Command Palette
Search for a command to run...
如果大型语言模型(LLMs)具有类似人类的属性,那么《帝国时代 II》亦然。
如果大型语言模型(LLMs)具有类似人类的属性,那么《帝国时代 II》亦然。
Adrian de Wynter
摘要
尽管针对大型语言模型(LLM)及由 LLM 驱动的智能体工作流(agentic workflows)已开展了大量研究,但该领域内的许多著作倾向于认为、归因于或假设 LLM 具备泛化的拟人化属性(如道德感或对自然语言的理解)。我们的目的并非论证这些属性是否存在,而是要指出这些结论可能是错误的。为此,我们在电子游戏《帝国时代 II》(Age of Empires II)上构建并训练了一个简单的神经网络,并指出,在足够强大的基质(substrate)中(例如乐高积木或大波士顿地区),任何实体也都可能呈现出此类属性。因此,LLM 所谓的拟人化属性在实证上并不具备唯一性:尽管某些属性(如对 prompt 的响应)可能保持恒定,但其他属性(如对其感知行为的解释)则可能随基质的不同而改变。因此,任何基于实证的讨论都需要明确的测量标准;否则,解释将取决于表征方式(representation)。随后,我们表明,无论实验者的观点如何,在脱离基质并泛化地假设这些属性在系统中存在或不存在,都会导致循环论证或无信息量的结论。
一句话总结
Adrian de Wynter 通过在 Age of Empires II 上训练一个简单的神经网络,证明了归因于大型语言模型的人类化属性在经验上并非独一无二,表明感知到的行为取决于底层 substrate,并指出概括性假设会导致循环论证或无信息的结论,需要明确的测量标准才能进行基于实证的讨论。
核心贡献
- 构建并在电子游戏 Age of Empires II 上训练了一个简单的神经网络,以证明所谓的人类化属性在经验上并非独一无二,且随底层 substrate 而变化。
- 提出了一种零假设,即实验避免预设人类化属性,以确保结论保持可靠和稳健。
- 感知到的人类化程度随界面呈现方式有很大差异,表明许多人化测量评估的是呈现方式而非实际系统行为。
引言
评估大型语言模型的研究经常预设人类化属性(如同理心或道德推理)的存在。这种方法论往往导致循环论证或无信息的结论,因为实验设计依赖于其试图测试的假设本身。为解决这一问题,作者在电子游戏 Age of Empires II 内训练了一个简单的神经网络,以证明人类化行为可以在任何足够强大的 substrate 中出现。他们指出,感知到的智能高度依赖于表征,并提出了一种零假设框架,以促进严谨的实验,避免结果在本质上偏向或反对人类化。
数据集
-
数据集组成与来源
- 作者通过查询 Semantic Scholar API 并检索 ArXiv 上的论文收集了科学文章。
- 搜索查询针对特定时间段(2024 年 5 月 1 日至 2026 年 5 月 1 日)内标题匹配 'agent lllm' 的内容。
- 收集过程实施了超时和退避机制,以避免过载外部服务。
-
过滤与处理
- 初始去重步骤基于精确标题匹配移除了条目。
- 使用校准过的 LLM-as-a-judge(具体为 GPT-5.2)进行了语义过滤。
- 过滤流程排除了非科学文章或未将 LLM 作为研究核心方面的作品。
- 额外的提示词分类了文档类型,并确定 LLM 是否为研究主体以进行预标注。
-
数据集规模与采样
- 作者从初始过滤池中随机采样了 1,024 篇论文的 subset。
- 应用所有过滤和标注规则后,最终 curated 数据集包含 315 篇论文。
-
元数据与标注
- 论文根据人类化属性进行了标注,包括假设、研究重点和结论。
- 作品中声称的 emergent properties 被识别为自由格式列表并手动规范化。
- 标签表明论文是否假设、研究或得出结论认为 LLM 拥有人类化属性。
-
使用与伦理
- 该数据集支持对 LLM 研究中人类化假设的调查分析,而非模型训练。
- 研究中未使用人类受试者,且爬取过程负责任地进行。
- 标注和匿名化的数据集可在仓库中获取,而调查代码因许可和伦理考虑尚未发布。
方法
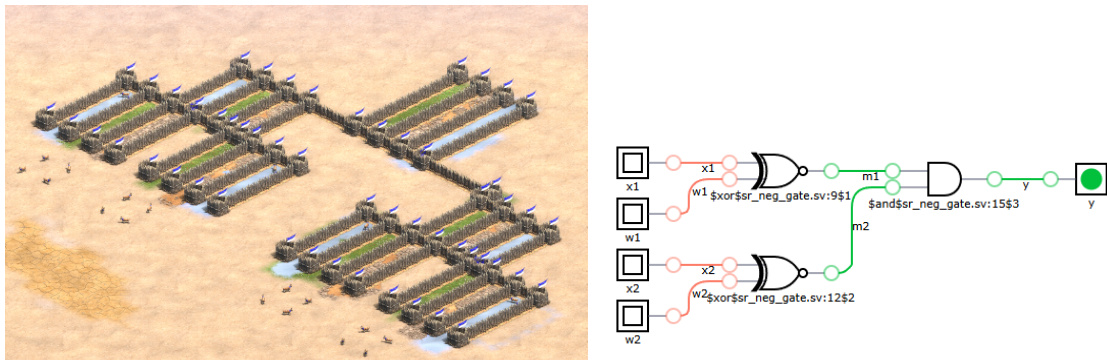
作者确立了 Age of Empires II (AoE II) 的功能性和图灵完备性,以证明任何神经网络都可以在游戏引擎内实现。这是通过使用游戏内单位和触发器构建基本逻辑门(特别是 NAND 门)来实现的。在此基础上,作者使用避免浮点运算的 bipolar 1-bit 架构实现了一个 perceptron,这是神经网络的基本构建块。
perceptron 实现利用 bipolar 表示,其中位被映射到 {−1,+1} 而非标准二进制,从而允许表示学习所需的负权重和偏置。核心架构由两个并行 XNOR 门组成,其输出馈入 AND 门,该门充当 Heaviside step function h(z)。在此特定配置中,偏置项被硬编码到 AND 门逻辑中以简化电路。
如下图所示:
为了训练 perceptron 学习 AND 函数,作者采用了一种适合 1-bit 硬件约束的基于 ansatz 的训练算法。训练电路以真实标签 t、输入向量 x 和当前权重 w 作为输入。过程首先计算 perceptron 的输出 f(x) 并将其与真实标签 t 比较以确定误差 ϵ。该误差使用 XOR 运算计算,ϵ=XOR(f(x),t)。
电路随后评估权重是否需要更新。如果误差非零,则根据规则 w←w+ηϵx 更新权重,其中学习率 η 设置为 1。实现包括逻辑以比较新权重集与当前权重集;如果它们相同,则过程中断,否则重试。
参考框架图以了解此训练算法的详细电路布局:
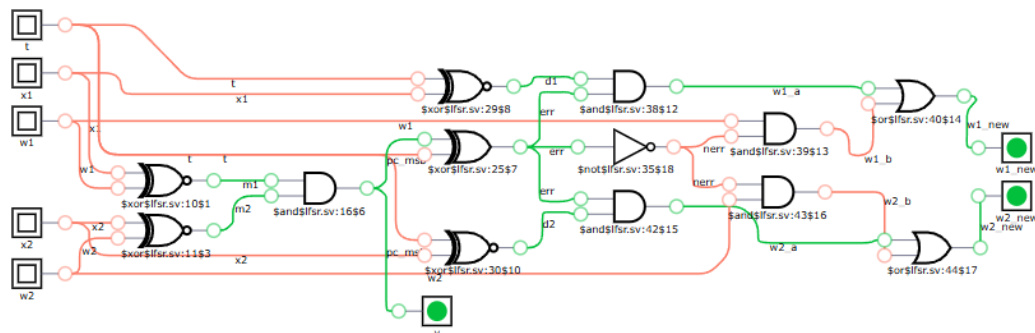
这种方法利用了 bipolar 位表示提供的并发控制,其中每个逻辑位由两个物理轨道(在游戏语境中为 goats)表示,以管理信号时序并避免竞争条件。虽然这种基于 ansatz 的策略不如标准 gradient descent 复杂,但它成功展示了在游戏环境中训练 perceptron 的能力。
实验
该分析检验了测量 LLM 中人类化属性的有效性,证明了机制分析和 substrate 不变性本身并不能防止循环论证,除非明确陈述假设。平行语料库研究验证了这些方法论问题的普遍性,揭示了大多数论文假设人类化特征,并经常在未经独立验证的情况下得出其存在的结论。因此,研究结果强调了系统性地依赖接受或拒绝设置,这往往导致关于 emergent capabilities 的无信息结果。