Command Palette
Search for a command to run...
正则化 f-散度核检验
正则化 f-散度核检验
Mónica Ribero Antonin Schrab Arthur Gretton
摘要
我们提出了一种框架,用于基于 f-散度(f-divergence)族构建实用的、基于核函数的两样本检验(two-sample tests)。该检验统计量通过散度的正则化变分表示(regularized variational representation)中的见证函数(witness function)计算得出,我们利用核方法对该见证函数进行估计。所提出的检验在核带宽和正则化参数等超参数上具有自适应能力。我们为该 f-散度估计量族提供了统计检验功效(statistical test power)的理论保证。尽管我们的检验涵盖了多种 f-散度,但我们特别聚焦于“曲棍棒散度”(Hockey-Stick divergence),这主要得益于其在差分隐私审计(differential privacy auditing)和机器卸载(machine unlearning)评估中的应用。在两样本检验实验中,结果表明不同的 f-散度对不同的局部差异(localized differences)具有敏感性,这凸显了利用多样化统计量的重要性。在机器卸载场景中,我们提出了一种相对检验(relative test),以区分真正的卸载失败与安全分布变化。
一句话总结
作者提出了一种通过估计正则化变分表示的见证函数来构建基于核的双样本测试的实用框架,该方法利用核方法,生成的测试能够自适应超参数并提供关于功效的理论保证,重点在于用于差分隐私审计和机器遗忘评估的曲棍球棒散度,其中相对测试能够区分真正的遗忘失败与安全的分布变化。
核心贡献
- 该工作引入了一个从 f-散度族构建实用的基于核的双样本测试的框架,使用正则化变分表示。测试统计量通过核方法估计的见证函数计算得出,并对核带宽和正则化参数等超参数具有自适应性。
- 该论文为 f-散度估计族的统计测试功效提供了理论保证。基于这些一致散度估计的置换测试建立了渐近和非渐近功效保证。
- 提出了一种用于机器遗忘的相对距离测试,以区分真正的遗忘失败与安全的分布变化。实验表明不同的 f-散度对不同的局部差异敏感,说明了利用多样化统计量的重要性。
引言
双样本测试对于验证机器学习模型至关重要,例如在隐私审计和机器遗忘等背景下。然而,没有单一的距离度量适用于所有场景,因为一些应用需要对局部差异敏感,而另一些则需要平滑变化。现有方法面临困难,因为 f-散度估计所需的见证函数通常是非平滑的,并且在计算上难以学习。作者引入了一个统一框架,利用基于核的似然比估计和 ℓ2-正则化从 f-散度族构建双样本测试。他们证明了理论收敛保证,并提出了一种聚合方法来检测广泛的分布变化。此外,他们通过引入基于曲棍球棒散度的相对距离测试,将此框架应用于改进机器遗忘评估。
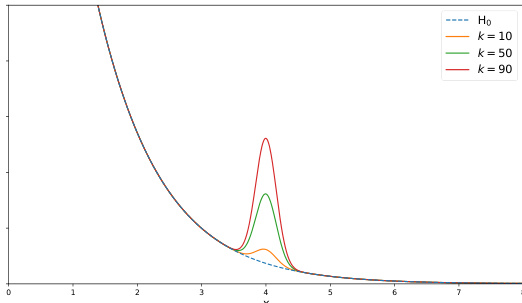
方法
提出的框架从 f-散度族构建实用的基于核的双样本测试。测试统计量通过散度的正则化变分表示的见证函数计算得出,该函数使用核方法估计。这种设计使测试能够自适应核带宽和正则化参数等超参数,同时为统计测试功效提供理论保证。
该方法始于 f-散度的变分表示。对于空间 Z 上的概率分布 P 和 Q,散度使用凸函数 f 定义。变分形式将散度表示为 P 和 Q 下期望之差的函数上的上确界。见证函数是达到此上确界的函数。为了估计这一点,作者专注于估计拉德隆 - 尼科迪姆导数 dQdP 而不是直接估计散度。该导数的 λ-正则化版本在再生核希尔伯特空间中使用核 k 定义。该估计量具有涉及从样本和正则化参数构建的核矩阵的闭式表达式。
使用估计的密度比,作者通过将估计代入变分定义来构建任何 f-散度的估计量。样本被分为两组,其中一组用于构建密度比估计量,另一组用于估计散度计算所需的期望。这种分离确保了 consistency,允许估计量随着样本量趋于无穷大而收敛到真实的 f-散度。
对于假设检验程序,采用置换测试来控制第一类错误的概率。当估计的散度超过从数据导出的置换分位数时,测试拒绝零假设。作者证明该测试是一致的,这意味着随着样本量增加,第二类错误的概率收敛到零。为了处理双样本问题的固有对称性和 f-散度的不对称性,该方法可以利用两个方向上散度的平均值或最大值。
超参数选择通过自适应置换测试解决。这种方法自适应地结合多个超参数配置的结果,以避免手动调整。此外,构建了一个称为 f-Agg 的聚合测试,以在 f-散度集合上聚合这些自适应置换测试。这种聚合通过利用对不同的局部差异敏感的多样化统计量,增强了测试针对广泛替代假设的功效。
特别关注曲棍球棒散度,其动机在于其在差分隐私审计和机器遗忘中的应用。曲棍球棒散度对应于一个特定的凸函数,其中见证函数是基于阈值的指示函数。作者使用正则化密度比推导出了该散度的特定估计量。虽然可以通过半定规划直接优化正则化曲棍球棒见证函数,但实验结果表明,插入估计量方法能产生更好的性能。这是因为直接优化中使用的再生核希尔伯特空间函数类可能不适合表示真实见证函数的不连续性质。
该框架提供了非渐近功效保证,刻画了在任何固定样本量下可以高概率检测到的替代假设集合。理论分析表明,任何 f-散度大于随样本量减少的速率的分布都可以被高准确度正确检测。这些保证对提出的置换测试以及基于正则化 χ2-散度的测试均成立。该方法有效地平衡了估计似然比的准确性与所需样本量的效率。
实验
该工作在合成基准和实际应用(如差分隐私审计和机器遗忘)上评估了提出的 f-散度测试与最先进基线的对比。实验表明,去正则化的 MMD 和 KALE 在检测异常值方面比标准 MMD 具有更高的统计功效,特别是在传统方法难以应对的小扰动情况下。此外,研究确定了在机器遗忘评估中使用双样本测试的局限性,即对训练噪声敏感,并提出了一种三样本测试,能够更准确地区分成功的遗忘与固有的模型变异性。
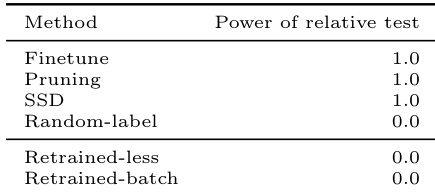
该表展示了用于评估各种机器遗忘方法有效性的三样本相对相似性测试的结果。它表明,近似遗忘技术如微调、剪枝和 SSD 被一致识别为无效,而随机标签技术和重训练变体被正确分类为安全。微调、剪枝和 SSD 等近似方法表现出高测试功效,表明它们未能消除遗忘集的影响。随机标签方法和重训练变体未显示测试功效,确认它们产生的模型与重训练基线在统计上不可区分。该测试成功区分了无效的近似遗忘策略和成功的遗忘过程。
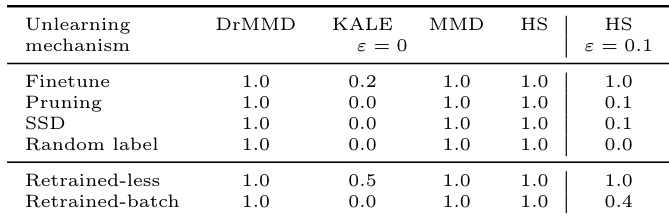
作者通过测试遗忘模型与重训练基线之间的统计不可区分性来评估机器遗忘机制。结果表明,像 MMD 和 DrMMD 这样的严格双样本测试即使在具有不同超参数的有效重训练场景中也能检测到分布差异,限制了其验证用途。然而,使用带有松弛参数的曲棍球棒散度可以更好地区分近似遗忘方法和重训练基线。MMD 和 DrMMD 测试一致拒绝所有遗忘和重训练变体的零假设,表明它们对训练噪声过于敏感。与微调相比,剪枝和 SSD 等近似遗忘方法在松弛的曲棍球棒测试下显示出较低的检测率。KALE 测试在评估的遗忘机制中与其他基于散度的测试相比,通常表现出较低的统计功效。
该表比较了各种双样本测试在 Expo-1D 基准上针对不同分布参数的统计功效。结果表明,KALE 估计量在具有中等扰动倍数的设置中通常比 MMD 和 DrMMD 实现更高的功效,而当扰动倍数较大时,MMD 成为更优的方法。提出的方法在大多数配置中始终比先前工作的基线实现更高的检测率。KALE 在大多数参数配置中表现出优于 MMD 和 DrMMD 的性能。当扰动倍数较大时,MMD 实现了最高的检测率。提出的测试在大多数测试设置中通常优于先前工作的基线方法。

作者评估了曲棍球棒 (HS) 测试与 DP-Auditorium 库在检测非私有机制中的隐私违规方面的表现,使用的样本量为 500 和 5000。结果表明,HS 测试在识别所有测试机制的违规方面非常有效,而 DP-Auditorium 基线在大多数情况下难以检测偏差。HS 测试一致识别所有测试的非私有机制中的隐私违规,而 DP-Auditorium 基线在大多数 SVT 变体中未能检测到违规。对于基于均值机制,HS 测试即使在较小样本量下也能实现高检测率,而基线显示出明显较低的敏感性。增加样本量提高了两种方法的检测能力,但 HS 测试在统计功效上相对于 DP-Auditorium 库保持明显优势。

实验评估了机器遗忘有效性和统计测试性能,以区分成功和近似移除技术。结果表明,微调 (Finetuning) 和剪枝 (Pruning) 等近似方法未能移除数据影响,而曲棍球棒散度测试比 MMD 等更严格的指标提供更好的区分,后者对训练噪声过于敏感。此外,提出的统计测试在检测隐私违规和分布差异方面始终表现出比基线库更高的功效,且跨越不同的参数配置。