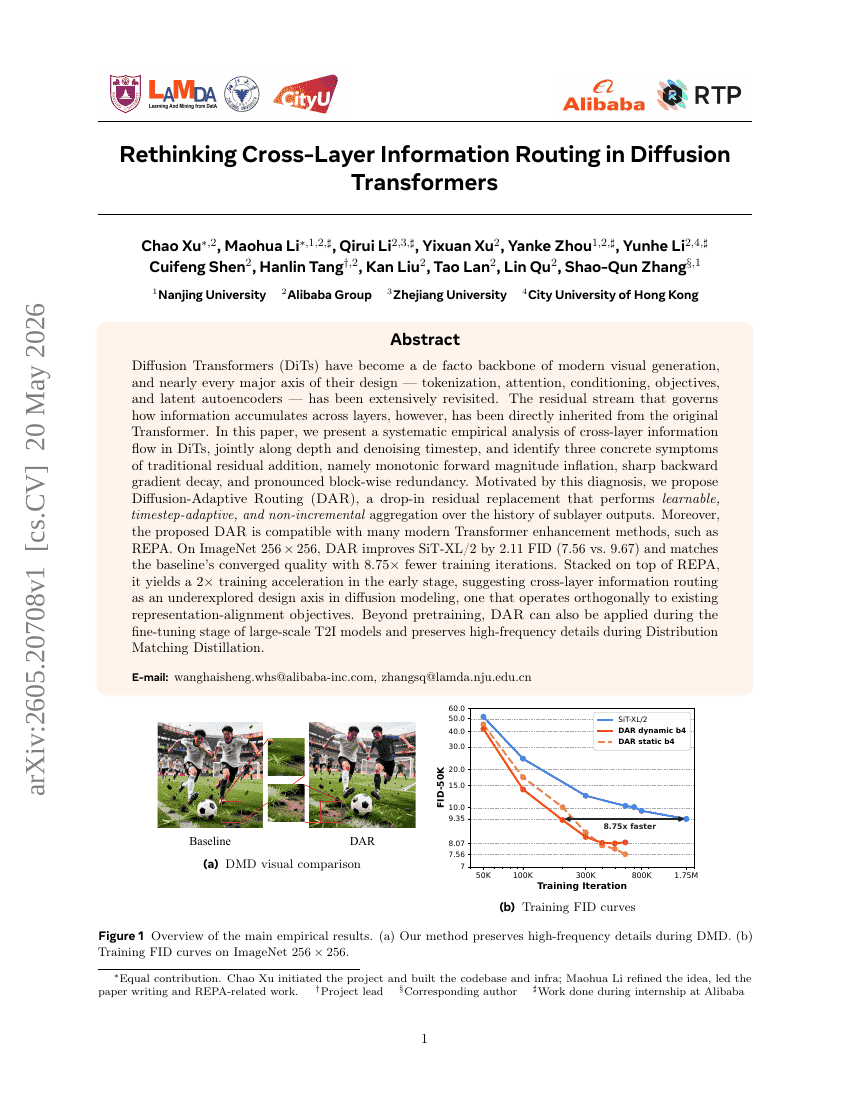
重新思考扩散Transformer中的跨层信息路由
Lens:重新思考基础文本到图像模型的训练效率
Gamma-World:超越双玩家的生成式多 Agent 世界建模
AutoFigure:生成与优化可供出版的科学插图
AutoResearch AI:迈向人工智能驱动的科学发现研究自动化
Agent Harness 综述
D2-Monitor:基于犹豫感知路由的扩散语言模型动态安全监控
面向鲁棒多视图三维重建的几何感知表征去噪
EvalVerse:面向专业电影级视频生成的流水线感知与专家校准基准测试
MobileGym:一种用于移动 GUI Agent 研究的可验证且高度并行的仿真平台
SpatialBench:你的空间基础模型是全能选手吗?
LocateAnything:基于并行框解码的快速且高质量视觉-语言定位
Gemini Embedding 2:来自 Gemini 的原生多模态 Embedding 模型
语言模型需要睡眠
ECHO:终端代理免费学习世界模型
ParaVT:驯服代理视频强化学习中并行工具使用的工具先验悖论
TriSplat:仿真就绪的前馈式3D场景重建
基础协议:面向 Agent 社会的协调层
WBench:用于交互式视频世界模型评估的综合多轮基准
Macaron-A2UI:个人 Agent 中生成式 UI 的模型
DVAO:用于多奖励强化学习的动态方差自适应优势优化
ViMU:视频隐喻理解基准测试
SMOL:115种代表性不足语言的专业级平行翻译数据
Chi-Bench:AI 智能体能否自动化端到端、长周期、政策丰富的医疗工作流?
结合策略优化与蒸馏的大语言模型长上下文推理方法
通过对比的视角:视觉语言模型(VLMs)中自我改进的视觉推理
HRM-Text:在高效预训练中超越规模化
理解我的意思:对齐视觉和语言表示以实现视频细粒度对象理解
StepAudio 2.5 技术报告
SciAtlas:用于自动化科学研究的大规模知识图谱
重新思考扩散Transformer中的跨层信息路由
Lens:重新思考基础文本到图像模型的训练效率