Command Palette
Search for a command to run...
世界追踪:超越可视范围的生成式像素对齐几何
世界追踪:超越可视范围的生成式像素对齐几何
Hao Zhang Mohamed El Banani Jen-Hao Cheng Paul Zhang Yi Hua Ben Mildenhall Christoph Lassner Narendra Ahuja Gengshan Yang
摘要
图像到三维(Image-to-3D)方法往往在保真度与完整性之间进行权衡:深度估计器锚定于输入像素,但仅重建可见表面;而图像到三维生成模型虽然能生成完整的几何形状,却常与输入图像发生错位。为此,我们提出“世界追踪”(World Tracing)方法,这是一种生成的像素对齐几何表示法,能够预测与观测像素对齐的三维点,同时补全可见表面之外的几何结构。对于每个输入像素,World Tracing 预测一个有序堆叠的相机空间三维点序列。该堆叠的第一层代表可见表面,后续层则代表与遮挡表面的前-后(front-to-back)相交点。我们通过世界追踪扩散 Transformer(WT-DiT)实现了这种表示法。WT-DiT 将多个几何层视为独立的去噪 token,并通过因式分解注意力(factorized attention)和全局注意力(global attention)进行耦合。WT-DiT 采用像素空间流匹配(pixel-space flow matching)进行训练,并使用一种混合噪声调度策略,以平衡可见表面的重建与遮挡几何的生成。在世界追踪方法在对象、场景及动态基准测试中,均在可见表面重建和完整几何生成方面展现出优异性能,超越了传统的深度预测器和图像到三维生成器。此外,该方法还保持了二维到三维的对应关系,支持基于文本驱动的三维场景编辑、几何条件的新视角视频合成,以及无需训练即可与纹理网格生成器集成。
一句话总结
World Tracing 是一种生成式像素对齐几何表示,通过世界追踪扩散 Transformer(WT-DiT)实例化,采用像素空间流匹配和混合噪声调度进行训练。它预测每个输入像素的有序相机空间 3D 点堆栈,表示可见和遮挡表面,在物体、场景和动态基准测试中优于深度预测器和图像到 3D 生成器,同时支持文本驱动的 3D 场景编辑、几何条件的新视角视频合成以及无需训练即可与纹理网格生成器集成。
核心贡献
- 本工作介绍了 World Tracing,这是一种生成式像素对齐几何表示,旨在通过预测有序的相机空间 3D 点堆栈来解决保真度与完整性之间的权衡。该方法通过扩散 Transformer 实例化此表示,该 Transformer 通过分解和全局注意力耦合多个几何层,并使用像素空间流匹配进行训练。
- 跨物体、场景和视频的全面评估表明,多层生成在保持可见表面准确性的同时提高了完整几何。该方法在这些基准测试中优于深度预测器和图像到 3D 生成器。
- 该系统保留了 2D 到 3D 的对应关系,以支持下游任务,如文本驱动的 3D 场景编辑和几何条件的新视角视频合成。额外的演示展示了无需训练即可与纹理网格生成器集成,验证了该模型作为几何先验的实用性。
引言
单图像 3D 估计通常迫使在忠实的可见表面重建和完整几何生成之间做出选择。现有的深度估计器与输入像素对齐,但无法对遮挡表面进行建模,而图像到 3D 模型生成完整形状,但代价是像素对齐。这一限制阻碍了需要一致相机空间几何的下游应用,如 3D 编辑和新视角合成。为了解决这一问题,作者介绍了 World Tracing,这是一种生成式像素对齐几何表示,预测每个输入像素的有序 3D 点堆栈,以捕获可见和隐藏表面。其通过流匹配训练的扩散 Transformer 实例化此表示,以统一高保真表面估计与合理的遮挡几何补全。
数据集
数据集组成与来源
- 作者构建了三个用于多层 3D 资产训练的语料库,包含约 30 万个物体、场景帧和 1.68 万个动态片段。
- 物体数据来源包括 Objaverse-XL、Objaverse、3D-FUTURE、Toys4k、GSO 和 TrueBones,产生了约 1700 万个渲染视图。
- 场景数据结合了公共 3D-FRONT 语料库和一个保留的内部场景集,用作泛化探针。
- 动态资产由 Objaverse-XL 动画子集和来自 TrueBones 的绑定角色组成,采样为短视频片段。
- 补充的 12 数据集 RGBD 风格语料库支持混合训练,包含来自 ScanNet v2、MegaDepth 和 Waymo Open 的真实照片,以及 Hypersim 和 Taskonomy 等合成集。
每个子集的关键细节
- 渲染利用随机化照明、视角和内参以确保多样性。
- 真值层源自深度剥离,以记录有序的前后表面交点。
- 前向填充规则填充具有少于 L 个交点的射线,以创建密集 L 层 XYZ 目标。
- RGBD 风格语料库仅针对可见表面层 L0 提供监督,而多层语料库塑造 L1 到 L5 层。
模型使用与训练混合
- 小批量以 60% 的概率从 3D 资产语料库采样,以 40% 的概率从 RGBD 风格语料库采样。
- RGBD 数据集按行数的平方根加权,真实照片集提升 1.5 倍。
- 训练在 504x504 分辨率下进行,全局批量大小为 512,通过 AdamW 优化。
- 评估依赖于保留的公开基准,包括 100 个唯一物体、3D-FRONT 划分以及动态基准如 Obj-Val 和 Truebone。
处理和增强策略
- 在线增强对图像和相机空间目标同时应用随机裁剪、翻转和仿射扰动。
- 光度抖动调整亮度、对比度和饱和度,而 alpha 蒙版经历随机膨胀或腐蚀。
- 动态片段在帧之间保持几何和蒙版空间增强的一致性,以保留时间完整性。
- 深度值使用原始内参转换为相机空间 XYZ,并通过每个样本的对数中值图进行归一化。
方法
作者提出了一种图像到 3D 流水线,旨在从单张输入图像生成 L 层点图。这种方法的核心是一种像素对齐表示,其中几何表示为张量 X∈RL×H×W×3,每层对应沿像素射线的前后交点。为了促进训练,作者采用密集监督策略,其中较深层中的空交点从最近的较早有效层填充,确保每个有效输入射线监督所有层。
整体框架在提供的图表中说明。过程从两个输入开始:RGBA 图像 (H,W,4) 和噪声多层 XYZ 堆栈 (L,H,W,5)。视觉信息由冻结的 MoGe ViT-L 编码器处理,生成像素对齐图像 tokens。同时,噪声几何被块化为几何 tokens。这两流 tokens 随后被融合在一起。
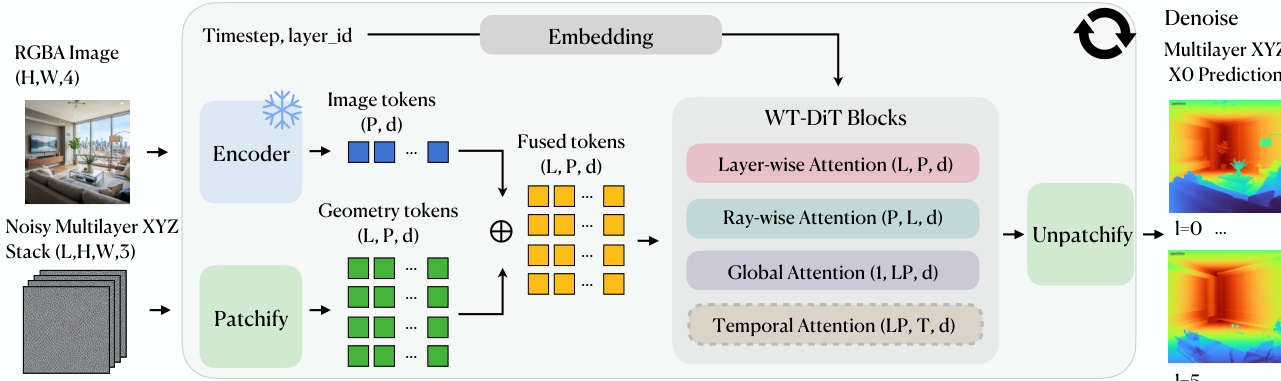
融合后的 tokens 被送入 WT-DiT 块堆栈,作为核心扩散 Transformer。该模块采用专用的三方注意力分解来有效地处理多层结构。首先,层间注意力允许每层将自己作为 2D 图像进行关注。其次,射线间注意力使同一像素的 tokens 能够沿前后层轴进行关注,强制执行深度排序和一致性。第三,全局注意力恢复物体或场景级上下文。对于动态片段,还插入时间注意力块以处理时间轴依赖。
条件通过时间步和层标识符的嵌入应用。这些嵌入通过 FiLM 层调制到网络中,无需可学习加性位置 tokens 即可打破层排列对称性。网络使用流匹配目标直接在归一化坐标信号上进行训练,预测干净端点 x^0。最后,输出 tokens 被反块化以生成最终去噪多层 XYZ 预测,保留相机空间坐标和像素到 3D 对应关系。
实验
实验验证了像素对齐多层范式在物体、场景和动态片段上产生更忠实的 3D 几何,同时有益于依赖于姿态或遮挡结构的下游流水线。定性比较表明,该模型生成完整几何而不牺牲可见表面准确性,通过更好地建模遮挡表面和保留分布外输入上的平面结构,优于基于回归和标准帧的基线。下游演示证实,这种相机空间表示实现了鲁棒的物体插入、纹理网格生成和视图合成,确立了多层方法作为现实世界几何任务的优越先验。
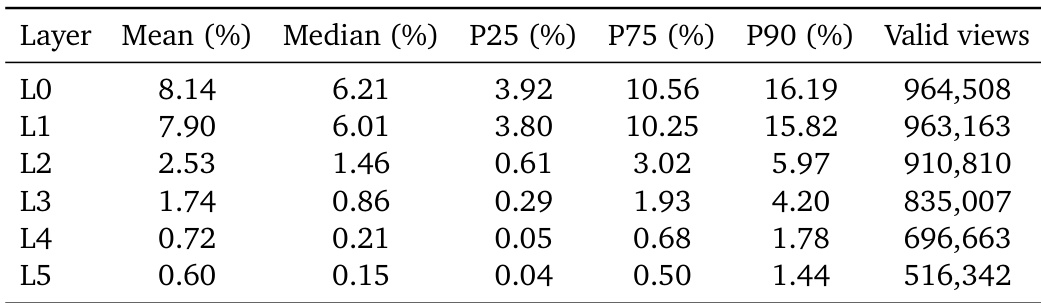
该表格展示了多层几何模型的有效像素覆盖率和视图计数的每层统计信息。结果表明,随着层深度从表面增加到更深的遮挡区域,平均覆盖率和有效视图均呈现一致的下降趋势。平均有效覆盖率在初始层最高,并在后续层中显著减小。随着层索引从上到下移动,有效视图数量稳步减少。可见表面层和更深几何层之间的数据密度存在显著差异。
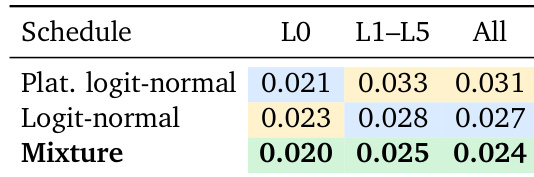
作者评估了不同的扩散时间步调度,以确定其对多层几何生成质量的影响。虽然特定调度有利于可见表面或更深遮挡层,但将它们组合成混合体在整个几何堆栈上产生最一致的结果。平台化 logit-normal 调度在可见 Layer 0 上优于标准调度。与平台化变体相比,标准 logit-normal 调度对更深层更有效。两种分布的混合在所有层上实现了最佳整体性能。
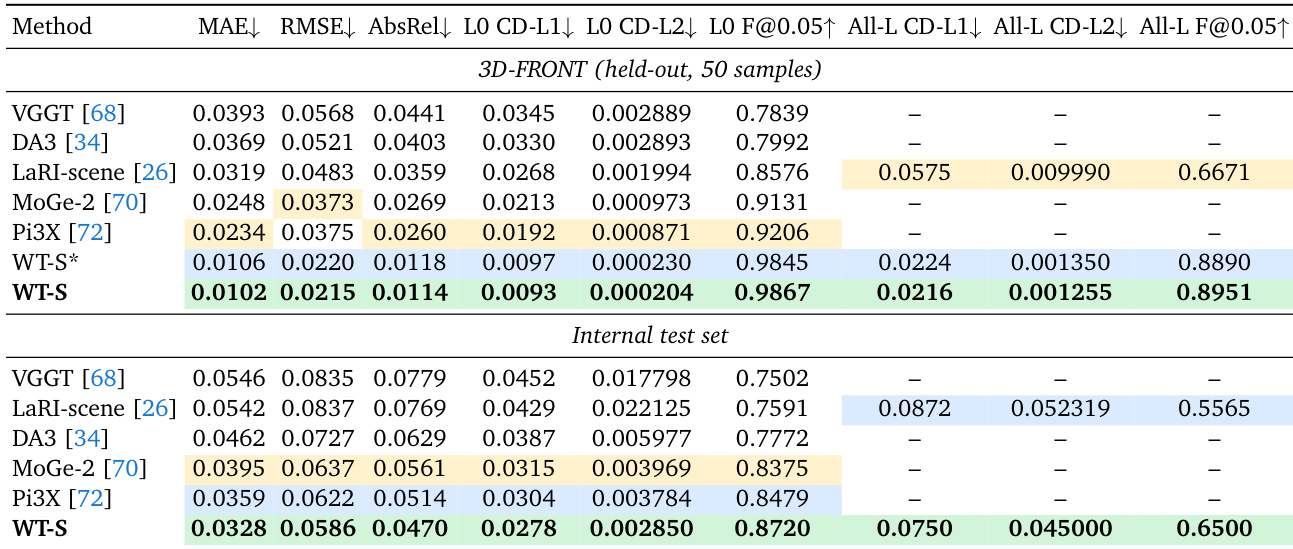
作者在 3D-FRONT 基准和内部测试集上评估了场景几何生成。与 LaRI-scene 和 MoGe-2 等现有基线相比,提出的 WT-S 方法在可见表面深度准确性和完整多层几何重建方面实现了卓越性能。WT-S 在所有比较方法中实现了最佳可见表面深度和 L0 点云几何。该方法在所有层几何指标上比不产生遮挡层的单层基线有了显著改进。在更广泛语料库上训练的全模型在保留基准上优于仅在 3D-FRONT 上训练的模型。
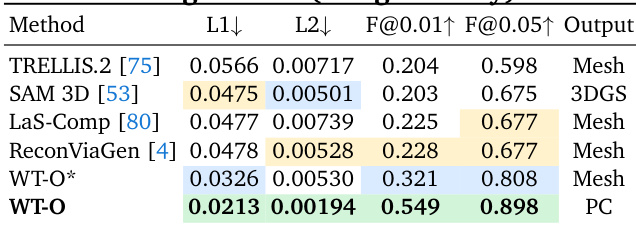
该表格对比了提出的 WT-O 方法与若干基线在物体几何生成方面的表现。结果表明,WT-O 实现了最高的准确性和完整性,优于生成网格或 3D Gaussians 的方法。数据支持像素对齐多层范式在物体上产生更忠实 3D 几何的主张。与其他方法相比,WT-O 在所有测量类别中实现了最佳性能指标。提出的方法生成的点云输出在几何保真度方面超越了基于网格和 3D Gaussian 的基线。在此评估中,TRELLIS.2 和 ReconViaGen 等基线显示出更高的错误率和更低的保真度分数。
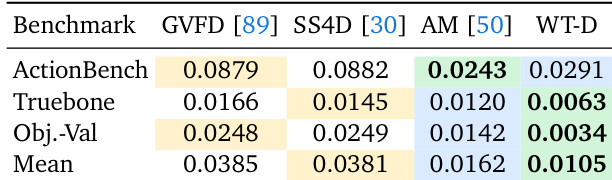
作者使用提出的模型与若干基线在物体、绑定和动作驱动划分上评估动态几何生成。提出的方法实现了最佳整体平均性能,并在物体验证和绑定资产基准上领先。ActionMesh 在动作驱动基准上表现尤为出色,其中真值与其原生输出格式匹配。提出的模型在所有动态几何基准上实现了最佳平均性能。结果显示,与扩散和回归基线相比,在物体验证和绑定资产评估上具有更高的准确性。由于与真值的原生格式对齐,ActionMesh 在动作驱动运动任务中保持顶级表现。
实验评估了多层几何模型在场景、物体和动态生成任务上的表现,揭示了可见表面和更深遮挡区域之间的显著数据密度差异。扩散调度的评估表明,组合分布可产生跨层的一致结果,而提出的方法在重建精度和完整性方面优于现有基线。结果验证了在评估场景中,像素对齐多层范式比传统网格或高斯方法产生更忠实的 3D 几何。