Command Palette
Search for a command to run...
关于在线策略蒸馏的几何
关于在线策略蒸馏的几何
Zhennan Shen Yanshu Li Qingyu Yin Chak Tou Leong Zhilin Wang Yanxu Chen Rongduo Han Sunbowen Lee Yi R. Fung
摘要
策略内蒸馏(OPD)日益被用于提升大语言模型的推理能力,但其训练动态尚未得到充分理解。我们刻画了OPD更新在参数空间中的轨迹,并将其与监督微调(SFT)及可验证奖励强化学习(RLVR)进行比较。一系列参数空间诊断指标一致表明,OPD处于一种松弛的偏离主成分状态:与SFT相比,其更新影响的权重更少,且更显著地避开主成分方向;而与RLVR相比,其更新受到的约束则相对宽松。除上述静态定位外,OPD还表现出子空间锁定现象:其累积更新迅速进入一个狭窄的低维通道中。将训练限制在训练初期形成的更新子空间内,能够保持OPD的性能,但会显著降低SFT的效果,这表明该锁定子空间在功能上已足以满足OPD的需求。控制实验进一步表明,对更新tokens进行稀疏化处理以及使rollout生成偏离策略,均能保持秩动态,而将OPD目标与RLVR混合则会改变该动态。总体而言,这些结果表明,OPD并非仅仅是SFT与RLVR之间的过渡点,而是在参数空间中诱导出了一种独特的更新几何结构。
一句话总结
针对大语言模型推理的在线策略蒸馏(OPD)与监督微调(SFT)及可验证奖励强化学习(RLVR)进行的参数空间诊断表明,OPD 动力学占据一个松弛的离主成分状态,并迅速经历子空间锁定。这表明 OPD 诱导了一种独特的低维更新几何结构,当将其约束于早期更新子空间时能够保持性能,而不仅仅是作为监督微调与可验证奖励强化学习之间的中间过渡点。
核心贡献
- 本文通过引入松弛的离主成分状态来刻画在线策略蒸馏的参数空间轨迹,将其定位在监督微调与可验证奖励强化学习之间。针对更新稀疏度、谱漂移和主子空间旋转的诊断表明,与监督微调相比,在线策略蒸馏施加了更具选择性且能保持几何结构的更新,同时受到的约束少于强化学习。
- 分析发现了一种子空间锁定现象,即累积参数更新在训练早期迅速收敛到一个狭窄的低维通道中。跨检查点追踪有效维度和谱形状表明,将后续优化约束于该早期子空间能够保持在线策略蒸馏的性能,同时显著降低监督微调的性能,从而证实该通道在功能上是充分的。
- 隔离 token 监督密度、 rollout 策略和目标组成的控制实验表明,稀疏化 token 并将 rollout 策略切换为离策状态能够保持低秩动力学特性。引入强化学习目标进行插值会破坏该轨迹,证实锁定子空间对运行时扰动具有鲁棒性,但对训练目标高度敏感。
引言
大型推理模型已通过监督微调和强化学习等后训练方法在复杂数学与编程任务上取得进展,尽管在线策略蒸馏在实践中取得了成功,但其内在机制仍缺乏深入理解。先前的几何分析仅单独涵盖监督微调与强化学习,无法预测在线策略蒸馏如何探索参数空间,因为它本质上将密集的 token 级指导与对策采样相结合。作者利用一系列参数空间诊断工具,将在线策略蒸馏定位在这两种范式之间的松弛离主成分状态,并识别出训练迅速收敛至稳定低维更新通道的早期子空间锁定现象。研究进一步证明,该轨迹严格受目标组成控制,而非 token 监督密度,从而为未来算法设计提供了清晰的几何框架。
数据集
- 数据集构成与来源: 作者未构建自定义数据集。评估套件由公开可用的模型检查点、数据集和基准测试汇编而成,具体引用了 Qwen3、DAPO-Math-17k、Dolci-Think SFT、DeepCoder 和 LiveCodeBench。
- 各子集关键细节: 每项资源均源自开源仓库,并对照其原始许可证或使用条款进行验证。作者确认所有组件均符合预期研究目的,并明确声明未重新分发任何原始材料。
- 数据使用与处理: 收集的资源严格保留用于研究评估与分析,而非模型训练。作者使用 ChatGPT 起草了初步的绘图与分析脚本,但所有实验设计、数值结果和代码逻辑均由研究团队独立审查与编辑。
- 元数据与额外处理: 所提供部分未描述自定义裁剪策略、元数据构建或训练混合比例。工作流程优先保证引用透明、许可证合规,并对所有 AI 辅助写作与代码生成进行人工验证。
方法
作者利用一个框架分析在线策略蒸馏(OPD)的参数空间动力学,并将其与监督微调(SFT)及可验证奖励强化学习(RLVR)进行对比。该框架围绕四项核心诊断构建:更新稀疏度、主角度旋转、谱漂移和更新掩码重叠。这些指标用于刻画大语言模型参数空间中参数更新的位置与演变。如下图所示,该框架将 OPD 定位在一个松弛的离主成分状态中,与 SFT 和 RLVR 均有所区别。SFT 引发密集更新,影响大量权重并强烈旋转预训练子空间,而 RLVR 表现出高度局部化的更新,从而保留预训练几何结构。OPD 占据中间位置,影响的权重少于 SFT,且比 SFT 更强烈地避开主方向,同时受到的约束少于 RLVR。
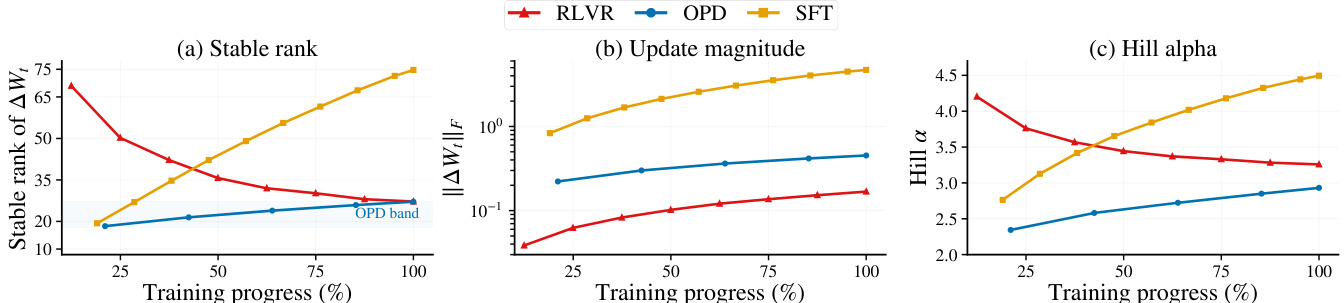
作者进一步研究 OPD 的训练轨迹,揭示了一种称为子空间锁定的现象。该现象指累积参数更新在训练早期迅速收敛到一个狭窄的低维子空间中。通过追踪每个检查点的累积更新 ΔWt=Wt−W0 来跟踪该轨迹。稳定秩定义为 srang(ΔWt)=∥ΔWt∥ob2∥ΔWt∥F2,用于衡量携带更新能量的主导奇异方向的有效数量。Frobenius 范数 ∥ΔWt∥F 用于衡量累积更新的幅度。如下图所示,OPD 的稳定秩迅速稳定在较低值,表明更新被限制在一个较小的子空间内。该锁定子空间对 OPD 而言在功能上是充分的,因为将其约束于此能保持性能,而相同约束会严重降低 SFT 的表现。这表明 OPD 的更新几何并非仅仅是中间状态,而是其训练动力学涌现出的特性。

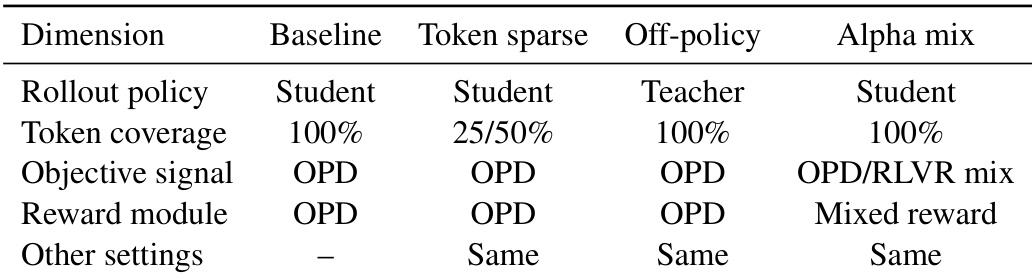
为理解维持该锁定子空间的机制,作者进行了一系列控制实验。他们对三个候选因素施加扰动: token 级教师监督、 rollout 生成策略和目标组成。实验表明,稀疏化更新 token 并将 rollout 生成切换为离策状态能够保持秩动力学特性,表明这些运行时扰动不会破坏锁定子空间。相比之下,将 OPD 目标与 RLVR 混合会改变秩动力学。作者基于梯度源提供了机制性解释。OPD 梯度是 token 级校正的总和,gOPD=∑tJt⊤δt,其中 Jt 为局部雅可比矩阵,δt 为师生 token 差异。若 token 梯度共享一个主导更新子空间,掩码处理或更改 rollout 策略主要重新缩放二阶矩,从而保留主导谱方向。然而,目标混合改变了梯度源本身,结合了 OPD 与 RLVR 梯度:gα=αgOPD+(1−α)gRLVR。这改变了协方差几何结构,解释了其为何会破坏类 OPD 的秩轨迹。下图总结了这些干预措施及其影响,表明锁定子空间对 token 和策略变化具有鲁棒性,但对目标组成高度敏感。

实验
实验在旨在刻画参数空间几何、更新动力学和功能充分性的诊断设置中,将 OPD 与监督微调和强化学习基线进行了对比评估。结果表明,OPD 占据一个中间的非主成分状态,在保留模型几何结构方面比监督微调更有效,同时受到的约束少于强化学习。额外分析验证了 OPD 迅速锁定到一个持久且低维的更新子空间中,该子空间在早期涌现并能抵御运行时扰动,而功能充分性测试证实将更新约束于该早期通道能够维持性能。综合来看,这些发现确立了 OPD 的锁定子空间是学习过程中稳健且功能充分的驱动因素。
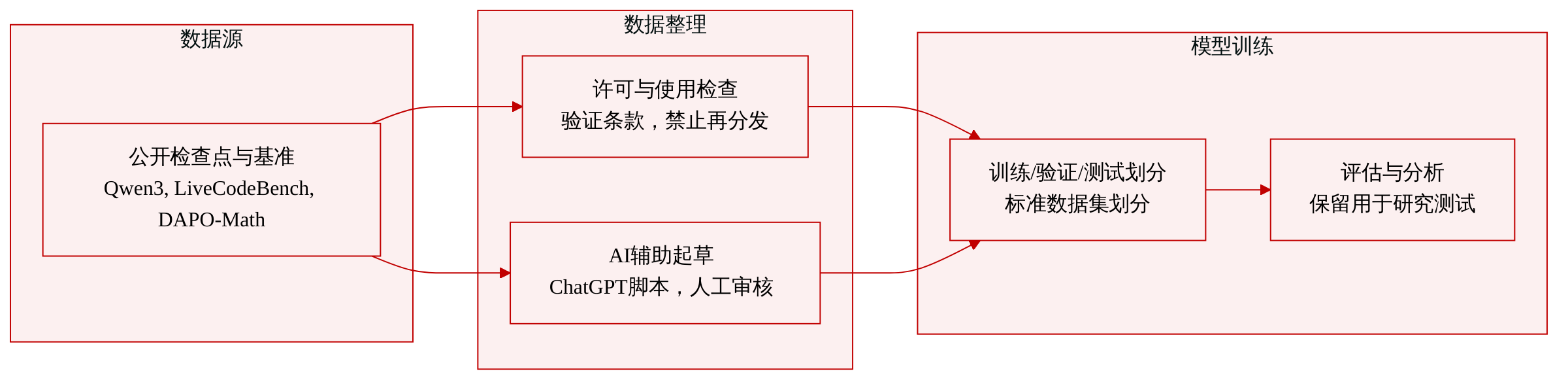
作者对比了不同微调方法及其参数更新,表明 OPD 在稀疏度和子空间旋转方面处于 SFT 与 RLVR 之间的中间状态。OPD 展现出一个在早期涌现的低维更新通道,对训练具有功能充分性,并在运行时扰动下保持稳定性。结果突出了 OPD 独特的更新模式,其特征为早期子空间锁定以及跨变体的稳定谱特性。OPD 在稀疏度和子空间旋转上介于 SFT 与 RLVR 之间,表现出中间选择性与几何保留能力。OPD 在训练早期形成低维更新通道,保持稳定且对学习具有功能充分性。OPD 的谱特性对运行时扰动具有鲁棒性,但对目标组成的变化高度敏感。
作者分析了 OPD 的参数空间动力学,显示其在稀疏度、子空间旋转和更新局部化方面处于 SFT 与 RLVR 之间的中间状态。OPD 展现出在训练早期涌现的低维更新通道,对学习具有功能充分性,且其谱特性在各种运行时扰动下保持稳定。结果表明,OPD 的低维结构并非源于微小更新,而是持久且早期锁定的更新子空间。OPD 在稀疏度和子空间旋转上介于 SFT 与 RLVR 之间,表现出中间选择性与几何保留能力。OPD 的更新通道早期涌现并保持稳定,在秩约束下展现出功能充分性。OPD 的低维更新谱特性对运行时扰动具有鲁棒性,但对目标组成的变化高度敏感。
作者分析了 OPD 的参数空间动力学,表明其处于 SFT 与 RLVR 之间的松弛离主成分状态,具有中间选择性与几何保留能力。OPD 从训练早期维持一个低维更新子空间,该子空间早期涌现且对学习具有功能充分性,秩约束下的稳健性能验证了这一点。这些发现得到了跨训练进程的稳定秩、更新幅度和谱形状诊断的支持。OPD 展现出早期涌现并在整个训练过程中保持稳定的低维更新子空间,从而区别于 SFT 与 RLVR。OPD 的早期低维更新通道具有功能充分性,因为在秩为 16 的约束下训练依然稳健。OPD 的谱特性对运行时扰动具有鲁棒性,但对目标组成的变化高度敏感,表明更新几何结构与学习目标紧密相关。
作者分析了 OPD 在不同变体中的参数空间行为,重点关注师生模型规模、数据域和随机种子变化对更新动力学的影响。结果表明,OPD 在不同配置下均保持稳定的低维更新通道,更新尺度与谱形状仅出现微小变化,表明其对这类变化具有鲁棒性。该更新通道的早期涌现与功能充分性得以保留,说明其为 OPD 过程的稳定特征。OPD 在不同师生规模、数据域和随机种子下均维持一致的低位更新通道。训练配置的变化主要影响更新尺度而非谱形状,表明更新几何结构具有鲁棒性。早期涌现且功能充分的更新通道在各种扰动下保持稳定,凸显了其在 OPD 中的持久性。
实验通过对比 OPD 与 SFT 和 RLVR 的微调轨迹,并在秩约束、架构变化和运行时扰动下测试其鲁棒性,从而评估 OPD 的参数空间动力学。定性分析表明,OPD 在稀疏度和子空间几何方面始终稳定处于两个基线之间的中间状态。OPD 不依赖微小的参数变化,而是独特地建立了一个低维且早期锁定的更新通道,该通道对学习保持功能充分性。该结构模式在不同配置下展现出强稳定性,尽管其对底层学习目标的偏移仍保持敏感。